一、前言
大文件上传下载一直以来是前端常用且常考的热门话题。本文将分别介绍大文件上传/下载的思路和前端实现代码。
二、分片上传
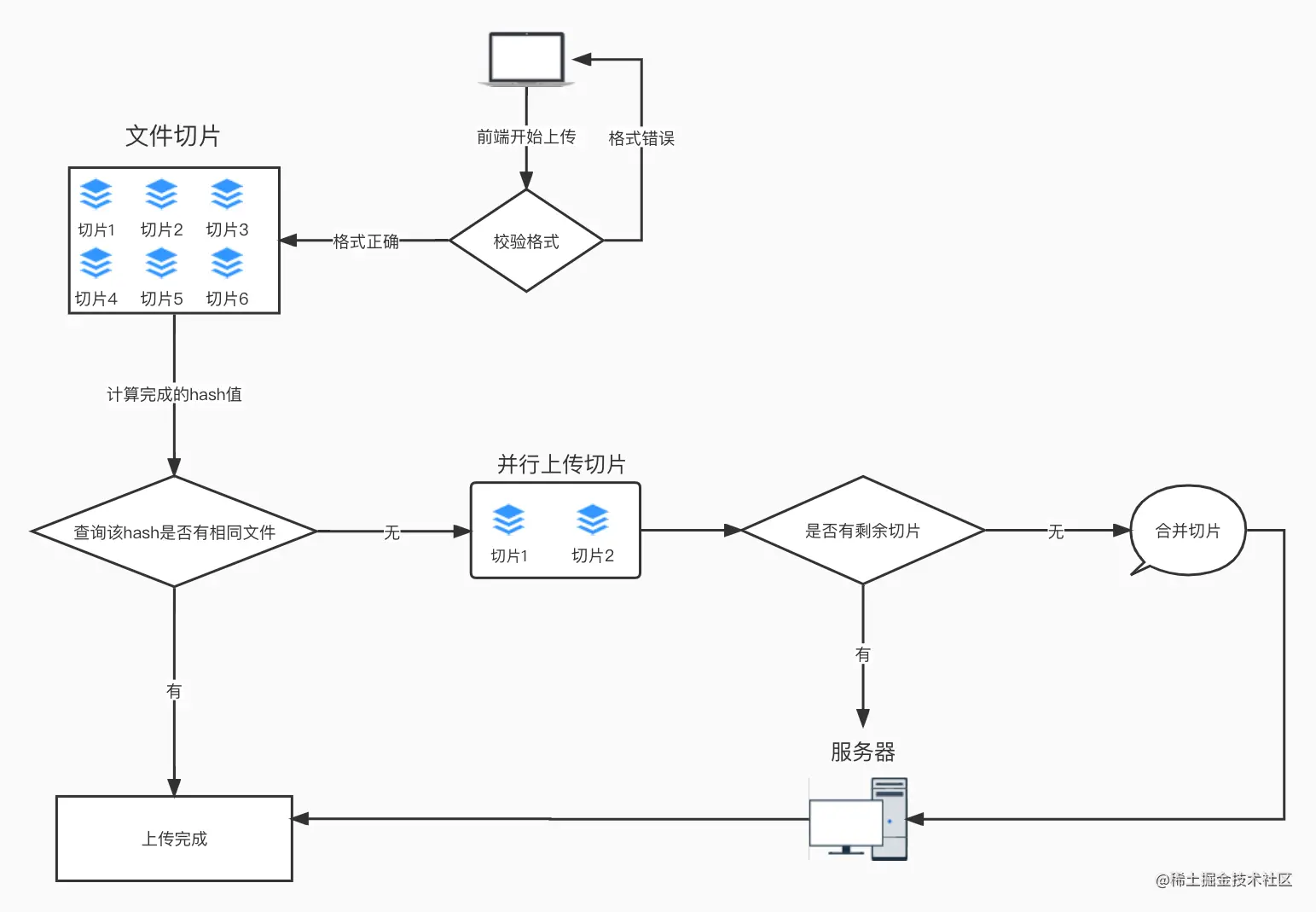
整体流程
- 对文件做切片,选择文件后,对获取到的file对象使用slice方法可以将其按照制定的大小进行切片,通俗来讲就是分割文件(因为
File对象基于Blob,Blob实例具有Blob.prototype.slice()方法; - 利用
spark-md5.min.js计算整个文件的全量Hash,这一步操作可以放在web worker中执行,以免造成浏览器卡顿; - 将获取到的文件hash值传给后端,判断文件是否存在:
如果存在,即满足"秒传"条件,返回上传成功。
如果不存在,即进行“断点续传“查询是否存在该文件的切片文件,如果存在,返回切片文件的详细信息; - 如果未上传则全部上传,如果上传了一段,则将剩下的文件片段进行上传(控制并发和断点续传);
- 上传完成后通知后端合并,后端合并结束返回文件地址。
如果不存在的话,查询是否存在该文件的切片文件,如果存在,返回切片文件的详细信息。
1. 文件切片
/**
* 开始文件切片
* @param file
* @param size
* @returns {*[]}
*/
const CHUNK_SIZE = 1024 * 50; //50KB 指定切片大小
function splitFile(file, size = CHUNK_SIZE) {
const fileChunkList = []
let curChunkIndex = 0
while (curChunkIndex < file.size) {
const chunk = file.slice(curChunkIndex, curChunkIndex + size)
fileChunkList.push(chunk)
curChunkIndex += size
}
return fileChunkList
}
2. 判断文件是否存在(全量校验)
web worker使用示例:
//主线程代码
const worker = new Worker('worker.js') //创建worker,worker.js是你要执行的脚本路径同级目录下直接写名字
worker.postMessage(files) //将得到的文件对象传递给worker线程
worker.onmessage = (e)=>{
// 接受worder传递回来的参数
console.log(e.data) //参数在e.data中
}
// worker.js worker文件代码
onmessage = (e)=>{
const files = e.data //拿到文件对象后既可以执行相关切片操作了
}
我们这里切片还是在主线程进行,只是将文件是否存在的校验放到了web worker中
// 计算hash值
const chunkList = splitFile(file) //上面分割完的文件切片
function calculateHash(chunkList) {
return new Promise(resolve => {
const woker = new Worker('/hash.js')
woker.postMessage({
chunkList})
woker.onmessage = e => {
const {
hash} = e.data;
if (hash) {
resolve(hash)
}
}
})
}
hash.js web worker,需要引入spark-md5.min.js分片计算文件的md5值
注意:
- 每个文件的md5值都是唯一的,
spark.end()就是文件的md5值. - 由于
浏览器有并发请求数限制,如果所有请求同时发出,超出限制的请求将会进行等待,可能会超时,所以我们要对切片上传做并发池控制
/**
* 创建web worker 进行文件校验计算hash值
* @param e
*/
self.onmessage = e => {
self.importScripts("/spark-md5.min.js");
const {
chunkList } = e.data;
const spark = new self.SparkMD5.ArrayBuffer();
let percentage = 0;
let count = 0;
const loadNext = index => {
const reader = new FileReader();
reader.readAsArrayBuffer(chunkList[index]);
reader.onload = e => {
count++;
spark.append(e.target.result);
if (count === chunkList.length) {
self.postMessage({
percentage: 100,
hash: spark.end()
});
self.close();
} else {
percentage += 100 / chunkList.length;
self.postMessage({
