在此篇文章中,我们将理解数据,数据清洗,数据分析并最后可视化结果。通过这篇文章将一起学习和巩固很多知识。
理解数据
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
import re
import datetime
from pyecharts import options as opts
from pyecharts.charts import Pie,Bar,Grid,Calendar,Tab,Line,Scatter,Gauge
# 会员信息表
customers = pd.read_excel('F:\cumcm2018c1.xlsx')
customers.head()

# 销售流水表
orders = pd.read_csv('F:\cumcm2018c2.csv')
orders.head()
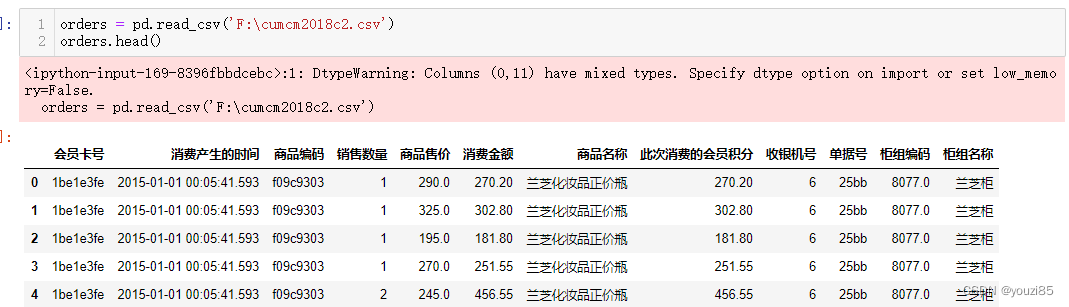
print(f'会员信息表中有{customers.shape[0]}条记录,{customers.shape[1]}个字段')
print(f'订单流水表中有{orders.shape[0]}条记录,{orders.shape[1]}个字段')

数据清洗
会员信息表预处理
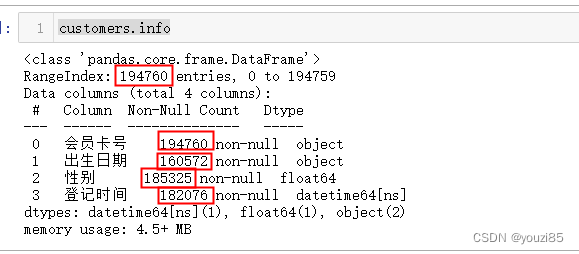
# 查看会员表的信息,发现除了会员卡号,其余三个信息都是有空值情况
customers.info()
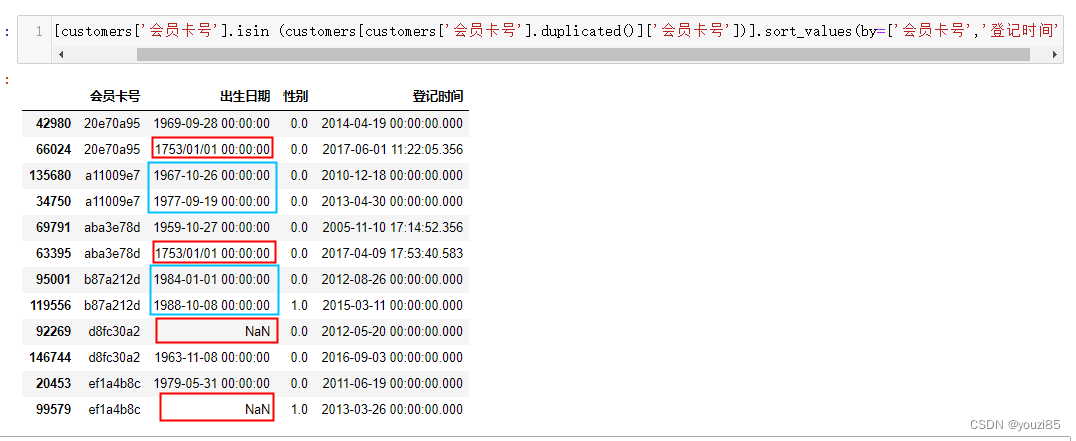
# 会员信息表中的用户应该是唯一的,但是表中出现了重复值,把这些重复的会员找出来查看
# 重复项有多少
customers['会员卡号'].duplicated().sum()

customers[customers['会员卡号'].isin (customers[customers['会员卡号'].duplicated()]['会员卡号'])].sort_values(by=['会员卡号','登记时间'])
# 查看这6个重复的会员信息,从图中可以看出,红色标出的出生日期要不是有明显错误,要不是没填,就认为该条信息是用户随便写的,因为删掉这几条数据。还有两个用户的信息,我们默认保留第一条数据
# 删掉有误数据
customers.drop(index=[66024,34750,63395,119556,92269,99579],inplace=True)
# 查看表中空值数据占比
customers.isna().mean()
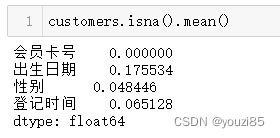
# 对于会员表中,因为空值数据性别和登记时间空的数据比较少,所以满足出生日期,性别,登记日期全部为空的用户肯定不超过数据的5%,所以我们直接进行删除
# 先复制一份,再操作,不修改原数据
customers_copy=customers.copy()
# customers.isna().sum(axis=1)==3 得到三个字段都是空的行
customers.drop(index = customers[customers.isna().sum(axis=1)==3].index,inplace=True)
# 删除后查看数据情况
print(customers.isnull().mean())
customers.info()

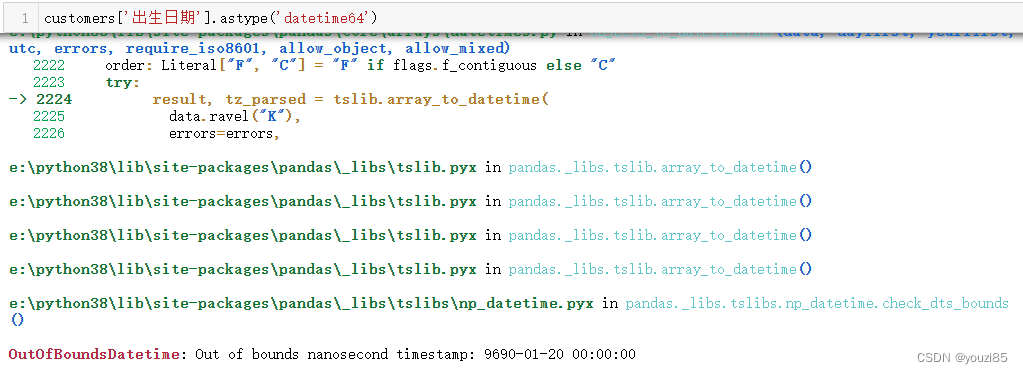
# 对于出生日期,因为我们需要计算会员的年龄,而目前数据类型是object类型,我们需要转成日期类型
customers['出生日期'].astype('datetime64')
# 或者
customers['出生日期'] = pd.to_datetime(customers['出生日期'])
# 都是会报错的,因为出生日期这个数据中,有用户随意输入,有不满足条件的数据在内,所以无法通过这两种方法将数据类型转成日期类型
# 因为我们想知道出生日期,是为了知道这些会员的年龄,好在后面用户画像中了解我们这些用户的年龄,因此我们直接计算出一列作为年龄
def tim(x):
try:
return int(datetime.date.today().year)-int(datetime.datetime.fromisoformat(str(x)).year)
except ValueError:
pass
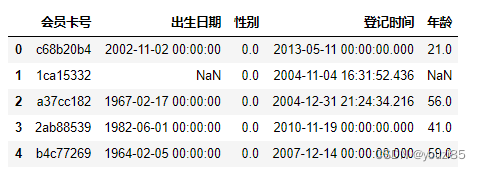
customers['年龄'] = customers['出生日期'].apply(tim)
# datetime.datetime.fromisoformat是将字符串转化为日期类型
# datetime.datetime.year得到日期的年份,但是是float类型
# datetime.date.today() 获得今天的日期
customers.head()
customers.isnull().mean()
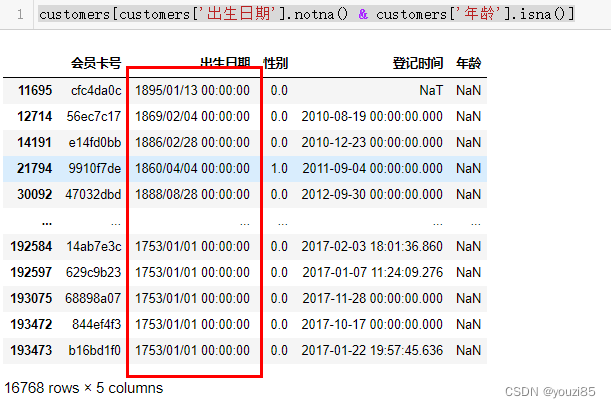
# 发现出现有出生日期的数据,但是没有转化成年龄,查看问题原因

# 查找为什么有出生日期的没有转化为年龄
# 就是出生日期这一列不是空的,但是年龄是空的数据
customers[customers['出生日期'].notna() & customers['年龄'].isna()]
# 发现出现这个现象的原因是部分数据出生日期的格式不正确,所以需要转化数据格式再转化为年龄
# 调整上面的函数,使格式不正确的出生日期也能转化为年龄
def tim(x):
try:
return int(datetime.date.today().year)-int(datetime.datetime.fromisoformat(str('-'.join(str(x).split('/')))).year)
except ValueError:
pass
customers['年龄'] = customers['出生日期'].apply(tim)
customers.isnull().mean()

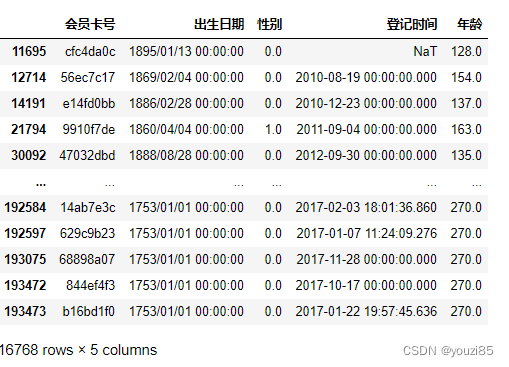
# 根据年龄查看用户是否存在乱输入信息情况
# 因为正常来消费购物的人,年纪不可能是小于0岁或者大于100岁的,查看用户数情况
customers.query('年龄<0 | 年龄>=100')
# 因为出生日期有问题的消费者比较多,加上出生日期没有的用户数大概有20%的数据有问题,因为出生日期只有在描述用户画像年龄的时候会用到,所以不删除,先保留着
# 查看登记时间问题数据
# 因为登记时间会员录入时间,一般不应该是有问题的,并且登记时间数据只占所有数据的3%,所以直接删掉
customers.dropna(subset = ['登记时间'],inplace=True)
# 查看等级时间中是否有问题数据
print('最小时间:',customers['登记时间'].min(),'最大时间:',customers['登记时间'].max())
# 将登记时间分成10组,看看登记时间分布
pd.cut(customers['登记时间'],10).value_counts()
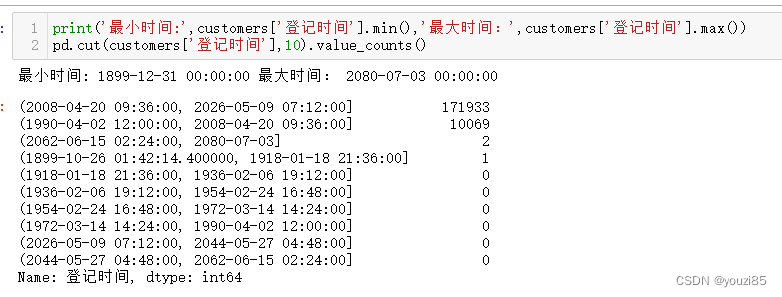
# 发现数据都集中在1990年到2026年,删掉那三个异常值
customers.drop(index = customers.query('登记时间<1990 | 登记时间>"2023-05-09 07:12:00"').index,inplace=True)
# 再次查看登记时间数据,看看是否还有异常数据(因为之前数据分组是分到2026年,但是现在都还没到2026年,若是出现,则表示还是有异常数据)
print(customers['登记时间'].min(),customers['登记时间'].max()) # 得到结果,现在数据正常

订单流水表预处理
# 查看订单流水表情况
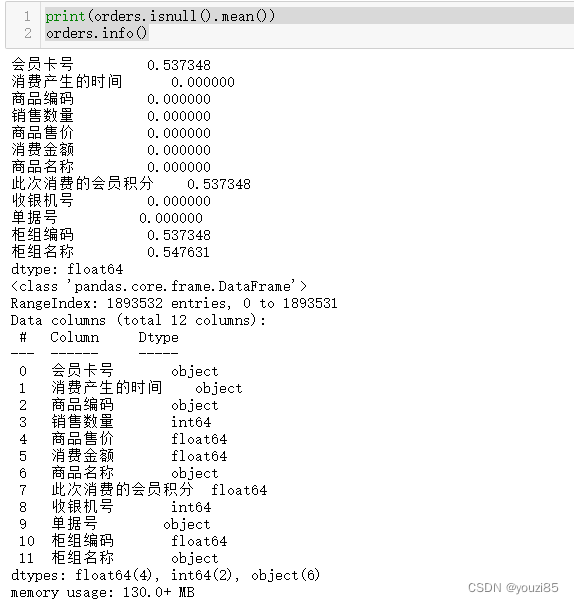
print(orders.isnull().mean())
orders.info()
# 因为想之后想看看用户的购买偏好,所以手动添加一列type,手动归类商品的类别
def cond(x):
facial = ['化妆','美白','眼','唇','腮','精华','隔离','面膜','粉底','气垫','口红','乳液','眉','鼻','高光','护肤','睫毛','霜','洁颜','细致','毛孔','保湿','淡斑','修容','遮瑕','膏','啫喱','脸','滋润','肌','胭脂','颊','抗老',
'喷雾'
]
shoe = ['鞋','靴','高跟','帽']
clothes = ['衣','裙','裤','女装','男装','服饰']
perfume = ['香氛','香水','香薰']
gold = ['黄金','铂金','玉石','宝石','玉','镶嵌','饰品']
house = ['床','屋','家','木','厨']
food = ['茶','巧克力','阿胶','酒','糖']
pattern = '.*['+'|'.join(facial)+'].*'
pattern1 = '.*['+'|'.join(shoe)+'].*'
pattern2 = '.*['+'|'.join(clothes)+'].*'
pattern3 = '.*['+'|'.join(perfume)+'].*'
pattern4 = '.*['+'|'.join(gold)+'].*'
pattern5 = '.*['+'|'.join(house)+'].*'
pattern6 = '.*['+'|'.join(food)+'].*'
if re.search(pattern,x):
return '化妆护肤类'
elif re.search(pattern1,x):
return '鞋帽类'
elif re.search(pattern2,x):
return '服装类'
elif re.search(pattern3,x):
return '香水类'
elif re.search(pattern4,x):
return '金类玉石'
elif re.search(pattern5,x):
return '家装家用'
elif re.search(pattern6,x):
return '食品类'
else:
return '未知分类'
orders['type'] = orders['商品名称'].apply(cond)
orders.head()
# 可以看出会员号很多都缺失,但是会员号是作为两张表连接的键,必须保证存在的,所以这边再准备一份数据,用于连接两张表的时候使用
# 首先复制一份
orders_copy = orders.copy()
orders = orders.dropna(subset=['会员卡号'])
orders.isnull().mean()
# 可以看到删掉了订单流水表中的空会员卡号的数据,这里得到的结果中只有柜组名称是空的,但是这个并不影响后面的计算,所以不用处理

# 销售数量是不会出现负数的,查看是否还有问题数据
print(len(orders[orders['销售数量']<0.0])) # 6807
# 删掉销售数量是空的数据
orders.drop(index=orders[orders['销售数量']<0.0].index,inplace=True)
# 查看销售金额是否小于0,有则删掉
print(len(orders[orders['消费金额']<0]))
orders.drop(index=orders[orders['消费金额']<0.0].index,inplace=True)

# 查看会员积分有没有<0的,有就删掉
orders[orders['此次消费的会员积分']<0]
# 删掉
orders.drop(index=orders[orders['此次消费的会员积分']<0.0].index,inplace=True)
将会员表和订单流水表合并起来
# 合并两表
df = pd.merge(customers,orders,how='outer',on='会员卡号')
# 为了保留表中所有数据,采用了全外连接
分析数据
用户画像
- 性别
# 查看会员性别比例及参与消费的性别比例
# 会员男女比例
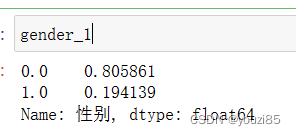
gender_1 = customers['性别'].value_counts()
gender_1 = gender_1/gender_1.sum() # 转化成百分比
# 参与消费的男女比例(表示即存在在customers也存在orders中的数据)
gender_2 = df[df['消费产生的时间'].notna()][['性别','会员卡号']].drop_duplicates()['性别'].value_counts()
gender_2 = gender_2/gender_2.sum() # 转化成百分比

# 结果可视化
pie_1 = Pie()
pie_1.add('会员表性别比例',[list(z) for z in zip(gender_1.index.map({0.0:'女',1.0:'男'}).tolist(),gender_1.values.round(2).tolist())],
center= ['25%','50%'],
radius=[30, 75],
label_opts=opts.LabelOpts(formatter="{b}:{c}"),
)
pie_1.set_global_opts(title_opts = opts.TitleOpts(title='会员性别比例'))
pie_2 = Pie()
pie_2.add('消费会员性别比例',[list(z) for z in zip(gender_2.index.map({0.0:'女',1.0:'男'}).tolist(),gender_2.values.round(2).tolist())],
center = ['70%','50%'],
radius=[30, 75],
label_opts=opts.LabelOpts(formatter="{b}:{c}"),
)
pie_2.set_global_opts(title_opts = opts.TitleOpts(title='消费会员性别比例',pos_left="57%"))
grid = Grid()
grid.add(pie_1,grid_opts=opts.GridOpts(pos_right="70%"))
grid.add(pie_2,grid_opts=opts.GridOpts(pos_left="70%"))
grid.render_notebook()
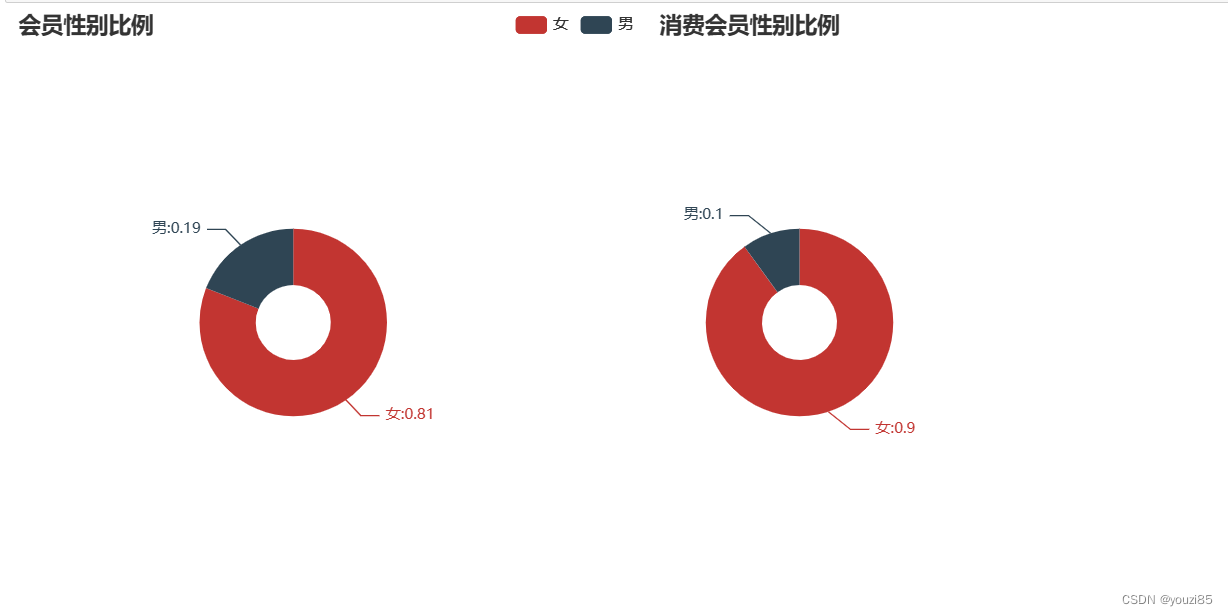
从该饼状图中可以看出,我们商城的会员用户基本是女性,并且参与消费的会员用女性比例更大。
- 年龄
# 查看会员表中年龄分布
print(customers['年龄'].min(),customers['年龄'].max()) # -7857.0 270.0
# 发现会员信息中用户年龄存在乱填现象,我们的用户的年纪是一定处于0-100之间的,所以我们就只取这部分用户查看年龄分布
age_1 = pd.cut(customers.query('年龄>0 & 年龄<100')['年龄'],10).value_counts()
age_1
# 查看销售流水中的年龄分布
# 消费的会员年龄分布
df_age = df.query('年龄>0 & 年龄<100 ')
df_age = df_age[df_age['消费产生的时间'].notna()][['年龄','会员卡号']].drop_duplicates()
age_2 = pd.cut(df_age['年龄'],10).value_counts()
age_2


## 为了作图,将结果按照index排序,并重置索引
age_1 = age_1.sort_index().reset_index()
age_2 = age_2.sort_index().reset_index()
# 图形可视化
bar1 = Bar()
bar1.add_xaxis(age_1['index'].apply(lambda x:str(x)).tolist())
bar1.add_yaxis('年龄分布',age_1['年龄'].values.tolist())
bar1.set_global_opts(xaxis_opts = opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts = opts.TitleOpts(title='会员年龄占比'))
bar2 = Bar()
bar2.add_xaxis(age_2['index'].apply(lambda x:str(x)).tolist())
bar2.add_yaxis('年龄分布',age_2['年龄'].values.tolist())
bar2.set_global_opts(xaxis_opts = opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts = opts.TitleOpts(title='消费会员年龄占比',pos_left='55%'))
grid = Grid()
grid.add(bar1,grid_opts=opts.GridOpts(pos_right='55%'))
grid.add(bar2,grid_opts=opts.GridOpts(pos_left='55%'))
grid.render_notebook()
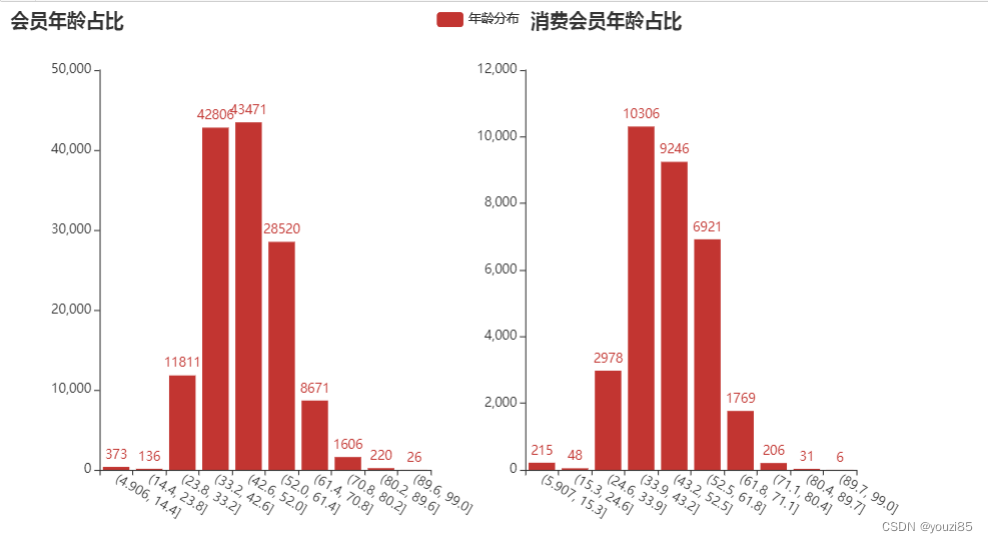
从这里可以看出,我们商城的消费群体年龄主要集中于30+~50+,并且对比两个图表,同样是会员,24-33岁消费会员占该年段会员的比例是最高的,30+和50+的会员后序消费意向会高于40+的会员,猜想可能是年轻并有消费能力的的用户更愿意购物花费,而50+的用户可能处于退休状态,有更多的时间来消费购物。40+年龄段的人可能家庭和工作原因,没有很多的时间来购物。
- 购买偏好
# 因为我想看看会员和非会员各自不同的购买偏好,所以对合并表df,需要增加一列是否是会员列
# 添加会员字段,是会员则是1,不是会员则是0
df['会员']=1
# 因为customers中出生日期,性别,登记时间全为空的数据不存在,出现这种情况,只可能是因为连表的时候仅仅在订单表中存在,而会员表中不存在
df.loc[df['出生日期'].isna() & df['性别'].isna() & df['登记时间'].isna() & df['消费产生的时间'].notna(),'会员']=0
df.head()
# 这里订单商品的类别是我自己手动定的,里面很多商品其实不知道是什么类别,所以都算在其他类,若是现实中如果这么一张类别表,得出的结果才更准确
# 取消科学计数法,没有这个下面这个聚合结果就看不到具体的值,是科学计数
pd.set_option('display.float_format',lambda x:'%.2f'%x)
type_1 = df.loc[df['消费产生的时间'].notna() & df['会员']==1,['消费金额','type']].groupby('type').sum()
type_0 = df.loc[df['消费产生的时间'].notna() & df['会员']==0,['消费金额','type']].groupby('type').sum()


# 为图形展示改变一下重设索引
type_1 = type_1.sort_values(by='消费金额',ascending=False).reset_index()
type_0 = type_0.sort_values(by='消费金额',ascending=False).reset_index()
type_1['占比']=type_1['消费金额']/type_1['消费金额'].sum()
type_0['占比']=type_0['消费金额']/type_0['消费金额'].sum()
# 会员
bar1 = Bar()
bar1.add_xaxis(type_1['type'].tolist())
bar1.add_yaxis('类别',type_1['消费金额'].tolist())
bar1.set_global_opts(xaxis_opts = opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),)
pie1 = Pie()
pie1.add('各类别占比',[list(z) for z in zip(type_1['type'].tolist(),type_1['占比'].tolist())],
radius=[30,75],
center=[700,200]
)
pie1.set_global_opts(legend_opts = opts.LegendOpts(is_show=False))
grid1 = Grid()
grid1.add(bar1,grid_opts=opts.GridOpts(pos_right="30%") )
grid1.add(pie1,grid_opts=opts.GridOpts(pos_left="55%") )
# 非会员
bar0 = Bar()
bar0.add_xaxis(type_0['type'].tolist())
bar0.add_yaxis('类别',type_0['消费金额'].tolist())
bar0.set_global_opts(xaxis_opts = opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),)
pie0 = Pie()
pie0.add('各类别占比',[list(z) for z in zip(type_0['type'].tolist(),type_0['占比'].tolist())],
radius=[30,75],
center=[700,200]
)
pie0.set_global_opts(legend_opts = opts.LegendOpts(is_show=False))
grid0 = Grid()
grid0.add(bar0,grid_opts=opts.GridOpts(pos_right="30%") )
grid0.add(pie0,grid_opts=opts.GridOpts(pos_left="55%") )
tab = Tab()
tab.add(grid1,'会员产品偏好类别')
tab.add(grid0,'非会员产品偏好类别')
tab.render_notebook()
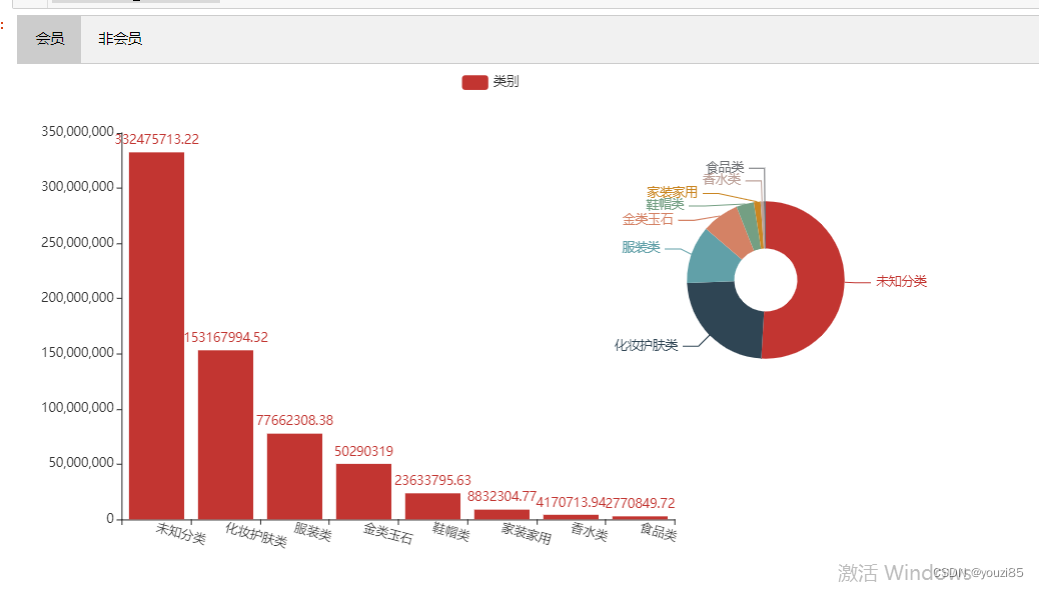

综上,因为未知分类中杂糅了很多类别,但是从已知类别中可以看出,用户的偏好类型基本都是化妆护肤类,其次是服装类。
因此,商城一楼基本都设有大牌美妆专柜,二楼基本是服装专柜,与实际情况相符。
用订单数量来计算用户购买偏好,其中同一个会员同一个消费产生的时间表示同一个订单。
- 购买时间偏好
df['消费产生的时间'] = pd.to_datetime(df['消费产生的时间'])
# 获取消费产生的时间的小时
df['df_hour'] = df['消费产生的时间'].dt.hour
df_hour = df.drop_duplicates(subset=['消费产生的时间']).groupby(by=['会员','df_hour'])['会员卡号'].count()
df_hour = df_hour.reset_index()
# 补充缺少的时间的数据
df_hour = pd.concat([df_hour,pd.DataFrame([[j,i,0] for j in (0,1) for i in range(2,9)],columns=df_hour.columns)]).sort_values(by=['会员','df_hour'])
# 图像展示
bar = Bar()
bar.add_xaxis(np.arange(24).tolist())
bar.add_yaxis('会员',df_hour[df_hour['会员']==1]['会员卡号'].tolist())
bar.add_yaxis('非会员',df_hour[df_hour['会员']==0]['会员卡号'].tolist())
bar.set_series_opts(label_opts = opts.LabelOpts(is_show=False))
bar.set_global_opts(title_opts = opts.TitleOpts(title='用户消费时间偏好柱状图'))
bar.render_notebook()
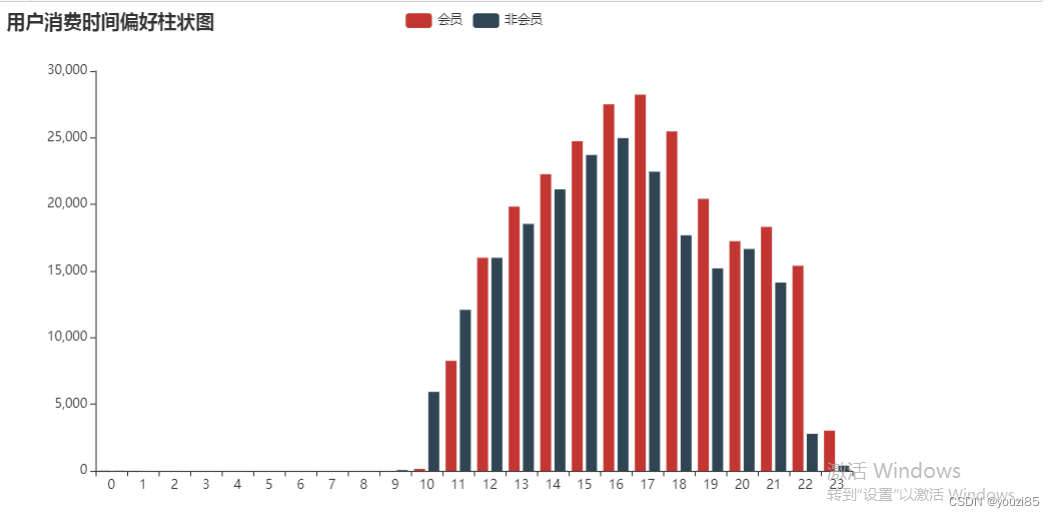
- 购买日期偏好
df['消费日期'] = df['消费产生的时间'].dt.date
# 获得日期日期类型的最大值和最小值
# 2015-01-01
df['消费日期'].sort_values().head(1)
# 2018-01-03
df['消费日期'].sort_values(ascending=False).head(1)
df_calendar = df.drop_duplicates(subset=['消费产生的时间']).groupby(by=['消费日期','会员'])['会员卡号'].count().reset_index()
df_calendar['消费日期'] = pd.to_datetime(df_calendar['消费日期'])
df_calendar
df_tmp = pd.DataFrame(pd.date_range(start='2015-01-01',end='2018-01-03'),columns=['date'])
df_tmp
df_calendar = pd.merge(df_tmp,df_calendar,how='left',left_on='date',right_on='消费日期')
df_calendar['会员卡号'].fillna(0,inplace=True)
df_calendar
data = df_calendar.groupby('date')['会员卡号'].sum().reset_index()
data1 = df_calendar[df_calendar['会员']==1].groupby('date')['会员卡号'].sum().reset_index()
data2 = df_calendar[df_calendar['会员']==0].groupby('date')['会员卡号'].sum().reset_index()
# max_value = data['会员卡号'].max()
# min_value = data['会员卡号'].min()
c1 = Calendar()
c1 .add(
series_name="",
yaxis_data=data.values.tolist(),
calendar_opts=opts.CalendarOpts(
pos_top="120",
pos_left="30",
pos_right="30",
range_=['2015-01-01','2018-02-01'],
yearlabel_opts=opts.CalendarYearLabelOpts(is_show=False),
),
).set_global_opts(
title_opts=opts.TitleOpts(pos_top="30", pos_left="center", title="全部用户员日期消费偏好情况"),
visualmap_opts=opts.VisualMapOpts(
max_=800, min_=0, orient="horizontal", is_piecewise=False
),
# datazoom_opts=opts.DataZoomOpts(),
)
c2 = Calendar()
c2.add(
series_name="",
yaxis_data=data1.values.tolist(),
calendar_opts=opts.CalendarOpts(
pos_top="120",
pos_left="30",
pos_right="30",
range_=['2015-01-01','2018-02-01'],
yearlabel_opts=opts.CalendarYearLabelOpts(is_show=False),
),
).set_global_opts(
title_opts=opts.TitleOpts(pos_top="30", pos_left="center", title="会员日期消费偏好情况"),
visualmap_opts=opts.VisualMapOpts(
max_=500, min_=0, orient="horizontal", is_piecewise=False
),
# datazoom_opts=opts.DataZoomOpts(),
)
c3 = Calendar()
c3.add(
series_name="",
yaxis_data=data2.values.tolist(),
calendar_opts=opts.CalendarOpts(
pos_top="120",
pos_left="30",
pos_right="30",
range_=['2015-01-01','2018-02-01'],
yearlabel_opts=opts.CalendarYearLabelOpts(is_show=False),
),
).set_global_opts(
title_opts=opts.TitleOpts(pos_top="30", pos_left="center", title="非会员日期消费偏好情况"),
visualmap_opts=opts.VisualMapOpts(
max_=500, min_=0, orient="horizontal", is_piecewise=False
),
# datazoom_opts=opts.DataZoomOpts(),
)
tab = Tab()
tab.add(c1,'全部用户')
tab.add(c2,'会员')
tab.add(c3,'非会员')
tab.render_notebook()
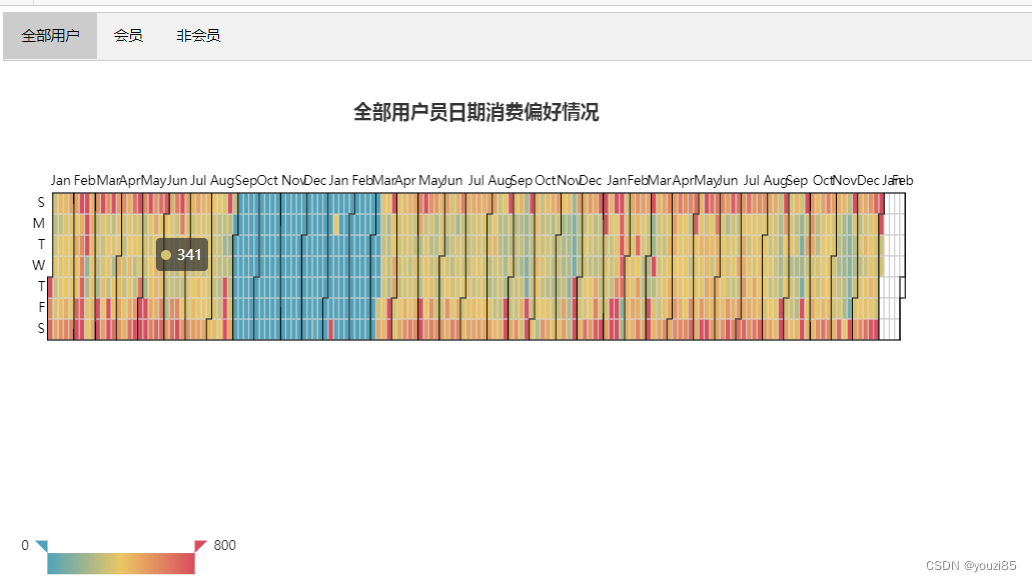
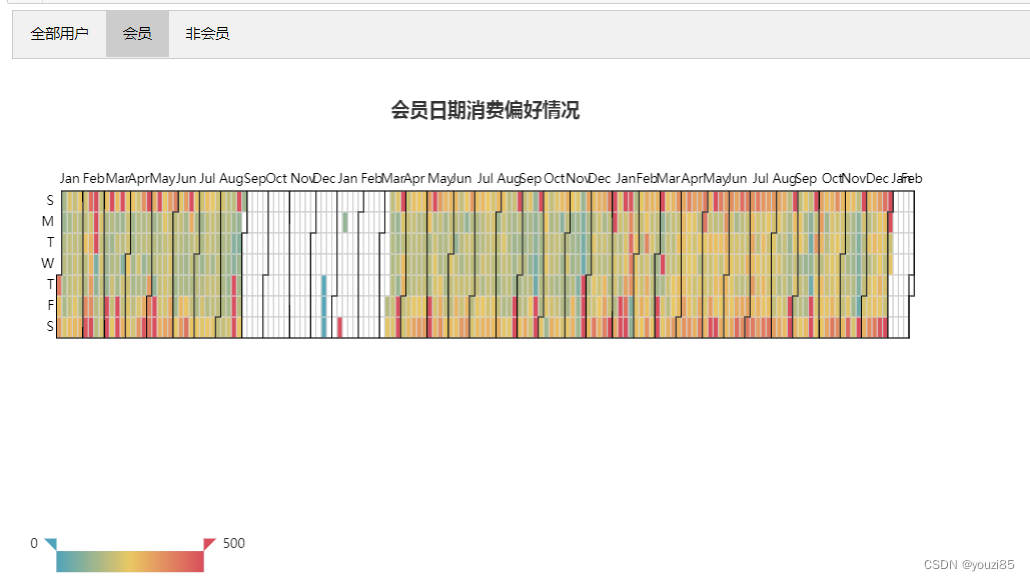

从上图中可以看出,用户消费次数较多的是周六周日,其次是周五
df['消费年份'] = df['消费产生的时间'].dt.year
df['消费季度'] = df['消费产生的时间'].dt.quarter
df['消费天数'] = df['消费产生的时间'].dt.day
# 假设用户的消费偏好没有特别大的波动,所以我们用平均值来求对应的值
# 季度
## 所有用户 一共有三年,所以求平均值就除以3
all_quarter = (df[['消费产生的时间','消费季度','会员卡号']].drop_duplicates()['消费季度'].value_counts()/3).sort_index()
# 会员
vip_quarter = (df.loc[df['会员']==1,['消费产生的时间','消费季度','会员卡号']].drop_duplicates()['消费季度'].value_counts()/3).sort_index()
# 非会员
novip_quarter = (df.loc[df['会员']==0,['消费产生的时间','消费季度','会员卡号']].drop_duplicates()['消费季度'].value_counts()/3).sort_index()
line = Line()
line.add_xaxis(xaxis_data = range(1,5))
line.add_yaxis('all',y_axis = all_quarter.values.round().tolist())
line.add_yaxis('会员',y_axis = vip_quarter.values.round().tolist())
line.add_yaxis('非会员',y_axis = novip_quarter.values.round().tolist())
line.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
)
)
line.render_notebook()
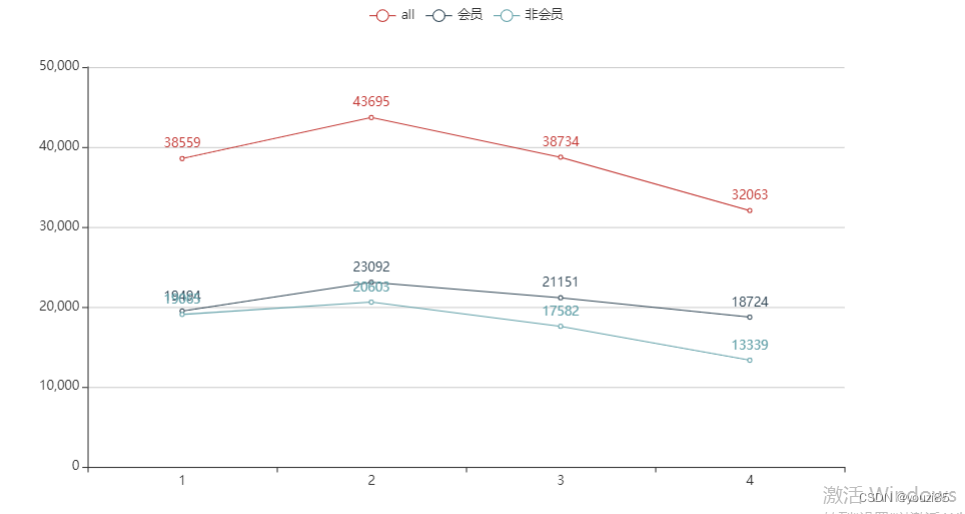
天数
## 所有用户 一共有三年,一个36个月,所以每个天数的平均值时,就除以36
all_day = (df[['消费产生的时间','消费天数','会员卡号']].drop_duplicates()['消费天数'].value_counts()/36).sort_index()
# 会员
vip_day = (df.loc[df['会员']==1,['消费产生的时间','消费天数','会员卡号']].drop_duplicates()['消费天数'].value_counts()/36).sort_index()
# 非会员
novip_day = (df.loc[df['会员']==0,['消费产生的时间','消费天数','会员卡号']].drop_duplicates()['消费天数'].value_counts()/36).sort_index()
# 注意:一年只有7个月是有31号,所以应该是除以21而不是36
all_day.loc[31]=all_day.loc[31]*36/21
vip_day.loc[31]=vip_day.loc[31]*36/21
novip_day.loc[31]=novip_day.loc[31]*36/21
line = Line()
line.add_xaxis(xaxis_data = range(1,32))
line.add_yaxis('all',y_axis = all_day.values.round().tolist(),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
])
)
line.add_yaxis('会员',y_axis = vip_day.values.round().tolist(),markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
])
)
line.add_yaxis('非会员',y_axis = novip_day.values.round().tolist(),markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
])
)
line.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=False),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
)
)
line.set_series_opts(label_opts = opts.LabelOpts(is_show=False))
line.render_notebook()

这里可以看出一个月中26号的消费倾向较高。
综上所述,用户消费习惯不会有巨大变动的情况下,用户消费更倾向于在下午时间,并且一周中周六周日的消费意愿更明显,一个月中在26号更愿意消费,一年中第二季度的消费意愿更强。
商场日常统计分析
- 每日消费人数,每日消费金额,每日人均消费金额
# 每天消费用户数量
ev_num = df.drop_duplicates(subset=['会员卡号','消费日期']).groupby('消费日期')['会员卡号'].count()
# 每天消费金额总量
ev_money = df.groupby('消费日期')['消费金额'].sum()
# 每天人均消费金额
ev_per_money = ev_money/ev_num
ev_num.max()
ev_money.max()
ev_per_money.max()

bar = (
Bar()
.add_xaxis(ev_num.index.tolist())
.add_yaxis(
"消费人数",
ev_num.values.tolist(),
yaxis_index=0,
color="#d14a61",
label_opts=opts.LabelOpts(is_show=False)
)
.add_yaxis(
"消费总金额",
ev_money.values.tolist(),
yaxis_index=1,
color="#5793f3",
label_opts=opts.LabelOpts(is_show=False)
)
.extend_axis(
yaxis=opts.AxisOpts(
name="消费总金额",
type_="value",
min_=0,
max_=25000000, # ev_money.max(),
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#d14a61")
),
axislabel_opts=opts.LabelOpts(formatter="¥{value}"),
)
)
.extend_axis(
yaxis=opts.AxisOpts(
type_="value",
name="人均消费金额",
min_=0,
max_=10000,#ev_per_money.max(),
position="left",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#675bba")
),
axislabel_opts=opts.LabelOpts(formatter="¥{value}"),
splitline_opts=opts.SplitLineOpts(
is_show=True, linestyle_opts=opts.LineStyleOpts(opacity=1)
),
)
)
.set_global_opts(
yaxis_opts=opts.AxisOpts(
name="消费人数",
min_=0,
max_=3024, # ev_num.max()
position="right",
offset=80,
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#5793f3")
),
axislabel_opts=opts.LabelOpts(formatter="{value}人"),
),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
datazoom_opts = opts.DataZoomOpts(range_start = 95, range_end = 100),
title_opts = opts.TitleOpts(title='每日消费情况统计')
)
)
line = (
Line()
.add_xaxis(ev_per_money.index.tolist())
.add_yaxis(
"人均消费金额",
ev_per_money.values.tolist(),
yaxis_index=2,
color="#675bba",
label_opts=opts.LabelOpts(is_show=False),
)
)
overlap_1 = bar.overlap(line)
grid1 = (
Grid(init_opts=opts.InitOpts(width="1200px", height="800px"))
.add(
overlap_1, grid_opts=opts.GridOpts(pos_right="30%"), is_control_axis_index=True
)
)
grid1.render_notebook()
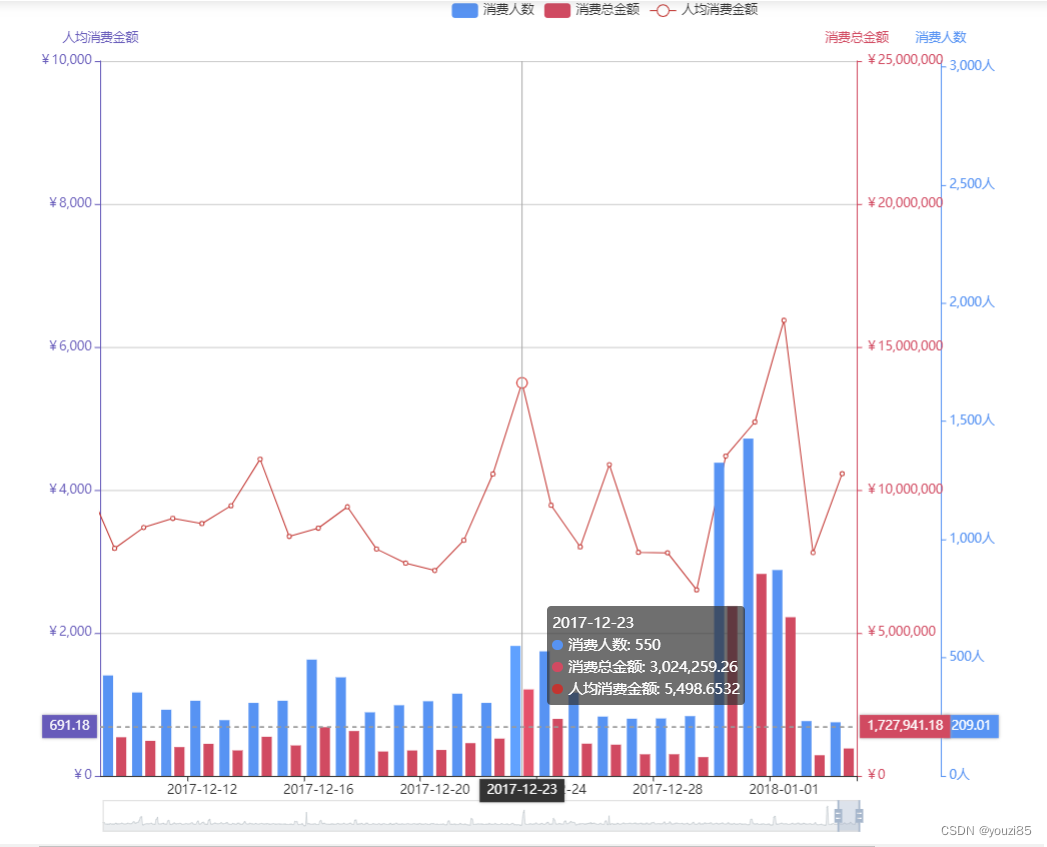
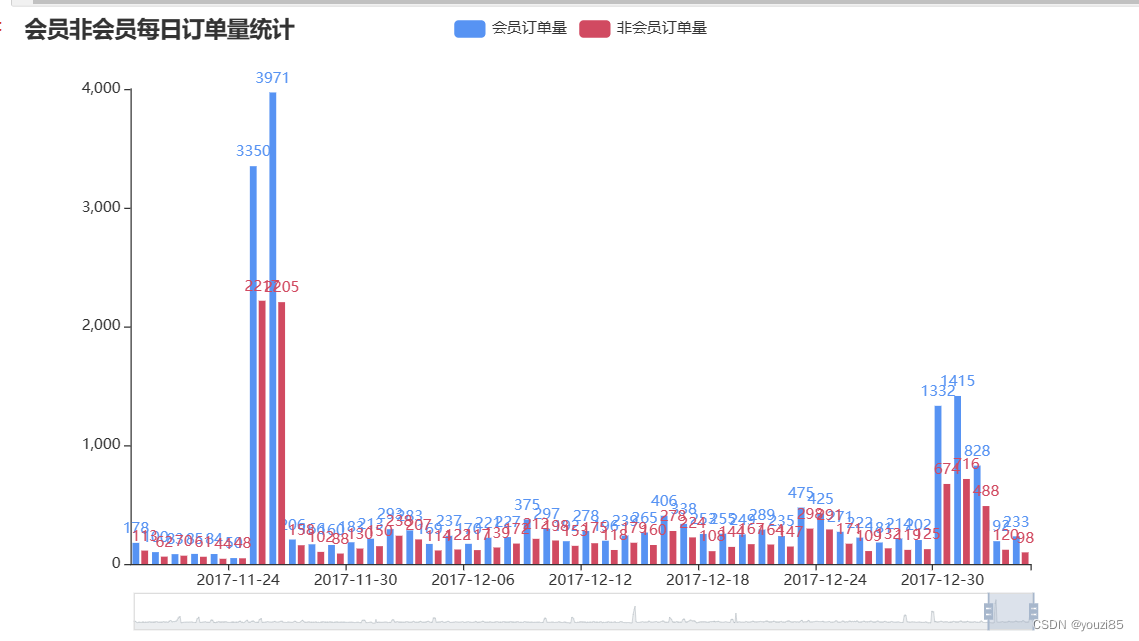
- 会员与非会员的的数据对比。
## 会员订单数,消费金额
vip_order = df.loc[df['会员']==1,['会员卡号','消费产生的时间','消费日期']].drop_duplicates().groupby('消费日期')['消费产生的时间'].count()
vip_money = df[df['会员']==1].groupby('消费日期')['消费金额'].sum()
## 非会员订单数,消费金额
novip_order = df.loc[df['会员']==0,['会员卡号','消费产生的时间','消费日期']].drop_duplicates().groupby('消费日期')['消费产生的时间'].count()
novip_money = df[df['会员']==0].groupby('消费日期')['消费金额'].sum()
bar1 = Bar()
bar1.add_xaxis(vip_order.index.tolist())
bar1.add_yaxis('会员订单量',vip_order.values.tolist(),color="#d14a61")
bar1.add_yaxis('非会员订单量',novip_order.values.tolist(),color="#5793f3")
bar1.set_global_opts(datazoom_opts = opts.DataZoomOpts(range_start=95,range_end=100),title_opts = opts.TitleOpts(title='会员非会员每日订单量统计'))
bar1.render_notebook()
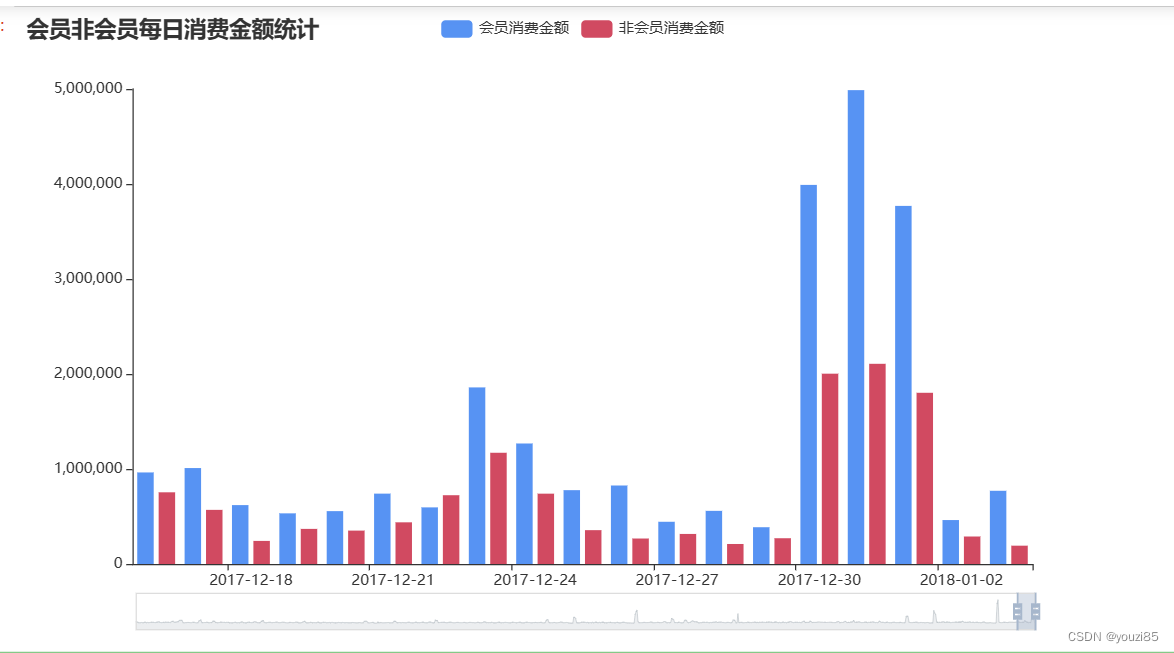
bar2 = Bar()
bar2.add_xaxis(vip_money.index.tolist())
bar2.add_yaxis('会员消费金额',vip_money.values.tolist(),label_opts=opts.LabelOpts(is_show=False),color="#d14a61")
bar2.add_yaxis('非会员消费金额',novip_money.values.tolist(),label_opts=opts.LabelOpts(is_show=False),color="#5793f3")
bar2.set_global_opts(datazoom_opts = opts.DataZoomOpts(range_start=98,range_end=100),title_opts = opts.TitleOpts(title='会员非会员每日消费金额统计'))
bar2.render_notebook()
df_order_all = df[['消费产生的时间','会员']].drop_duplicates().groupby('会员').count()
df_order_all = df_order_all/df_order_all.sum()
df_money_all = df.groupby('会员')['消费金额'].sum()
df_money_all = df_money_all/df_money_all.sum()
会员与非会员的总量对比
pie_1 = Pie()
pie_1.add('订单占比',
[list(z) for z in zip(df_order_all.index.map({0:'非会员',1:'会员'}).tolist(), df_order_all.values.flatten().round(2).tolist())],
center=["25%", "50%"],
radius=[80, 100],
label_opts=opts.LabelOpts(formatter="{b}:{c}"),
)
pie_1.set_colors(["#d14a61", "#5793f3"])
pie_1.set_global_opts(title_opts = opts.TitleOpts(title='会员非会员订单量占比'))
pie_2 = Pie()
pie_2.add('消费金额占比',
[list(z) for z in zip(df_money_all.index.map({0:'非会员',1:'会员'}).tolist(), df_money_all.values.round(2).tolist())],
center=["70%", "50%"],
radius=[80, 100],
label_opts=opts.LabelOpts(formatter="{b}:{c}"),
)
pie_2.set_colors(["#d14a61", "#5793f3"])
pie_2.set_global_opts(title_opts = opts.TitleOpts(title='会员非会员消费金额占比',pos_left="60%"))
grid2 = Grid()
grid2.add(pie_1,grid_opts=opts.GridOpts(pos_right="70%"))
grid2.add(pie_2,grid_opts=opts.GridOpts(pos_left="70%"))
grid2.render_notebook()

- 以历史1月数据监控2018年1月消费金额达标情况
# 添加月份字段
df['消费月份']=df['消费产生的时间'].dt.month
# 查看历年1月数据
df.query('消费月份==1 and 消费年份==2015')['消费日期'].unique().size
df.query('消费月份==1 and 消费年份==2016')['消费日期'].unique().size
df.query('消费月份==1 and 消费年份==2017')['消费日期'].unique().size
# 可以看出2016年1月数据是缺失的,所以我们用2015年和2017年的数据来监控2018年1月的消费情况。

# 对1月历史消费金额求平均值
jan_avg = df[df['消费月份']==1 & df['消费年份'].isin([2015,2017])]['消费金额'].sum()/2
jan_avg

jan_2018 = df[(df['消费月份']==1) & (df['消费年份']==2018)]['消费金额'].sum()
jan_2018

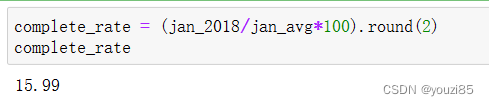
complete_rate = (jan_2018/jan_avg*100).round(2)
complete_rate
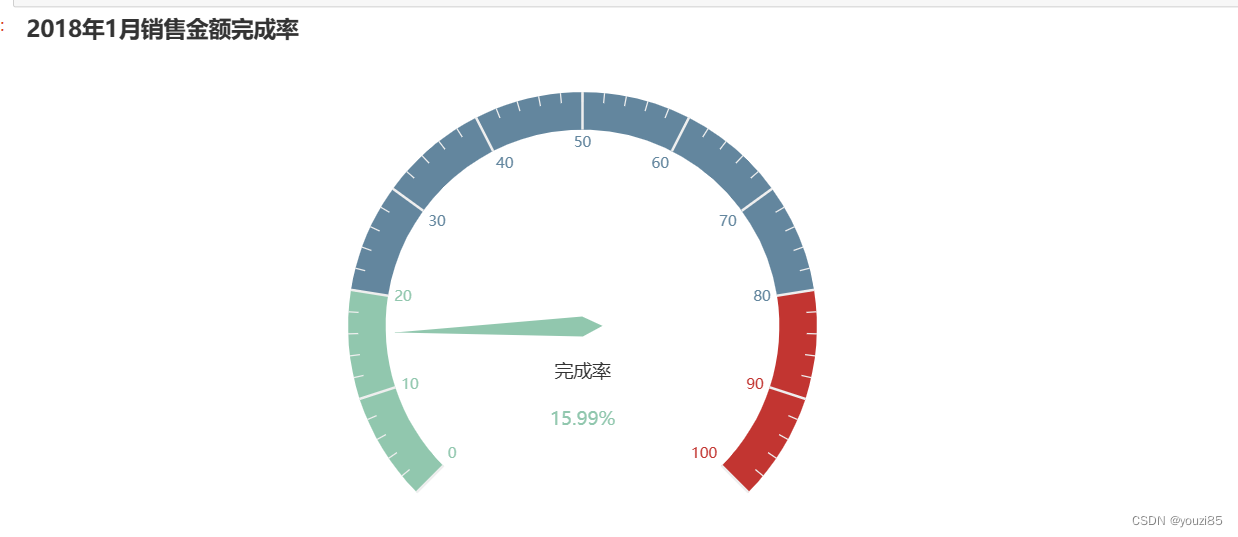
gauge = Gauge()
gauge .add(series_name="业务指标", data_pair=[["完成率", complete_rate]],
title_label_opts = opts.GaugeTitleOpts(offset_center=["0%", "20%"]),
detail_label_opts = opts.GaugeDetailOpts(formatter="{value}%", offset_center=["0%", "40%"]))
gauge .set_global_opts(
title_opts = opts.TitleOpts(title= '2018年1月销售金额完成率'),
legend_opts=opts.LegendOpts(is_show=False),
)
gauge.render_notebook()
# 最后将上面的结果通过页面布局更好的显示
# 最好将界面中的颜色统一 一下
page = Page(layout=Page.DraggablePageLayout)
page.add(grid1,grid2,bar1,bar2,gauge)
page.render()

Page.save_resize_html("render.html", cfg_file="D:\chart_config.json", dest="shop.html")
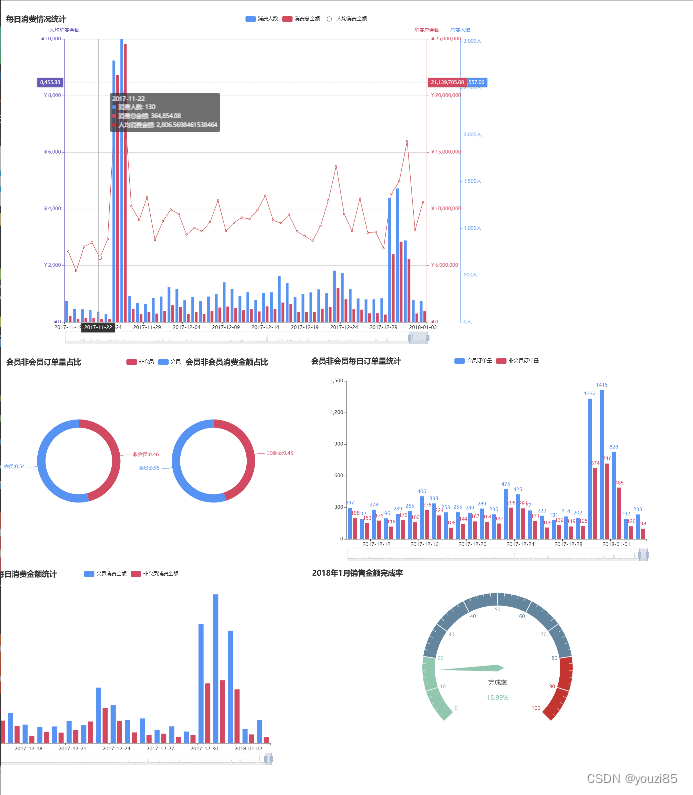
百货商场日常数据大屏
RFM分析
对用户进行RFM分析,因为订单的消费日期只到2018年1月3日的,所以假设在这个时间点进行分析。
R:表示用户最近一次消费的记录
F:表示用户一共消费了几次
M:表示用户一共消费了多少金额
df.drop(df[df['消费金额']<0].index,inplace=True)
df.drop(df[df['销售数量']<0].index,inplace=True)
# 求消费用户最近一次的消费时间,就是求离2018年1月3日的天数,差的越多说明消费的时间越远。
df['end_time']=pd.to_datetime('2018-01-03')
df['R'] = df['end_time'].dt.date-df['消费日期']
# 没有消费日期,R得到的结果就是NaT,如果最后要将结果的天数取出来没有办法成功
# 所以这里先将NaT填充,但是不能直接用-1填充,需要加上参数pd.Timedelta(seconds=-1)
df['R'].fillna(pd.Timedelta(seconds=-1),inplace=True)
# 把 0 days结果转换为0
# df['R'] = df['R'].map(lambda x: x/np.timedelta64(1,'D'))
df['R'] = df['R'].astype('str').apply(lambda x: x.split(' ')[0]).astype('int32')
df['R']
# 发现不能分组,然后查原因,是因为在这里把会员卡号识别成int或者datetime类型了,所以修改会员卡号的字段类型
df['会员卡号'] = df['会员卡号'].astype(str)
# 求用户最近一次的消费时间
df_R = df[['会员卡号', 'R']].groupby('会员卡号').agg(np.min)
df_R

# F是用户消费次数,这里一个订单代表购买一次
df_F = df[['会员卡号','消费产生的时间']].drop_duplicates().groupby('会员卡号').count()
df_F.columns=['F']
df_F

# M 用户的消费金额
df_M = df.groupby('会员卡号').agg({'消费金额':sum})
df_M.columns=['M']
df_M

# 连表
df_RFM_tmp = df_R.merge(df_F,left_index=True,right_index=True).merge(df_M,left_index=True,right_index=True)
df_RFM_tmp.reset_index(inplace=True)
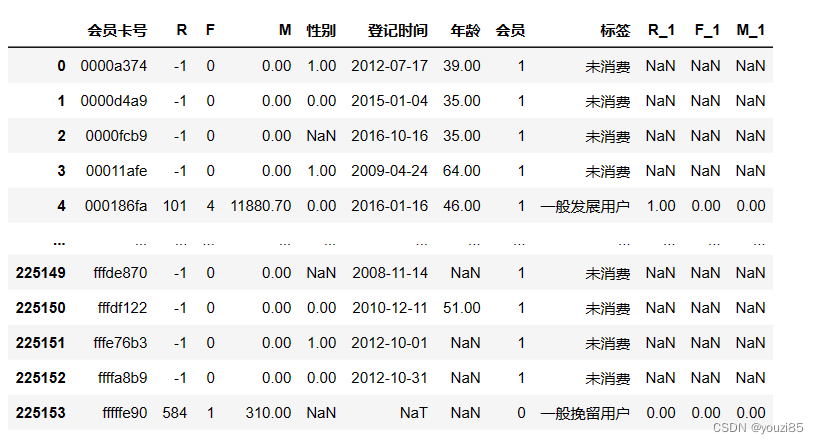
df_RFM = df_RFM_tmp.merge(customers[['会员卡号','性别','登记时间','年龄']],how='left',on='会员卡号')
df_RFM['会员']=1
df_RFM.loc[df_RFM['登记时间'].isna(),'会员']=0
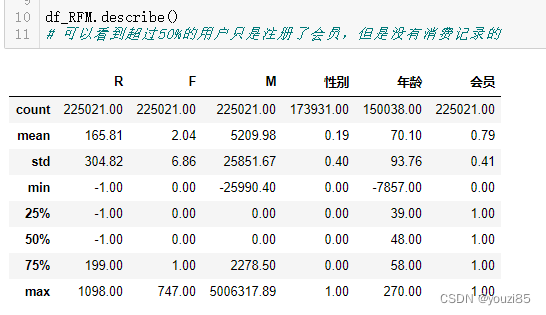
df_RFM.describe()
# 可以看到超过50%的用户只是注册了会员,但是没有消费记录的
# 对于没有进行消费的用户,直接标记为未消费
# 消费次数是0
df_RFM['标签'] = df_RFM['F'].apply(lambda x :'未消费' if x ==0 else np.NaN)
# 对剩余用户数再次求平均
df_RFM[df_RFM['标签'].isna()].agg({'R':['mean','min','max'],'F':['mean','min','max'],'M':['mean','min','max']})

# 所以我们以平均值作为分界,若是大于平均值则设置为1,若是小于平均值则设置为0
mean_dict={'R_mean':419,'F_mean':5,'M_mean':13126}
def func(y):
p_mean = y+'_mean'
name = y + '_1'
if y=='R':
df_RFM.loc[df_RFM[df_RFM['标签'].isna()].index,name] = df_RFM[df_RFM['标签'].isna()][y].apply(lambda x:0 if x>mean_dict[p_mean] else 1)
else:
df_RFM.loc[df_RFM[df_RFM['标签'].isna()].index,name] = df_RFM[df_RFM['标签'].isna()][y].apply(lambda x:1 if x>mean_dict[p_mean] else 0)
return
func('R')
func('F')
func('M')

## 标记用户,针对不同的用户采取不同的措施
'''
R F M
重要价值用户 1 1 1 保持现状
重要发展用户 1 0 1 提升频次
重要保持用户 0 1 1 用户回流
重要挽留用户 0 0 1 重点召回
一般价值用户 1 1 0 刺激消费
一般发展用户 1 0 0 挖掘需求
一般保持用户 0 1 0 流失召回
一般挽留用户 0 0 0 可放弃治疗
'''
def func(arg1,arg2,arg3):
if (arg1==1) & (arg2==1) & (arg3==1):
return '重要价值用户'
elif (arg1==1) & (arg2==0) & (arg3==1):
return '重要发展用户'
elif (arg1==0) & (arg2==1) & (arg3==1):
return '重要保持用户'
elif (arg1==0) & (arg2==0) & (arg3==1):
return '重要挽留用户'
elif (arg1==1) & (arg2==1) & (arg3==0):
return '一般价值用户'
elif (arg1==1) & (arg2==0) & (arg3==0):
return '一般发展用户'
elif (arg1==0) & (arg2==1) & (arg3==0):
return '一般保持用户'
elif (arg1==0) & (arg2==0) & (arg3==0):
return '一般挽留用户'
# 填充空值
df_RFM['标签'].fillna(df_RFM.apply(lambda row: func(row['R_1'],row['F_1'],row['M_1']),axis=1),inplace=True)
给用户打上了标签,此时对于不用的用户采用不同的运营方式。