Linux内核在2022年主要发布了5.16-5.19以及6.0和6.1这几个版本,每个版本都为eBPF引入了大量的新特性。本文将对这些新特性进行一点简要的介绍,更详细的资料请参考对应的链接信息。总体而言,eBPF在内核中依然是最活跃的模块之一,它的功能特性也还在高速发展中。某种意义上说,eBPF正朝着一个完备的内核态可编程接口快速进化。
eBPF 进阶: 内核新特性进展一览
- BPF kfuncs
- Bloom Filter Map:5.16
- Compile Once – Run Everywhere:Linux 5.17
- bpf_loop() 辅助函数:5.17
- BPF_LINK_TYPE_KPROBE_MULTI:5.18
- 动态指针和类型指针:5.19
- USDT:5.19
- bpf panic:6.1
- BPF 内存分配器、链表:6.1
- user ring buffer 6.1
一、eBPF概述
1.1eBPF是什么
eBPF 是一个基于寄存器的虚拟机,使用自定义的 64 位 RISC 指令集,能够在 Linux 内核内运行即时本地编译的 “BPF 程序”,并能访问内核功能和内存的一个子集。这是一个完整的虚拟机实现,不要与基于内核的虚拟机(KVM)相混淆,后者是一个模块,目的是使 Linux 能够作为其他虚拟机的管理程序。eBPF 也是主线内核的一部分,所以它不像其他框架那样需要任何第三方模块(LTTng 或 SystemTap),而且几乎所有的 Linux 发行版都默认启用。熟悉 DTrace 的读者可能会发现 DTrace/BPFtrace 对比非常有用。
在内核内运行一个完整的虚拟机主要是考虑便利和安全。虽然 eBPF 程序所做的操作都可以通过正常的内核模块来处理,但直接的内核编程是一件非常危险的事情 - 这可能会导致系统锁定、内存损坏和进程崩溃,从而导致安全漏洞和其他意外的效果,特别是在生产设备上(eBPF 经常被用来检查生产中的系统),所以通过一个安全的虚拟机运行本地 JIT 编译的快速内核代码对于安全监控和沙盒、网络过滤、程序跟踪、性能分析和调试都是非常有价值的。部分简单的样例可以在这篇优秀的 eBPF 参考中找到。
基于设计,eBPF 虚拟机和其程序有意地设计为不是图灵完备的:即不允许有循环(正在进行的工作是支持有界循环【译者注:已经支持有界循环,#pragma unroll 指令】),所以每个 eBPF 程序都需要保证完成而不会被挂起、所有的内存访问都是有界和类型检查的(包括寄存器,一个 MOV 指令可以改变一个寄存器的类型)、不能包含空解引用、一个程序必须最多拥有 BPF_MAXINSNS 指令(默认 4096)、“主"函数需要一个参数(context)等等。当 eBPF 程序被加载到内核中,其指令被验证模块解析为有向环状图,上述的限制使得正确性可以得到简单而快速的验证。
主要区别如下:
- 允许使用C 语言编写代码片段,并通过LLVM编译成eBPF 字节码;
- cBPF 只实现了SOCKET_FILTER,而eBPF还有KPROBE 、PERF等。
- BPF使用socket 实现了用户态与内核交互,eBPF 则定义了一个专用于eBPF 的新的系统调用,用于装载BPF 代码段、创建和读取BPF map,更加通用。
- BPF map 机制,用于在内核中以key-value 的方式临时存储BPF 代码产生的数据。
对于eBPF可以简单的理解成kernel实现了一个虚拟机机制,将类C代码编译成字节码(后文有详细解释),挂在到内核的钩子上,当钩子被触发时,kernel在虚拟机的"沙盒"中运行字节码,这样既能方便的实现很多功能,也能通过沙箱保证内核的安全性。
1.2eBPF的演进
最初的[Berkeley Packet Filter (BPF) PDF]是为捕捉和过滤符合特定规则的网络包而设计的,过滤器为运行在基于寄存器的虚拟机上的程序。
在内核中运行用户指定的程序被证明是一种有用的设计,但最初BPF设计中的一些特性却并没有得到很好的支持。例如,虚拟机的指令集架构(ISA)相对落后,现在处理器已经使用64位的寄存器,并为多核系统引入了新的指令,如原子指令XADD。BPF提供的一小部分RISC指令已经无法在现有的处理器上使用。
因此Alexei Starovoitov在eBPF的设计中介绍了如何利用现代硬件,使eBPF虚拟机更接近当代处理器,eBPF指令更接近硬件的ISA,便于提升性能。其中最大的变动之一是使用了64位的寄存器,并将寄存器的数量从2提升到了10个。由于现代架构使用的寄存器远远大于10个,这样就可以像本机硬件一样将参数通过eBPF虚拟机寄存器传递给对应的函数。另外,新增的BPF_CALL指令使得调用内核函数更加便利。
将eBPF映射到本机指令有助于实时编译,提升性能。3.15内核中新增的eBPF补丁使得x86-64上运行的eBPF相比老的BPF(cBPF)在网络过滤上的性能提升了4倍,大部分情况下会保持1.5倍的性能提升。很多架构 (x86-64, SPARC, PowerPC, ARM, arm64, MIPS, and s390)已经支持即时(JIT)编译。
1.3ebpf环境搭建
编译运行源码samples/bpf中的代码
- 下载内核源码并解压
- /bin/sh: scripts/mod/modpost: No such file or directory 遇到这种错误,需要make scripts
- make M=samples/bpf 需要.config文件,需要保证这些项存在
- 遇到错误libcrypt1.so.1 not found,执行如下代码(https://www.mail-archive.com/[email protected]/msg1818037.html)
$ cd /tmp
$ apt -y download libcrypt1
$ dpkg-deb -x libcrypt1_1%3a4.4.25-2_amd64.deb .
$ cp -av lib/x86_64-linux-gnu/* /lib/x86_64-linux-gnu/
$ apt -y --fix-broken install
5.编译成功,可以执行samples/bpf中的可执行文件。
编译运行自己开发的代码
\1. 下载linux source code,编译内核并升级
git clone https://github.com/torvalds/linux.git
cd linux/
git checkout -b v5.0 v5.0
配置文件
cp -a /boot/config-4.14.81.bm.15-amd64 ./.config
echo '
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_BPF_JIT=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
CONFIG_FTRACE_SYSCALLS=y
CONFIG_FUNCTION_TRACER=y
CONFIG_HAVE_DYNAMIC_FTRACE=y
CONFIG_DYNAMIC_FTRACE=y
CONFIG_HAVE_KPROBES=y
CONFIG_KPROBES=y
CONFIG_KPROBE_EVENTS=y
CONFIG_ARCH_SUPPORTS_UPROBES=y
CONFIG_UPROBES=y
CONFIG_UPROBE_EVENTS=y
CONFIG_DEBUG_FS=y
CONFIG_DEBUG_INFO_BTF=y
' >> ./.config
需要添加sid源安装dwarves
apt install dwarves
make oldconfig
apt install libssl-dev
make
make modules_install
make install
reboot
此时:
uname -a
Linux n231-238-061 5.0.0 #1 SMP Mon Dec 13 05:38:52 UTC 2021 x86_64 GNU/Linux
编译bpf helloworld
切换到https://github.com/bpftools/linux-observability-with-bpf的helloworld目录
sed -i 's;/kernel-src;/root/linux;' Makefile
make
有报错:
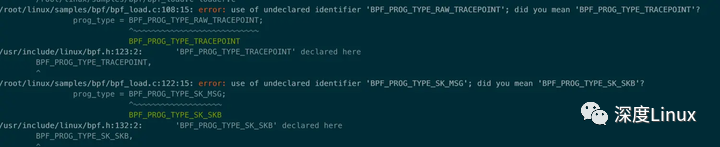
参考:http://www.helight.info/blog/2021/build-kernel-ebpf-sample/解决
cp /root/linux/include/uapi/linux/bpf.h /usr/include/linux/bpf.h
执行./monitor-exec,有报错
./monitor-exec: error while loading shared libraries: libbpf.so: cannot open shared object file: No such file or directory
解决方法
cd /root/linux/tools/lib/bpf/
make
make install
在 /etc/ld.so.conf 中添加 /usr/local/lib64这一行,运行 sudo ldconfig 重新生成动态库配置信息。
~/linux/tools/lib/bpf# ldconfig -v 2>/dev/null | grep libbpf
libbpf.so.0 -> libbpf.so.0.5.0
libbpf.so -> libbpf.so
最终执行情况:
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
可能需要安装apt-get install gcc-multilib g+±multilib
https://github.com/sirfz/tesserocr/issues/130
安装bpftrace
(1)debian 添加sid源 https://github.com/iovisor/bcc/blob/master/INSTALL.md#debian—source
deb http://deb.debian.org/debian sid main contrib non-free
deb-src http://deb.debian.org/debian sid main contrib non-free
(2)apt install bpftrace https://github.com/iovisor/bpftrace/blob/master/INSTALL.md
1.4使用eBPF可以做什么?
