
来源:专知
本文约3200字,建议阅读5分钟
在这篇论文中,我们提出了一种新的范式,有效地利用最先进的基础模型生成的语言定位分割掩模,来解决日常场景中各种拾放机器人操作任务。
改善通用机器人代理的泛化能力长期以来一直是研究社区积极追求的重要挑战。现有的方法通常依赖于收集大规模的现实世界机器人数据,如 RT-1 数据集。然而,这些方法通常效率较低,限制了它们在开放领域的新对象和多样化背景下的能力。在这篇论文中,我们提出了一种新的范式,有效地利用最先进的基础模型生成的语言定位分割掩模,来解决日常场景中各种拾放机器人操作任务。通过将掩模传递的精确语义和几何形状整合到我们的多视角策略模型中,我们的方法可以感知到准确的物体姿态,并实现高效的学习样本。此外,这种设计有助于有效地泛化抓取训练过程中观察到的具有类似形状的新对象。我们的方法包括两个独特的步骤。首先,我们引入一系列基础模型,以准确地把自然语言需求对应到多个任务上。其次,我们开发了一个多模态多视角策略模型,该模型结合了RGB图像、语义掩模和机器人本体感知状态等输入,共同预测出准确且可执行的机器人动作。在Franka Emika 机器人手臂上进行的大量现实世界实验验证了我们提出的范例的有效性。在YouTube和哔哩哔哩上展示了现实世界的演示。
https://arxiv.org/abs/2306.05716

创建一个能在真实世界环境中对各种物体执行多种动作的通用机器人代理仍然是一个长期存在且具有挑战性的任务。虽然在工业场景中单一任务的机器人可能就足够了,但设计用来在日常生活中协助和与人互动的机器人需要具有高度的泛化能力。在这篇论文中,我们努力开发一个多功能的机器人模型,赋予机器人代理这种泛化能力。具体来说,我们专注于拾放任务,这在机器人操控中起着基础和关键的作用。例如,在涵盖了全面和大规模多任务厨房操控数据集的RT-1[1]中,有近85%的任务涉及到与拾放相关的动作。这个数字强调了拾放任务在实际真实世界应用中的重要性。创建多功能代理的第一个挑战是如何有效地将抽象的抓握指令转化为具体的机器人输入。目前的方法利用了各种形式,包括任务标识符[2]、目标图像[3]、展示人类示范的视频[4],以及越来越受欢迎的自然语言指令[1,4,5,6,7]。特别是语言,为人机交互提供了最自然和可扩展的方式,从而便于更容易地与机器人进行交流。第二个挑战涉及提高单一机器人模型处理多个拾放任务的泛化能力,包括视觉感知和动作执行。这就需要开发一个能够有效学习和适应广泛任务范围,同时保持效率和可扩展性的模型。
为了应对上述挑战,最近的进步[1,6,8]主要采用了基于学习的模型。值得注意的是,其中一项开创性的工作是RT-1[1],该工作引入了一个全面的模型,能够使用涵盖了17个月、涉及13个机器人的大约130,000次示范的大规模数据集来执行各种指令。然而,收集真实世界的数据需要大量的资源,而且这种方法在组合泛化方面存在限制,难以处理未见过的物体、背景或环境[1,9]。此外,一项开创性的工作MOO[9]提出了利用从开放词汇对象检测模型中获取的对象位置先验来提高效率。然而,依赖于检测只能提高视觉泛化能力。它仍然需要像RT-1[1]一样的大规模训练数据,来进行动作执行的学习。
我们提出了一种新的模式,有效地将2D分割基础模型与控制模型结合起来,以解决上述限制。具体来说,我们将分割掩模引入为控制模型的一种新的输入模式,因为分割已被证明在动作策略学习中具有重要的优先权[10,11,12]。将掩模作为一种新的模式加入,可以提供一种有效的方式,将大型基础模型的能力转移到策略模型中,从而有助于智能地抓取具有类似几何形状的各种物体。因此,我们的模型展示了泛化到未见过的物体类别和任务的能力,即使在复杂的环境中,也表现出数据效率和稳健性。这一进步为真实世界应用中的多功能机器人系统铺平了道路,减少了对大规模数据收集的依赖。
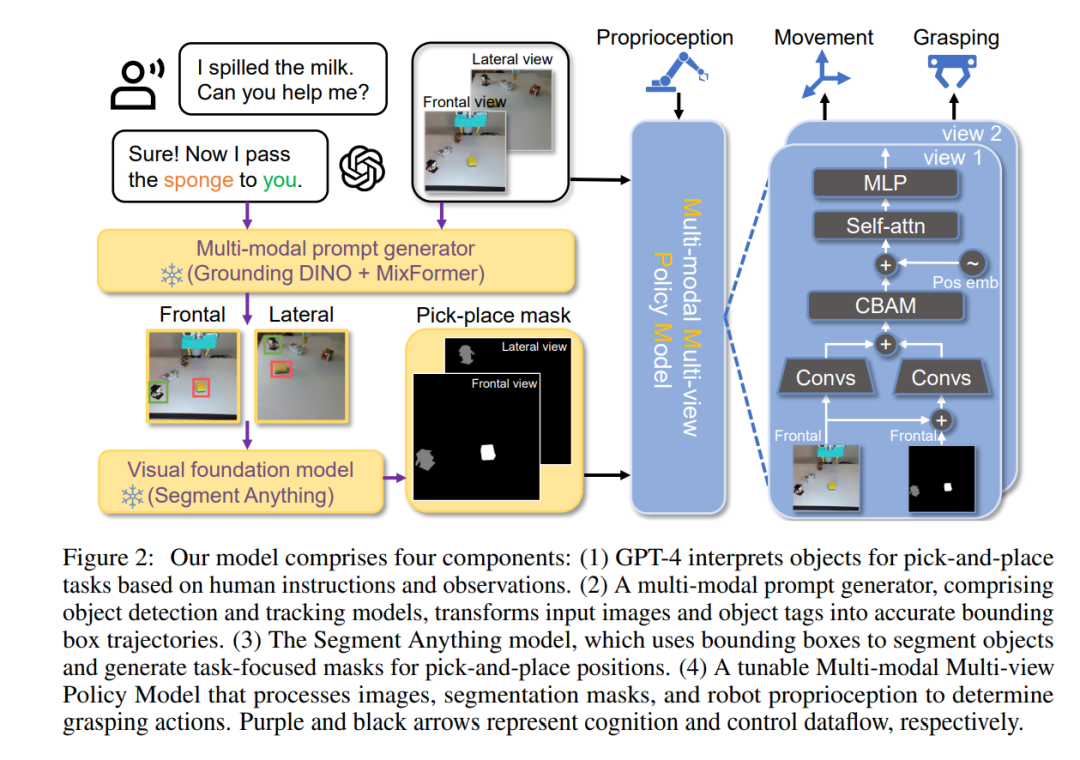
为了进一步构建一个具有自然人机交互的整体机器人系统,我们提出进一步利用大型语言模型GPT-4[13],并将两步流程设计到我们的系统中。(1) 身体化掩模生成:我们使用GPT-4解释人类的指令,通过检测和追踪模型识别和定位物体。然后,我们采用视觉基础模型SAM[14]生成目标物体的分割掩模,作为下一步的输入。(2) 动作预测:我们引入了一种多模态多视图策略模型(MMPM),用于联合训练RGB图像、语义掩模和机器人运动,从而实现更好的3D感知,从而导致精确的动作预测。我们精心收集了一个包含各种物体(500次示范,26个物体,5种形状类型)的机器人数据集,用于高效的拾放任务训练。我们的实验显示了我们提出的模型的有效性,特别是在泛化到未见过的物体、复杂背景和多个干扰物方面。我们的任务的简单演示如图1所示。
本文的贡献可以总结如下:(1) 我们是首批使用分割掩模将基础模型应用于通用拾放代理的研究者之一,旨在以样本效率高的方式增强其泛化能力。(2) 我们使用Franka Emika Research 3机器人臂收集了一个精选的真实世界机器人数据集,并开发了一种多模态多视图策略模型,以进行准确的动作预测。(3) 我们的真实世界实验结果表明,我们的控制模型可以有效地提高性能,并泛化以处理未见过的物体、新的背景和更多的干扰物。
方法
在本节中,我们首先在第3.1节中介绍问题的形式化。接下来,在第3.2节中,我们详细介绍了使用基础模型进行身体化掩模生成的流程。最后,我们在第3.3节中详细阐述了多模态多视图策略模型及其训练方法。
