论文:CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
代码:https://github.com/tgxs002/CORA
出处:CVPR2023
一、背景
开集目标检测(Open-vocabulary detection,OVD)最近得到了很大的关注,CLIP 的出现让开集目标检测有了新的解决方式
CLIP 是学习图像和文本之间的关系来进行匹配的,那么能否将 CLIP 用于解决开集目标检测呢
这里会有两个问题:
-
如何将 CLIP 使用到 region-level 的任务上:
一个简单的做法是将 region 扣出来当做一个图像,但这并非好的解决方式,因为 region 和 image 之间本来就有 gap
-
如何学习可泛化的目标 proposal:
ViLD、OV-DETR、Region-CLIP 等都需要使用 RPN 或 class-agnostic 目标检测器来挖掘出没被提及的类别,但这些 RPN 也都是基于训练数据来训练的,不可能将所有目标都检出,所以其实能检出的需要的类别也很少
本文中提出了一个基于 DETR 且引入了 CLIP 的方法,且没有使用额外的 image-text 数据,来实现开集目标检测
二、方法
OVD 是一个希望能检出所有类别的检测任务,本文提出了 CORA 来解决该任务
2.1 总体结构
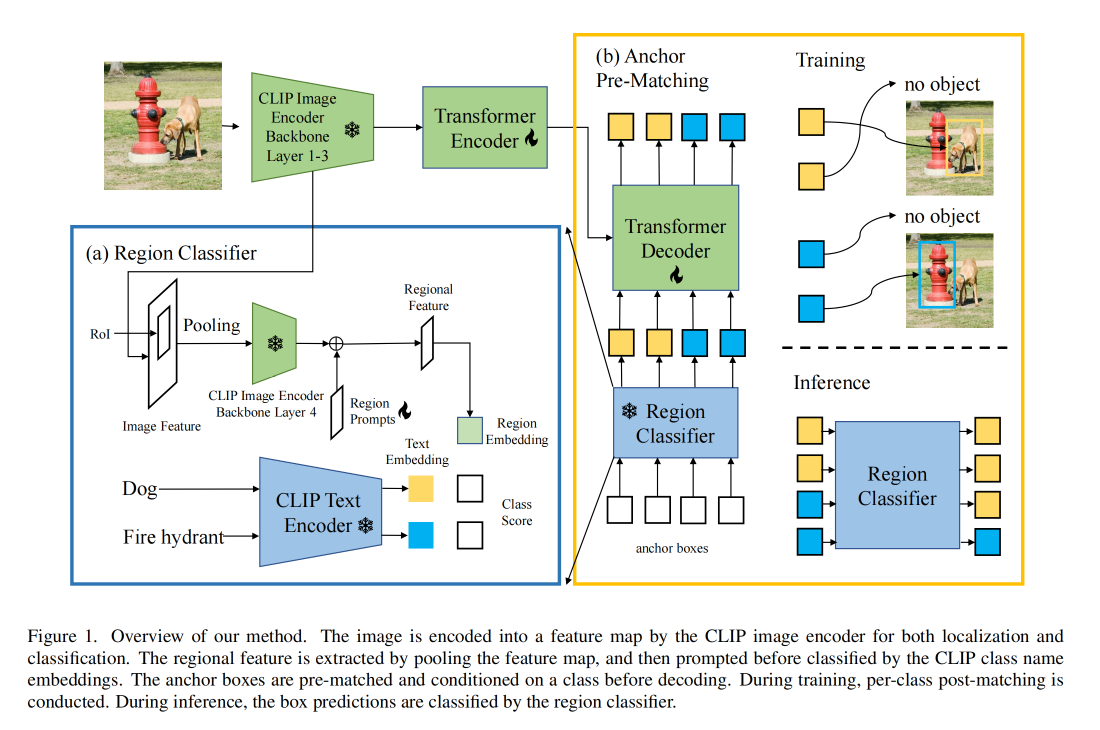
如图 1 所示,给定一个图像作为输入:
-
首先,使用训练好的 CLIP 中的 ResNet backbone 来提出图像的特征,分类和定位共享这个特征
-
接着,region classification:给定一个待分类的 region(anchor box 或 box prediction),作者使用 RoIAlign 来得到 region 特征,然后使用 CLIP 的 attention pooling 来得到区域编码,可以使用从 CLIP text encoder 得到的 class embedding 来进行分类
-