一个eBPF程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的eBPF程序。鉴于它的起源,eBPF特别适合编写网络程序,将该网络程序附加到网络socket,进行流量过滤,流量分类以及执行网络分类器的动作。eBPF程序甚至可以修改一个已建链的网络socket的配置。XDP工程会在网络栈的底层运行eBPF程序,高性能地进行处理接收到的报文。
从下图可以看到eBPF支持的功能:
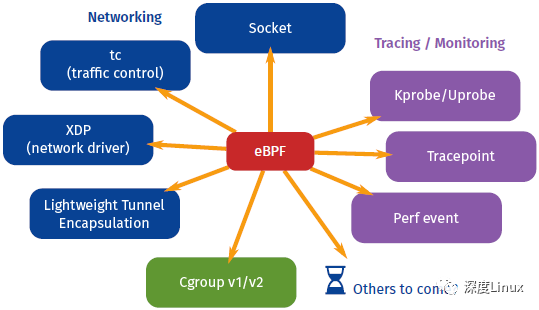
BPF对网络的处理可以分为tc/BPF和XDP/BPF,它们的主要区别如下(参考该文档):
XDP的钩子要早于tc,因此性能更高:tc钩子使用sk_buff结构体作为参数,而XDP使用xdp_md结构体作为参数,sk_buff中的数据要远多于xdp_md,但也会对性能造成一定影响,且报文需要上送到tc钩子才会触发处理程序。由于XDP钩子位于网络栈之前,因此XDP使用的xdp_buff(即xdp_md)无法访问sk_buff元数据。
struct xdp_buff {
/* Linux 5.8*/
void *data;
void *data_end;
void *data_meta;
void *data_hard_start;
struct xdp_rxq_info *rxq;
struct xdp_txq_info *txq;
u32 frame_sz; /* frame size to deduce data_hard_end/reserved tailroom*/
};
struct xdp_rxq_info {
struct net_device *dev;
u32 queue_index;
u32 reg_state;
struct xdp_mem_info mem;
} ____cacheline_aligned; /* perf critical, avoid false-sharing */
struct xdp_txq_info {
struct net_device *dev; };
data指向page中的数据包的其实位置,data_end指向数据包的结尾。由于XDP允许headroom(见下文),data_hard_start指向page中headroom的起始位置,即,当对报文进行封装时,data会通过bpf_xdp_adjust_head()向data_hard_start移动。
相同的BPF辅助函数也可以用以解封装,此时data会远离data_hard_start。data_meta一开始指向与data相同的位置,但bpf_xdp_adjust_meta() 能够将其朝着 data_hard_start 移动,进而给用户元数据提供空间,这部分空间对内核网络栈是不可见的,但可以被tc BPF程序读取( tc 需要将它从 XDP 转移到 skb)。
反之,可以通过相同的BPF程序将data_meta远离data_hard_start来移除或减少用户元数据大小。data_meta 还可以单纯地用于在尾调用间传递状态,与tc BPF程序访问的skb->cb[]控制块类似。 对于struct xdp_buff中的报文指针,有如下关系 :data_hard_start <= data_meta <= data < data_end。rxq字段指向在ring启动期间填充的额外的与每个接受队列相关的元数据。BPF程序可以检索queue_index,以及网络设备上的其他数据(如ifindex等)。
tc能够更好地管理报文:tc的BPF输入上下文是一个sk_buff,不同于XDP使用的xdp_buff,二者各有利弊。当内核的网络栈在XDP层之后接收到一个报文时,会分配一个buffer,解析并保存报文的元数据,这些元数据即sk_buff。
该结构体会暴露给BPF的输入上下文,这样tc ingress层的tc BPF程序就能够使用网络栈从报文解析到的元数据。使用sk_buff,tc可以更直接地使用这些元数据,因此附加到tc BPF钩子的BPF程序可以读取或写入skb的mark,pkt_type, protocol, priority, queue_mapping, napi_id, cb[] array, hash, tc_classid 或 tc_index, vlan metadata等,而XDP能够传输用户的元数据以及其他信息。tc BPF使用的 struct __sk_buff定义在linux/bpf.h头文件中。xdp_buff 的弊端在于,其无法使用sk_buff中的数据,XDP只能使用原始的报文数据,并传输用户元数据。
XDP的能够更快地修改报文:sk_buff包含很多协议相关的信息(如GSO阶段的信息),因此其很难通过简单地修改报文数据达到切换协议的目的,原因是网络栈对报文的处理主要基于报文的元数据,而非每次访问数据包内容的开销。因此,BPF辅助函数需要正确处理内部sk_buff的转换。而xdp_buff 则不会有这种问题,因为XDP的处理时间早于内核分配sk_buff的时间,因此可以简单地实现对任何报文的修改(但管理起来要更加困难)。
tc/ebpf和xdp可以互补:如果用户需要修改报文,同时对数据进行比较复杂的管理,那么,可以通过运行两种类型的程序来弥补每种程序类型的局限性。XDP程序位于ingress,可以修改完整的报文,并将用户元数据从XDP BPF传递给tc BPF,然后tc可以使用XDP的元数据和sk_buff字段管理报文。
tc/eBPF可以作用于ingress和egress,但XDP只能作用于ingress:与XDP相比,tc BPF程序可以在ingress和egress的网络数据路径上触发,而XDP只能作用于ingress。
tc/BPF不需要改变硬件驱动,而XDP通常会使用native驱动模式来获得更高的性能。但tc BPF程序的处理仍作用于早期的内核网络数据路径上(GRO处理之后,协议处理和传统的iptables防火墙的处理之前,如iptables PREROUTING或nftables ingress钩子等)。而在egress上,tc BPF程序在将报文传递给驱动之前进行处理,即在传统的iptables防火墙(如iptables POSTROUTING)之后,但在内核的GSO引擎之前进行处理。一个特殊情况是,如果使用了offloaded的tc BPF程序(通常通过SmartNIC提供),此时Offloaded tc/eBPF接近于Offloaded XDP的性能。
从下图可以看到TC和XDP的工作位置,可以看到XDP对报文的处理要先于TC:
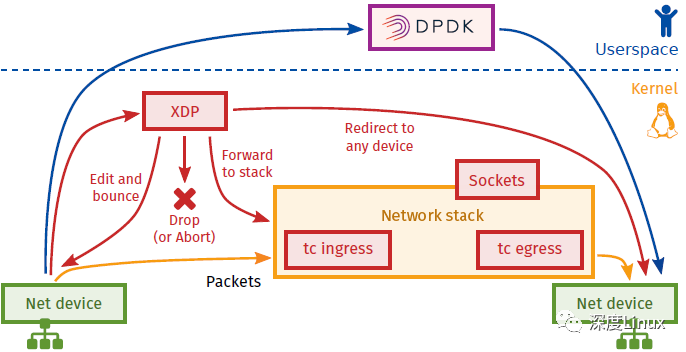
内核执行的另一种过滤类型是限制进程可以使用的系统调用。通过seccomp BPF实现。
eBPF也可以用于通过将程序附加到tracepoints, kprobes,和perf events的方式定位内核问题,以及进行性能分析。因为eBPF可以访问内核数据结构,开发者可以在不编译内核的前提下编写并测试代码。对于工作繁忙的工程师,通过该方式可以方便地调试一个在线运行的系统。此外,还可以通过静态定义的追踪点调试用户空间的程序(即BCC调试用户程序,如Mysql)。
使用eBPF有两大优势:快速,安全。为了更好地使用eBPF,需要了解它是如何工作的。
1.5内核的eBPF校验器
在内核中运行用户空间的代码可能会存在安全和稳定性风险。因此,在加载eBPF程序前需要进行大量校验。首先通过对程序控制流的深度优先搜索保证eBPF能够正常结束,不会因为任何循环导致内核锁定。严禁使用无法到达的指令;任何包含无法到达的指令的程序都会导致加载失败。
第二个阶段涉及使用校验器模拟执行eBPF程序(每次执行一个指令)。在每次指令执行前后都需要校验虚拟机的状态,保证寄存器和栈的状态都是有效的。严禁越界(代码)跳跃,以及访问越界数据。
校验器不会检查程序的每条路径,它能够知道程序的当前状态是否是已经检查过的程序的子集。由于前面的所有路径都必须是有效的(否则程序会加载失败),当前的路径也必须是有效的,因此允许验证器“修剪”当前分支并跳过其模拟阶段。
校验器有一个"安全模式",禁止指针运算。当一个没有CAP_SYS_ADMIN特权的用户加载eBPF程序时会启用安全模式,确保不会将内核地址泄露给非特权用户,且不会将指针写入内存。如果没有启用安全模式,则仅允许在执行检查之后进行指针运算。例如,所有的指针访问时都会检查类型,对齐和边界冲突。
无法读取包含未初始化内容的寄存器,尝试读取这类寄存器中的内容将导致加载失败。R0-R5的寄存器内容在函数调用期间被标记未不可读状态,可以通过存储一个特殊值来测试任何对未初始化寄存器的读取行为;对于读取堆栈上的变量的行为也进行了类似的检查,确保没有指令会写入只读的帧指针寄存器。
最后,校验器会使用eBPF程序类型(见下)来限制可以从eBPF程序调用哪些内核函数,以及访问哪些数据结构。例如,一些程序类型可以直接访问网络报文。、
1.6pf()系统调用
使用bpf()系统调用和BPF_PROG_LOAD命令加载程序。该系统调用的原型为:
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf_attr允许数据在内核和用户空间传递,具体类型取决于cmd参数。
cmd可以是如下内容:
BPF_MAP_CREATE
Create a map and return a file descriptor that refers to the
map. The close-on-exec file descriptor flag (see fcntl(2)) is
automatically enabled for the new file descriptor.
BPF_MAP_LOOKUP_ELEM
Look up an element by key in a specified map and return its
value.
BPF_MAP_UPDATE_ELEM
Create or update an element (key/value pair) in a specified
map.
BPF_MAP_DELETE_ELEM
Look up and delete an element by key in a specified map.
BPF_MAP_GET_NEXT_KEY
Look up an element by key in a specified map and return the
key of the next element.
BPF_PROG_LOAD
Verify and load an eBPF program, returning a new file descrip‐
tor associated with the program. The close-on-exec file
descriptor flag (see fcntl(2)) is automatically enabled for
the new file descriptor.
