目录
简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区 别、使用软引用能带来的好处)。
如何判断对象是否死亡(两种方法)。
引用计数法 对象 + 一个引用计数器,引用 + 1;失效 - 1;任何时候计数器为 0 的对象就是不可能再被使用的。
这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内 存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
可达性分析算法 “GC Roots” 对象为起点,从这些节点开始向下搜索,节点所走过的路径称为引用链,当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的。
可作为 GC Roots 的对象包括下面几种:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 本地方法栈(Native 方法)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 所有被同步锁持有的对象
简单的介绍一下强引用、软引用、弱引用、虚引用(虚引用与软引用和弱引用的区 别、使用软引用能带来的好处)。
JDK1.2 前,传统引用定义: reference 类型数据存储数值代表另一块内存的起始地址。
JDK1.2 后,引用扩充,分为强、软、弱、虚四种(引用强度逐渐减弱)
强引用,垃圾回收器不回收。当内存不足,Java 虚拟机抛出 OutOfMemoryError 错误
软引用,内存空间足够,不回收。内存不足,回收。可实现内存敏感的高速缓存。 如果软引用的对象被垃圾回收,jvm把软引用加入关联引用队列。
软引用加速垃圾回收,维护系统安全,防止(OOM)等问题的产生。
弱引用,弱、软区别——弱对象生命周期更短。不管内存空间是否足够,都回收。
虚引用,虚引用不决定对象生命周期。在任何时候可能被垃圾回收。虚引用跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的区别: 虚引用必须和引用队列 (ReferenceQueue)联合使用。
如何判断一个常量是废弃常量
1. JDK1.7 之前,运行时常量池 (字符串常量池)→→方法区, 方法区实现永久代
2. JDK1.7 字符串常量池→→堆, 运行时常量池→→方法区。
3. JDK1.8 元空间 取代 永久代, 字符串常量池→→堆, 运行时常量池→→方法区,方法区实现元空间
字符串常量池中存在字符串 "abc",当前没有任何 String 对象引用,就说明常量 "abc" 就是废弃常量,如果这时发生内存回收,"abc" 被清理。
如何判断一个类是无用的类
- 该类所有实例被回收。
- ClassLoader 被回收。
- java.lang.Class 对象不被引用,无法通过反射访问。
垃圾收集有哪些算法,各自的特点?
标记-清除/复制/整理、分代收集
标记-清除算法 “标记”出所有不回收对象,“清除”回收没有被标记对象。
1. 效率问题 2. 空间问题(标记清除后会产生大量不连续的碎片)
标记-复制算法 内存分为两块, 每次用一块。一块用完,将存活对象复制到另一块, 然后清理使用的空间。每次对内存一半回收。
标记-整理算法 “标记”出所有不回收对象,所有存活对象向一端移动,清理端边界以外内存。
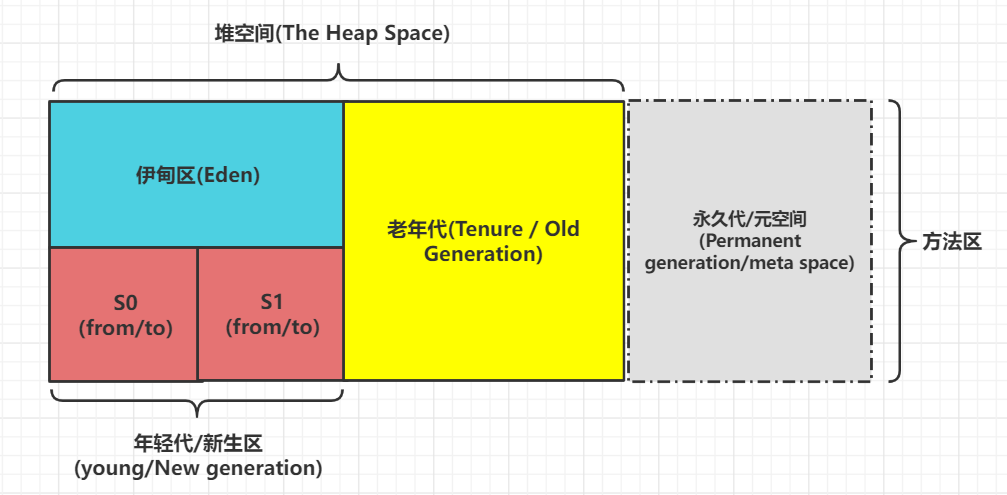
分代收集算法 根据对象存活周期不同将内存分为几块。一般将 java 堆分为新生代和老年代。
比如新生代中,每次收集都会有大量对象死去,选择”标记-复制“算法,付出少量对象的复制成本。老年代的对象存活率比较高,必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
HotSpot 为什么要分为新生代和老年代?
常见的垃圾回收器有哪些?
