MATALB版本为2022b
数据
为了能够便于验证实验的可行性,在这里给出实验所需的数据。
该数据为人体活动时产生的加速度数据,包括三轴传感器的X轴、Y轴、Z轴和合加速度。
百度网盘链接:https://pan.baidu.com/s/1xHufym00DH6fC6ZfylVUVA
提取码:2023
此数据集仅供各位验证实验所用,禁止用于学位论文和期刊论文等
模型训练程序和dataset文件夹默认处于同一目录下,如果两者不在同一目录下则需要修改源代码中的文件路径
dataset文件夹包含train和test两个文件夹,每个文件夹下包含A.xlsx、X.xlsx、Y.xlsx、Z.xlsx和label.xlsx五个文件。
模型搭建
MATLAB搭建深度学习模型可以使用直接使用代码搭建也可以使用工具箱搭建,下面将介绍使用工具箱搭建1DCNN模型。
1、点击APP选项卡下的“深度网络设计器”工具箱
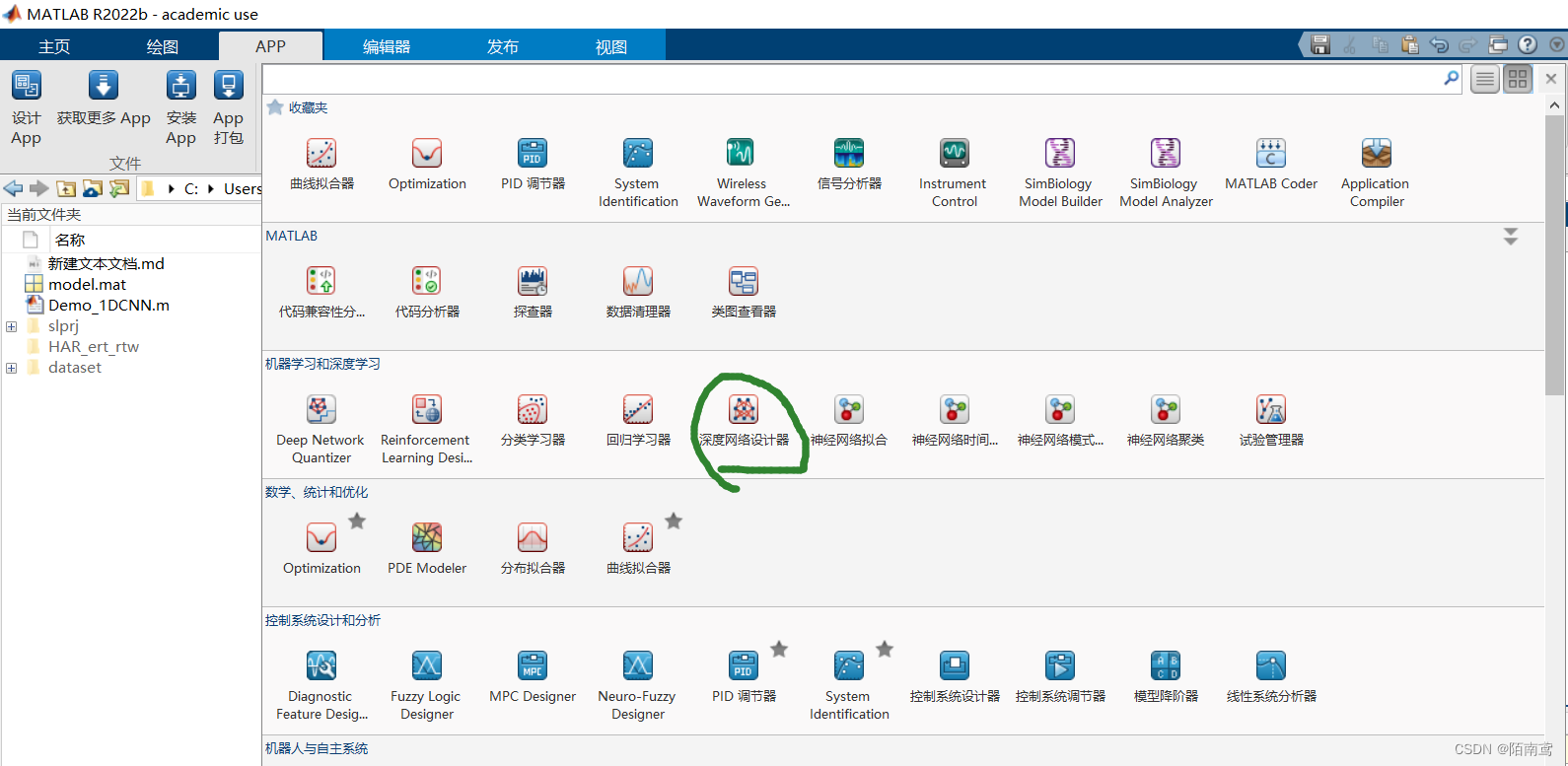
2、新建空白网络

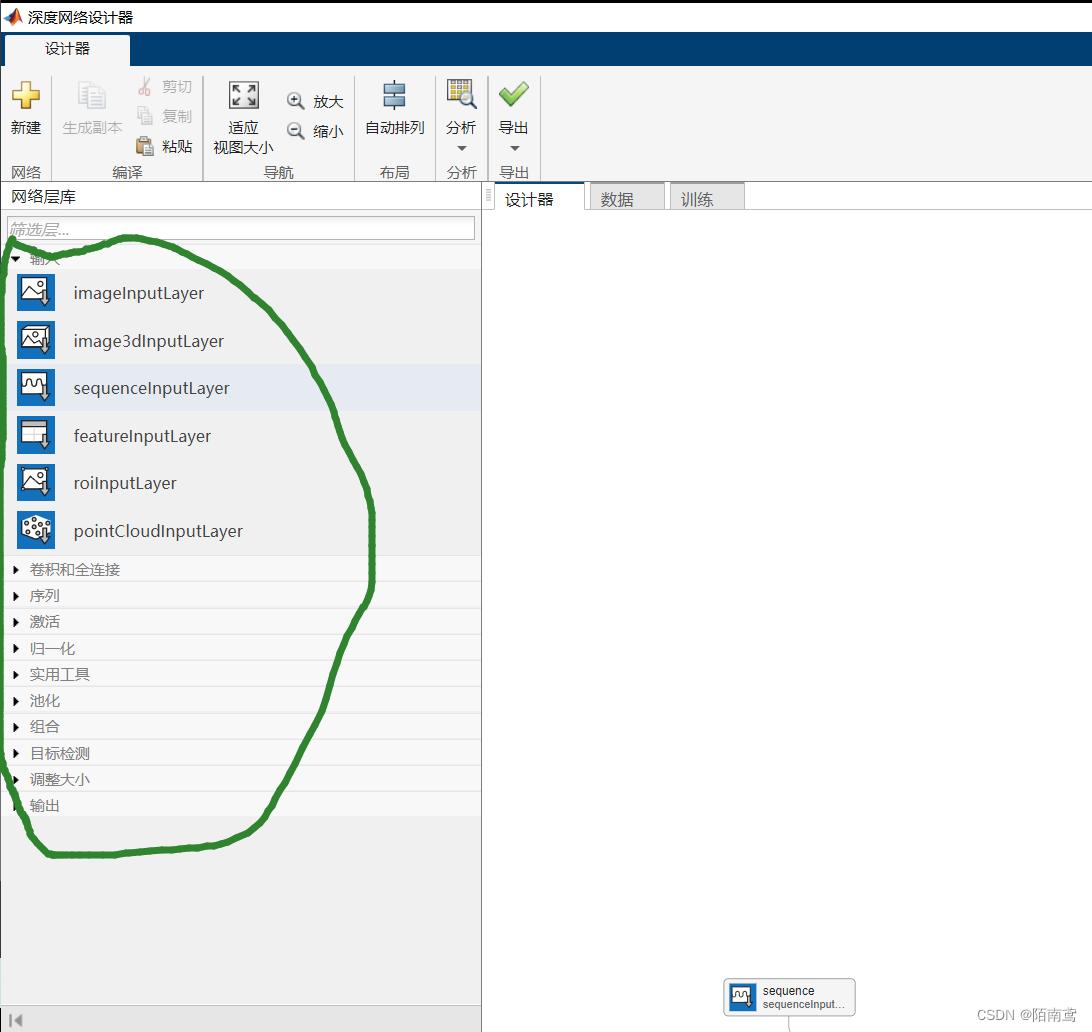
3、模型搭建
通过拖动左侧的模块可以实现网络的搭建
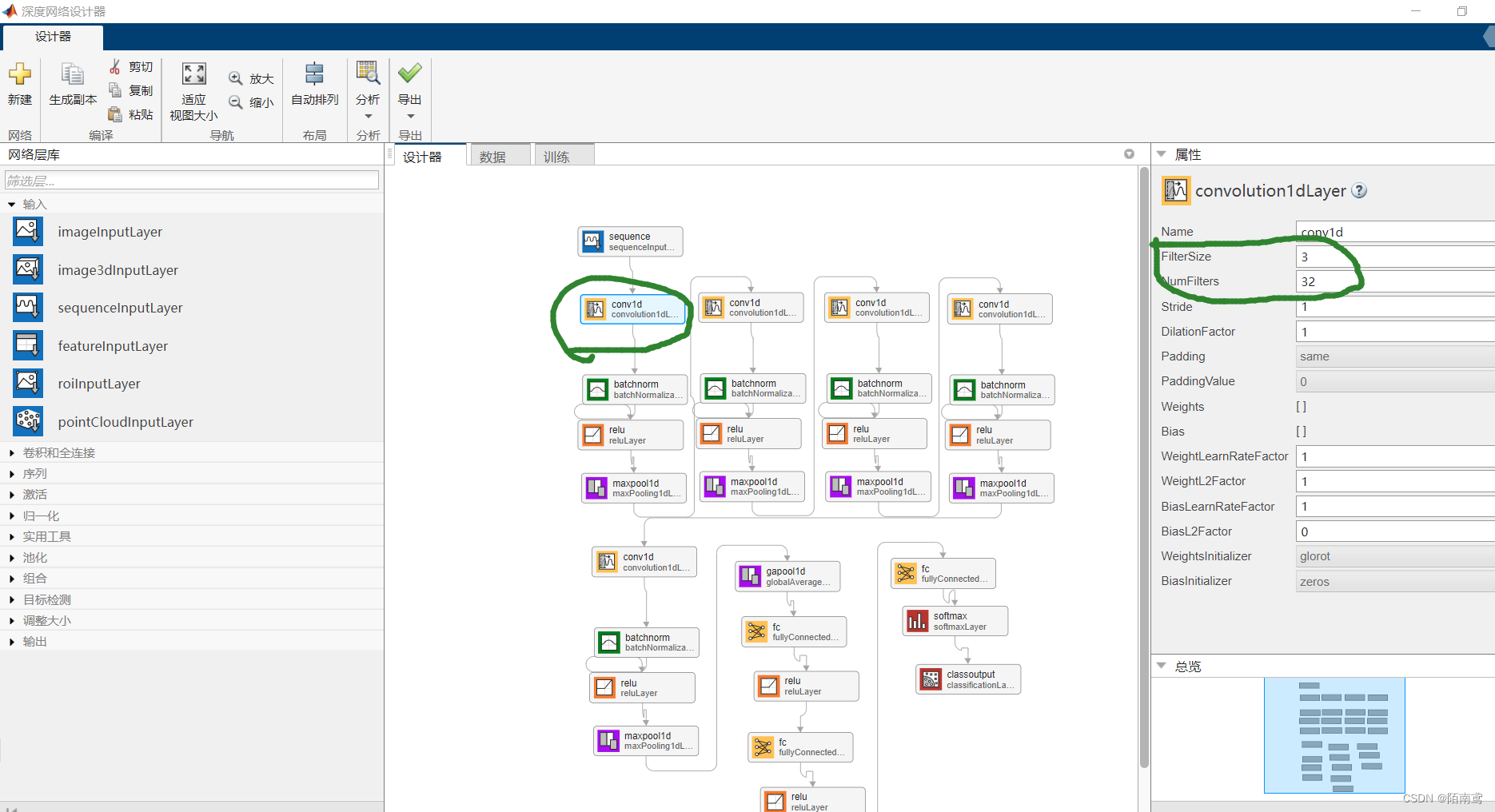
4、参数设置
模型中各个层的参数,例如卷积层的卷积核数量或尺寸等参数,可以单击对应模块,在右侧的“属性”内进行设置
5、模型搭建完以后,需要设置优化器等参数
