使用矩阵计算卷积
GEMM算法
矩阵乘法运算(General Matrix Multiplication),形如:
C = A B , A ∈ R m × k , B ∈ R k × n , C ∈ R m × n C = AB, A\in \mathbb{R}^{m\times k},B\in \mathbb{R}^{k\times n},C\in \mathbb{R}^{m\times n} C=AB,A∈Rm×k,B∈Rk×n,C∈Rm×n
矩阵乘法的计算可以写成如下公式:
C m , n = ∑ k = 1 K A m , k B k , n ; m , n , k ∈ R C_{m,n}=\sum_{k=1}^{K}A_{m,k}B_{k,n};m,n,k\in \mathbb{R} Cm,n=k=1∑KAm,kBk,n;m,n,k∈R
矩阵的乘法操作可以写成如下图所示,

写成伪代码的形式为:
for i=1 to n
for j=1 to n
c[i][j]=0
for k=1 to n
c[i][j] = c[i][j]+a[i][k]*b[k][j]
从上面可以看到使用普通的矩阵乘法运算,其复杂度是 O ( n 3 ) O(n^3) O(n3),这个复杂度相对来说是很高的,当矩阵的维度很大时,运算量会显著增加。
矩阵运算作为基础运算,有大量的科学家对其进行研究,试图降低其运算复杂度。
以Strassen’s Matrix Multiplication Algorithm为例,其将矩阵乘法的运算复杂度降低到了 O ( n l o g 2 7 ) ≈ O ( n 2.81 ) O(n^{log 2^7})\approx O(n^{2.81}) O(nlog27)≈O(n2.81)。
这个算法是Strassen于1969年发布的论文《Gaussian Elimination is not Optimal.》中提出的,主要是通过矩阵块的操作,减少乘法运算的次数。
将矩阵写成矩阵块的形式:
A = ( A 11 A 12 A 21 A 22 ) , B = ( B 11 B 12 B 21 B 22 ) , C = ( C 11 C 12 C 21 C 22 ) A=\begin{pmatrix} A_{11} & A_{12} \\ A_{21} & A_{22} \end{pmatrix},B=\begin{pmatrix} B_{11} & B_{12} \\ B_{21} & B_{22} \end{pmatrix},C=\begin{pmatrix} C_{11} & C_{12} \\ C_{21} & C_{22} \end{pmatrix} A=(A11A21A12A22),B=(B11B21B12B22),C=(C11C21C12C22)
由 C = A B C=AB C=AB,可得:
C 11 = A 11 B 11 + A 12 B 21 C 12 = A 11 B 12 + A 12 B 22 C 21 = A 21 B 11 + A 22 B 21 C 22 = A 21 B 12 + A 22 B 22 \begin{matrix} C_{11} = A_{11}B_{11} + A_{12}B_{21} \\ C_{12} = A_{11}B_{12} + A_{12}B_{22} \\ C_{21} = A_{21}B_{11} + A_{22}B_{21} \\ C_{22} = A_{21}B_{12} + A_{22}B_{22} \end{matrix} C11=A11B11+A12B21C12=A11B12+A12B22C21=A21B11+A22B21C22=A21B12+A22B22
写成上面的形式,只是把矩阵的乘法写成了块的运算,并没能改变乘法的次数,除了分块可以在硬件上实现并行运算,并没有改变算法本身的复杂度。
Strassen将矩阵的运算写成如下形式,