percentage: Number.parseFloat(percentage).toFixed(2)
});
// calculate recursively
loadNext(count);
}
};
};
loadNext(0);
};
3. 切片上传
// 获取已经上传了多少片段 hash:整个文件的md5值
const uploadRes = await getUploadedPartList(hash)
let fileData = fileChunkList.map((file, index) => ({
fileHash: hash, // 文件唯一hash值
hash,
file, // 文件bolb
index,
size: file.size, // 文件大小
percentage: uploadRes.data.includes(index) ? 100 : 0
})
)
// 开始上传片段
let targetRes = await uploadChunks(uploadRes.data, hash, fileData, file, loaded => {
onProgress(parseInt((loaded / file.size).toFixed(2)))
})
resolve(targetRes)
// 开始上传切片 返回上传进度
/**
* @param uploadList 已上传的切片
* @param hash 整个文件的md5值
* @param fileData 文件切片
* @param fileOriginalData 文件源数据
* @param onProgress 进度回调函数
* @returns {Promise<any>}
*/
async function uploadChunks(uploadList = [], hash, fileData = [], fileOriginalData, onProgress) {
return new Promise(async (resolve, reject) => {
let pool = []//并发池
let max = 3 //最大并发量
let finish = 0//完成的数量
let failList = []//失败的列表
//获取未上传的切片数组 并格式化切片数据
const requestList = fileData.filter(({
index}) => !uploadList.includes(index)).map(({
file,fileHash, index}) => {
const formData = new FormData()
formData.append('file', file)
formData.append('uploadId', fileHash)
formData.append('partNumber', index)
return {
formData}
})
// 控制并发和断点续传
for(let i=0;i<requestList.length;i++){
let item = requestList[i]
let task = axios.post('xxxxx',{
params: item.formData})
let task = axios({
url: 'xxxx',
method: 'POST',
data: item.formData,
isUpload: 1,
//监测切片上传进度
onUploadProgress: e => {
fileData[index].percentage = parseInt(String((e.loaded / e.total) * 100))
const loaded = fileData.map(i => i.size * i.percentage).reduce((acc, cur) => acc + cur);
onProgress(loaded)
},
}))
task.then(()=>{
//请求结束后将该Promise任务从并发池中移除
let index = pool.findIndex(t=> t===task)
pool.splice(index)
}).catch(()=>{
failList.push(item)
}).finally(()=>{
finish++
//所有请求都请求完成,通知后端合并文件
if(finish===list.length){
mergeRequestList()
}
})
pool.push(task)
if(pool.length === max){
//每当并发池跑完一个任务,就再塞入一个任务
await Promise.race(pool)
}
}
}
// 上传完成后通知后端合并文件
function mergeRequestList(hash, file) {
return new Promise(async (resolve, reject) => {
let {
data} = await axios({
url:'xxx',
method: 'POST',
data,
isUpload: 0
})
if (data.success) {
Message.success('上传成功!')