实验结果
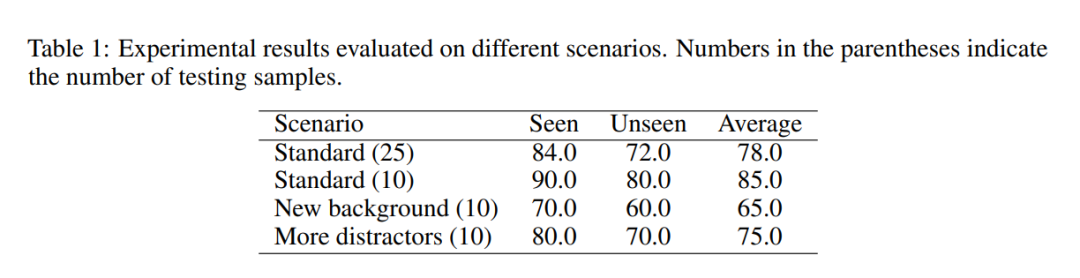
在本节中,我们首先介绍我们的数据集。然后我们在接下来的部分中详细阐述训练细节、实验设置和结果。我们首先对我们的方法的有效性以及其泛化到未见过的物体、新的背景和更多干扰物的能力进行了全面评估。为了确保更强大的评估,我们在每个设置下随机测试了大量的任务,括号中的数字表示实验任务的数量。标准环境是指与训练数据一致的,有0-2个干扰物的桌面背景。实验结果如表1所示。这些结果表明,在引入新背景时,无论是在已见或未见设置下,性能都会略有下降。然而,我们的模型对更多的干扰物表现出鲁棒性,这可以归因于在动作学习中引入了分割掩模的模式。
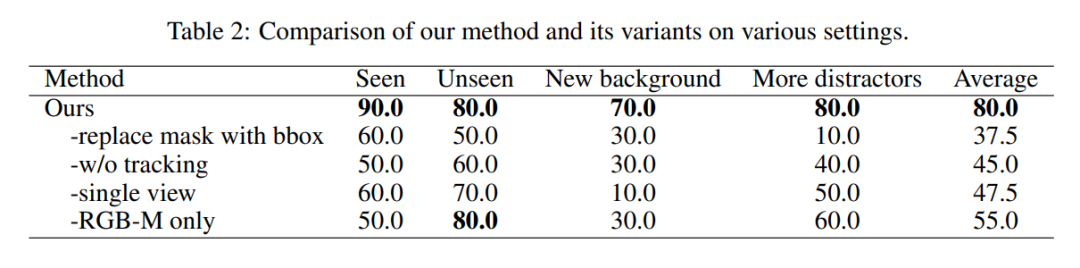
为了进一步验证我们提出的方法及其各个组件的有效性,我们将我们的方法与几种变体进行了比较。我们在四种设置中评估每种方法:1)标准环境中的已见物体;2)标准环境中的未见物体;3)新背景中的已见物体;以及 4)带有更多干扰物(随机3-6个)的已见物体。每个设置包括10个任务,因此每种方法总共有40个任务。详细的任务列表可以在附录B中找到。
比较实验的结果如表2所示。我们分析结果以解答以下问题:• 对于动作预测,分割掩模是否优于边界框?• 用于提示生成的跟踪是否比逐帧检测更稳健?• 多视图融合是否比单视图更有优势?• 单独包含RGB分支是否有益?
分割掩模对于动作预测比边界框更有效。我们首先将物体掩模替换为其边界框,这类似于MOO [9]。关键的区别在于,MOO需要模型由于在第一帧之后固定边界框而隐式地执行时间相关性,而我们明确地合并了一个跟踪器。结果显示,分割掩模明显优于边界框。除了提供更多的几何和形状先验,分割掩模对复杂纹理和干扰物也显示出更大的鲁棒性。相反,边界框难以实现这种精度。
用于提示生成的跟踪比逐帧检测更稳健。然后,我们将首帧检测和后续帧跟踪的范式替换为逐帧检测用于提示生成。成功率显著降低,特别是当机器人手臂在抓取过程中严重阻挡物体时,这说明了检测-跟踪范式的鲁棒性。此外,检测-跟踪范式显著提高了推理速度。
与单视图相比,多视图融合更有益。我们进一步调查将多视图模型转换为单视图模型,仅保留前视图。实验结果显示,在所有设置中性能都有显著下降。特别地,在新背景环境中出现了显著下降。我们认为这是因为多视图视觉可以通过视差估计深度,使其比单视图视觉更鲁棒。
单独有一个RGB分支是有益的。最后,我们基于ResNet-50实现了一个单分支RGB-M策略模型进行公平的比较。实验结果显示其性能明显下降,证明了我们的双流架构的有效性。这种双流方法允许模型有效地处理和解释局部和全局特征,从而更准确地理解环境及其内部的物体。
