Kubernetes 也提供了类似的linux top的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。
Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具,它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用 1m 的 CPU 和 2MB 的内存,所以性价比非常高。
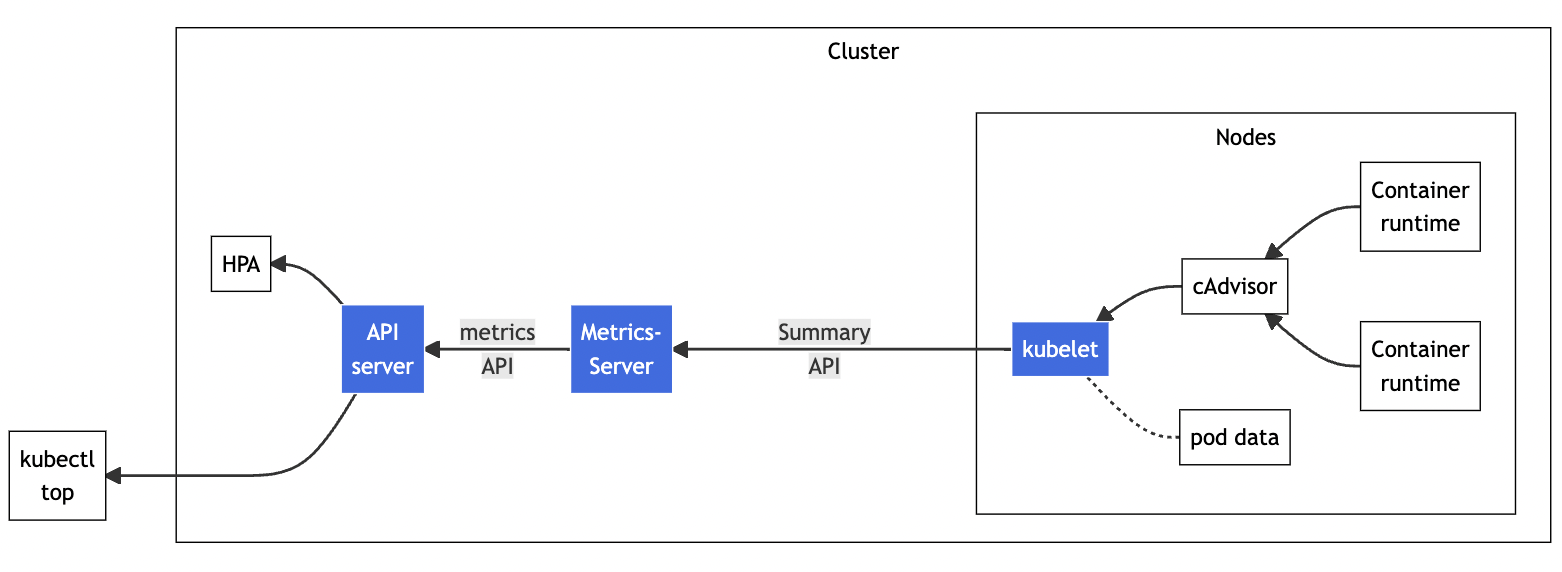
它调用 kubelet 的 API 拿到节点和 Pod 的指标,再把这些信息交给 apiserver,这样 kubectl、HPA 就可以利用 apiserver 来读取指标了。
Metrics Server 的所有依赖都放在了一个 YAML 描述文件里,你可以使用 wget 或者 curl 下载:
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlkubectl top 来查看 Kubernetes 集群当前的资源状态了。它有两个子命令,node 查看节点的资源使用率,pod 查看 Pod 的资源使用率。
kubectl top node