size参数给出了bpf_attr联合体对象的字节长度。BPF_PROG_LOAD加载的命令可以用于创建和修改eBPF maps,maps是普通的key/value数据结构,用于在eBPF程序和内核空间或用户空间之间通信。其他命令允许将eBPF程序附加到一个控制组目录或socket文件描述符上,迭代所有的maps和程序,以及将eBPF对象固定到文件,这样在加载eBPF程序的进程结束后不会被销毁(后者由tc分类器/操作代码使用,因此可以将eBPF程序持久化,而不需要加载的进程保持活动状态)。完整的命令可以参考bpf()帮助文档。
虽然可能存在很多不同的命令,但大体可以分为两类:与eBPF程序交互的命令,与eBPF maps交互的命令,或同时与程序和maps交互的命令(统称为对象)。
1.7eBPF程序类型
使用BPF_PROG_LOAD加载的程序类型确定了四件事:附加的程序的位置,验证器允许调用的内核辅助函数,是否可以直接访问网络数据报文,以及传递给程序的第一个参数对象的类型。实际上,程序类型本质上定义了一个API。创建新的程序类型甚至纯粹是为了区分不同的可调用函数列表(例如,BPF_PROG_TYPE_CGROUP_SKB 和BPF_PROG_TYPE_SOCKET_FILTER)。
当前内核支持的eBPF程序类型为:
- BPF_PROG_TYPE_SOCKET_FILTER: a network packet filter
- BPF_PROG_TYPE_KPROBE: determine whether a kprobe should fire or not
- BPF_PROG_TYPE_SCHED_CLS: a network traffic-control classifier
- BPF_PROG_TYPE_SCHED_ACT: a network traffic-control action
- BPF_PROG_TYPE_TRACEPOINT: determine whether a tracepoint should fire or not
- BPF_PROG_TYPE_XDP: a network packet filter run from the device-driver receive path
- BPF_PROG_TYPE_PERF_EVENT: determine whether a perf event handler should fire or not
- BPF_PROG_TYPE_CGROUP_SKB: a network packet filter for control groups
- BPF_PROG_TYPE_CGROUP_SOCK: a network packet filter for control groups that is allowed to modify socket options
- BPF_PROG_TYPE_LWT_*: a network packet filter for lightweight tunnels
- BPF_PROG_TYPE_SOCK_OPS: a program for setting socket parameters
- BPF_PROG_TYPE_SK_SKB: a network packet filter for forwarding packets between sockets
- BPF_PROG_CGROUP_DEVICE: determine if a device operation should be permitted or not
随着新程序类型的增加,内核开发人员也会发现需要添加新的数据结构。
1.8eBPF数据结构
eBPF使用的主要的数据结构是eBPF map,这是一个通用的数据结构,用于在内核或内核和用户空间传递数据。其名称"map"也意味着数据的存储和检索需要用到key。
使用bpf()系统调用创建和管理map。当成功创建一个map后,会返回与该map关联的文件描述符。关闭相应的文件描述符的同时会销毁map。每个map定义了4个值:类型,元素最大数目,数值的字节大小,以及key的字节大小。eBPF提供了不同的map类型,不同类型的map提供了不同的特性。
- BPF_MAP_TYPE_HASH: a hash table
- BPF_MAP_TYPE_ARRAY: an array map, optimized for fast lookup speeds, often used for counters
- BPF_MAP_TYPE_PROG_ARRAY: an array of file descriptors corresponding to eBPF programs; used to implement jump tables and sub-programs to handle specific packet protocols
- BPF_MAP_TYPE_PERCPU_ARRAY: a per-CPU array, used to implement histograms of latency
- BPF_MAP_TYPE_PERF_EVENT_ARRAY: stores pointers to struct perf_event, used to read and store perf event counters
- BPF_MAP_TYPE_CGROUP_ARRAY: stores pointers to control groups
- BPF_MAP_TYPE_PERCPU_HASH: a per-CPU hash table
- BPF_MAP_TYPE_LRU_HASH: a hash table that only retains the most recently used items
- BPF_MAP_TYPE_LRU_PERCPU_HASH: a per-CPU hash table that only retains the most recently used items
- BPF_MAP_TYPE_LPM_TRIE: a longest-prefix match trie, good for matching IP addresses to a range
- BPF_MAP_TYPE_STACK_TRACE: stores stack traces
- BPF_MAP_TYPE_ARRAY_OF_MAPS: a map-in-map data structure
- BPF_MAP_TYPE_HASH_OF_MAPS: a map-in-map data structure
- BPF_MAP_TYPE_DEVICE_MAP: for storing and looking up network device references
- BPF_MAP_TYPE_SOCKET_MAP: stores and looks up sockets and allows socket redirection with BPF helper functions
所有的map都可以通过eBPF或在用户空间的程序中使用 bpf_map_lookup_elem() 和bpf_map_update_elem()函数进行访问。某些map类型,如socket map,会使用其他执行特殊任务的eBPF辅助函数。eBPF的更多细节可以参见官方帮助文档。
注: 在Linux4.4之前,bpf()要求调用者具有CAP_SYS_ADMIN capability权限,从Linux 4.4.开始,非特权用户可以使用BPF_PROG_TYPE_SOCKET_FILTER类型和相应的map创建受限的程序,然而这类程序无法将内核指针保存到map中,仅限于使用如下辅助函数: * get_random * get_smp_processor_id * tail_call * ktime_get_ns 可以通过sysctl禁用非特权访问: /proc/sys/kernel/unprivileged_bpf_disabled eBPF对象(maps和程序)可以在不同的进程间共享。例如,在fork之后,子进程会继承引用eBPF对象的文件描述符。此外,引用eBPF对象的文件描述符可以通过UNIX域socket传输。引用eBPF对象的文件描述符可以通过dup(2)和类似的调用进行复制。当所有引用对象的文件描述符关闭后,才会释放eBPF对象。eBPF程序可以使用受限的C语言进行编写,并使用clang编译器编译为eBPF字节码。受限的C语言会禁用很多特性,如循环,全局变量,浮点数以及使用结构体作为函数参数。可以在内核源码的samples/bpf/*_kern.c 文件中查看例子。 内核中的just-in-time (JIT)可以将eBPF字节码转换为机器码,提升性能。在Linux 4.15之前,默认会禁用JIT,可以通过修改/proc/sys/net/core/bpf_jit_enable启用JIT。
- 0 禁用JIT
- 1 正常编译
- 2 dehub模式。
从Linux 4.15开始,内核可能会配置CONFIG_BPF_JIT_ALWAYS_ON 选项,这种情况下,会启用JIT编译器,bpf_jit_enable 会被设置为1。
如下架构支持eBPF的JIT编译器:
- * x86-64 (since Linux 3.18; cBPF since Linux 3.0);
- * ARM32 (since Linux 3.18; cBPF since Linux 3.4);
- * SPARC 32 (since Linux 3.18; cBPF since Linux 3.5);
- * ARM-64 (since Linux 3.18);
- * s390 (since Linux 4.1; cBPF since Linux 3.7);
- * PowerPC 64 (since Linux 4.8; cBPF since Linux 3.1);
- * SPARC 64 (since Linux 4.12);
- * x86-32 (since Linux 4.18);
- * MIPS 64 (since Linux 4.18; cBPF since Linux 3.16);
- * riscv (since Linux 5.1)
1.9eBPF辅助函数
可以参考官方帮助文档查看libbpf库提供的辅助函数。
官方文档给出了现有的eBPF辅助函数。更多的实例可以参见内核源码的samples/bpf/和tools/testing/selftests/bpf/目录。
在官方帮助文档中有如下补充:
由于在编写帮助文档的同时,也同时在进行eBPF开发,因此新引入的eBPF程序或map类型可能没有及时添加到帮助文档中,可以在内核源码树中找到最准确的描述: include/uapi/linux/bpf.h:主要的BPF头文件。包含完整的辅助函数列表,以及对辅助函数使用的标记,结构体和常量的描述 net/core/filter.c:包含大部分与网络有关的辅助函数,以及使用的程序类型列表 kernel/trace/bpf_trace.c:包含大部分与程序跟踪有关的辅助函数 kernel/bpf/verifier.c:包含特定辅助函数使用的用于校验eBPF map有效性的函数 kernel/bpf/:该目录中的文件包含了其他辅助函数(如cgroups,sockmaps等)
如何编写eBPF程序
历史上,需要使用内核的bpf_asm汇编器将eBPF程序转换为BPF字节码。幸运的是,LLVM Clang编译器支持将C语言编写的eBPF后端编译为字节码。bpf()系统调用和BPF_PROG_LOAD命令可以直接加载包含这些字节码的对象文件。
可以使用C编写eBPF程序,并使用Clang的 -march=bpf参数进行编译。在内核的samples/bpf/ 目录下有很多eBPF程序的例子。大多数文件名中都有一个_kern.c后缀。Clang编译出的目标文件(eBPF字节码)需要由一个本机运行的程序进行加载(通常为使用_user.c开头的文件)。为了简化eBPF程序的编写,内核提供了libbpf库,可以使用辅助函数来加载,创建和管理eBPF对象。
例如,一个eBPF程序和使用libbpf的用户程序的大体流程为:
- 在用户程序中读取eBPF字节流,并将其传递给bpf_load_program()。
- 当在内核中运行eBPF程序时,将会调用bpf_map_lookup_elem()在一个map中查找元素,并保存一个新的值。
- 用户程序会调用 bpf_map_lookup_elem() 读取由eBPF程序保存的内核数据。
然而,大部分的实例代码都有一个主要的缺点:需要在内核源码树中编译自己的eBPF程序。幸运的是,BCC项目解决了这类问题。它包含了一个完整的工具链来编写并加载eBPF程序,而不需要链接到内核源码树。
二、eBPF框架
在开始说明之前先解释下eBPF上的名词,来帮忙更好的理解:
- eBPF bytecode:将C语言写的钩子代码,通过clang编译成二进制字节码,通过程序加载到内核中,钩子触发后在kernel "虚拟机"中运行。
- JIT: Just-in-time compilation,将字节码编译成本地机器码来提升运行速度,和Java中的概念类似。
- Maps:钩子代码可以将一些统计类信息保存在键值对的map中,来与用户空间程序进行通信,传递数据。
- 关于eBPF机制详细的讲解网上有很多,这里就不展开了,这里先上一张图,这里包括了使用或者编写ebpf涉及到的所有东西,下面会对这个图进行详细的讲解。
- ’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
- foo_kern.c 钩子实现代码,主要负责:
- 声明使用的Map节点
- 声明钩子挂载点及处理函数
通过LLVM/clang编译成字节码
- 编译命令:clang --target=bpf
- android平台有集成eBPF的编译,后文会提到
foo_user.c 用户空间处理函数,主要负责:
- 将foo_kern.c 编译成的字节码加载到kenel中
- 读取Map中的信息并处理输出给用户
kernel当收到eBPF的加载请求时,会先对字节码进行验证,并通过JIT编译为机器码,当钩子事件来临后,调用钩子函数,kernel会对加载的字节码进行验证,来保证系统的安全性,主要验证规则如下:
- a. 检查是否声明了GNU GPL,检查kernel的版本是否支持
- b. 函数调用规则:
允许bpf函数之间的相互调用
只允许调用kernel允许的BPF helper函数,具体可以参考linux/bpf.h文件
上述以外的函数及动态链接都是不允许的。
- c. 流程处理规则:
不允许使用loop循环以防止进入死循环卡死kernel
不允许有不可到达的分支代码
- d. 堆栈大小被限制在MAX_BPF_STACK范围内。
- e. 编译的字节码大小被限制在BPF_COMPLEXITY_LIMIT_INSNS范围内。
钩子挂载点,主要包括:
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
另外在kernel的源代码中samples/bpf目录下有大量的示例,感兴趣的可以阅读下。
三、eBPF在Android平台的使用
经过上面枯燥的讲解,大家应该对eBPF有了基础的认识,下面我们就来通过android平台上的一个监控性能的小例子来实操下。这个小例子的需求是统计系统中每个应用在一段时间内系统调用的次数。
3.1android系统对eBPF的编译支持
目前android编译系统已经对eBPF进行了集成,通过android.bp就能很方便的在android源代码中编译eBPF的字节码。
android.bp示例:
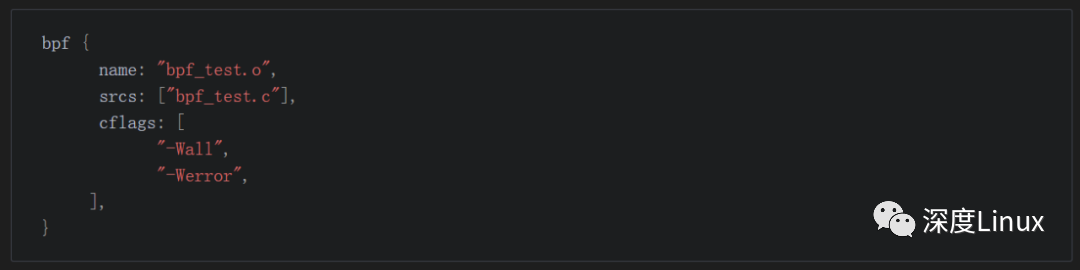
相关的编译代码在soong的bpf.go,虽然google关于soong的文档很少,但是至少代码是比较清晰的。
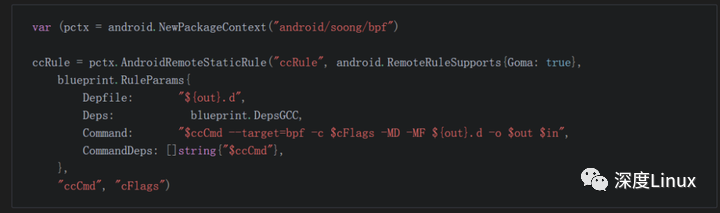
这里的$ccCmd一般是clang, 所以它的编译命令主要是clang --target=bpf。和普通的bpf编译没有区别。
3.2eBPF钩子代码实现
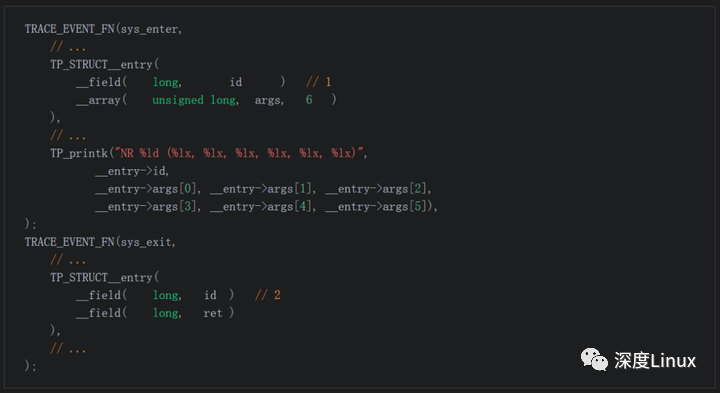
解决了编译问题,下一步我们开始实现钩子代码,我们准备使用tracepoint钩子,首先要找到我们需要的tracepoint函数sys_enter和sys_exit。函数定义在include/trace/events/syscalls.h文件sys_enter的trace参数是id 和长度为6的数组。
- sys_exit的trace参数是两个长整形数 id 和ret。
找到了钩子后,下一步就可以编写钩子处理代码了:
定义map保存系统调用统计信息,在DEFINE_BPF_MAP声明map的同时,也会生成删,改,查的宏函数,例如本例中会生成如下函数:
bpf_pid_syscall_map_lookup_elem
bpf_pid_syscall_map_update_elem
bpf_pid_syscall_map_delete_elem
- 定义回调函数参数类型,需要参考前面的tracepoint的定义。
- 指定监听的tracepoint事件。
- 使用bpf_trace_printk函数打印debug信息,会直接打印信息到ftrace中。
- 在map中查找指定key。
- 更新指定的key的值。
3.3加载钩子代码
我们只需要把我们编译出来的*.o文件push到手机的system/etc/bpf目录下,重启手机,系统会自动加载我们的钩子文件,加载成功后会在 /sys/fs/bpf目录下显示我们定义的map及prog文件。
系统加载代码在system/bpf/bpfloader中,代码很简单。
主要有如下操作:
1)在early-init阶段向下面两个节点写1
– /proc/sys/net/core/bpf_jit_enable
使能eBPF JIT,当内核设定BPF_JIT_ALWAYS_ON的时候,默认为1
– /proc/sys/net/core/bpf_jit_kallsyms
使特权用户可以通过kallsyms节点读取kernel的symbols
2)启动bpfloader service
– 读取system/etc/bpf目录下的*.o文件,调用libbpf_android.so中的loadProg函数加载进内核。
– 生成相应的/sys/fs/bpf/节点。
– 设置属性bpf.progs_loaded为1
sys节点分为map节点和prog节点两种, 分别为map_, prog_
下面是Android Q版本上的节点信息。

可以使用下面的命令调试动态加载

3.4用户空间程序实现
下面我们需要编写用户空间的显示程序,本质上就是在用户态通过系统调用把BPF map给读出来
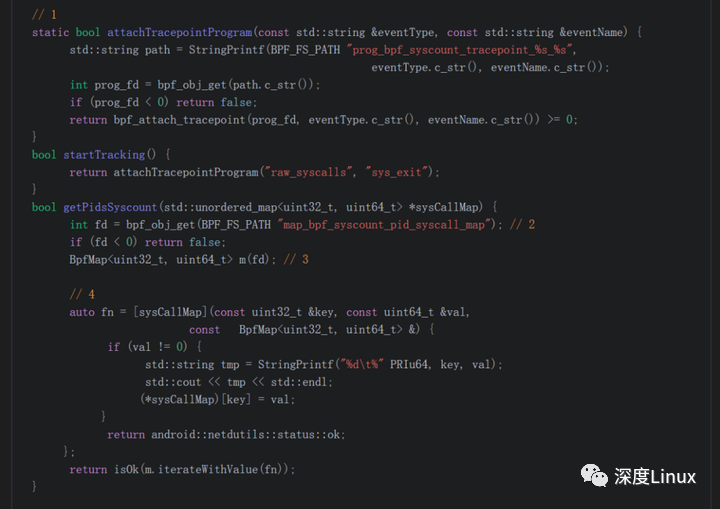
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
- 1)eBPF统计只有在调用bpf_attach_tracepoint只有才会起作用。bpf_attach_tracepoint是bcc里面的函数,android将bcc的一部分内容打包成了libbpf,放到了系统库里面。
- 2)取得map的fd, bpf_obj_get会直接调用bpf的系统调用。
- 3)将fd包装成BpfMap,android在BpfMap.h中定义了很多方便的函数。
- 4)遍历map回调函数。返回值必须是android::netdutils::status::ok(在android的新版本中已经进行修改)。
3.5 运行结果查看
直接在目录下执行mm,将编译出来的bpf.o push到/system/etc/bpf目录下,将统计程序push到/system/bin目录下,重启,看下结果。
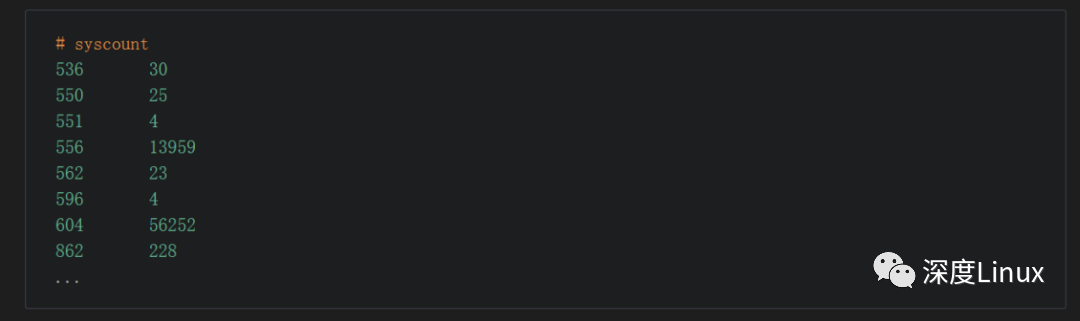
前面的是pid, 后面的是系统调用次数。至此,如何在android平台使用eBPF实现统计系统中每个pid在一段时间内系统调用的次数的功能就介绍完了。
此外还有很多技术细节没有深入研究,不过毕竟只是初探,就先讲到这里了,后续有时间再进一步深入研究。研究的时间还是比较短,如果有任何错误的地方欢迎指正。
四、seccomp 概述
下面内容来自Linux官方文档:
4.1历史
seccomp首个版本在2005年合入Linux 2.6.12版本。通过在 /proc/PID/seccomp中写入1启用该功能。一旦启用,进程只能使用4个系统调用read(), write(), exit()和sigreturn(),如果进程调用其他系统调用将会导致SIGKILL。该想法和补丁来自andreaarcangeli,作为一种安全运行他人代码的方法。然而,这个想法一直没有实现。
在2007年,内核2.6.23中改变了启用seccomp的方式。添加了 prctl()操作方式(PR_SET_SECCOMP和 SECCOMP_MODE_STRICT参数),并移除了 /proc 接口。PR_GET_SECCOMP操作的行为比较有趣:如果进程不处于seccomp模式,则会返回0,否则会发出SIGKILL信号(原因是prctl()不是一个允许的系统调用)。Kerrisk说,这证明了内核开发人员确实有幽默感。
