在我之前的文章:
通过上面的两篇文章的介绍,我们应该充分掌握了如何使用 enrich processor 来丰富数据了。特别是在上面的第二篇文章中,我们需要使用手动来一个一个地通过 Kibana 的界面来写入数据。我们感觉还是比较麻烦。如果我们能够实现自动化来完成整个的操作,那将是非常好的。在今天的文章中,我们将结合 enrich processor 和 Logstash 来实现数据的丰富自动化。我们可以利用 Linux 所提供的脚本来完成数据摄入的自动化。
在一下的展示中,我将使用如下的架构来进行展示:

数据描述
在进行我们的练习之前,我们下载所需要的数据及相关文档:
git clone https://github.com/evermight/elasticsearch-ingestarallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ pwd
/home/parallels/data/elasticsearch-ingest/part-3
parallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ tree -L 3
.
├── 01-zip_geo.sh
├── 02-customer.sh
├── 03-product.sh
├── 04-order_item.sh
├── 05-order.sh
├── data
│ ├── customer
│ │ ├── data.csv
│ │ └── readme.txt
│ ├── mysql
│ │ ├── load.sql
│ │ └── readme.md
│ ├── order
│ │ ├── data.csv
│ │ └── data.xlsx
│ ├── order_item
│ │ ├── data.csv
│ │ └── data.xlsx
│ ├── product
│ │ └── data.csv
│ └── zip_geo
│ ├── data.csv
│ └── data.xlsx
├── env.sample
├── logstash
│ ├── customer.conf
│ ├── order.conf
│ ├── order_item.conf
│ ├── product.conf
│ └── zip_geo.conf
├── mapping
│ ├── customer.json
│ ├── order.json
│ └── zip_geo.json
├── part-3.pdf
├── part-3.pptx
├── pipeline
│ ├── customer.json
│ ├── order_item.json
│ └── order.json
├── policy
│ ├── customer.json
│ ├── order_item.json
│ ├── product.json
│ └── zip_geo.json
├── readme.md
├── run.sh