resolve(data.data)
} else {
reject(data.message)
}
})
}
/**
* 自定义axios
* @param url
* @param method
* @param data
* @param isUpload
* @param onUploadProgress
* @returns {Promise<any>}
*/
function request({
url, method = 'post', data, isUpload, onUploadProgress = e => e}) {
const service = axios.create({
baseURL,
timeout: 0,
onUploadProgress,
headers: {
'Content-Type': 'application/json'
},
})
if (isUpload) {
axios.defaults.headers.post['Content-Type'] = 'multipart/form-data'
axios.defaults.headers.post['UpLoadFile'] = '1'
}
service.defaults.headers.common['Authorization'] = `Bearer ${
token}`
service.interceptors.response.use(response => {
if (response) {
return Promise.resolve(response)
}
}, error => {
return Promise.reject(error)
})
return service.request({
url,
method,
data
})
}
三、分片下载
原理:
服务器使用 HTTP 响应头 Accept-Ranges 标识自身支持范围请求 (partial requests)。字段的具体值用于定义范围请求的单位。
当浏览器发现Accept-Ranges头时,可以尝试继续中断了的下载,而不是重新开始。
服务端需要支持Range请求首部
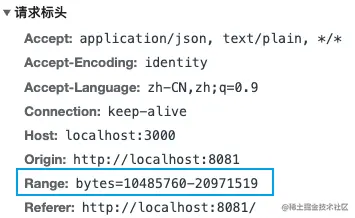
Range说明
在一个 Range 首部中,可以一次性请求多个部分,服务器会以 multipart 文件的形式将其返回。
状态码为 206 Partial Content:服务器返回的是范围响应。
状态码为 416 Range Not Satisfiable : 表示请求范围不合法,客户端错误。
状态码为 200 :服务器允许忽略 Range 头部,返回整个文件\
使用方法
Range: <unit>=<range-start>-
Range: <unit>=<range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>
Range: <unit>=<range-start>-<range-end>, <range-start>-<range-end>, <range-start>-<range-end>
- unit : 范围请求所采用的单位,通常是字节(bytes)。
- range-start : 范围的起始值,一个整数。
- range-end : 范围的结束值,可选,如果不存在,就一直延续到文件末端。
简单实现
一个url指向的资源,如果浏览器可以解析就会渲染,解析不了就直接下载,所以如果是.html/.jpg/.mp4等就会在开一个tab渲染出来,如果是.rar/.zip等文件就会直接下载。
如果需要所有资源都直接下载,不管什么媒体类型,就需要在响应头加上Content-Disposition:attachment。
app.use(async (ctx, next) => {
fileFilter(ctx)
await next()
})
function fileFilter(ctx){
const url = ctx.request.url
const p = /^\/files\//
if(p.test(url)){
ctx.set('Accept-Ranges', 'bytes')
ctx.set('Content-Disposition', 'attachment')
}
}
断点下载
整体流程如下图:
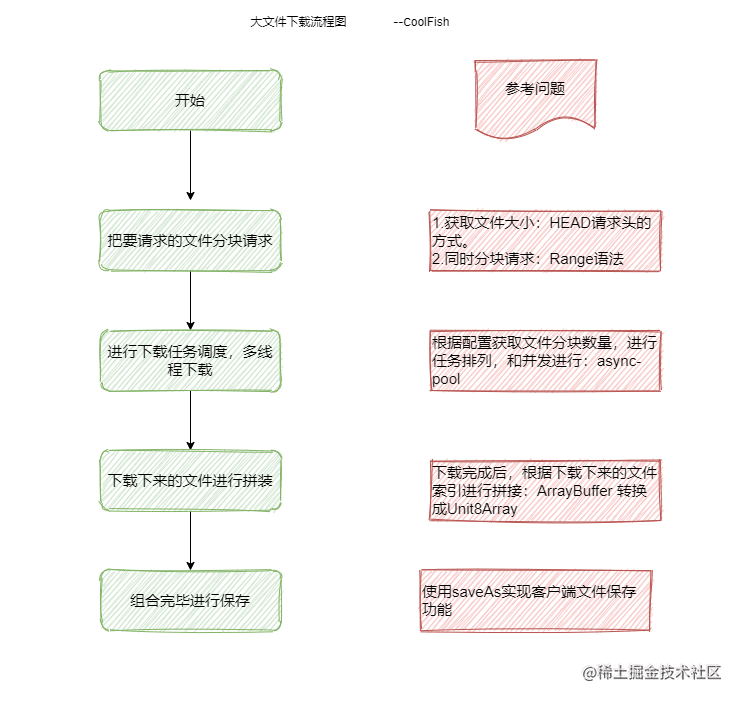
- 获取文件大小
首先我们需要获取文件的总大小,从而计算分片范围进行分块下载。
// 获取待下载文件的大小
async getFileSize (name = this.fileName) {
try {
const res = await http.get(`/size/${name}`)
this.fileSize = res.data.data
return res.data.data
} catch (error) {
console.log({ error })
}
}
- 根据文件大小和分片大小计算分片数量
const CHUNK_SIZE = 10 * 1024 * 1024 // 一个分片10MB
async onDownload () {
try {
// 根据文件大小和分片大小计算分片数量
const fileSize = await this.getFileSize(this.fileName)
