
王北南,Alluxio软件工程师,也是PrestoDB的committer。加入Alluxio之前,北南博士是Twitter Presto团队的技术负责人,并为Twitter的数据平台构建了大规模分布式SQL系统。他在性能优化、分布式缓存和大数据方面有12年的工作经验。王北南博士毕业于雪城大学计算机工程专业,专业方向是对分布式系统进行信号模型检测和运行验证。
陈寿纬,Alluxio软件工程师,在Alluxio主要负责数据湖方案结合、结构化数据与高可用性优化等相关工作。陈寿纬博士毕业于罗格斯大学电子与计算机工程系,专业方向是大规模分布式系统的性能与稳定性优化。
查询Iceberg表
Create Table

可能很多人用Presto只用 Hive Connector,其实Iceberg connector跟Hive差不多,不管从实现,还是从功能上都有互相的参照,尤其是在实现方面使用了非常多的Hive connector底层的代码。它创建table也是一样,我们可以从一个 TPC-DS数据的 customer表里抽几列再创建一个table,你可以指定这个数据的格式,可以是Parquet也可以是ORC格式。也可以同时指定分区(partition),这里用出生的月份这样会容易些,因为月份只有12个,也就是12个分区。我们创建了这个表之后,跟Hive表一样,你可以select这个表,select* from Iceberg.test,test1是表名,你可以用一个美元符号$加上partitions,这样你可以把这个表的所有分区给列出来。每个分区都会有一个统计,比如说下面第一行8月,能看到它有多少行有多少个文件,大小总共有多大,同时对于customer_sk这一列,能看到最小值多少最大值多少。后面的birth date就是日期,对于8月最小值是1,最大值是31,空值有若干。因为8月是大月,后面的9月是小月最大值是30,每一个partition都会有自己的统计,后面我们会再讲, predicate pushdown会用到这个,可以让我们跳过很多的分区,其实Hive也有这个功能,只不过可能有些数据在Hive metastore上,元数据这里没有的话,用不上这个功能,但在Iceberg上它内嵌在table里了,就会比较好用一些。
Insert

前面提到Iceberg会有一些事务(transaction)支持。我们试着往这个表里加入一行, SK是1000,日期是40,我特意插入了一个不可能存在的日期月份是13,这样等于说我新创建了一个partition。其实不管是不是新建partition都会产生一个新的快照(snapshot),在Presto里,通过select * from 表, 表的名字上面加一个美元$符号,然后再加一个snapshots,就可以列出这个 table所有的snapshots。大家可以看到有两个snapshots,因为新建table时出一个,插入一行之后又出一个,manifest list就有两个avro文件,第二个snapshot基于第一个,第二个snapshot 的parent ID就是第一个snapshot的parent ID,待会我们会用snapshot ID来做time travel。
对于这样一个文件,我们加了一个partition进去之后会怎么样,看一下这个目录,其实Iceberg的目录非常简单,我们指定一个目录,它在这下面就创建一个test1,里边有两个文件夹,一个是data (数据),一个是metadata(元数据)。数据里边是按照月份来分区的,这里面是 14个分区,因为12个月份,还有个空值,再加上我们新加的月份13,等于现在一共14个分区,这个文件就是这么组织的,而每个目录下面就是parquet文件。
Query
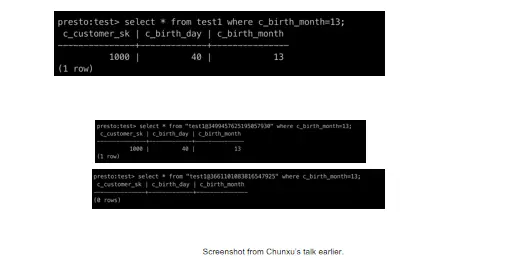
那么我们在query的时候会发生什么呢?