└── teardown.sh如上所示,我们的文档结构如上所示。我们的数据结构如下:
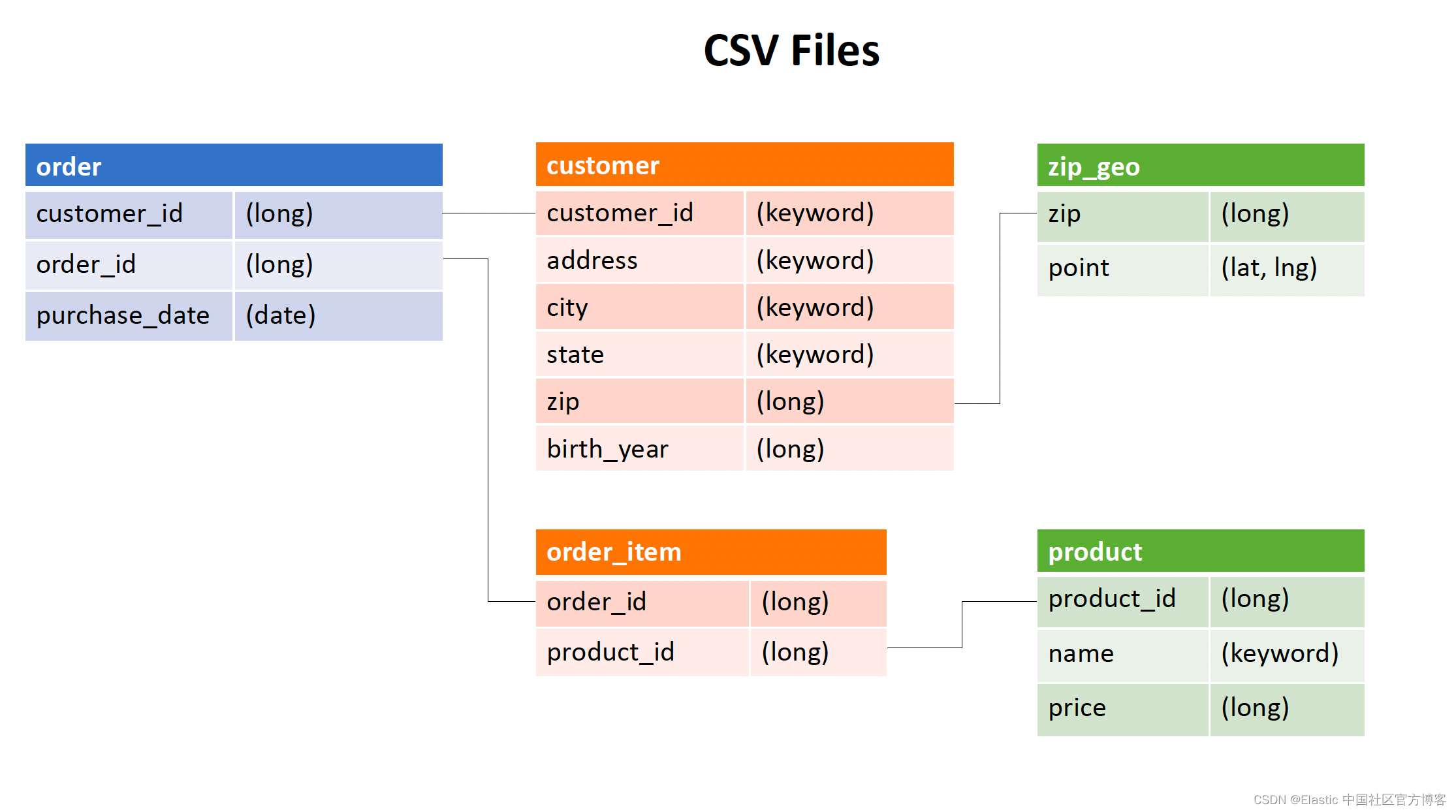
我们有如上的几个表格。它们之间的数据是相互关联的。我们知道在 Elasticsearch 中的数据,它不像传统的关系数据库,在查询的时候,我们可以通过 join 来丰富数据,而且为了能够提高数据的查询速度,我们最好把数据实现扁平化,这也就是的数据的非规范化(denormalization)。我们可以详细阅读文章 “Elasticsearch:Elasticsearch 中索引映射的非规范化”。在摄入数据的时候,我们希望把相关的内容最终能丰富到最后的文档中。我们希望实现如下的内容:

从上面的最终结果,我们可以看出来,我们需要的数据来自不同的表格。这个需要我们使用 enrich processor 来帮我们完成。
文件目录描述
在项目的目录(part-3)下面,我们可以看到如下的几个子目录:
- data:在这个目录里它含有我们需要的各个数据以及它们的来源
- mapping:在这个目录中,它含有各个表格数据的 mapping。通常我们并不需要预先定义数据的类型。我们可以让 Elasticsearch 帮我们自动识别数据的类型,但这往往不是最佳的。通过定义相应数据的 mapping,一方面它可以帮忙明确地定义数据字段的类型,比如 geo_point 数据类型,另一方面,通过设置 mapping,也可以提高数据的摄入速度
- policy:在这个目录中,它定义了使用 enrich processor 时所需要的 policies。
- pipeline:在这个目录里,它定义了在 enrich 时,我们需要使用到的 enrich processor
- logstash:在这个目录里,它定义了 Logstash 需要使用到的配置文件
写入文档的顺序
由于我们的数据是一个关系数据表格,在我们写入数据的时候,我们先从上面图中的右边开始写入数据,这是因为左边的表格依赖于右边的表格。只有它们的数据是准备好的状态,那么我们才可以利用它们来丰富左边的表格。这也就是我们看到的如下的脚本:

如上图所示,我们可以看到
01-zip_geo.sh
02-customer.sh
03-product.sh
04-order_item.sh
05-order.sh 这个其实就是我们执行脚本的顺序。我们需要按照上面的顺序从上到下来进行执行。
摄入数据
我们知道在我们摄入数据的时候,我们可以使用 Logstash 来写入 CSV 文档。Logstash 的好处是,它含有丰富的 filters 来供我们对数据进行处理。

针对 Elastic Stack 8.x 的安装来说,在默认的情况下,Elasticsearch 是带有安全的。针对自签名的集群来说,它通常还含有证书。针对带有安全的集群,我们可以参考文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。下面,我们以摄入 zip_geo 为例来进行展示。在摄入数据的时候,我们需要使用到 fingerprint。我们可以参考文章 “Beats:使用 fingerprint 来连接 Beats/Logstash 和 Elasticsearch”。