Serial 收集器 一个单线程收集器。新生代采用标记-复制算法,老年代采用标记-整理算法。简单高效。 适合Client 模式下的虚拟机
ParNew 收集器 是 Serial 收集器的多线程版本,能与 CMS 收集器工作。适合Server 模式下的虚拟机
Parallel Scavenge 收集器 Parallel Scavenge 收集器关注点是吞吐量(运行用户代码时间与 CPU 总消耗时间的比值)。CMS 等垃圾收集器 关注点是用户线程的停顿时间(提高用户体验)。
Serial Old 收集器 Serial 收集器的老年代版本,一个单线程收集器。两大用途: JDK1.5 以前与 Parallel Scavenge 收集器搭配使用,另一种用途是作为 CMS 收集器的后备方案。
Parallel Old 收集器 Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量 以及 CPU 资源的场合,优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集 器。
CMS(Concurrent Mark Sweep)收集器 一种获取最短回收停顿时间为目标的收集器。 第一款并发收集器,第一次实现垃圾收集线程与用户线程同时工作。优点:并发收集、低停顿。缺点:CPU 资源敏感; 无法处理浮动垃圾; “标记-清除”算法结束时产生大量空间碎片。
- 初始标记: 暂停所有线程,记录 root 相连对象
- 并发标记: 同时开启 GC 和用户线程,闭包记录可达对象。
- 重新标记: 修正并发标记期间标记产生变动的标记记录
- 并发清除: 开启用户线程,同时 GC 线程对未标记的区域做清扫。
G1 (Garbage-First) 一款面向服务器的垃圾收集器。高概率满足 GC 停顿时间要求,高吞吐量性能特征。被视为 JDK1.7 中 HotSpot 虚拟机的一个重要进化特征。
- 并行与并发:G1 充分利用 CPU、多核环境,缩短 Stop-The-World 停顿时间。
- 分代收集:保留分代概念。
- 空间整合:G1 整体“标记-整理”;局部“标记-复制”。
- 可预测的停顿: G1 除了追求低停顿外,建立可预测的停顿时间模型。
G1 收集器的运作: 初始标记 并发标记 最终标记 筛选回收
G1 收集器在后台维护了一个优先列表,每次根据允许的收集时间,优先选择回收价值 最大的 Region(这也就是它的名字 Garbage-First 的由来) 。
ZGC 收集器 与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
介绍一下 CMS,G1 收集器。
Minor Gc 和 Full GC 有什么不同呢?
部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
整堆收集 (Full GC):收集整个 Java 堆和方法区。
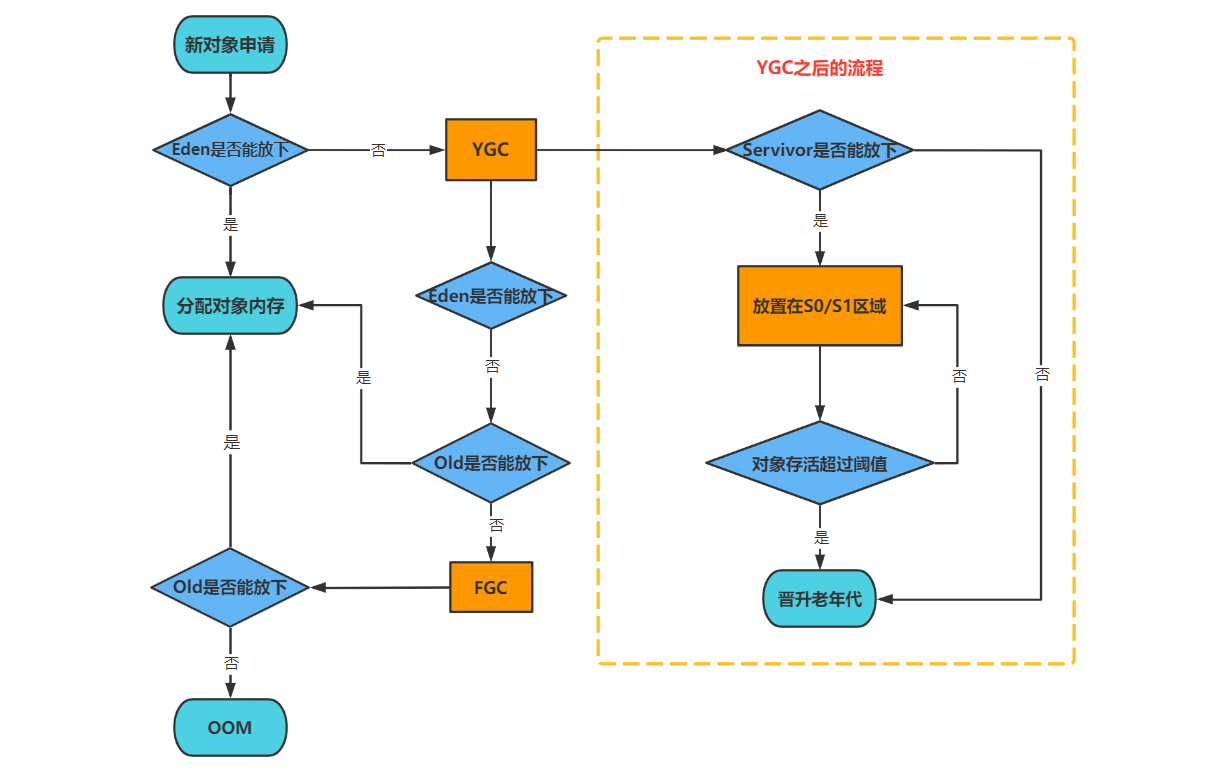
Minor GC触发条件:当Eden区满时,触发Minor GC。
Full GC触发条件:
- 通过Minor GC后进入老年代的平均大小大于老年代的可用内存。如果发现统计数据说之前Minor GC的平均晋升大小比目前old gen剩余的空间大,则不会触发Minor GC而是转为触发full GC。
- 老年代空间不够分配新的内存(或永久代空间不足,但只是JDK1.7有的,这也是用元空间来取代永久代的原因,可以减少Full GC的频率,减少GC负担,提升其效率)。
- 由Eden区、From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小。
- 调用System.gc时,系统建议执行Full GC,但是不必然执行。