这个其实大家都会——写个SQL,从这个select*from Test1的时候,指定一个条件,我这个月份是13,那就把我刚才新插入的那一条记录给调出来了。我后面会介绍一下怎么做时间穿梭(Time travel),我们可以看到在这个表名test1这有个@符,后面我可以加一个 snapshot ID,如果我用第二个(快照)snapshot,就能查到这个记录,如果我用第一个snapshot就没有这个记录,为什么?因为第一个query发生在插入这条记录之前。这还挺有用的,因为有的时候就想查一下我这个表昨天是什么样的。但这也有问题,如果你频繁插入数据的话,就会产生大量的snapshot,avro里面就会有大量的数据。那我们是不是要丢掉一些过期的快照?这也是个优化点,现在presto还没有,但以后我觉得我们会把它做进去。
另外有些朋友会问,既然Iceberg connector有这个功能了,能不能用它来取代MySQL,做OLTP来处理一些在线的transaction数据? ——可以,但是不能像MySQL那么用,频繁的插入数据还会带来一些问题,需要做更深入的优化,直接这么用的话会产生大量的小文件和快照,但这些都有办法解决,我们后面会把它慢慢迭代进去。
Schema Evolution
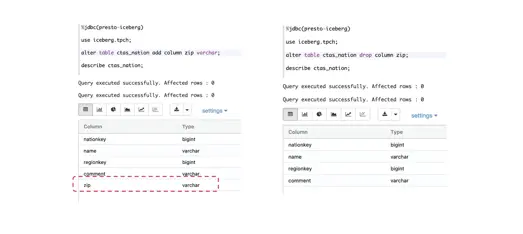
这个是我的前同事Chunxu做 Schema Evolution的时候截的一张图。可以看到这也是Iceberg的一个亮点,就是说这个表原来有几列,我可以加一列或者改一列,当然这也不难,因为原来 Hive table也可以这样做,但是做完之后,你的table还能不能查?Iceberg给我们的答案是 table改完了还能查,当然这里边也有tricky的地方,里面的数据也不是这么完整,但是不管怎么样它没出错,你先改好table,用老的query还能够查到。这个功能我觉得还是挺实用的,因为各个公司 table总在改,改完之后 table在presto这边还是可以查的。
Iceberg连接器更新
接下来会讲一下我们社区最近这一两个月的一些贡献,希望能够对大家有帮助,我主要讲是Presto DB,Trino那边是另外一套故事,尽量兼顾来讲。
New Features

最近这两三个月,有几个功能进来之后给我们的一些东西解锁了。
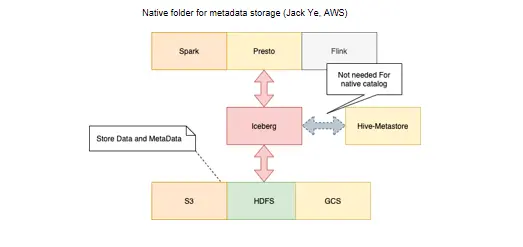
1.第一份credit要重点给亚马逊公司AWS 的Jack Ye,他做了一个 native folder的支持,这个在Iceberg叫做Hadoop catalog,盘活了我们的很多功能,解决了我们非常多的痛点。
2.另外就是腾讯的Baolong,他把local cache这个功能给加上去了,现在Iceberg connector可以和 RaptorX那一套,就是Hive connector里的cache,同样享受local cache,得到提速。当然这个不是那么简单,那么开箱即用,可能会需要一些配置,后面我会再详细地讲。
3.接下来就是Uber的Xinli Shang,我们俩给parquet做了升级。Xinli Shang是Parquet社区的chair,他给parquet做了升级后,我们拿过来放在presto里,我们的升级工作历时大概半年,升级到新的parquet之后,我们也解锁了Iceberg 1.12,有更多新的功能,包括对v2 的Iceberg table的支持。
4.还有一个predicate pushdown,在后面Beinan(Alluxio)也会详细地讲一下,这是可以优化查询的一个功能。
Iceberg Native Catalog
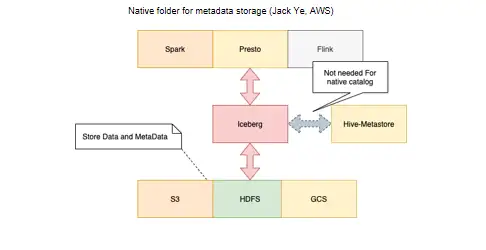