在 logstash 目录下,我们可以看到如下的 zip_geo.conf 文档:
zip_geo.conf
input {
file {
path => "##PROJECTPATH##/data/zip_geo/data.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
mode => "read"
exit_after_read => true
file_completed_action => "log"
file_completed_log_path => "##PROJECTPATH##/.logstash-status"
}
}
filter {
csv {
autodetect_column_names => true
}
mutate {
convert => {
"zip" => "integer"
"point" => "string"
}
}
}
output {
elasticsearch {
hosts => ["##ELASTICHOST##"]
ssl => ##ELASTICSSL##
user => "##ELASTICUSER##"
password => "##ELASTICPASS##"
index => "zip_geo"
ssl => true
ca_trusted_fingerprint => "##FINGERPRINT##"
}
}这是一个标准的 Logstash 配置文件。在上面,我们可以看到一下奇奇怪怪的的像 ##PROJECTPATH## 这样的占位符号。这个需要在哪里配置呢?
我们回到项目的根目录下(part-3),我们可以看到一个叫做 env.sample 的文档。我们通过如下的命令来来创建一个叫做 .env 的文件:
cp env.sample .env我们可以使用我们喜欢的编辑器来编辑这个 .env 文件:
vi .envPROJECTPATH="/home/parallels/data/elasticsearch-ingest/part-3"
ELASTICHOST="192.168.0.3:9200"
ELASTICSSL="true"
ELASTICUSER="elastic"
ELASTICPASS="h6y=vgnen2vkbm6D+z6-"
FINGERPRINT="bd0a26dc646ef1cb3cb5e132e77d6113e1b46d56ee390dd3c6f0b2d2b16962c4"
LOGSTASHPATH="/home/parallels/elastic/logstash-8.8.2"我们根据自己的配置填入上面的信息。其中 FINGERPRINT 最为简单的办法就是通过 Kibana 的配置文件 config/kibana.yml 文件来获得。我们保存好上面的文件。这里其实就是定义的环境变量。我们接下来查看 1-zip_geo.sh 文件:
1-zip_geo.sh
#!/bin/bash
source ./.env
hostprotocol="http"
if [ "$ELASTICSSL" = "true" ]; then
hostprotocol="https"
fi
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/zip_geo"
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/zip_geo/_mapping" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/mapping/zip_geo.json
logstashconf=`cat ${PROJECTPATH}/logstash/zip_geo.conf`
logstashconf="${logstashconf//\#\#PROJECTPATH\#\#/"$PROJECTPATH"}"
logstashconf="${logstashconf//\#\#ELASTICHOST\#\#/"$ELASTICHOST"}"
logstashconf="${logstashconf//\#\#ELASTICSSL\#\#/"$ELASTICSSL"}"
logstashconf="${logstashconf//\#\#ELASTICUSER\#\#/"$ELASTICUSER"}"
logstashconf="${logstashconf//\#\#ELASTICPASS\#\#/"$ELASTICPASS"}"
logstashconf="${logstashconf//\#\#FINGERPRINT\#\#/"$FINGERPRINT"}"
$LOGSTASHPATH/bin/logstash -e "$logstashconf"
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.json
sleep 30
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy/_execute"上面的代码看起来很负责,一下子看不太明白。在开始的部分,我们从环境变量里得到 ELASTICSSL 的值。如果 Elasticsearch 集群的访问是 https 访问的,那么这个值应该设置为 true。这个在接下来的 curl 指令中需要用到。值得注意的是:由于我们的集群是自签名的,我们使用 -k 选项来绕开证书的配置,尽管我们也可以通过设置来配置证书的访问。
记下来,我们使用 curl 指令来创建 zip_geo 索引。它的指令的格式有点类似:
curl -k -u elastic:h6y=vgnen2vkbm6D+z6- https://localhost:9200/zip_geo如果是在 Kibana 中的 Dev Tools 中进行操作,它相当于:
PUT zip_geo上述指令创建一个叫做 zip_geo 的指令。