在接下来的五年左右,seccomp领域的情况一直很平静,直到2012年linux3.5中加入了seccomp模式2(或“seccomp过滤模式”)。为seccomp添加了第二个模式:SECCOMP_MODE_FILTER。使用该模式,进程可以指定允许哪些系统调用。通过mini的BPF程序,进程可以限制整个系统调用或特定的参数值。现在已经有很多工具使用了seccomp过滤,包括 Chrome/Chromium浏览器, OpenSSH, vsftpd, 和Firefox OS。此外,容器中也大量使用了seccomp。
2013年的3.8内核版主中,在/proc/PID/status中添加了一个“Seccomp”字段。通过读取该字段,进程可以确定其seccomp模式(0为禁用,1为严格,2为过滤)。Kerrisk指出,进程可能需要从其他地方获取一个文件的文件描述符,以确保不会收到SIGKILL。
2014 年3.17版本中加入了 seccomp()系统调用(不会再使得prctl()系统调用变得更加复杂)。seccomp()系统调用提供了现有功能的超集。它还增加了将一个进程的所有线程同步到同一组过滤器的能力,有助于确保即使是在安装过滤器之前创建的线程也仍然受其影响。
4.2BPF
seccomp的过滤模式允许开发者编写BPF程序来根据传入的参数数目和参数值来决定是否可以运行某个给定的系统调用。只有值传递有效(BPF虚拟机不会取消对指针参数的引用)。
可以使用seccomp() 或prctl()安装过滤器。首先必须构造BPF程序,然后将其安装到内核。之后每次执行系统调用时都会触发过滤代码。也可以移除已经安装的过滤器(因为安装过滤器实际上是一种声明,表明任何后续执行的代码都是不可信的)。
BPF语言几乎早于Linux(Kerrisk)。首次出现在1992年,被用于tcpdump程序,用于监听网络报文。但由于报文数目比较大,因此将所有的报文传递到用于空间再进行过滤的代价相当大。BPF提供了一种内核层面的过滤,这样用户空间只需要处理其感兴趣的报文。
seccomp过滤器开发人员发现可以使用BPF实现其他类型的功能,后来BPF演化为允许过滤系统调用。内核中的小型内核内虚拟机用于解释一组简单的BPF指令。
BPF允许分支,但仅允许向前的分支,因此不能出现循环,通过这种方式保证出现能够结束。BPF程序的指令限制为4096个,且在加载期间完成有效性校验。此外,校验器可以保证程序能够正常退出,并返回一条指令,告诉内核针对该系统调用应该采取何种动作。
BPF的推广正在进行中,其中eBPF已经添加到了内核中,可以针对tracepoint(Linux 3.18)和raw socket(3.19)进行过滤,同时在4.1版本中合入了针对perf event的eBPF代码。
BPF有一个累加器寄存器,一个数据区(用于seccomp,包含系统调用的信息),以及一个隐式程序计数器。所有的指令都是64位长度,其中16比特用于操作码,两个8bit字段用于跳转目的地,以及一个32位的字段保存依赖操作码解析出的值。
BPF使用的基本的指令有:load,stora,jump,算术和逻辑运算,以及return。BPF支持条件和非条件跳转指令,后者使用32位字段作为其偏移量。条件跳转会在指令中使用两个跳转目的字段,每个字段都包含一个跳转偏移量(具体取决于跳转为true还是false)。
由于具有两个跳转目的,BPF可以简化条件跳转指令(例如,可以使用"等于时跳转",但不能使用"不等于时跳转"),如果需要另一种意义上的比较,可以将这两种偏移互换。目的地即是偏移量,0表示"不跳转"(执行下一跳指令),由于它们是8比特的值,最大支持跳转255条指令。正如前面所述,不允许负偏移量,避免循环。
给seccomp使用的BPF数据区(struct seccomp_data)有几个不同的字段来描述正在进行的系统调用:系统调用号,架构,指令指针,以及系统调用参数。它是一个只读buffer,程序无法修改。
4.3编写过滤器
可以使用常数和宏编写BPF程序,例如:
BPF_STMT(BPF_LD | BPF_W | BPF_ABS, (offsetof(struct seccomp_data, arch)))
上述命令将会创建一个加载(BPF_LD)字(BPF_W)的操作,使用指令中的值作为数据区的偏移量(BPF_ABS)。该值是architecture字段与数据区域的偏移量,因此最终结果是一条指令,该指令会根据架构加载累加器(来自AUDIT.h中的AUDIT_ARCH_*值)。下一条指令为:
BPF_JUMP(BPF_JMP | BPF_JEQ | BPF_K ,AUDIT_ARCH_X86_64 , 1, 0)
上述命令会创建一个jump-if-equal指令(BPF_JMP | BPF JEQ),将指令中的值(BPF_K)与累加器中的值进行比较。如果架构为x86-64,该跳转会忽略吓一跳指令(跳转的指令数为"1"),否则会继续执行(跳转为false,“0”)。
BPF程序应该首先对其架构进行校验,确保系统调用与程序所期望的一致。BPF程序可能是在与它允许的架构不同的架构上创建的。
一旦创建了过滤器,在每次系统调用时都会允许该程序,同时也会对性能造成一定影响。每个程序在退出时必须返回一条指令,否则,校验器会返回EINVAL。返回的内容为一个32位的数值。高16比特指定了内核的动作,其他比特返回与动作相关的数据。
程序可以返回5个动作:SECCOMP_RET_ALLOW表示允许运行系统调用;SECCOMP_RET_KILL表示终止进程,就像该进程由于SIGSYS(进程不会捕获到该信号)被杀死一样;SECCOMP_RET_ERRNO会告诉内核尝试通知一个ptrace()跟踪器,使其有机会获得控制权;SECCOMP_RET_TRAP告诉内核立即发送一个真实的SIGSYS信号,进程会在期望时捕获到该信号。
可以使用seccomp() (since Linux 3.17) 或prctl()安装BPF程序,这两种情况下都会传递一个 struct sock_fprog指针,包含指令数目和一个指向程序的指针。为了成功执行指令,调用者要么需要具有CAP_SYS_ADMIN权限,要么给进程设置PR_SET_NO_NEW_PRIVS属性(使用execve()执行新的程序时会忽略set-UID, set-GID, 和文件capabilities)。
如果过滤器运行程序调用 prctl() 或seccomp(),那么就可以安装更多的过滤器,它们将以与添加顺序相反的顺序运行,最终返回过滤器中具有最高优先级的值(KILL的优先级最高,ALLOW的优先级最低)。如果筛选器允许调用fork()、clone()和execve(),则会在调用这些命令时保留筛选器。
seccomp过滤器的两个主要用途是沙盒和故障模式测试。前者用于限制程序,特别是需要处理不可信输入的系统调用,通常会用到白名单。对于故障模式测试,可以使用seccomp给程序注入各种不可预期的错误来帮助查找bugs。
目前有很多工具和资源可以简化seccomp过滤器和BPF的开发。Libseccomp提供了一组高级API来创建过滤器。libseccomp项目给出了很多帮助文档,如seccomp_init()。
最后,内核有一个just-in-time (JIT)编译器,用于将BPF字节码转化为机器码,通过这种方式可以提升2-3倍的性能。JIT编译器默认是禁用的,可以通过在下面文件中写入1启用。
/proc/sys/net/core/bpf_jit_enable
4.4XDP
概述
XDP是Linux网络路径上内核集成的数据包处理器,具有安全、可编程、高性能的特点。当网卡驱动程序收到数据包时,该处理器执行BPF程序。XDP可以在数据包进入协议栈之前就进行处理,因此具有很高的性能,可用于DDoS防御、防火墙、负载均衡等领域。
XDP数据结构
XDP程序使用的数据结构是xdp_buff,而不是sk_buff,xdp_buff可以视为sk_buff的轻量级版本。两者的区别在于:sk_buff包含数据包的元数据,xdp_buff创建更早,不依赖与其他内核层,因此XDP可以更快的获取和处理数据包。
xdp_buff数据结构定义如下:
// /linux/include/net/xdp.h
struct xdp_rxq_info {
struct net_device *dev;
u32 queue_index;
u32 reg_state;
struct xdp_mem_info mem;
} ____cacheline_aligned; /* perf critical, avoid false-sharing */
struct xdp_buff {
void *data;
void *data_end;
void *data_meta;
void *data_hard_start;
unsigned long handle;
struct xdp_rxq_info *rxq;
};
sk_buff数据结构定义如下:
// /include/linux/skbuff.h
struct sk_buff {
union {
struct {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
union {
struct net_device *dev;
/* Some protocols might use this space to store information,
* while device pointer would be NULL.
* UDP receive path is one user.
*/
unsigned long dev_scratch;
};
};
struct rb_node rbnode; /* used in netem, ip4 defrag, and tcp stack */
struct list_head list;
};
union {
struct sock *sk;
int ip_defrag_offset;
};
union {
ktime_t tstamp;
u64 skb_mstamp_ns; /* earliest departure time */
};
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48] __aligned(8);
union {
struct {
unsigned long _skb_refdst;
void (*destructor)(struct sk_buff *skb);
};
struct list_head tcp_tsorted_anchor;
};
#if defined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
unsigned long _nfct;
#endif
unsigned int len,
data_len;
__u16 mac_len,
hdr_len;
/* Following fields are _not_ copied in __copy_skb_header()
* Note that queue_mapping is here mostly to fill a hole.