点击“训练”
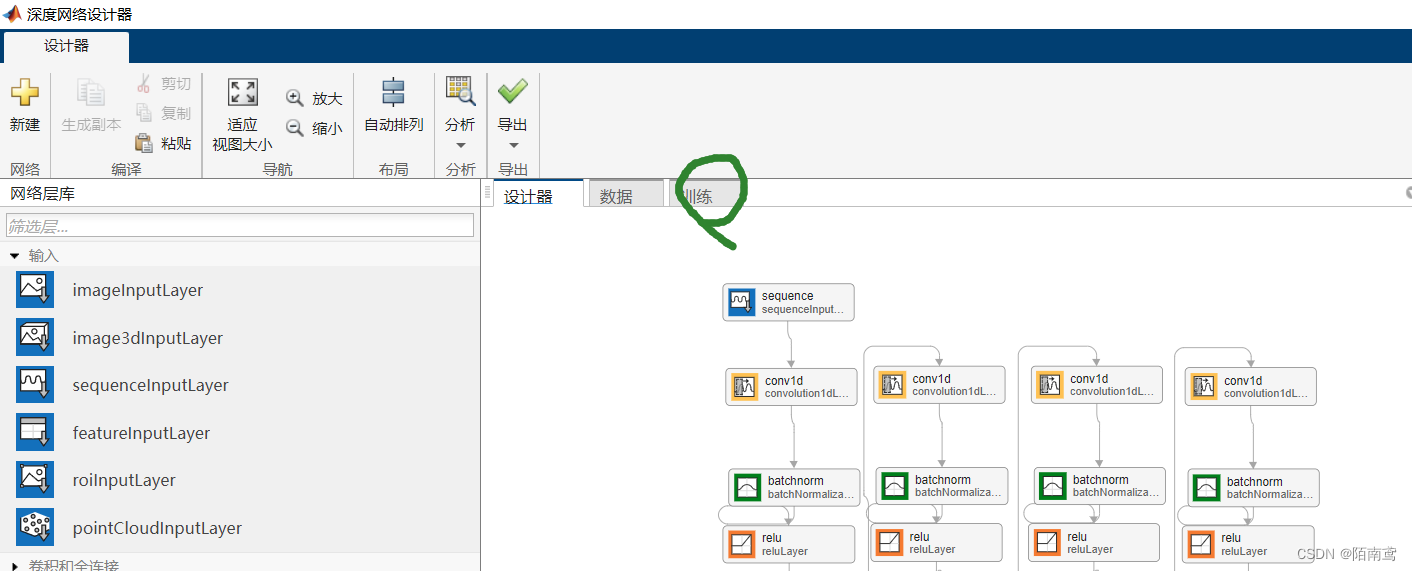
点击“训练选项”
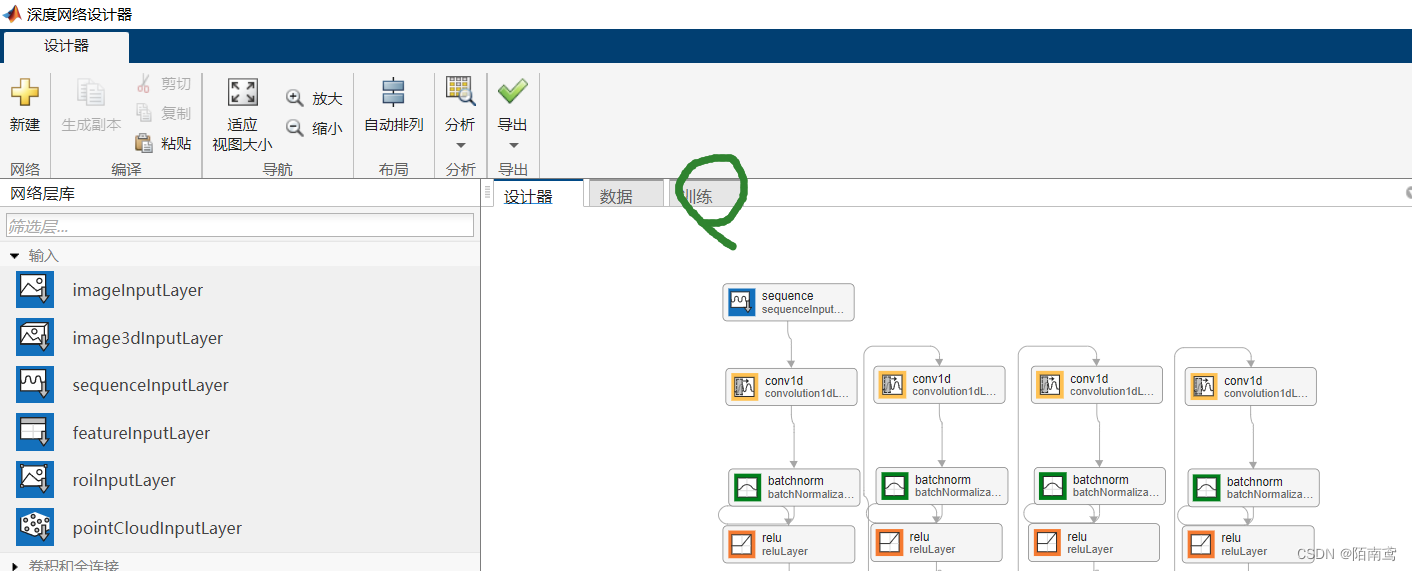
可以对优化器、学习率、批大小等参数进行设置,可以根据自己的需求进行参数修改

6、导出为代码(2DCNN可以直接使用工具箱进行训练,1DCNN我目前没有实现),也可以导出到工作区,具体看自己的需求。生成代码后可以在.m文件中直接修改参数,比较方便一点。
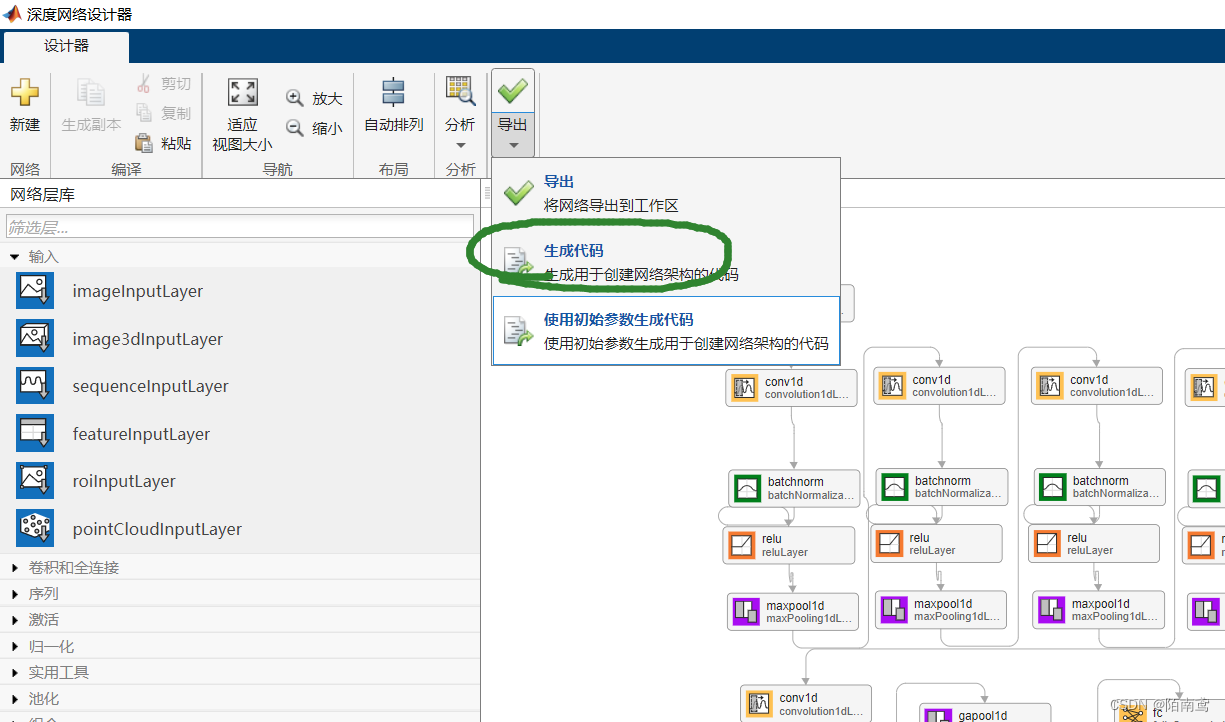
7、导出后的界面
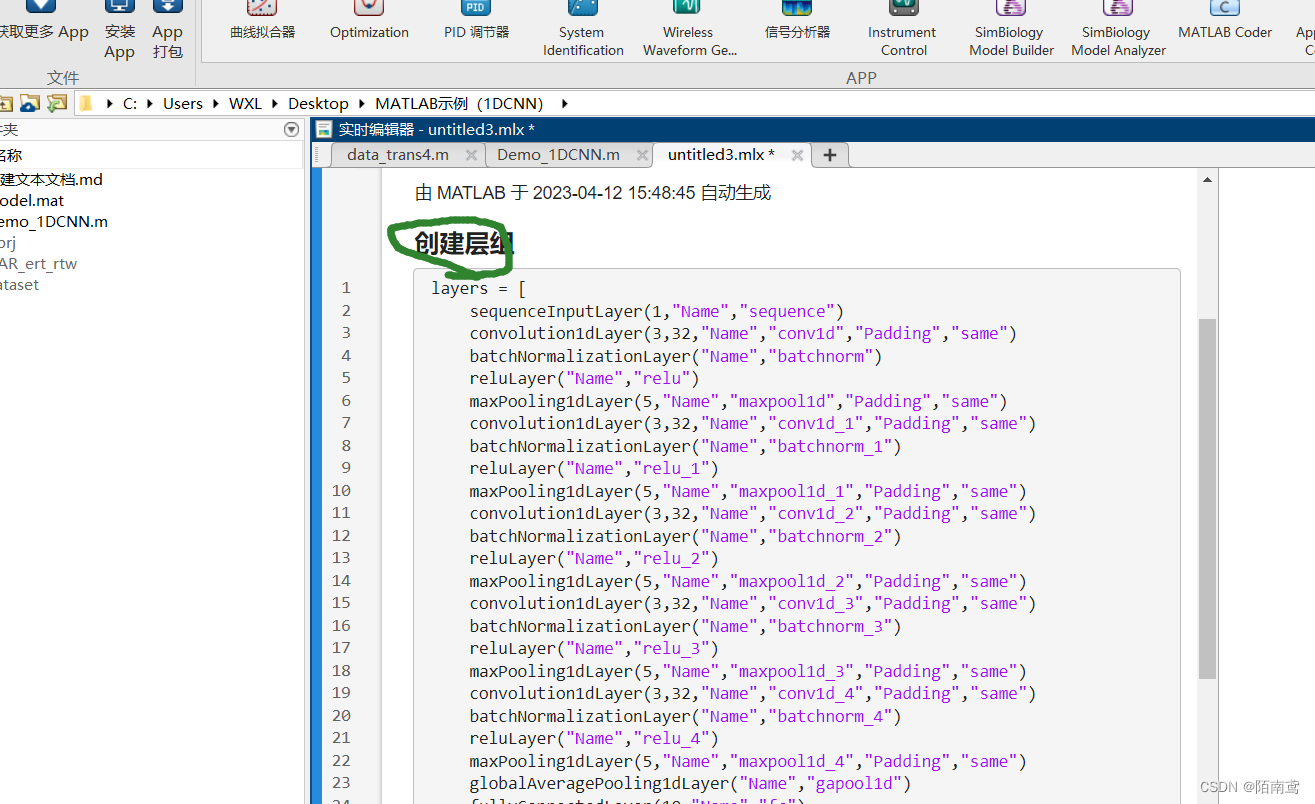
8、把创建层组里面的内容复制到自己的.m文件中,然后运行就可以实现模型的训练了
值得注意的是,生成的代码不包括优化器和批大小等参数的配置。
下面给出模型训练部分所需要的代码
clear all
close all
%% 数据加载和生成
% 数据说明:人体活动加速度数据,包括三轴加速度的X、Y、Z轴和合加速度
train_a = xlsread('dataset\train\A.xlsx');
train_x = xlsread('dataset\train\X.xlsx');
train_y = xlsread('dataset\train\Y.xlsx');
train_z = xlsread('dataset\train\Z.xlsx');