接下来的指令,它相当于:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- ”https://localhost:9200/zip_geo/_mapping" \
-H "Content-Type: application/json" \
-d /Users/liuxg/data/elasticsearch-ingest/part-3/mapping/zip_geo.json上述命令相当于在 Kibana 中打入如下的命令:
PUT zip_geo/_mapping
{
"properties": {
"zip": {
"type": "long"
},
"point": {
"type": "geo_point"
}
}
}下面的代码:
logstashconf=`cat ${PROJECTPATH}/logstash/zip_geo.conf`
logstashconf="${logstashconf//\#\#PROJECTPATH\#\#/"$PROJECTPATH"}"
logstashconf="${logstashconf//\#\#ELASTICHOST\#\#/"$ELASTICHOST"}"
logstashconf="${logstashconf///\#\#ELASTICSSL\#\#/"$ELASTICSSL"}"
logstashconf="${logstashconf//\#\#ELASTICUSER\#\#/"$ELASTICUSER"}"
logstashconf="${logstashconf//\#\#ELASTICPASS\#\#/"$ELASTICPASS"}"
logstashconf="${logstashconf//\#\#FINGERPRINT\#\#/"$FINGERPRINT"}"
./bin/logstash -e "$logstashconf"这部分代码的真正意思是替换 zip_geo,conf 里含有 “## ... ##" 部分的字符串进行替换。如果你对这个不是很熟悉的话,请参阅网上的链接。在上面的最后部分,我们使用 Logstash 来运行在 logstashconf 变量里的管道。
下面的代码:
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.json它用来运行 zip_geo_policy 以生成相应的 .enrich_zip_geo_policy,,,,, 索引。它想到于如下的命令:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- "https://localhost:9200/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.json在 Kibana 中,我们可以打入如下的命令来实现同样的功能:
PUT /_enrich/policy/zip_geo_policy
{
"match": {