*/
__u16 queue_mapping;
/* if you move cloned around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define CLONED_MASK (1 << 7)
#else
#define CLONED_MASK 1
#endif
#define CLONED_OFFSET() offsetof(struct sk_buff, __cloned_offset)
__u8 __cloned_offset[0];
__u8 cloned:1,
nohdr:1,
fclone:2,
peeked:1,
head_frag:1,
xmit_more:1,
pfmemalloc:1;
#ifdef CONFIG_SKB_EXTENSIONS
__u8 active_extensions;
#endif
/* fields enclosed in headers_start/headers_end are copied
* using a single memcpy() in __copy_skb_header()
*/
/* private: */
__u32 headers_start[0];
/* public: */
/* if you move pkt_type around you also must adapt those constants */
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_TYPE_MAX (7 << 5)
#else
#define PKT_TYPE_MAX 7
#endif
#define PKT_TYPE_OFFSET() offsetof(struct sk_buff, __pkt_type_offset)
__u8 __pkt_type_offset[0];
__u8 pkt_type:3;
__u8 ignore_df:1;
__u8 nf_trace:1;
__u8 ip_summed:2;
__u8 ooo_okay:1;
__u8 l4_hash:1;
__u8 sw_hash:1;
__u8 wifi_acked_valid:1;
__u8 wifi_acked:1;
__u8 no_fcs:1;
/* Indicates the inner headers are valid in the skbuff. */
__u8 encapsulation:1;
__u8 encap_hdr_csum:1;
__u8 csum_valid:1;
#ifdef __BIG_ENDIAN_BITFIELD
#define PKT_VLAN_PRESENT_BIT 7
#else
#define PKT_VLAN_PRESENT_BIT 0
#endif
#define PKT_VLAN_PRESENT_OFFSET() offsetof(struct sk_buff, __pkt_vlan_present_offset)
__u8 __pkt_vlan_present_offset[0];
__u8 vlan_present:1;
__u8 csum_complete_sw:1;
__u8 csum_level:2;
__u8 csum_not_inet:1;
__u8 dst_pending_confirm:1;
#ifdef CONFIG_IPV6_NDISC_NODETYPE
__u8 ndisc_nodetype:2;
#endif
__u8 ipvs_property:1;
__u8 inner_protocol_type:1;
__u8 remcsum_offload:1;
#ifdef CONFIG_NET_SWITCHDEV
__u8 offload_fwd_mark:1;
__u8 offload_l3_fwd_mark:1;
#endif
#ifdef CONFIG_NET_CLS_ACT
__u8 tc_skip_classify:1;
__u8 tc_at_ingress:1;
__u8 tc_redirected:1;
__u8 tc_from_ingress:1;
#endif
#ifdef CONFIG_TLS_DEVICE
__u8 decrypted:1;
#endif
#ifdef CONFIG_NET_SCHED
__u16 tc_index; /* traffic control index */
#endif
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority;
int skb_iif;
__u32 hash;
__be16 vlan_proto;
__u16 vlan_tci;
#if defined(CONFIG_NET_RX_BUSY_POLL) || defined(CONFIG_XPS)
union {
unsigned int napi_id;
unsigned int sender_cpu;
};
#endif
#ifdef CONFIG_NETWORK_SECMARK
__u32 secmark;
#endif
union {
__u32 mark;
__u32 reserved_tailroom;
};
union {
__be16 inner_protocol;
__u8 inner_ipproto;
};
__u16 inner_transport_header;
__u16 inner_network_header;
__u16 inner_mac_header;
__be16 protocol;
__u16 transport_header;
__u16 network_header;
__u16 mac_header;
/* private: */
__u32 headers_end[0];
/* public: */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize;
refcount_t users;
#ifdef CONFIG_SKB_EXTENSIONS
/* only useable after checking ->active_extensions != 0 */
struct skb_ext *extensions;
#endif
};
4.5XDP与eBPF的关系
XDP程序是通过bpf()系统调用控制的,bpf()系统调用使用程序类型BPF_PROG_TYPE_XDP进行加载。
XDP操作模式
XDP支持3种工作模式,默认使用native模式:
- Native XDP:在native模式下,XDP BPF程序运行在网络驱动的早期接收路径上(RX队列),因此,使用该模式时需要网卡驱动程序支持。
- Offloaded XDP:在Offloaded模式下,XDP BFP程序直接在NIC(Network Interface Controller)中处理数据包,而不使用主机CPU,相比native模式,性能更高
- Generic XDP:Generic模式主要提供给开发人员测试使用,对于网卡或驱动无法支持native或offloaded模式的情况,内核提供了通用的generic模式,运行在协议栈中,不需要对驱动做任何修改。生产环境中建议使用native或offloaded模式
XDP操作结果码
- XDP_DROP:丢弃数据包,发生在驱动程序的最早RX阶段
- XDP_PASS:将数据包传递到协议栈处理,操作可能为以下两种形式:1、正常接收数据包,分配愿数据sk_buff结构并且将接收数据包入栈,然后将数据包引导到另一个CPU进行处理。他允许原始接口到用户空间进行处理。这可能发生在数据包修改前或修改后。2、通过GRO(Generic receive offload)方式接收大的数据包,并且合并相同连接的数据包。经过处理后,GRO最终将数据包传入“正常接收”流
- XDP_TX:转发数据包,将接收到的数据包发送回数据包到达的同一网卡。这可能在数据包修改前或修改后发生
- XDP_REDIRECT:数据包重定向,XDP_TX,XDP_REDIRECT是将数据包送到另一块网卡或传入到BPF的cpumap中
- XDP_ABORTED:表示eBPF程序发生错误,并导致数据包被丢弃。自己开发的程序不应该使用该返回码
XDP和iproute2加载器
iproute2工具中提供的ip命令可以充当XDP加载器的角色,将XDP程序编译成ELF文件并加载他。
- 编写XDP程序xdp_filter.c,程序功能为丢弃所有TCP连接包,程序将xdp_md结构指针作为输入,相当于驱动程序xdp_buff的BPF结构。程序的入口函数为filter,编译后ELF文件的区域名为mysection。
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/tcp.h>
#define SEC(NAME) __attribute__((section(NAME), used))
SEC("mysection")
int filter(struct xdp_md *ctx) {
int ipsize = 0;
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
struct iphdr *ip;
ipsize = sizeof(*eth);
ip = data + ipsize;
ipsize += sizeof(struct iphdr);
if (data + ipsize > data_end) {
return XDP_DROP;
}
if (ip->protocol == IPPROTO_TCP) {
return XDP_DROP;
}
return XDP_PASS;
}
- 将XDP程序编译为ELF文件
clang -O2 -target bpf -c xdp_filter.c -o xdp_filter.o
- 使用ip命令加载XDP程序,将mysection部分作为程序的入口点
sudo ip link set dev ens33 xdp obj xdp_filter.o sec mysection
没有报错即完成加载,可以通过以下命令查看结果:
$ sudo ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdpgeneric/id:56 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:2f:a8:41 brd ff:ff:ff:ff:ff:ff
inet 192.168.136.140/24 brd 192.168.136.255 scope global dynamic noprefixroute ens33
valid_lft 1629sec preferred_lft 1629sec
inet6 fe80::d411:ff0d:f428:ce2a/64 scope link noprefixroute
valid_lft forever preferred_lft forever
其中,xdpgeneric/id:56说明使用的驱动程序为xdpgeneric,XDP程序id为56
- 验证连接阻断效果
- 使用nc -l 8888监听8888 TCP端口,使用nc xxxxx 8888连接发送数据,目标主机未收到任何数据,说明TCP连接阻断成功
- 使用nc -kul 9999监听UDP 9999端口,使用nc -u xxxxx 9999连接发送数据,目标主机正常收到数据,说明UDP连接不受影响
- 卸载XDP程序
$ sudo ip link set dev ens33 xdp off
卸载后,连接8888端口,发送数据,通信正常。
XDP和BCC
编写C代码xdp_bcc.c,当TCP连接目的端口为9999时DROP:
#define KBUILD_MODNAME "program"
#include <linux/bpf.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/tcp.h>
int filter(struct xdp_md *ctx) {
int ipsize = 0;
void *data = (void *)(long)ctx->data;
void *data_end = (void *)(long)ctx->data_end;
struct ethhdr *eth = data;
struct iphdr *ip;
ipsize = sizeof(*eth);
ip = data + ipsize;
ipsize += sizeof(struct iphdr);
if (data + ipsize > data_end) {
return XDP_DROP;
}
if (ip->protocol == IPPROTO_TCP) {
struct tcphdr *tcp = (void *)ip + sizeof(*ip);
ipsize += sizeof(struct tcphdr);
if (data + ipsize > data_end) {
return XDP_DROP;
}
if (tcp->dest == ntohs(9999)) {
bpf_trace_printk("drop tcp dest port 9999\n");
return XDP_DROP;
}
}
return XDP_PASS;
}
与使用ip命令加载XDP程序类似,这里编写python加载程序实现对XDP程序的编译和内核注入。
#!/usr/bin/python
from bcc import BPF
import time
device = "ens33"
b = BPF(src_file="xdp_bcc.c")
fn = b.load_func("filter", BPF.XDP)
b.attach_xdp(device, fn, 0)
try:
b.trace_print()
except KeyboardInterrupt:
pass
b.remove_xdp(device, 0)
验证效果,使用nc测试,无法与目标主机9999端口实现通信
$ sudo python xdp_bcc.py
<idle>-0 [003] ..s. 22870.984559: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22871.987644: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22872.988840: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22873.997261: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22875.000567: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22876.002998: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22878.005414: 0: drop tcp dest port 9999