train_label = xlsread('dataset\train\label.xlsx');
test_a = xlsread('dataset\test\A.xlsx');
test_x = xlsread('dataset\test\X.xlsx');
test_y = xlsread('dataset\test\Y.xlsx');
test_z = xlsread('dataset\test\Z.xlsx');
test_label = xlsread('dataset\test\label.xlsx');
% 获取数组维度
[trainRow, trainCol] = size(train_a);
[testRow, testCol] = size(test_a);
% 创建存储加速度数据的元组
train = cell(trainRow,1);
test = cell(testRow, 1);
% 数据集生成
for i = 1:trainRow
train{
i, 1} = [train_a(i,:); train_x(i,:); train_y(i,:); train_z(i,:)];
end
for i = 1:testRow
test{
i, 1} = [test_a(i,:); test_x(i,:); test_y(i,:); test_z(i,:)];
end
%% 训练数据处理
% 标签类型转换
train_label = string(train_label);
train_label = categorical(train_label);
test_label = string(test_label);
test_label = categorical(test_label);
% 训练集测试集划分,选择总训练集的80%的数据用来作训练集,20%的数据作验证集
row_trian_1 = length(train)*0.8;
row_trian = int64(row_trian_1);
XTrain = train(1:row_trian, 1);
TTrain = train_label(1:row_trian, 1);
XValidation = train(row_trian:length(train), 1);
TValidation = train_label(row_trian:length(train), 1);
% 类别数量获取
numClasses = numel(categories(test_label));
%% 网络设计
kernelSize = 9;
layers = [
sequenceInputLayer(4,"Name","sequence","MinLength",128)
convolution1dLayer(kernelSize,32,"Name","conv1d","Padding","same")
