转换器模型是自然语言处理(NLP)研究领域越来越流行的神经网络架构,大型变压器可以在许多任务上实现最先进的性能。代价是转换器过多的计算消耗和成本,尤其是对于长序列上的训练模型。
谷歌和加州大学伯克利分校的研究人员最近发表的一篇论文被著名的国际表征学习大会(ICLR 2020)接受,提出了一种称为“改革者”的新转换器模型,即使仅在单个GPU上运行,也能实现令人印象深刻的性能。
为了提高变压器效率,研究人员用局部敏感哈希(LSH)取代了点积注意力,将复杂度从O(L 2)更改为O(L log L),其中L是指序列的长度。LSH 是一种算法技术,用于从海量数据中挖掘类似项目时的最近邻搜索。
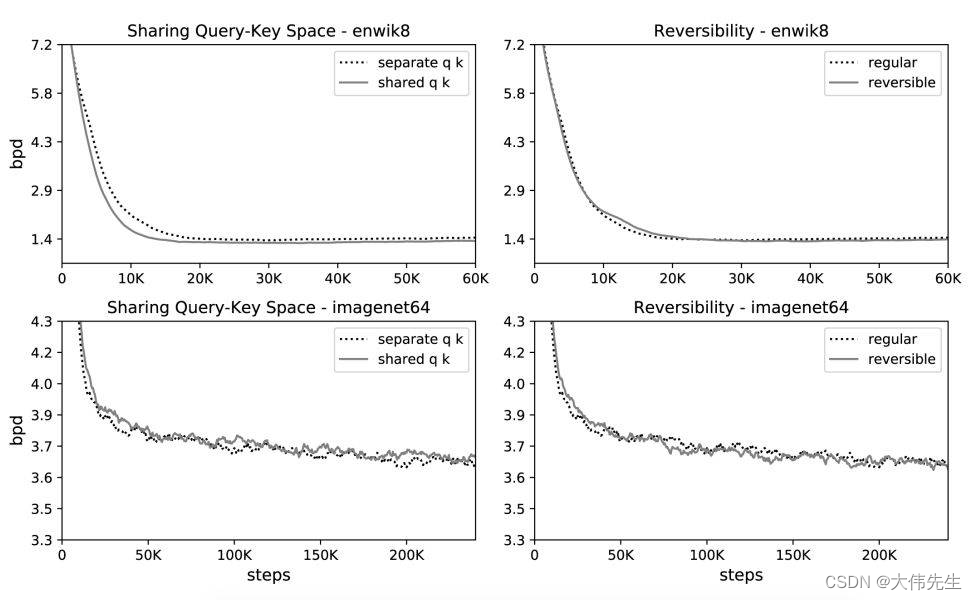
研究人员还使用了可逆残差层而不是标准残差,这使得在训练过程中仅存储一次激活,而不是N次(其中N表示层数)。与变形金刚模型相比,最终的重整器模型表现相似,但在长序列上显示出更高的存储效率和更快的速度。
研究人员对长度为64K的图像生成任务imagenet12和长度为8K的文本任务enwik64进行了实验,以将传统的变压器与提出的可逆变压器进行比较。两个变形金刚具有相同数量的参数,学习曲线几乎相同。实验结果表明,可逆变压器在不牺牲精度的情况下节省了内存。
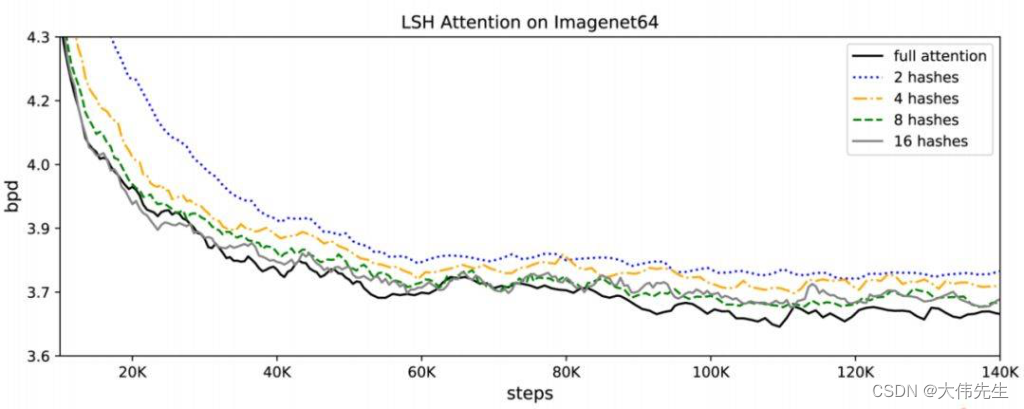
LSH 注意力是全注意力的近似值,其准确性随着哈希值的增加而提高。当哈希值为 8 时,LSH 注意力几乎等同于全注意力。一般来说,模型的计算成本随着哈希值的增加而增加。这允许研究人员根据自己的计算预算调整哈希值。
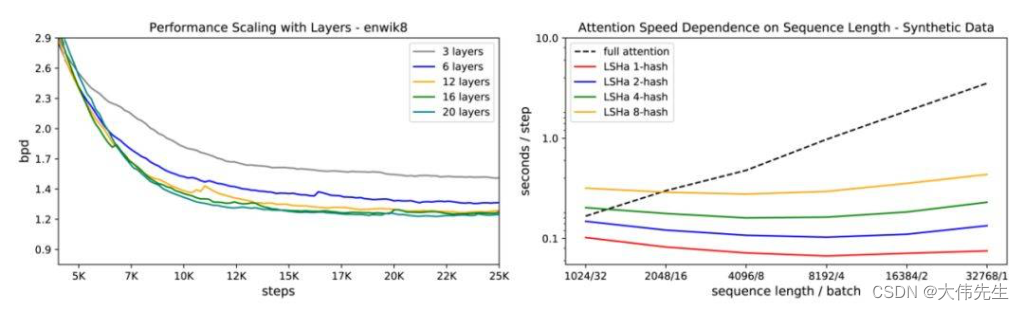
研究人员在enwik8上测试了LSH的注意力表现,这也显示了不同注意力类型的速度和序列长度之间的关系,而代币总数保持不变。结果表明,常规注意力随着序列长度的增加而减慢,而LSH注意力速度保持稳定。
该论文已被ICLR 2020选中,获得了“8、8、6”的近乎完美的分数。该研究在研究界获得了好评,预计将对该领域产生重大影响。
论文《改革者:高效变压器》发表在OpenReview上。