const chunksCount = Math.ceil(fileSize / CHUNK_SIZE)
// 使用 asyncPool 实现并发下载
const results = await asyncPool(3, [...new Array(chunksCount).keys()], (i) => {
const start = i * CHUNK_SIZE
const end = i + 1 === chunksCount ? fileSize : (i + 1) * CHUNK_SIZE - 1
return this.getBinaryContent(start, end, i)
})
results.sort((a, b) => a.index - b.index)
// 根据分片结果数组构建新的 Blob 对象
const buffers = new Blob(results.map((r) => r.data.data))
// 文件合并与下载
saveFile(this.fileName, buffers)
} catch (error) {
console.log({
error })
}
}
上面使用 asyncPool 实现文件分片的并发下载,该函数具体实现为:
async function asyncPool(poolLimit, array, iteratorFn) {
const allTask = [] // 存储所有的异步任务
const executing = [] // 存储正在执行的异步任务
for (const item of array) {
// 调用 iteratorFn 函数创建异步任务
const p = Promise.resolve().then(() => iteratorFn(item, array))
allTask.push(p) // 保存新的异步任务
// 当 poolLimit 值小于或等于总任务个数时,进行并发控制
if (poolLimit <= array.length) {
// 当任务完成后,从正在执行的任务数组中移除已完成的任务
const e = p.then(() => executing.splice(executing.indexOf(e), 1))
executing.push(e) // 保存正在执行的异步任务
if (executing.length >= poolLimit) {
await Promise.race(executing) // 等待较快的任务执行完成
}
}
}
return Promise.all(allTask)
}
- 请求下载分片内容
设置请求头Accept-Ranges的开始和结束,获取文件的分片内容,因为下载完文件还需要合并所有分片,所以还需要文件切片的索引值。
/**
* 下载分片内容
* @param {*} start
* @param {*} end
* @param {*} i
* @param {*} ifRange
*/
async getBinaryContent (start, end, i, ifRange = true) {
try {
let options = {
responseType: "blob",
}
// 如果需要分片下载,则加上 Range 请求头
if (ifRange) {
options.headers = {
Range: `bytes=${
start}-${
end}`
}
}
const result = await http.get(`/down/${
this.fileName}`, options);
return {
index: i, data: result };
} catch (error) {
return {
}
}
},
- 文件合并和下载
我们获取到的文件数据是ArrayBuffer类型,这个数据是不能直接操作的,所以我们需要使用类型数组来操作它,这里我们使用Unit8Array类型数组来合并文件数据,最后通过生成BlobUrl来进行文件下载。
const saveFile = (name, buffers, mime = 'application/octet-stream') => {
//文件合并,result为合并的文件数据
if (!buffers.length) return
const totalLength = buffers.reduce((acc, value) => acc + value.length, 0)
const result = new Uint8Array(totalLength)
let length = 0
for (const array of buffers) {
result.set(array, length)
length += array.length
}
//文件下载
const blob = new Blob([result], {
type: mime })
const blobUrl = URL.createObjectURL(blob)
const a: HTMLAnchorElement = document.createElement('a')
a.download = filename
a.href = blobUrl
a.click()
URL.revokeObjectURL(blobUrl)
}