batchNormalizationLayer("Name","batchnorm")
reluLayer("Name","relu")
maxPooling1dLayer(2,"Name","maxpool1d","Padding","same","Stride",2)
convolution1dLayer(kernelSize,64,"Name","conv1d_1","Padding","same")
batchNormalizationLayer("Name","batchnorm_1")
reluLayer("Name","relu_1")
maxPooling1dLayer(2,"Name","maxpool1d_1","Padding","same","Stride",2)
convolution1dLayer(kernelSize,128,"Name","conv1d_2","Padding","same")
batchNormalizationLayer("Name","batchnorm_2")
reluLayer("Name","relu_2")
maxPooling1dLayer(2,"Name","maxpool1d_2","Padding","same","Stride",2)
convolution1dLayer(kernelSize,256,"Name","conv1d_3","Padding","same")
batchNormalizationLayer("Name","batchnorm_3")
reluLayer("Name","relu_3")
maxPooling1dLayer(2,"Name","maxpool1d_3","Padding","same","Stride",2)
convolution1dLayer(kernelSize,512,"Name","conv1d_3","Padding","same")
batchNormalizationLayer("Name","batchnorm_3")
reluLayer("Name","relu_3")
maxPooling1dLayer(2,"Name","maxpool1d_3","Padding","same","Stride",2)
globalAveragePooling1dLayer("Name","gapool1d")
fullyConnectedLayer(128,"Name","fc")
reluLayer("Name","relu_4")
fullyConnectedLayer(64,"Name","fc_1")
reluLayer("Name","relu_5")
fullyConnectedLayer(numClasses,"Name","fc_2")
softmaxLayer("Name","softmax")
classificationLayer("Name","classoutput")];
%% 网络训练参数设置