这就是我刚才提到的 Jack做的 native catalog——原来在Iceberg叫Hadoop catalog,其实Iceberg数据也是存在 S3、HDFS、GCS里的。它的每一个table下面既有元数据,又有数据,那为什么还需要Hive metastore,还要去Hive metastore里取元数据呢?这是因为最开始的Hive catalog还是要依赖Hive的元数据的,我们需要找到 table的路径,到这个table里把Iceberg自己的元数据加载出来,然后用 presto进行查询。有了 Jack这个很好的修改,我们可以支持Hadoop catalog,你直接给它一个路径,table都放在这个路径下面,它到这个路径上去扫一下,就可以录入所有的table,像table1,table2,table3, 每个table多少元数据,我们就不再需要Hive metastore了。有了这个native catalog之后, presto和Iceberg的结合就完整了。本来我们还依赖于一个额外的元数据存储,现在我们可以直接使用native catalog,这解决了非常多的痛点。
Iceberg Loca Cache
这个是之前有朋友问的 local cache,这个功能可能两个礼拜以前才merge的,腾讯的Baolong特别厉害几天就把这功能给做好了。那么为什么这个东西这么快就做好了,这个得从Iceberg connector的实现说起,是因为Iceberg connector和 Hive connector用的是一套东西,都是同一个Parquet reader或者是ORC reader。所以说我们当时在 RaptorX这个项目里,就是在 Hive下面做local cache,这个项目里用的很好的 local cache,在 Facebook、头条、还有Uber都取得很好效果,我们就把这个local cache直接搬到Iceberg里来用,直接能取得一个很好的效果。
这个里边有关键点得跟大家说一下,这个 local cache像是每个worker自己的私有缓存,它不像Alluxio cache那样,是一个分布式的、弹性的,可以部署比如说100个节点或200个节点,可以水平扩展的。但是这里不一样,这里边给你一个就近的小容量的local缓存,给每个worker可能500g或者1TB的一个本地磁盘,用来当作缓存使用。
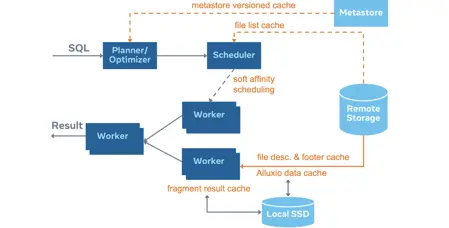
这里就有一个问题, Presto在做plan的时候是随机分的,比如说每一个大的table下面有1万个partition,上面可能有100万个文件,随便拿一个文件,它不一定去哪个worker,每个worker cache不了那么多数据。于是我们就有一个soft affinity scheduling,有点像做负载均衡的时候会有一个affinity的功能一样,也就是粘连,比如说这个文件去work1,以后就一直去work1,这样的话work1只要把它cache了,你再访问这个文件它的cache命中率就提高了,所以这个affinity的功能是一定要打开的。
如果你发现local cache命中率很低,你就要看是不是affinity做的不对,是不是你的节点频繁增加或者减少,即使你什么都不调,你只要把 soft affinity打开,用一个比如说500g或者1TB的 local cache,它的命中率应该是不会低的,应该是有百分之六七十的命中率,这个是数据量很大的情况,数据量小的话可能有100%的命中率。
事实上就是Presto交给Iceberg来做一个plan。在收到SQL请求后,Presto解析,把 SQL拆一拆,告诉Iceberg要查什么,Iceberg就会生成一个plan,说要扫哪些文件,然后presto通过 soft affinity把这些文件分发给特定的worker,这些worker就会去扫这些文件,如果命中了本地cache扫本地文件,如果没命中本地cache就扫远程文件。其实Alluxio就是一个二级的存储,本地没命中去Alluxio,Alluxio还没命中去三级存储。