"indices": "zip_geo",
"match_field": "zip",
"enrich_fields": ["point"]
}
}由于生成丰富索引需要一定的时间,在脚本的部分,我们挂起 30 秒的时间,当然这个依赖于数据量的多少。
在最后的部分,我们执行:
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy/_execute"它相当于执行:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- "https://localhost:9200/_enrich/policy/zip_geo_policy/_execute"在 Kibana 中,我们可以通过如下的命令来完成相应的功能:
PUT /_enrich/policy/zip_geo_policy/_execute好了,让我们来执行第一个脚本:


运行完,我们的第一个脚本后,我们可以在 Kibana 中进行查看:


我们按照同样的套路依次执行如下的脚本:
02-customer.sh
03-product.sh
04-order_item.sh
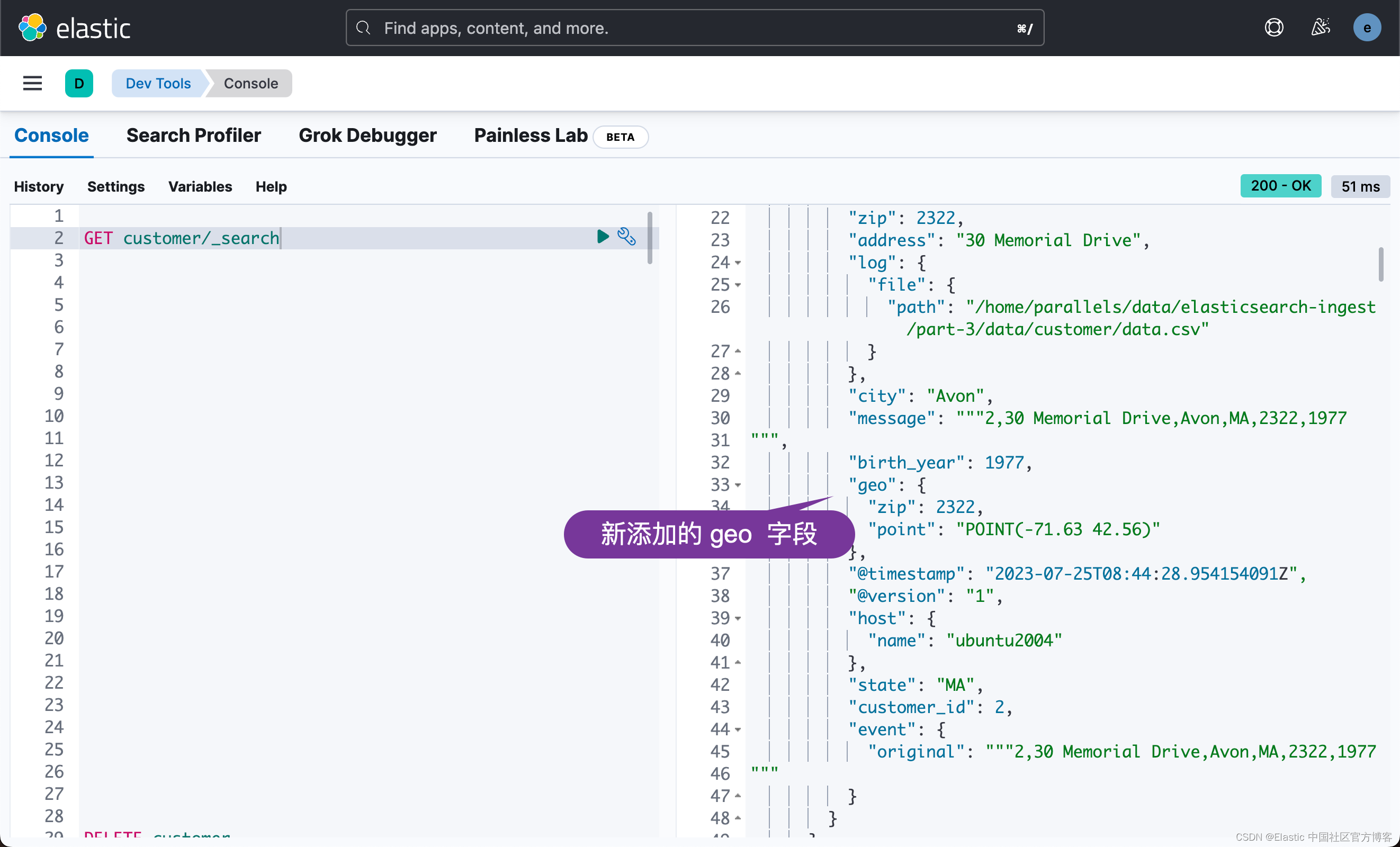
05-order.sh 在运行完 02-customer.sh 后,我们可以看到:
我们接着运行 02-product.sh 脚本。我们可以查看到 product 索引的文档:

我们再接着运行 04-order_item.sh 脚本:

我们接下来运行 05-order.sh:
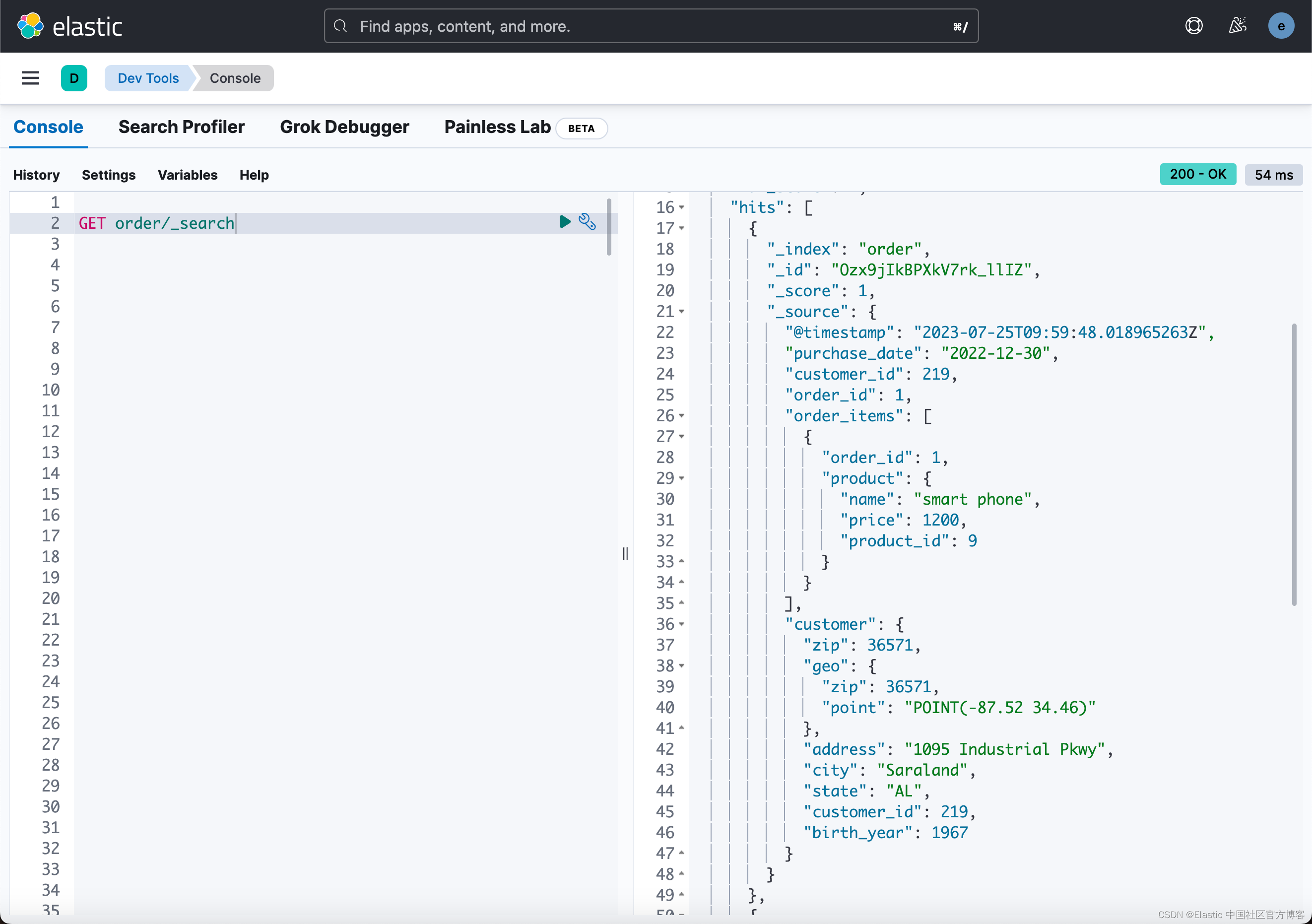
从上面,我们可以看到我们最终想要的结果。
为了能删除所有之前创建的资源,我们可以一键删除:
./teardown.sh然后,我们可以再使用一个命令来完成所有的运行:
parallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ cat run.sh
./01-zip_geo.sh
./02-customer.sh
./03-product.sh
./04-order_item.sh
./05-order.sh./run.sh特别注意的一点是,我们的 enrich processor 是在 ingest pipeline 里被调用的,比如:
output {
elasticsearch {
hosts => ["##ELASTICHOST##"]
ssl => ##ELASTICSSL##
user => "##ELASTICUSER##"
password => "##ELASTICPASS##"
index => "customer"
pipeline => "customer_pipeline"
ca_trusted_fingerprint => "##FINGERPRINT##"
}
}你可以在地址下载所有的代码:GitHub - evermight/elasticsearch-ingest