% 批大小
miniBatchSize = 128;
% 优化器设置
options = trainingOptions("adam", ...
MiniBatchSize=miniBatchSize, ...
MaxEpochs=10, ...
ValidationData={
XValidation,TValidation}, ...
Plots="training-progress", ...
Verbose=0, ...
LearnRateSchedule="piecewise",...
LearnRateDropPeriod=10);
% 模型训练
[net, info] = trainNetwork(XTrain,TTrain,layers,options);
模型训练
这是运行上面代码所得到的训练进度
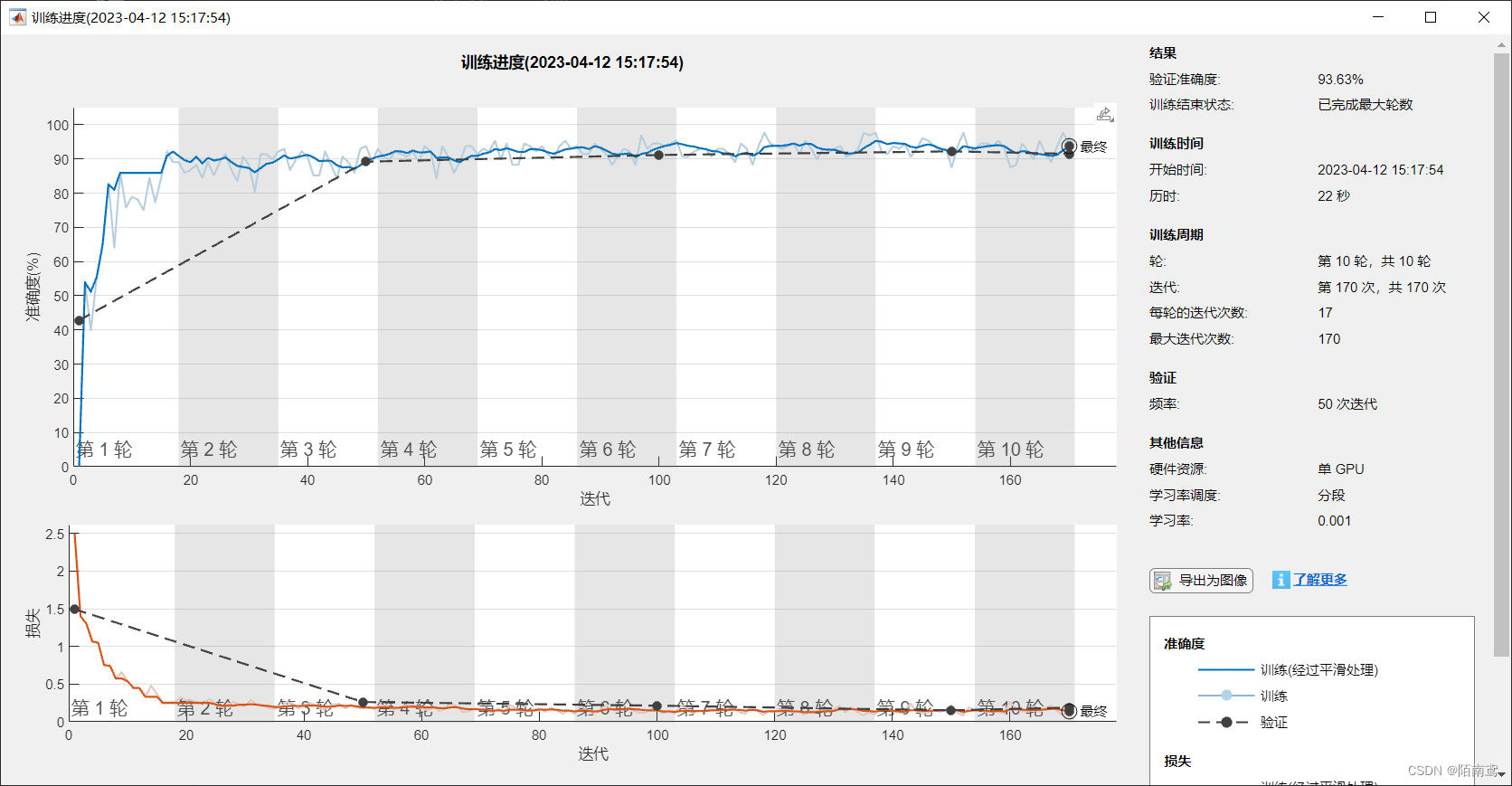
模型保存
%% 模型保存
% net代表上面模型的名字
% model.mat代表保存后的模型名字和路径
save('model.mat', "net")
模型加载
% 请注意,代码最右侧的net一定要写,这与保存模型时,模型的名称对应
net = load("model.mat").net;
模型评估
训练好的模型需要使用评价指标进行评估,以判断模型的性能是否符合我们的要求,下面给出各类别的准确率、召回率和F1分数的计算代码,以及宏平均(macro)准确率、召回率和F1分数
