efficientnet在工业检测展现出了极其强大的检测效果,与yolov3和yolov5为同一竞争赛道,曾连续霸版6个月以上,而已efficientnet为基础的其他改进模型在工业检测上也表征出适用性。官方源码的框架是基于tensortflow的,且复现的精度远远不及论文提及的精度。zylo117改进的pytorch代码在更容易复现,也更容易学习。
一、创建环境
还是按照先前的建议,在创建新项目工程的时候,环境的适配性极其重要。使用其他项目的环境在安装新的requirements,容易导致原有项目又要重新安装环境。为避免环境适配性问题,一个项目对应一个环境是最好的。
1、打开Anaconda Prompt
conda create -n efficient python==3.72、激活环境
conda activate efficient成功的话表示环境已经创建完毕。
二、下载源码
1、点击上面的GitHub网站。
2、下载后解压,用pycharm以工程模式打开即可。

三、配置环境
根据复现的源码要求,我们需要安装的包分别有:pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml webcolors,1.4.0的torch和0.5.0的torchvison。
1、首先在pycharm先选择刚刚下载好的环境,在pycharm如何选择环境的话请看作者另一篇yolov8的复现里面有。
2、点击Terminal,最左边括号显示efficient(上面创建的环境)。配置环境时建议关掉梯子或者其他的代理。
(1)
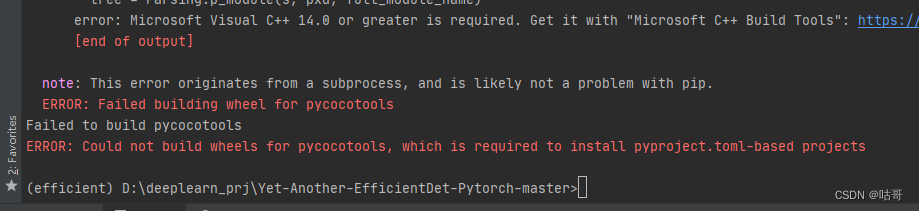
pip install pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml webcolors(2)上述代码最容易发生的一个错误是pycocotools的安装失败,原因是pycocotools不再提供Windows的支持。
解决方法:
pip install pycocotools-windows
这一步表示已安装成功。
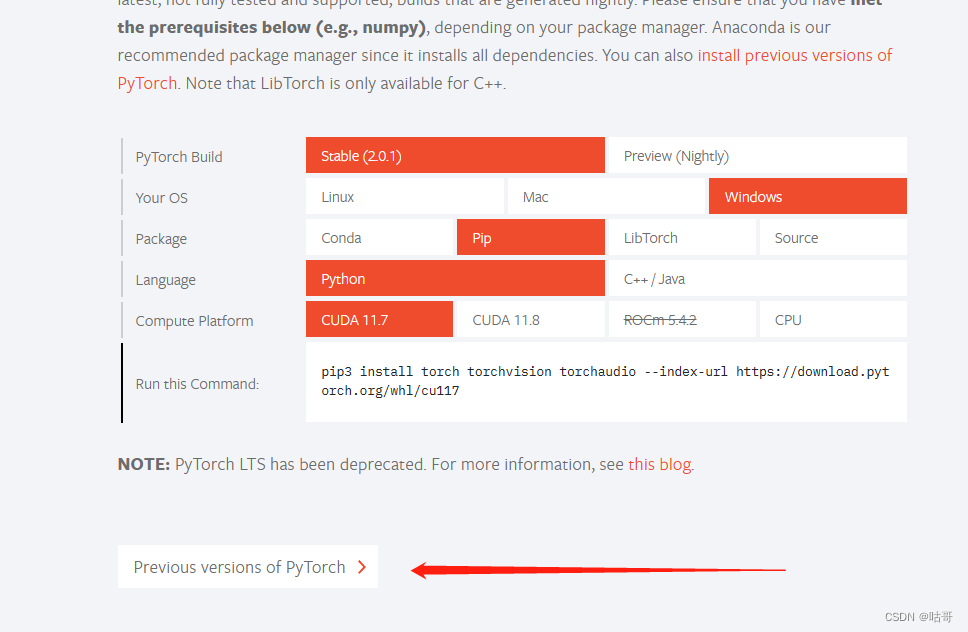
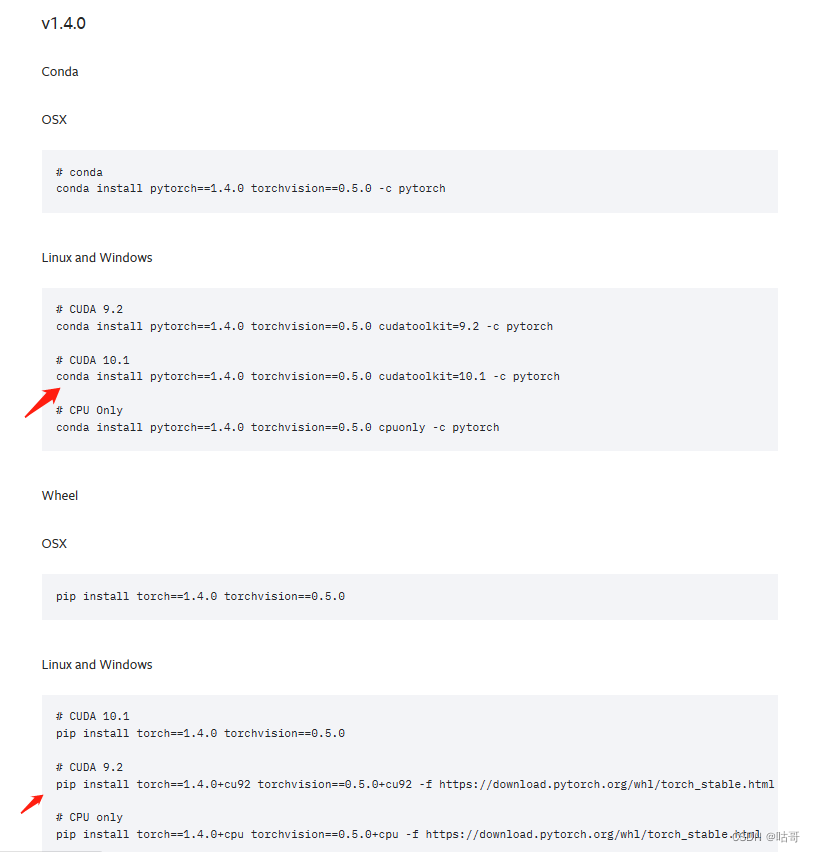
(3) 按照代码流程,下一步要下载torch和torchvision,在windows直接按照源码的步骤可能会下载错误。
建议按照pytorch官网的下载,网址:PyTorch
https://pytorch.org/
下载完成后,在pycharm的Terminal输入
python import torch torch.cuda.is_available() 若返回Ture则可为GPU版本在配置环境的过程种,还可能遇到一个情况,先安装的pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml webcolors。可能后面再下载torch和torchvision会存在能下载但是不可用,import torch失败。
解决方法:先去pytorch官网下载完torch和torchvison。再下载以上的包。
至此,环境配置已经完成。(接下来当以为一切顺利的时候,有可能会碰上cv版本的不适配还是会出错,如果上面的环境都不行,可以私聊作者发一个适配环境包,直接放置在anaconda的envs下面即可,虽然不经常看)
四、初步验证模型是否能测试
1、下载权重
选个D0测试一下:漏了一个瓜皮,效果还行。