<idle>-0 [003] ..s. 22882.018119: 0: drop tcp dest port 9999
4.5Rings
有4类不同类型的ring:FILL, COMPLETION, RX 和TX,所有的ring都是单生产者/单消费者,因此用户空间的程序需要显示地同步对这些rings进行读/写的多进程/线程。
UMEM使用2个ring:FILL和COMPLETION。每个关联到UMEM的socket必须有1个RX队列,1个TX队列或同时拥有2个队列。如果配置了4个socket(同时使用TX和RX),那么此时会有1个FILL ring,1个COMPLETION ring,4个TX ring和4个RX ring。
ring是基于首(生产者)尾(消费者)的结构。一个生产者会在结构体xdp_ring的producer成员指出的ring索引处写入数据,并增加生产者索引;一个消费者会结构体xdp_ring的consumer成员指出的ring索引处读取数据,并增加消费者索引。
可以通过_RING setsockopt系统调用配置和创建ring,使用mmap(),并结合合适的偏移量,将其映射到用户空间
ring的大小需要是2次幂。
4.6UMEM Fill Ring
FILL ring用于将UMEM帧从用户空间传递到内核空间,同时将UMEM地址传递给ring。例如,如果UMEM的大小为64k,且每个chunk的大小为4k,那么UMEM包含16个chunk,可以传递的地址为0到64k。
传递给内核的帧用于ingress路径(RX rings)。
用户应用也会在该ring中生成UMEM地址。注意,如果以对齐的chunk模式运行应用,则内核会屏蔽传入的地址。即,如果一个chunk大小为2k,则会屏蔽掉log2(2048) LSB的地址,意味着2048, 2050 和3000都将引用相同的chunk。如果用户应用使用非对其的chunk模式运行,那么传入的地址将保持不变。
4.7UMEM Completion Ring
COMPLETION Ring用于将UMEM帧从内核空间传递到用户空间,与FILL ring相同,使用了UMEM索引。
已经发送的从内核空间传递到用户空间的帧还可以被用户空间使用。
用户应用会消费该ring种的UMEM地址。
4.8RX Ring
RX ring位于socket的接收侧,ring中的每个表项都是一个xdp_desc 结构的描述符。该描述符包含UMEM偏移量(地址)以及数据的长度。
如果没有帧从FILL ring传递给内核,则RX ring中不会出现任何描述符。
用户程序会消费该ring中的xdp_desc描述符。
4.9TX Ring
TX Ring用于发送帧。在填充xdp_desc(索引,长度和偏移量)描述符后传递给该ring。
如果要启动数据传输,则必须调用sendmsg(),未来可能会放宽这种限制。
用户程序会给TX ring生成xdp_desc 描述符。
4.10XSKMAP / BPF_MAP_TYPE_XSKMAP
在XDP侧会用到类型为BPF_MAP_TYPE_XSKMAP 的BPF map,并结合bpf_redirect_map()将ingress帧传递给socket。
用户应用会通过bpf()系统调用将socket插入该map。
注意,如果一个XDP程序尝试将帧重定向到一个与队列配置和netdev不匹配的socket时,会丢弃该帧。即,如果一个AF_XDP socket绑定到一个名为eth0,队列为17的netdev上时,只有当XDP程序指定到eth0且队列为17时,才会将数据传递给该socket。参见samples/bpf/获取例子
4.11配置标志位和socket选项
XDP_COPY 和XDP_ZERO_COPY bind标志
当绑定到一个socket时,内核会首先尝试使用零拷贝进行拷贝。如果不支持零拷贝,则会回退为使用拷贝模式。即,将所有的报文拷贝到用户空间。但如果想强制指定一种特定的模式,则可以使用如下标志:如果给bind调用传递了XDP_COPY,则内核将强制进入拷贝模式;如果没有使用拷贝模式,则bind调用会失败,并返回错误。相反地,XDP_ZERO_COPY 将强制socket使用零拷贝或调用失败。
XDP_SHARED_UMEM bind 标志
该表示可以使多个socket绑定到系统的UMEM,但仅能使用系统的队列id。这种模式下,每个socket都有其各自的RX和TX ring,但UMEM只能有一个FILL ring和一个COMPLETION ring。为了使用这种模式,需要创建第一个socket,并使用正常模式进行绑定。然后创建第二个socket,含一个RX和一个TX(或二者之一),但不会创建FILL 或COMPLETION ring(与第一个socket共享)。在bind调用中,设置XDP_SHARED_UMEM选项,并在sxdp_shared_umem_fd中提供初始socket的fd。以此类推。
那么当接收到一个报文后,应该上送到那个socket呢?答案是由XDP程序来决定。将所有的socket放到XDP_MAP中,然后将报文发送给数组中索引对应的socket。下面展示了一个简单的以轮询方式分发报文的例子:
#include <linux/bpf.h>
#include "bpf_helpers.h"
#define MAX_SOCKS 16
struct {
__uint(type, BPF_MAP_TYPE_XSKMAP);
__uint(max_entries, MAX_SOCKS);
__uint(key_size, sizeof(int));
__uint(value_size, sizeof(int));
} xsks_map SEC(".maps");
static unsigned int rr;
SEC("xdp_sock") int xdp_sock_prog(struct xdp_md *ctx)
{
rr = (rr + 1) & (MAX_SOCKS - 1);
return bpf_redirect_map(&xsks_map, rr, XDP_DROP);
}
注意,由于只有一个FILL和一个COMPLETION ring,且是单生产者单消费者的ring,需要确保多处理器或多线程不会同时使用这些ring。libbpf没有提供原子同步功能。
当多个socket绑定到相同的umem时,libbpf会使用这种模式。然而,需要注意的是,需要在xsk_socket__create调用中提供XSK_LIBBPF_FLAGS__INHIBIT_PROG_LOAD libbpf_flag,然后将其加载到自己的XDP程序中(因为libbpf没有内置路由流量功能)。
XDP_USE_NEED_WAKEUP bind标志
该选择支持在FILL ring和TX ring中设置一个名为need_wakeup的标志,用户空间作为这些ring的生产者。当在bind调用中设置了该选项,如果需要明确地通过系统调用唤醒内核来继续处理报文时,会设置need_wakeup 标志。
如果将该标志设置给FILL ring,则应用需要调用poll(),以便在RX ring上继续接收报文。如,当内核检测到FILL ring中没有足够的buff,且NIC的RX HW RING中也没有足够的buffer时会发生这种情况。此时会关中断,这样NIC就无法接收到任何报文(由于没有足够的buffer),由于设置了need_wakeup,这样用户空间就可以在FILL ring上增加buffer,然后调用poll(),这样内核驱动就可以将这些buffer添加到HW ring上继续接收报文。
如果将该标志设置给TX ring,意味着应用需要明确地通知内核发送位于TX ring上的报文。可以通过调用poll(),或调用sendto()完成。
可以在samples/bpf/xdpsock_user.c中找到例子。在TX路径上使用libbpf辅助函数的例子如下:
if (xsk_ring_prod__needs_wakeup(&my_tx_ring))
sendto(xsk_socket__fd(xsk_handle), NULL, 0, MSG_DONTWAIT, NULL, 0);
建议启用该模式,由于减少了TX路径上的系统调用的数目,因此可以在应用和驱动运行在同一个(或不同)core的情况下提升性能。
XDP_{RX|TX|UMEM_FILL|UMEM_COMPLETION}_RING setsockopts
这些socket选项分别设置RX, TX, FILL和COMPLETION ring的描述符数量(必须至少设置RX或TX ring的描述符大小)。如果同时设置了RX和TX,就可以同时接收和发送来自应用的流量;如果仅设置了其中一个,就可以节省相应的资源。如果需要将一个UMEM绑定到socket,需要同时设置FILL ring和COMPLETION ring。如果使用了XDP_SHARED_UMEM标志,无需为除第一个socket之外的socket创建单独的UMEM,所有的socket将使用共享的UMEM。注意ring为单生产者单消费者结构,因此多进程无法同时访问同一个ring。参见XDP_SHARED_UMEM章节。
使用libbpf时,可以通过给xsk_socket__create函数的rx和tx参数设置NULL来创建Rx-only和Tx-only的socket。
如果创建了一个Tx-only的socket,建议不要在FILL ring中放入任何报文,否则,驱动可能会认为需要接收数据(但实际上并不是这样的),进而影响性能。
XDP_UMEM_REG setsockopt
该socket选项会给一个socket注册一个UMEM,其对应的区域包含了可以容纳报文的buffer。该调用会使用一个指向该区域开始处的指针,以及该区域的大小。此外,还有一个UMEM可以切分的chunk大小参数(目前仅支持2K或4K)。如果一个UMEM区域的大小为128K,且chunk大小为2K,意味着该UMEM域最大可以有128K / 2K = 64个报文,且最大的报文大小为2K。
还有一个选项可以在UMEM中设置每个buffer的headroom。如果设置为N字节,意味着报文会从buffer的第N个字节开始,为应用保留前N个字节。最后一个选项为标志位字段,会在每个UMEM标志中单独处理。
XDP_STATISTICS getsockopt
获取一个socket丢弃信息,用于调试。支持的信息为:
struct xdp_statistics {
__u64 rx_dropped; /* Dropped for reasons other than invalid desc */
__u64 rx_invalid_descs; /* Dropped due to invalid descriptor */
__u64 tx_invalid_descs; /* Dropped due to invalid descriptor */
};
XDP_OPTIONS getsockopt
获取一个XDP socket的选项。目前仅支持XDP_OPTIONS_ZEROCOPY,用于检查是否使用了零拷贝。
从AF_XDP的特性上可以看到其局限性:不能使用XDP将不同的流量重定向的多个AF_XDP socket上,原因是每个AF_XDP socket必须绑定到物理接口的TX队列上。大多数的物理和仿真HW的每个接口仅支持一个RX/TX队列,因此当该接口上绑定了一个AF_XDP后,后续的绑定操作都将失败。仅有少数HW支持多RX/TX队列,且通常仅有2/4/8个队列,无法扩展给cloud中的上百个容器使用。
更多细节参见AF_XDP官方文档以及这篇论文。
五、TC
除了XDP,BPF还可以在网络数据路径的内核tc(traffic control)层之外使用。上文已经给出了XDP和TC的区别。
- ingress hook:__netif_receive_skb_core() -> sch_handle_ingress()
- egress hook:__dev_queue_xmit() -> sch_handle_egress()
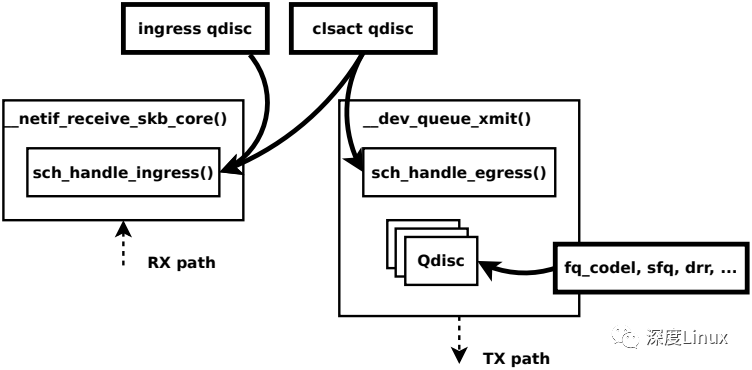
运行在tc层的BPF程序使用的是 cls_bpf (cls即Classifiers的简称)分类器。在tc中,将BPF的附着点描述为一个"分类器",这个词有点误导,因此它少描述了cls_bpf的所支持的功能。即一个完整的可编程的报文处理器不仅可以读取skb的元数据和报文数据,还可以对其进行任意修改,最后终止tc的处理,并返回裁定的action(见下)。cls_bpf可以认为是一个自包含的,可以管理和执行tc BPF程序的实体。
cls_bpf可以包含一个或多个tc BPF程序。通常,在传统的tc方案中,分类器和action模块是分开的,每个分类器可以附加一个或多个action,一旦匹配到分类器时就会执行action。但在现代软件数据路径中使用这种模式的tc处理复杂的报文时会遇到扩展性问题。由于附加到cls_bpf的tc BPF程序是完全自包含的,因此可以有效地将解析和操作过程融合到一个单元中。幸好有了cls_bpf的direct-action模式,该模式下,仅需要返回tc action裁定结果并立即结束处理流即可,可以在网络数据流中实现可扩展的可编程报文处理流程,同时避免了action的线性迭代。cls_bpf是tc层中唯一能够实现这种快速路径的“分类器”模块。
与XDP BPF程序类似,tc BPF程序可以在运行时通过cls_bpf自动更新,而不会中断任何网络流或重启服务。
cls_bpf可以附加的tc ingress和egree钩子都通过一个名为sch_clsact的伪qdisc进行管理。由于该伪qdisc可以同时管理ingress和egress的tc钩子,因此它是ingress qdisc的超集(也可直接替换)。对于__dev_queue_xmit()中的tc的egress钩子,需要注意的是,它不是在内核的qdisc root锁下运行的。因此,tc ingress和egress钩子都以无锁的方式运行在快速路径中,且这两个钩子都禁用了抢占,并运行在RCU读取侧。
通常在egress上会存在附着到网络设备上的qdisc,如sch_mq,sch_fq,sch_fq_codel或sch_htb,其中有些是可分类的qdisc(包含子类),因此会要求一个报文分类机制来决定在哪里解复用数据包。该过程通过调用tcf_classify()进行处理,进而调用tc分类器(如果存在)。cls_bpf也可以附加并用于如下场景:一些在qdisc root锁下的操作可能会收到锁竞争的影响。sch_clsact qdisc的egress钩子出现在更早的时间点,但它不属于这个锁的范围,因此作完全独立于常规的egress qdiscs。因此,对于sch_htb这样的情况,sch_clsact qdisc可以通过qdisc root锁之外的tc BPF执行繁重的包分类工作,通过在这些 tc BPF 程序中设置 skb->mark 或 skb->priority ,这样 sch_htb 只需要一个简单的映射即可,不需要在root锁下执行代价高昂的报文分类工作,通过这种方式可以减少锁竞争。
在sch_clsact结合cls_bpf的场景下支持offloaded tc BPF程序,这种情况下,先前加载的BPF程序是从SmartNIC驱动程序jit生成的,以便在NIC上以本机方式运行。只有在direct-action模式下运行的cls_bpf程序才支持offloaded。cls_bpf仅支持offload一个单独的程序(无法offload多个程序),且只有ingress支持offload BPF程序。
一个cls_bpf实例可以包含多个tc BPF程序,如果是这种情况,那么TC_ACT_UNSPEC程序返回码可以继续执行列表中的下一个tc BPF程序。然而,这样做的缺点是,多个程序需要多次解析相同的报文,导致性能下降。
5.1返回码
tc的ingress和egress钩子共享相同的action来返回tc BPF程序使用的裁定结果,定义在 linux/pkt_cls.h系统头文件中:
#define TC_ACT_UNSPEC (-1)
#define TC_ACT_OK 0
#define TC_ACT_SHOT 2
#define TC_ACT_STOLEN 4
#define TC_ACT_REDIRECT 7
系统头文件中还有一些以TC_ACT_*开头的action变量,可以被两个钩子使用。但它们与上面的语义相同。即,从tc BPF的角度来看TC_ACT_OK和TC_ACT_RECLASSIFY的语义相同,三个TC_ACT_stelled、TC_ACT_QUEUED和TC_ACT_TRAP操作码的语义也是相同的。因此,对于这些情况,我们只描述 TC_ACT_OK 和 TC_ACT_STOLEN 操作码。
从TC_ACT_UNSPEC开始,表示"未指定的action",用于以下三种场景:i)当一个offloaded tc程序的tc ingress钩子运行在cls_bpf的位置,则该offloaded程序将返回TC_ACT_UNSPEC;ii)为了在多程序场景下继续执行cls_bpf中的下一个BPF程序,后续的程序需要与步骤i中的offloaded tc BPF程序配合使用,但出现了一个非offloaded场景下运行的tc BPF程序;iii)TC_ACT_UNSPEC还可以用于单个程序场景,用于告诉内核继续使用skb,不会产生其他副作用。TC_ACT_UNSPEC与TC_ACT_OK类似,两者都会将skb通过ingress向上传递到网络栈的上层,或者通过egress向下传递到网络设备驱动程序,以便在egress进行传输。与TC_ACT_OK的唯一不同之处是,TC_ACT_OK基于tc BPF程序设定的classid来设置skb->tc_index,而 TC_ACT_UNSPEC 是通过 tc BPF 程序之外的 BPF上下文中的 skb->tc_classid 进行设置。
TC_ACT_SHOT通知内核丢弃报文,即网络栈上层将不会在ingress的skb中看到该报文,类似地,这类报文也不会在egress中发送。TC_ACT_SHOT和TC_ACT_STOLEN本质上是相似的,仅存在部分差异:TC_ACT_SHOT会通知内核已经通过kfree_skb()释放skb,且会立即给调用者返回NET_XMIT_DROP;而TC_ACT_STOLEN会通过consume_skb()释放skb,并给上层返回NET_XMIT_SUCCESS,假装传输成功。perf的报文丢弃监控会记录kfree_skb()的操作,因此不会记录任何因为TC_ACT_STOLEN丢弃的报文,因为从语义上说,这些 skb 是被消费或排队的而不是被丢弃的。
最后TC_ACT_REDIRECT action允许tc BPF程序通过bpf_redirect()辅助函数将skb重定向到相同或不同的设备ingress或egress路径上。通过将报文导入其他设备的ingress或egress方向,可以最大化地实现BPF的报文转发功能。使用该方式不需要对目标网络设备做任何更改,也不需要在目标设备上运行另外一个cls_bpf实例。
5.2加载tc BPF程序
假设有一个名为prog.o的tc BPF程序,可以通过tc命令将该程序加载到网络设备山。与XDP不同,它不需要依赖驱动将BPF程序附加到设备上,下面会用到一个名为em1的网络设备,并将程序附加到em1的ingress报文路径上。
# tc qdisc add dev em1 clsact
# tc filter add dev em1 ingress bpf da obj prog.o
第一步首先配置一个clsact qdisc。如上文所述,clsact是一个伪造的qdisc,与ingress qdisc类似,仅包含分类器和action,但不会提供实际的队列功能,它是附加bpf分类器所必需的。clsact 提供了两个特殊的钩子,称为ingress和egress,分类器可以附加到这两个钩子上。ingress和egress钩子都位于网络数据路径的中央接收和发送位置,每个经过设备的报文都会经过此处。ingees钩子通过内核的__netif_receive_skb_core() -> sch_handle_ingress()进行调用,egress钩子通过__dev_queue_xmit() -> sch_handle_egress()进行调用。
将程序附加到egress钩子上的操作为:
# tc filter add dev em1 egress bpf da obj prog.o
clsact qdisc以无锁的方式处理来自ingress和egress方向的报文,且可以附加到一个无队列虚拟设备上,如连接到容器的veth设备。
在钩子之后,tc filter命令选择使用bpf的da(direct-action)模式。推荐使用并指定da模式,基本上意味着bpf分类器不再需要调用外部tc action模块,所有报文的修改,转发或其他action都可以通过附加的BPF程序来实现,因此处理速度更快。
到此位置,已经附加bpf程序,一旦有报文传输到该设备后就会执行该程序。与XDP相同,如果不使用默认的section名称,则可以在加载期间进行指定,例如,下面指定的section名为foobar:
# tc filter add dev em1 egress bpf da obj prog.o sec foobar
iptables2的BPF加载器允许跨程序类型使用相同的命令行语法。
附加的程序可以使用如下命令列出:
# tc filter show dev em1 ingress
filter protocol all pref 49152 bpf
filter protocol all pref 49152 bpf handle 0x1 prog.o:[ingress] direct-action id 1 tag c5f7825e5dac396f
# tc filter show dev em1 egress
filter protocol all pref 49152 bpf
filter protocol all pref 49152 bpf handle 0x1 prog.o:[egress] direct-action id 2 tag b2fd5adc0f262714
prog.o:[ingress]的输出说明程序段ingress通过文件prog.o进行加载,且bpf运行在direct-action模式下。上面两种情况附加了程序id和tag,其中后者表示对指令流的hash,该hash可以与目标文件或带有堆栈跟踪的perf report等相关。最后,id表示系统范围内的BPF程序的唯一标识符,可以使用bpftool来查看或dump附加的BPF程序。
tc可以附加多个BPF程序,它提供了其他可以链接在一起的分类器。但附加一个BPF程序已经可以完全满足需求,因为通过da(direct-action)模式可以在一个程序中实现所有的报文操作,意味着BPF程序将返回tc action裁定结果,如TC_ACT_OK, TC_ACT_SHOT等。为了获得最佳性能和灵活性,推荐使用这种方式。
在上述show命令中,在BPF的相关输出旁显示了pref 49152 和handle 0x1。如果没有通过命令行显式地提供,会自动生成的这两个输出。perf表明了一个优先级数字,即当附加了多个分类器时,将会按照优先级上升的顺序执行这些分类器。handle表示一个标识符,当一个perf加载了系统分类器的多个实例时起作用。由于在BPF场景下,一个程序足矣,perf和handle通常可以忽略。
只有在需要自动替换附加的BPF程序的情况下,才会推荐在初始化加载前指定pref和handle,这样在以后执行replace操作时就不必在进行查询。创建方式如下:
# tc filter add dev em1 ingress pref 1 handle 1 bpf da obj prog.o sec foobar
# tc filter show dev em1 ingress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 prog.o:[foobar] direct-action id 1 tag c5f7825e5dac396f
对于原子替换,可以使用(来自文件prog.o中的foobar section的BPF程序)如下命令来更新现有的ingress钩子上的程序
# tc filter replace dev em1 ingress pref 1 handle 1 bpf da obj prog.o sec foobar
最后,为了移除所有ingress和egress上附加的程序,可以使用如下命令:
# tc filter del dev em1 ingress
# tc filter del dev em1 egress
为了移除网络设备上的整个clsact qdisc,即移除掉ingress和egress钩子上附加的所有程序,可以使用如下命令:
# tc qdisc del dev em1 clsact
如果NIC和驱动也像XDP BPF程序一样支持offloaded,则tc BPF程序也可以是offloaded的。Netronome的nfp同时支持两种类型的BPF offload。
# tc qdisc add dev em1 clsact
# tc filter replace dev em1 ingress pref 1 handle 1 bpf skip_sw da obj prog.o
Error: TC offload is disabled on net device.
We have an error talking to the kernel
如果出现了如上错误,则表示首先需要通过ethtool的hw-tc-offload来启动tc硬件offload:
# ethtool -K em1 hw-tc-offload on
# tc qdisc add dev em1 clsact
# tc filter replace dev em1 ingress pref 1 handle 1 bpf skip_sw da obj prog.o
# tc filter show dev em1 ingress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 prog.o:[classifier] direct-action skip_sw in_hw id 19 tag 57cd311f2e27366b
in_hw标志表示程序已经offload到了NIC中,注意不能同时offload tc和XDP BPF,必须且只能选择其中之一。
版权声明:本文为微信公众号「深度Linux」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
f handle 0x1 prog.o:[foobar] direct-action id 1 tag c5f7825e5dac396f
对于原子替换,可以使用(来自文件prog.o中的foobar section的BPF程序)如下命令来更新现有的ingress钩子上的程序
tc filter replace dev em1 ingress pref 1 handle 1 bpf da obj prog.o sec foobar
最后,为了移除所有ingress和egress上附加的程序,可以使用如下命令:
tc filter del dev em1 ingress
tc filter del dev em1 egress
为了移除网络设备上的整个clsact qdisc,即移除掉ingress和egress钩子上附加的所有程序,可以使用如下命令:
tc qdisc del dev em1 clsact
如果NIC和驱动也像XDP BPF程序一样支持offloaded,则tc BPF程序也可以是offloaded的。Netronome的nfp同时支持两种类型的BPF offload。
tc qdisc add dev em1 clsact
tc filter replace dev em1 ingress pref 1 handle 1 bpf skip_sw da obj prog.o
Error: TC offload is disabled on net device.
We have an error talking to the kernel
如果出现了如上错误,则表示首先需要通过ethtool的hw-tc-offload来启动tc硬件offload:
ethtool -K em1 hw-tc-offload on
tc qdisc add dev em1 clsact
tc filter replace dev em1 ingress pref 1 handle 1 bpf skip_sw da obj prog.o
tc filter show dev em1 ingress
filter protocol all pref 1 bpf
filter protocol all pref 1 bpf handle 0x1 prog.o:[classifier] direct-action skip_sw in_hw id 19 tag 57cd311f2e27366b
in_hw标志表示程序已经offload到了NIC中,注意不能同时offload tc和XDP BPF,必须且只能选择其中之一。
版权声明:本文为微信公众号「深度Linux」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://mp.weixin.qq.com/s?__biz=Mzg4NDQ0OTI4Ng==&mid=2247485153&idx=1&sn=95375d07e6c14912038b1920f049b339&chksm=cfb94f88f8cec69e5903bd97f6ac71abecdedde81ab604a9fc6c41e7fa07fdf6a0ead0c3718e#rd