集成学习
集成学习原理
集成学习:通过构建并结合多个学习器来完成学习任务,并提升预测结果的准确性和泛化能力。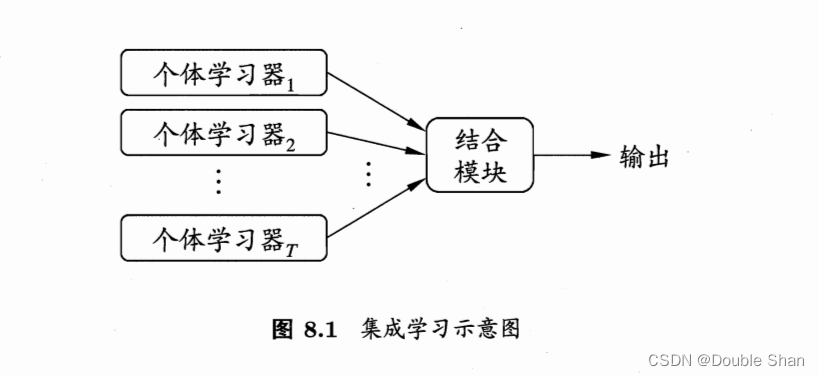
例子说明:

集成学习中的个体学习器必须满足两个条件:1、泛化误差要小于50%,即预测性能要比随机猜想强。2、预测的结果是有差异性的。
Adaboost算法
Boosting是一族可将弱学习器提升为强学习器的算法,这族算法的工作机制类似于:先从初始训练集训练出一个基学习器,在根据集学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器,如此重复学习,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合。而Adaboost算法是作为Boosting的代表。


Gradient Boosting

把H(X)和f(x)的条件放宽后,就可应用于二分类、多分类和回归种种机器问题学习上。

GBDT
Adaboost用于处理二分类问题,而GBDT是用于处理多分类回归问题。

Bagging
boosting是一种串行的集成学习方法,而Bagging是并行式集成学习的代表
自助采样法:给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样经过m个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则未出现,初始训练集中约有63.2%的样本出现在采样集中。
随机森林(Random Forest)
随机森林是Bagging的一个扩展变体,在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入属性的随机选择。
假设样本包含d个属性对基决策树的每个节点,先从该节点的属性结合中随机选择包含k(k<=d)个属性的子集用来进行最优划分。
随机森林训练效率通常由于Bagging,因为每个节点的划分只需要部分属性参与,而随机森林的泛化误差通常要低于Bagging,因为属性的扰动为每个基决策树提供了更高的鲁棒性。
参考:西瓜书、南瓜书视频