M 1 = ( A 11 + A 22 ) ( B 11 + B 22 ) M 2 = ( A 21 + A 22 ) B 11 M 3 = A 11 ( B 12 − B 22 ) M 4 = A 22 ( B 21 − B 11 ) M 5 = ( A 11 + A 12 ) B 22 M 6 = ( A 21 − A 11 ) ( B 11 + B 12 ) M 7 = ( A 12 − A 22 ) ( B 21 + B 22 ) \begin{align} M_1 & = (A_{11} + A_{22}) (B_{11} + B_{22}) \\ M_2 & = (A_{21} + A_{22})B_{11} \\ M_3 & = A_{11}(B_{12} − B_{22}) \\ M_4 & = A_{22}(B_{21} − B_{11}) \\ M_5 & = (A_{11} + A_{12})B_{22} \\ M_6 & = (A_{21} − A_{11})(B_{11} + B_{12}) \\ M_7 & = (A_{12} − A_{22})(B_{21} + B_{22})\end{align} M1M2M3M4M5M6M7=(A11+A22)(B11+B22)=(A21+A22)B11=A11(B12−B22)=A22(B21−B11)=(A11+A12)B22=(A21−A11)(B11+B12)=(A12−A22)(B21+B22)
C 11 = M 1 + M 4 − M 5 + M 7 C 12 = M 3 + M 5 C 21 = M 2 + M 4 C 22 = M 1 − M 2 + M 3 + M 6 \begin{align} C_{11} &= M_1 + M_4 − M_5 + M_7 \\ C_{12} &= M_3 + M_5 \\ C_{21} &= M_2 + M_4 \\ C_{22} &= M_1 − M_2 + M_3 + M_6 \end{align} C11C12C21C22=M1+M4−M5+M7=M3+M5=M2+M4=M1−M2+M3+M6
从上面这11个公式中可以看到,一次分治后降低到了7次乘法运算,相较于原来的8次少了一次,可以证明,这样可以将矩阵的乘法复杂度降低到 O ( n l o g 2 7 ) O(n^{log 2^7}) O(nlog27)。
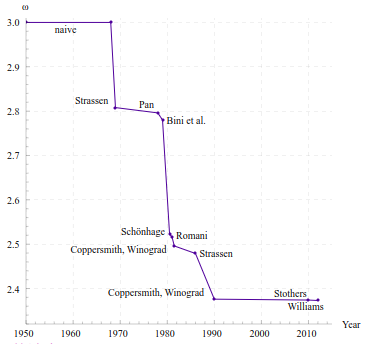
在此之后1990年Coppersmith和Winograd合作提出的Coppersmith–Winograd算法将复杂度降低到了 O ( n 2.376 ) O(n^{2.376}) O(n2.376),2014年斯坦福大学的Virginia Williams发表的论文Multiplying matrices in o(n2.373) time将复杂度降低到了 O ( n 2.373 ) O(n^{2.373}) O(n2.373),其演变过程如下图:
卷积运算
卷积运算的过程就是将卷积核在输入数据上滑动乘积求和的过程,其运算过程可以参考之前的文章
其计算方式第一直观的想法肯定是根据卷积的定义,逐元素相乘求和,写成伪代码的形式如下:
input[C][H][W];
kernels[M][K][K][C];
output[M][H][W];
for h in 1 to H do
for w in 1 to W do
for o in 1 to M do
sum = 0;
for x in 1 to K do
for y in 1 to K do
for i in 1 to C do
sum += input[i][h+y][w+x] * kernels[o][x][y][i];
output[o][w][h] = sum;
这种方式落到了逐个元素的运算上,不利于对运算做优化,考虑第一部分对矩阵乘法运算优化的介绍,考虑能不能将卷积运算转换成矩阵乘法的运算呢?答案当然是可以。
这正是引入img2col算法的初衷,因为现在的GPU/CPU基本都有对矩阵运算加速的BLAS库(Basic Linear Algebra Subprograms)。
img2col的方法将卷积的输入和卷积核都转成了矩阵的形式,最后卷积的运算变成了矩阵的乘法,如此就可以使用矩阵的加速运算了。
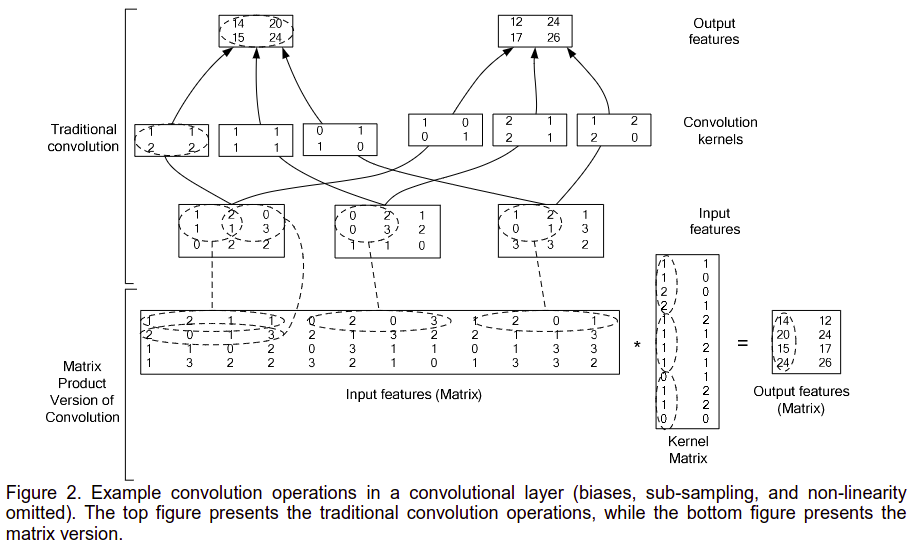
如上图,
输入是 W i × H i × C i = 3 × 3 × 3 W_i\times H_i \times C_i=3\times 3 \times 3 Wi×Hi×Ci=3×3×3的图像
卷积核的大小为 C i × C o × k w × k h C_{i}\times C_{o}\times k_{w} \times k_{h} Ci×Co×kw×kh
卷积步长 s t r i d e = 1 stride=1 stride=1
输出的大小为 W o × H o × C o = 2 × 2 × 2 W_o\times H_o \times C_o=2\times 2 \times 2 Wo×Ho×Co=2×2×2
转换成矩阵乘法时,
输入数据转换成矩阵的 s h a p e = ( W o ∗ H o ) × ( k w ∗ k h ∗ C i ) shape=(W_o*H_o)\times(k_w* k_h *C_i) shape=(Wo∗Ho)×(kw∗kh∗Ci)
卷积核转换成矩阵的 s h a p e = ( k w ∗ k h ∗ C i ) × C o shape=(k_w* k_h *C_i)\times C_o shape=(kw∗kh∗Ci)×Co
使用乘法后得到的卷积运算的输出 s h a p e = ( W o ∗ H o ) × C o shape=(W_o*H_o)\times C_o shape=(Wo∗Ho)×Co
可以看到,输出的矩阵,一列表示一幅卷积输出的图像,想比这是为什么称为img2col吧。
使用img2col实现卷积的代码如下:
int Conv2D::img2col(const std::vector<Eigen::MatrixXd> &x, std::vector<Eigen::MatrixXd> &out) const
{
out.clear();
assert(x.size() == channel_in_);
int w_o = x[0].rows();
int h_o = x[0].cols();
w_o = (w_o - kernel_w_) / stride_ + 1;
h_o = (h_o - kernel_h_) / stride_ + 1;
Eigen::MatrixXd x_mat(w_o * h_o, kernel_w_ * kernel_h_ * channel_in_);
for(int r = 0; r < h_o; ++r) {
for(size_t c = 0; c < w_o; ++c) {
for(size_t i = 0; i < channel_in_; ++i) {
for(size_t h = 0; h < kernel_h_; h++) {
for(size_t w = 0; w < kernel_w_; w++) {
x_mat(r * w_o + c, i * kernel_h_ * kernel_w_ + h * kernel_w_ + w)
= x[i](r * stride_ + h, c * stride_ + w);
}
}
}
}
}
auto t1 = std::chrono::steady_clock::now();
Eigen::MatrixXd res = x_mat * (*kernel_mat_);
auto t2 = std::chrono::steady_clock::now();
auto d = std::chrono::duration_cast<std::chrono::microseconds>(t2 - t1).count();
std::cout << "img2col duration: " << d << "us" << std::endl;
for(size_t i = 0; i < channel_out_; i++) {
auto so = res.col(i);
Eigen::MatrixXd m(h_o, w_o);
for(int r = 0; r < h_o; ++r) {
for(size_t c = 0; c < w_o; ++c) {
m(r, c) = so(r * h_o + c);
}
}
out.push_back(m);
}
return 0;
}
通过实验对比,img2col的方式比普通卷积的要快很多。
raw conv duration: 3530us
img2col duration: 260us
完整的实验代码可以参考仓库:
https://gitee.com/lx_r/basic_cplusplus_examples/tree/master/basic_cv