当然我们后续会有semantic cache,这个主要是给Hive做的,但是就像我前面提的,因为Iceberg和Hive底层的实现是同源的,因此结果我们都可以用。这里跟大家通报一个最新的进展,是AWS的Iceberg 团队Jack刚跟我们讲的,我们可能会不再使用presto的Hive 实现,当然这是可选的,你可以继续使用presto的 Hive实现,也可以使用Iceberg的native实现。这样以后Iceberg有什么新的功能,我们就不依赖Hive,这也是好事,而且我们可以引入更多向量化的东西,这是个长期的 plan,可能明年大家才会见到。
Iceberg Native Catalog
对于一个presto的查询来说,我们就说select* from table,比如说 city=‘Beijing’,profile age>18岁,这样一个查询,它其实就生成了左边这三个块的plan,先scan,scan完了给filter,filter完了给输出,其实就是扫完表之后,看哪些符合条件就输出但这个没有必要。比如说我们这个表是按照城市做的分区,没有必要扫整个表,而且每一个文件都有统计的,可能这个文件里年龄都是小于18岁的,就不用扫可以直接跳过了。
在 presto里有个connector optimizer,这个是prestoDB特有的一个东西,可以针对不同的connector来做优化,为什么要针对不同的connector做优化?因为很多人可能是一个Iceberg table去照映一个Hive table,这两个table底下 scan数据源是不一样的,所以你要决定到底把什么条件下推下去。其实有一个最简单的规则,就是Iceberg目前不支持profile.age这种有嵌套的字段的下推,那我就把 city下推,就把city的 filter下推到table scan,和table scan合并成一个plan节点,就是这个地方既做filter又做scan,然后下推给Iceberg,这里我把age>18岁留着,scan好了之后再filter,这个不是最优的方案,但这是最基本的规则。
Predicate Pushdown Resource Usage

我们来看看效果,这不是一个正规的Benchmark,就是刚才我建的 table,新加了一条记录,月份等于13的那个,如果我不开下推的话,是左边这种情况,它扫了200万条记录,input数据是200多KB;开了下推之后,它只扫描一条记录,时间和数据都有非常大的提升,它只扫特定的分区。这种查询在现实中遇不到,因为现实中肯定是有更多的组合,每个partition下面可能还有更多的文件,这里比较极端一些,只有这一个文件。其实这样效果不明显,文件越多效果越好,推荐大家试一试。
之前提到了 Native Iceberg IO,我们会使用Iceberg reader和writer来取代Hive实现,让它彻底的分开,也可能两个都支持,这个就是我们将要进行的工作,敬请期待。
Ongoing Work

另外一个是物化视图(materialized view),是我的前同事Chunxu在做的,这也是重要的一个功能,让临时表能够把数据存到一起,这个也没有那么简单, Facebook也有同事在做这个。我们这里不再多说了,Facebook很快会有一个关于物化视图的新的博客出来。
我会继续把v2 table实现一下删原来只能是按照分区来删,不能删除某一行或某几行,因为删除操作和insert是一样的,会再产生一些新的文件,标注说你这几行要被删掉了,然后真正出结果的时候,会把它合并到一起。现在是不支持这个功能的,那么我们要想支持这个功能,有两个做法,一个是使用 native Iceberg IO,另外一个就是在 Parquet的 reader上把要删的这些行标注出来,表示这些行不再显示。以上就是今年年底或明年年初的一些工作和设想,谢谢大家。
更多优质内容可查看Alluxio智库:
