大众媒体赋予这些术语的含义通常与机器学习科学家和工程师的理解有所出入。因此,当我们使用这些术语时,给出准确的定义很重要,其关系韦恩图如图1.2所示。

图1.2 自然语言处理、人工智能、机器学习和深度学习等术语的关系韦恩图
1 人工智能
人工智能作为一个研究领域出现在20世纪中叶,致力于使计算机模拟和执行通常由人类执行的任务。最初的方法专注于手动推导和硬编码显式规则,用于在各种感兴趣的环境中操作输入数据。这种范式通常称为符号主义人工智能。它适用于定义明确的问题,如国际象棋,但当遇到来自感知类问题时,如视觉和语音识别,它会明显地出错。我们需要一种新的范式,即计算机可以从数据中学习新的规则,而不是由人类明确地指定规则。这促使了机器学习的兴起。
2 机器学习
20世纪90年代,机器学习范式成为人工智能的主导。现在,计算机不再为每种可能的情况显式编码,而是通过相应的输入输出样例数据来训练模型,自动提取输入与输出之间的映射关系。虽然机器学习涉及大量的数学和统计学知识,但由于它倾向于处理大型和复杂数据集,因此它更加依赖实验、经验观察和工程手段,而非数学理论。
机器学习算法从输入数据中学习到一种表示,并将其转换为恰当的输出。为此,机器学习模型需要一组数据(如句子分类任务中的一组句子输入)和一组相应的输出(如用于句子分类的{“正”,“负”}标签)。还需要一个损失函数,它用于度量机器学习模型的当前输出与数据集的预期输出之间的偏差。为了帮助读者理解,不妨考虑二分类任务,其中机器学习的目标可能是找到一个所谓的决策边界的函数,其职责是完美地分割不同类型的数据点,如图1.3所示。这个决策边界应该在训练集之外的新数据实例上也有很好的表现。为了加速找到决策边界,读者可能需要首先对数据进行预处理,或者将其转换为更易于分割的形式。我们在称为假设集(hypothesis set)的可能函数集合中搜索目标函数。这种搜索是自动进行的,它使得机器学习的最终目标更容易实现,这就是所谓的学习。
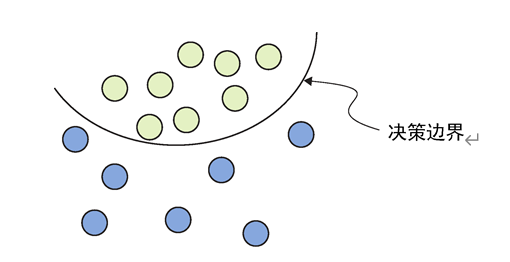
图1.3 机器学习中一个主要的激励任务的示例(在本图所示的情况中,假设集可以是弧线)
机器学习利用损失函数所包含的反馈信号的指导,在某个预定义的假设集中自动搜索输入与输出之间的最佳映射关系。假设集的性质决定了所考虑的算法类别,这些将在后面内容中简要介绍。
经典机器学习(classical machine learning)是从概率建模方法(如朴素贝叶斯)开始的。这里,我们不妨乐观地假设输入数据特征都是独立的。逻辑斯谛回归(logistic regression)是一种概率建模方法,它通常是数据科学家在数据集上首先尝试的方法。它和朴素贝叶斯的假设集都是线性函数集。
神经网络(neural network)虽然起源于20世纪50年代,但直到20世纪80年代人们才发现一种有效的训练大型网络的方法——反向传播(back propagation)与随机梯度下降(stochastic gradient descent)算法相结合。反向传播提供了一种计算网络梯度的方法,而随机梯度下降则使用这些梯度来训练网络。
本书附录B简要介绍了这些概念。1989年神经网络第一次成功应用。当时贝尔实验室的Yann LeCun建立了一个识别手写数字的系统,这个系统后来被美国邮政局广泛使用。
核方法(kernel method)从20世纪90年代开始流行。这种方法试图通过在点集之间找到良好的决策边界来解决分类问题,如图1.3所示。最流行的核方法是支持向量机(Support Vector Machine,SVM),它试图通过将数据映射到新的高维表示(其中超平面是有效边界)来找到好的决策边界,然后,令超平面和每个类目中最近的数据点之间的距离最大化。利用核方法,高维空间中的高计算成本得到降低。核函数用于计算点之间的距离,而不是显式地对高维数据表示进行计算,其计算成本远小于高维空间中的计算成本。这个方法有坚实的理论支撑,并且易于进行数学分析,当核函数是线性函数时,则该方法也是线性的,这使得该方法非常流行。然而,该方法在感知类机器学习问题上还存在很多可改进的地方,因为这种方法首先需要一个手动的特征工程步骤,而这一步又很容易出差错。
决策树(deciston tree)及其相关方法是另一类仍被广泛使用的方法。决策树是一种决策支持辅助工具,它将决策及其结果建模为树形结构。它本质上是一个图(graph),图中任意两个连通节点之间只存在一条路径。或者可以将树定义为将输入值转换为输出类别的流程图。决策树在21世纪10年代兴起,彼时基于决策树的方法开始比核方法更流行。这种流行得益于决策树更易于可视化、理解和解释。为了帮助读者理解,图 1.4 展示了一个决策树结构示例,该结构将输入{A,B}分类为类别1(如果A<10)、类别2(如果A≥10,而B≤25)和类别3(其他情况)。

图1.4 决策树结构示例
随机森林(random forest)为应用决策树提供了一种实用的机器学习方法。此方法涉及生成大量特化(specialized)决策树并组合它们的输出。随机森林非常灵活并具有普适性,这使得它经常成为继逻辑斯谛回归之后的第二种基线算法。2010年,当Kaggle开放式竞赛平台启动时,随机森林很快成为该平台上使用最广泛的算法。2014年,梯度提升机(Gradient Boosting Machine,GBM)取代了它。它们的原理都是迭代地学习新的基于决策树的模型,这些模型消除了以前迭代中模型的弱点。在撰写本书时,它们被广泛认为是解决非感知类机器学习问题的最佳方法。它们在Kaggle上依然备受青睐。
2012年左右,基于GPU训练的卷积神经网络(Conrolutional Neural Network,CNN)开始赢得年度ImageNet竞赛,这标志着当前深度学习“黄金时代”的来临。CNN开始主导所有主要的图像处理任务,如目标识别(object recognition)和目标检测(object detection)。同样,我们也可以在人类自然语言的处理中找到它的应用,即NLP。神经网络通过一系列越来越有意义的、分层的输入数据表示进行学习。这些层(layer)的数量确定了模型的深度(depth)。这也是术语“深度学习”(deep learning)的由来,即训练深度神经网络的过程。为了区别于深度学习,之前所述的所有机器学习方法通常称为浅层(shallow)或传统学习方法。请注意,深度较小的神经网络也可归类为浅层,但不是传统的。深度学习已经占据机器学习领域的主导地位。很明显作为解决感知类问题首选的深度学习在可处理问题的复杂性方面引发了一场“革命”。
虽然神经网络的灵感来自神经生物学,但它并不是我们神经系统工作的真实模式。神经网络的每一层都由一组数字(称其为层的权重)参数化,用于精确地指导该层如何对输入数据进行转换。在深度神经网络中,参数的总数很容易达到百万级。前面提到的反向传播算法是一种算法引擎,用于找到正确的参数集,即对网络进行学习。图1.5(a)展示了具有两个全连接隐藏层的简单前馈神经网络的可视化表示。图1.5(b)展示了一个等价的简化表示,我们将经常使用这种表示来简化图表。一个深度神经网络会有很多这样的层。一种著名的神经网络结构不具备这种前馈性质,它就是长短期记忆(Long Short-Term Memory,LSTM)循环神经网络(Recurrent Neural Network,RNN)。与图1.5中接收长度为2的固定长度输入的前馈结构不同,LSTM可以处理任意长度的输入序列。
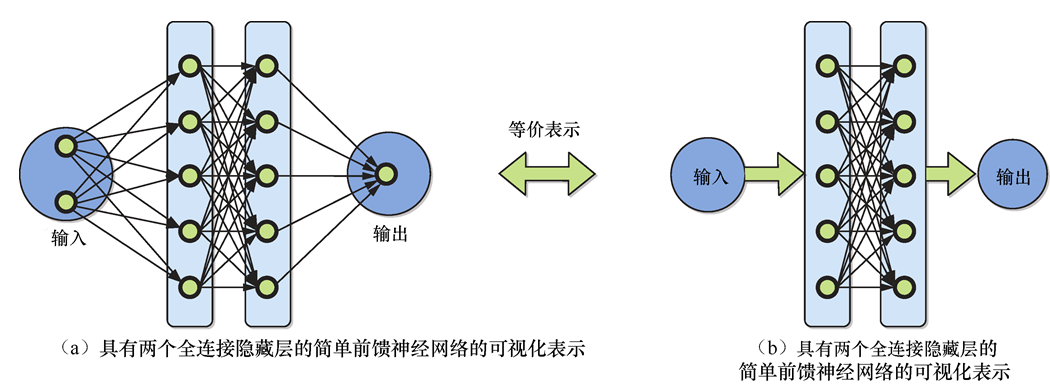
图1.5 具有两个全连接隐藏层的简单前馈神经网络
如前所述,引爆“深度学习革命”的是硬件、海量可用数据和算法的进步。专门为视频游戏市场开发的GPU,以及业已成熟的互联网,开始为深度学习领域提供前所未有的海量优质数据。数据源如Wikipedia、YouTube和ImageNet等的可用性推动了计算机视觉和NLP的进步。神经网络能够消除对昂贵的手动特征工程的需求,这是成功将浅层学习方法应用于感知数据的必要条件,可以说是影响深度学习易用性的因素。由于NLP是一个感知类问题,因此神经网络也是本书重点介绍的机器学习算法类型,尽管不是唯一的类型。
3 自然语言处理
语言是人类认知最重要的方面之一。毫无疑问,为了创造真正的人工智能,需要让机器掌握如何解释、理解、处理和操作人类语言的方法。这让NLP在人工智能和机器学习领域日渐重要。
与人工智能的其他子领域一样,处理NLP问题的初始方法(如句子分类和情感分析)都基于显式规则或符号主义人工智能。采用这些初始方法的系统通常无法推广到新任务,并且很容易崩溃。自20世纪90年代核方法出现以来,人们一直致力于研究特征工程——手动将输入数据转换为浅层学习方法可以用来正确预测的形式。特征工程非常耗时,且与特定任务相关,非领域专家难以掌握。2012年左右,深度学习的出现引发了NLP的真正革命。神经网络在其某些层中自动设计适当特征的能力降低了特征工程处理新任务和问题的门槛。然后,人们的工作重点转向为任何给定的任务设计适当的神经网络结构,以及在训练期间调整各种超参数。
训练NLP系统的标准方法是首先收集大量数据点,然后在句子或文档的情感分析任务中对每个数据点进行标注(如“正向”或“负向”)。最后将这些数据点提供给机器学习算法,以学习输入信号到输出信号映射关系的最佳表示,学习得到的模型在新数据点上也有很好的表现。在NLP和机器学习的其他子领域中,该过程通常称为有监督学习(supervised learning)范式。手动完成的标注过程为学习代表性映射关系提供了“监督信号”。另外,从未标注数据点的学习范式称为无监督学习(unsupervised learning)范式。
尽管今天的机器学习算法和系统不是生物学习系统的直接复制品,也不应该被视为此类系统的模型,但它们的某些方面受到进化生物学的启发,而且带来了重大的进步。对于每个新任务、语言或应用领域,有监督学习过程传统上是从头开始重复的,这似乎是有缺陷的。这个过程在某种程度上与自然系统基于先前获得的知识并加以复用的学习方式相反。饶是如此,从零开始的感知任务学习已经取得了重大进展,特别是在机器翻译、问答系统和聊天机器人方面,尽管它仍然存在一些缺点。特别是,今天的系统在输入信号相关样本的分布发生急剧变化时鲁棒性欠佳。换句话说,系统学习在某种类型的输入上表现良好。如果更改输入类型,可能会导致性能显著下降,有时甚至会出现严重故障。此外,为了使人工智能更普及,并使小型企业的普通工程师或没有大型互联网公司资源的任何人都能使用NLP技术,能够下载和复用他人学习到的知识将变得尤为重要。这对于以英语或其他流行语言之外的语言作为母语的地区的人们也很重要,因为英语或其他流行语言有预训练模型。此外,这对于执行所在地区独有的任务或前所未有的新任务的人来说也很重要。迁移学习提供了解决其中一些问题的方法。
迁移学习使人们能够将知识从一个环境中迁移到另一个环境中,这里将环境定义为特定任务、领域和语言的组合。最初的环境称为源环境,最终的环境称为目标环境。知识迁移的难易程度和是否成功取决于源环境和目标环境的相似性。很自然,在某种意义上与源环境“相似”的目标环境(我们将在本书后面定义)会更容易迁移和成功。
迁移学习在NLP中的应用比大多数实践者意识到的要早得多,因为使用预训练的嵌入(如Word2Vec或Sent2Vec)对单词进行向量化是一种很常见的做法(1.3节将对此进行详细介绍)。浅层学习方法通常将这些向量用作特征。我们将在1.3节和第4章更详细地介绍这两种技术,并在本书中以多种方式应用它们。这种流行的方法依赖于无监督的预处理步骤,该步骤用于在没有任何标签的情况下首先训练这些嵌入。然后,来自该步骤的知识被迁移到有监督学习上下文中的特定应用程序中,在该环境中,预训练学习的知识得到进一步处理,并针对与当前浅层学习问题相关的较小带标签样本集进行特化。传统上,这种结合无监督学习和有监督学习步骤的范式称为半监督学习(semisupervised learning)。
本文摘自《自然语言处理迁移学习实战》

一本书带你读懂ChatGPT背后的技术,自然语言处理迁移学习,解锁机器学习新境界,从浅层到深度,掌握NLP迁移学习的奥秘,让你的模型脱颖而出!
迁移学习作为机器学习和人工智能领域的重要方法,在计算机视觉、自然语言处理(NLP)、语音识别等领域都得到广泛应用。本书是迁移学习技术的实用入门图书,能够带领读者深入实践自然语言处理模型。首先,本书回顾了机器学习中的关键概念,并介绍了机器学习的发展历史,以及NLP迁移学习的进展;其次,深入探讨了一些重要的NLP迁移学习方法—NLP浅层迁移学习和NLP深度迁移学习;最后,涵盖NLP迁移学习领域中重要的子领域—以Transformer作为关键功能的深度迁移学习技术。读者可以动手将现有的先进模型应用于现实世界的应用程序,包括垃圾电子邮件分类器、IMDb电影评论情感分类器、自动事实检查器、问答系统和翻译系统等。
本书文字简洁、论述精辟、层次清晰,既适合拥有NLP基础的机器学习和数据科学相关的开发人员阅读,也适合作为高等院校计算机及相关专业的学生参考用书。