选D8测试:漏掉的民咕咕被检测出来了,还有旁边的水杯
2、部分代码解释
这里加载的权重使用了参数compound_coef,说明这个是可选的。
0-8表示下载的权重选择
至此模型已经验证可运行。


五、使用coco数据集训练(或者建立自己的数据集)
(1)准备数据集,有很多途径可以下载,官网,一些私人的百度云分享,csdn里面搜即可,其他数据集也行。
coco数据集得格式:
# for example, coco2017 datasets/ -coco2017/ -train2017/ -000000000001.jpg -000000000002.jpg -000000000003.jpg -val2017/ -000000000004.jpg -000000000005.jpg -000000000006.jpg -annotations -instances_train2017.json -instances_val2017.json我准备得是coco2014数据集 。
(2)创建参数配置文件
创建一个coco.yml(你数据集的名字.yml),放置在projects文件下,源码下载已经有了coco,logo,shape.
(3)其实并不需要从头开始训练coco数据集,这将花费巨大的时间成本 (几个月)。建议
的方式是使用预训练权重训练自定义数据集。甚至可以冻结部分主干网络,迁移学习的概念可以自己在其他地方补。
训练需要修改的地方:
train.py 的参数配置,或者后面直接在代码上加入也行。
此处修改成自己的数据集的绝对路径
efficientdet/dataset.py,修改文件夹名字
a.重新训练的代码:
python train.py -c 0 --batch_size 64 --optim sgd --lr 8e-2(里面的参数不一定适用,特别默认的num_workers=10,如果磁盘空间不够,会出现一句页面太小,建议根据自己的电脑硬件配置来决定)。
训练效果如下:
代码功能还包括停止和接着上次任务继续训练:
停止训练并保存当前的训练进度
Ctrl+c恢复训练
python train.py -c 2 -p your_project_name --batch_size 8 --lr 1e-3 \ --load_weights last \ --head_only Trueb.迁移学习
python train.py -c 2 -p your_project_name --batch_size 8 --lr 1e-3 --num_epochs 10 --load_weights /path/to/your/weights/efficientdet-d2.pth





以上则是就是简单的复现和训练自己想要的数据集格式了,efficientdet还支持VOC格式的,yml文件对应好和dataset换成VOC的数据加载文件即可,更加细节的方面请各位研究者们自己深究了。