前言
哈喽,铁子们,不知道你们在采集数据的时候,有没有过因为过快或者访问频繁,一访问就弹出验证码,然后就蚌珠了~

今天就分享一下,如何用Python来解决这个问题
环境模块
Python和pycharm
没安装(或者不会安装的)可以直接私信我
这里需要用到一个 ddddocr 模块 ,这是别人开源写好的一个东西,简单又好用,但是精确度差一点点,但是还是非常好用的。
如果你追求精确度的话,可以调用别人写好的一些API 。
咱们直接 win+r 弹出搜索框后输入 cmd ,点击确定弹出命令提示符窗口, 输入pip install ddddocr 即可安装。
代码展示
代码不多,非常简单。
模块安装好之后咱们先导入一下
import ddddocr
然后实例化一下,用一个 cor 接收一下这个数据。
ocr = ddddocr.DdddOcr()
在这里准备了四个验证码




分别实现一下验证码
首先我们用 with open 来读取一下这文件,读取方式使用 rb ,因为是图片的话就读取它的二进制数据
with open('img_3.png', 'rb') as f:
使用 f.read() 将数据读取出来,再自定义一个变量接收一下。
img_bytes = f.read()
然后我们通过 classification 将它传进去,把结果打印出来就可以了。
result = ocr.classification(img_bytes)
print(result)
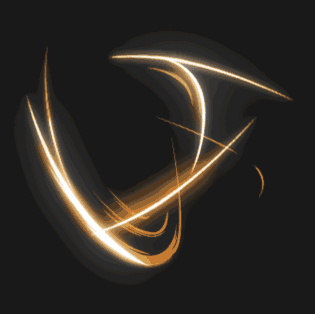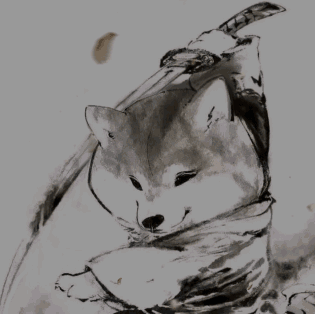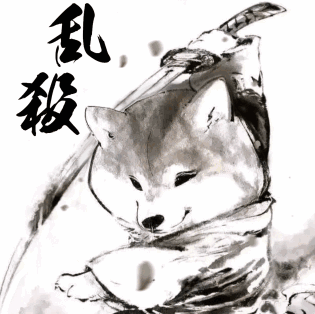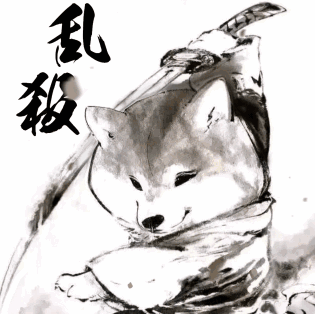
实现效果
纯数字的

字母+数字的
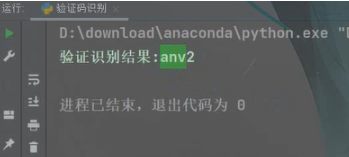

可以看到都完整的识别出来了,即使上面有一些花里胡哨的横线啥的。
完整代码
python学习交流Q群:770699889 ###
import ddddocr
ocr = ddddocr.DdddOcr()
with open('img_3.png', 'rb') as f:
img_bytes = f.read()
result = ocr.classification(img_bytes)
print(result)

好啦,今天的分享到这里就结束了 ~
如果需要更多视频学习的可以在b站搜索 :鹅头烧麦
对文章有问题的,或者有其他关于python的问题,可以在评论区留言或者私信我哦
觉得我分享的文章不错的话,可以关注一下我,或者给文章点赞(/≧▽≦)/