1. 概述
SMP称为共享存储型多处理机(Shared Memory mulptiProcessors), 也称为对称型多处理机(Symmetry MultiProcessors)。
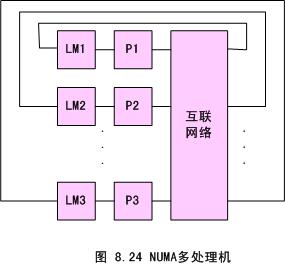
共享存储型多处理机有三种模型:均匀存储器存取(Uniform-Memory-Access,简称UMA)模型、非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型和只用高速缓存的存储器结构(Cache-Only Memory Architecture,简称COMA)模型,这些模型的区别在于存储器和外围资源如何共享或分布。
UMA多处理机模型如图8.23所示。图中,物理存储器被所有处理机均匀共享。所有处理机对所有存储字具有相同的存取时间,这就是为什么称它为均匀存储器存取的原因。每台处理机可以有私用高速缓存,外围设备也以一定形式共享。
共享存储型多处理机有三种模型:均匀存储器存取(Uniform-Memory-Access,简称UMA)模型、非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型和只用高速缓存的存储器结构(Cache-Only Memory Architecture,简称COMA)模型,这些模型的区别在于存储器和外围资源如何共享或分布。
UMA多处理机模型如图8.23所示。图中,物理存储器被所有处理机均匀共享。所有处理机对所有存储字具有相同的存取时间,这就是为什么称它为均匀存储器存取的原因。每台处理机可以有私用高速缓存,外围设备也以一定形式共享。

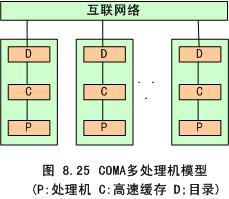
COMA模型如图8.25所示,一种只用高速缓存的多处理机。COMA模型是NUMA机的一种特例,只是将后者中分布主存储器换成了高速缓存, 在每个处理机结点上没有存储器层次结构,全部高速缓冲存储器组成了全局地址空间。远程高速缓存访问则借助于分布高速缓存目录进行。
共享存储系统拥有统一寻址空间,程序员不必参与数据分布和传输。早期的并行处理系统几乎都是基于总线的共享存储系统,它们的发展得益于两方面的原因:一个是微处理器令人难以置信的性能价格比,另一个是在基于微处理器的并行处理系统中广泛使用的cache技术。这些因素使得将多个处理器放到同一条总线上,共享单一存储器成为可能,并通过cache将所有处理器访问存储器所需的存储带宽降低到可以接受的水平。cache一致性是通过监听协议实现的。这种实现方式虽然简单,但是阻碍了系统的扩展能力。
到80年代中期,对可扩展的多处理器系统的需求不断增长。基于总线的、cache一致性、共享单一存储器的机器显然是不可扩展的。1996年SGI Origin 2000系列服务器的推出,一种称为S2MP的并行计算机体系结构受到了广泛的注意。S2MP全称为可扩展共享存储多处理(Scalable Shared-memory MultiProcessing)技术。S2MP系统将大量高性能微处理器连接起来,共享一个统一的地址空间,较好地解决其他并行处理系统无法解决的问题。
S2MP是一种共享存储的体系结构,和大规模的消息传递系统相比,它支持简单的编程模型,系统使用方便,是对SMP系统在支持更高扩展能力方面的发展。共享存储系统降低了通信的额外开销,因此系统也可以运行细粒度的应用。S2MP着眼于扩展性能的研究,和传统的基于总线的共享存储并行处理系统相比,它不存在系统中可以连接的处理器数目的总线带宽的限制。
S2MP作为大规模多处理系统,主要问题仍然是解决系统的可扩展和易编程能力。S2MP系统采用分布式存储器技术,引入cache,降低了访存时延。同时系统内处理器通过高速无阻塞的互连网络连接,增加了系统的通信带宽。这些技术保证了S2MP系统的可扩展性能。另一方面,解决编程问题的主要方法仍然是提供与单机类似的统一地址空间,因此S2MP系统采用共享存储的存储器模型,每个处理器结点都可以直接访问所有的存储单元,程序员不用在程序中显式地控制在处理器之间分布数据和进行通信,因而容易编程。直接访存也使得在处理器间动态分配任务,实现负载平衡简单了。同时,由于共享存储系统是由小规模并行多处理器系统演变而来的,它们具有相同的编程模型,所以那些已有的并行应用问题可以很容易地移植过来运行,解决了并行处理系统的应用程序开发问题。
到80年代中期,对可扩展的多处理器系统的需求不断增长。基于总线的、cache一致性、共享单一存储器的机器显然是不可扩展的。1996年SGI Origin 2000系列服务器的推出,一种称为S2MP的并行计算机体系结构受到了广泛的注意。S2MP全称为可扩展共享存储多处理(Scalable Shared-memory MultiProcessing)技术。S2MP系统将大量高性能微处理器连接起来,共享一个统一的地址空间,较好地解决其他并行处理系统无法解决的问题。
S2MP是一种共享存储的体系结构,和大规模的消息传递系统相比,它支持简单的编程模型,系统使用方便,是对SMP系统在支持更高扩展能力方面的发展。共享存储系统降低了通信的额外开销,因此系统也可以运行细粒度的应用。S2MP着眼于扩展性能的研究,和传统的基于总线的共享存储并行处理系统相比,它不存在系统中可以连接的处理器数目的总线带宽的限制。
S2MP作为大规模多处理系统,主要问题仍然是解决系统的可扩展和易编程能力。S2MP系统采用分布式存储器技术,引入cache,降低了访存时延。同时系统内处理器通过高速无阻塞的互连网络连接,增加了系统的通信带宽。这些技术保证了S2MP系统的可扩展性能。另一方面,解决编程问题的主要方法仍然是提供与单机类似的统一地址空间,因此S2MP系统采用共享存储的存储器模型,每个处理器结点都可以直接访问所有的存储单元,程序员不用在程序中显式地控制在处理器之间分布数据和进行通信,因而容易编程。直接访存也使得在处理器间动态分配任务,实现负载平衡简单了。同时,由于共享存储系统是由小规模并行多处理器系统演变而来的,它们具有相同的编程模型,所以那些已有的并行应用问题可以很容易地移植过来运行,解决了并行处理系统的应用程序开发问题。