kubectl top pod -n kube-systemKubernetes 为此就定义了一个新的 API 对象,叫做“HorizontalPodAutoscaler”,简称是“hpa”。它是专门用来自动伸缩 Pod 数量的对象,适用于 Deployment 和 StatefulSet。
HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量。
Prometheus 系统的核心是它的 Server,里面有一个时序数据库 TSDB,用来存储监控数据,另一个组件 Retrieval 使用拉取(Pull)的方式从各个目标收集数据,再通过 HTTP Server 把这些数据交给外界使用。
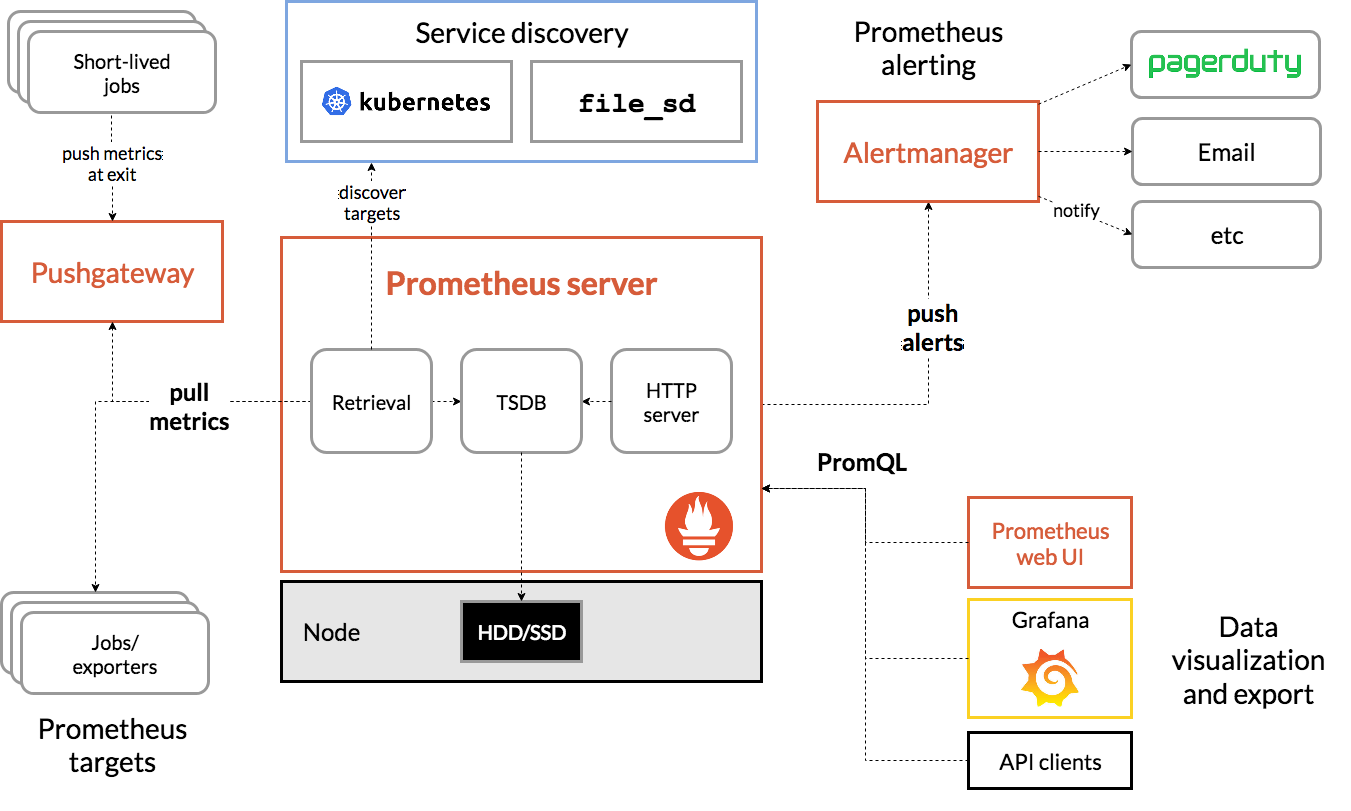
在 Prometheus Server 之外还有三个重要的组件:
- Push Gateway,用来适配一些特殊的监控目标,把默认的 Pull 模式转变为 Push 模式。
- Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
- Grafana 是图形化界面,可以定制大量直观的监控仪表盘。
此文章为7月Day24学习笔记,内容来源于极客时间《Kubernetes入门实战课》,推荐该课程。