然后,object localization:对于上面通过 CLIP 得到的图像特征,会使用 DETR-like encoder 进行进一步特征提取,然后输入 DETR-like decoder,anchor box 的 queries 会先使用 CLIP-based region classifier 进行分类,然后会根据预测的标签进行调整,然后使用 DETR-like decoder 来实现更好的定位。decoder 也会根据预测的 label 来估计 query 的匹配。在训练中,预测的框会和 gt 进行一对一匹配,然后使用 DETR 的方式进行训练。推理时,box 的类别直接使用 CLIP-based region classifier 来确定
针对这两个问题,CORA 也提出了解决方案:
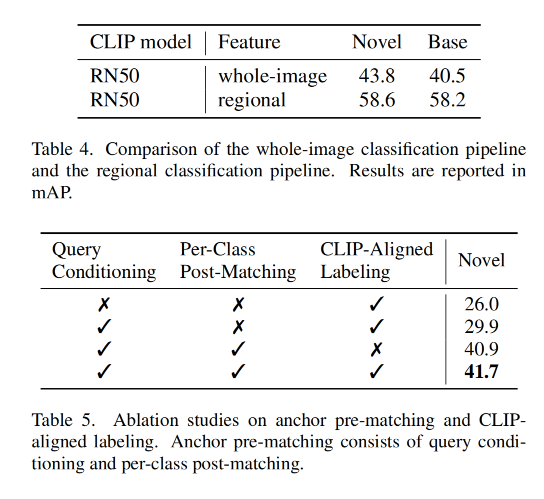
- 目标检测是识别和定位图像中的目标,CLIP 模型是在整个图像上训练的,有一定的 gap:作者提出了 region prompt,来调整 region features 以获得更好的定位
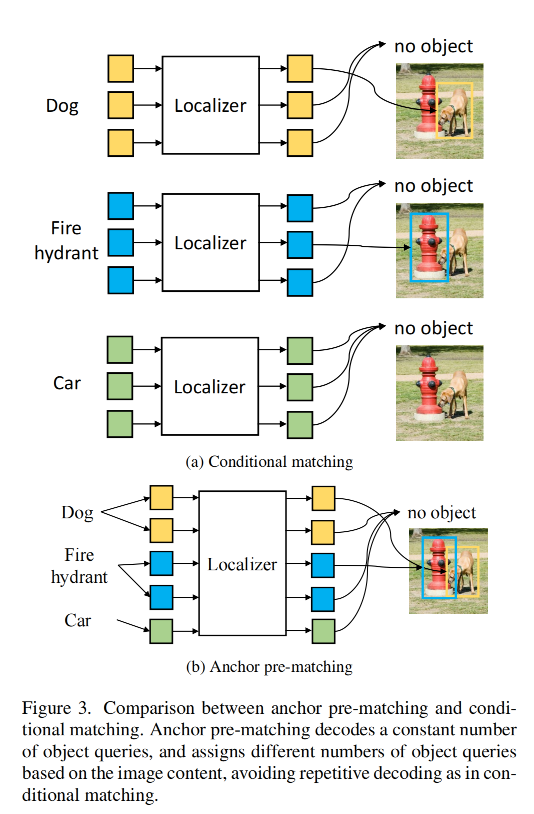
- 检测器需要对新类别学习目标的位置,但标注的类别都是基础类别:作者将 anchor pre-matching 提前了,让 class-aware 的目标定位能够在 infer 的时候泛化到新的类别
2.2 region prompting
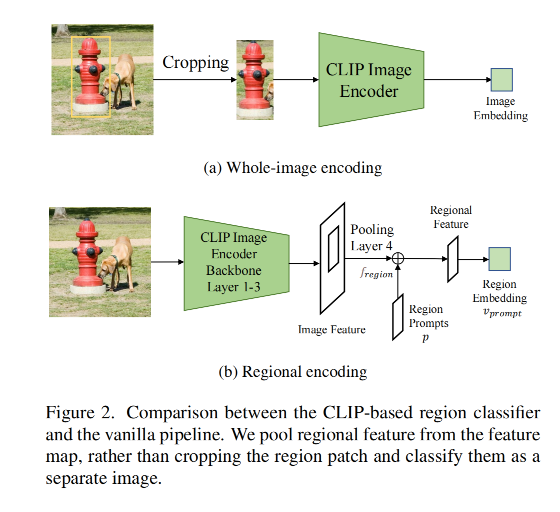
如图 2 所示,给定一个图像和一系列 RoI,首先对全图使用 CLIP encoder 的前 3 个 blocks 进行编码,然后使用 RoIAlign pooling
由于 CLIP 对全图编码和区域编码是有 gap 的,所以作者提出 region prompting 来通过可学习的 prompt p ∈ R S × S × C p\in R^{S \times S \times C} p∈RS×S×C 来扩展 region feature,对两组特征进行对齐
- S:region feature 的空间尺寸
- C:region features 的维度
给定一个 input region feature f r e g i o n f_{region} fregion,region prompt 计算如下:
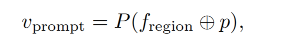
- ➕ 表示逐点相加
- P 是 CLIP 中的 attention pooling
如何优化 region prompt:
- 作者使用 base-class 标注的检测数据来训练 region prompt
- loss 为交叉熵
- 保持其他参数冻结,只训练 region prompt
2.3 anchor pre-matching
region prompt 能够帮助解决 image 和 region 的 gap
为了解决 RPN 在新类别上检出能力不足的问题,作者提出了 class-aware query-based 目标定位器,能够提升模型在没见过的类别上的定位能力
如图 1 所示,给定一个从 CLIP image encoder 得到的视觉特征, object query 会和 class name embedding 进行 pre-matched
Anchor Pre-matching:
目标定位是使用 DETR-style 的 encoder-decoder 结构实现的,encoder 用于细化特征图,decoder 用于将 object query 解码到 box
作者使用 DAB-DETR,object query 的类别 c i c_i ci 是根据相关的 anchor box b i b_i bi 来分配的
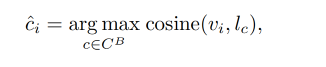
pre-matching 之后,每个 object query 会根据预测的类别来进行 class-aware box regression,object query 是有下面得到的:
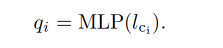
得到模型预测后,gt 和模型预测框的匹配是对每个类别分别使用双边匹配
对类别 c,假设 gt y c y^c yc 匹配到了 N c N_c Nc 个预测框,会通过最小化下面的分布来优化 N c N_c Nc 的排列:
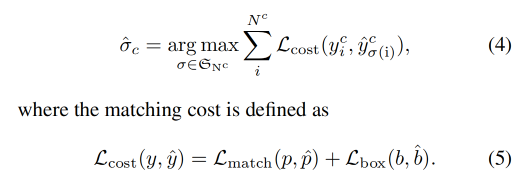
- L m a t c h L_{match} Lmatch:二值分类 loss,这里使用 focal loss
- L b o x L_{box} Lbox:是定位误差,这里使用 L1 和 GIoU 的加权和
模型的最终优化 loss 如下:
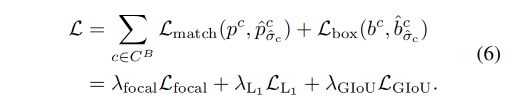
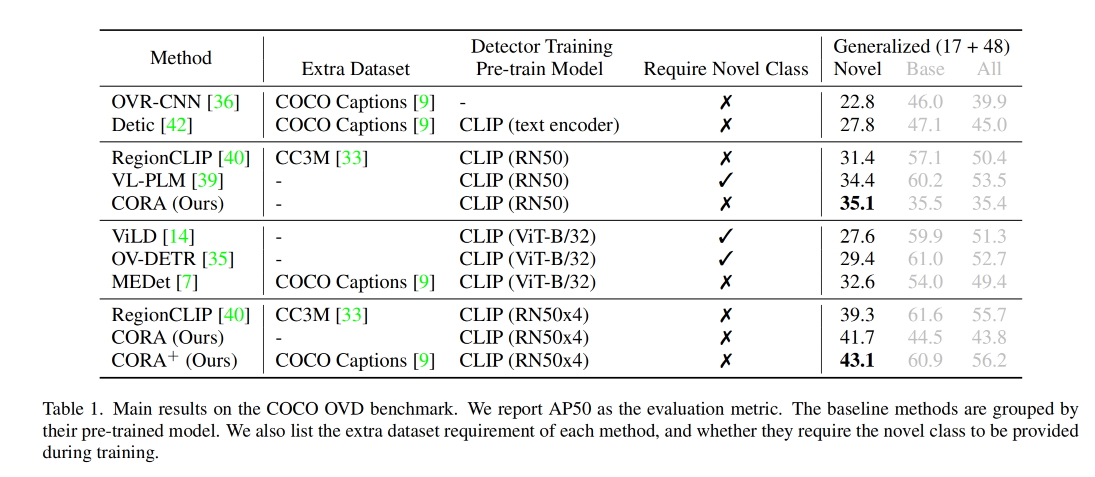
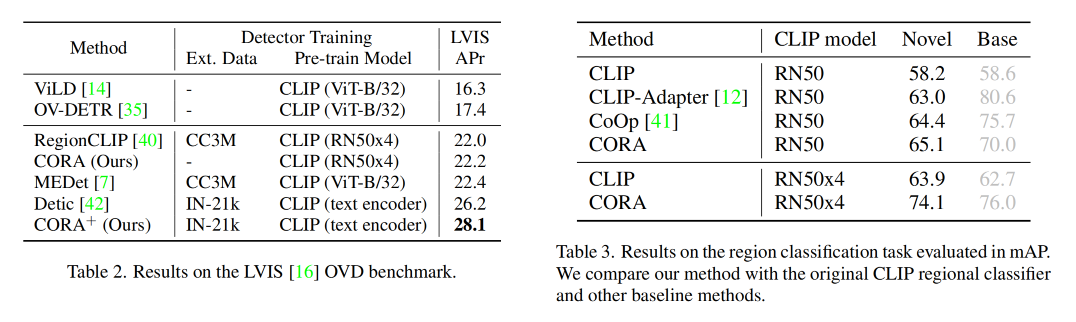
三、效果