%% 模型评估
YPred = classify(net, test);
YPred = categorical(YPred);
acc = mean(YPred == test_label);
% 混淆矩阵
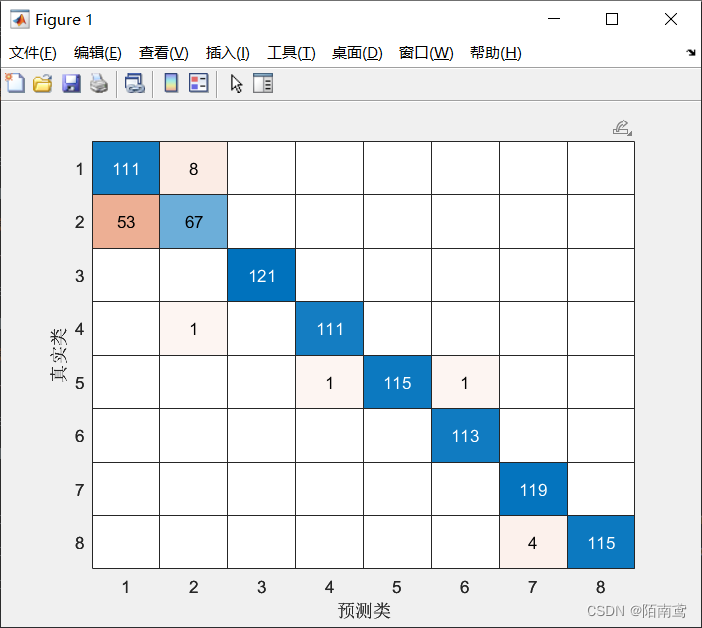
m = confusionmat(test_label,YPred);
% 绘制混淆矩阵
confusionchart(m,["类别1","类别2","类别3","类别4","类别5","类别6","类别7","类别8"])
A = m;
% 计算第一类的评价指标
c1_precise = m(1,1)/sum(m(:,1));
c1_recall = m(1,1)/sum(m(1,:));
c1_F1 = 2*c1_precise*c1_recall/(c1_precise+c1_recall);
% 计算第二类的评价指标
c2_precise = m(2,2)/sum(m(:,2));
c2_recall = m(2,2)/sum(m(2,:));
c2_F1 = 2*c2_precise*c2_recall/(c2_precise+c2_recall);
% 计算第三类的评价指标
c3_precise = m(3,3)/sum(m(:,3));
c3_recall = m(3,3)/sum(m(3,:));
c3_F1 = 2*c3_precise*c3_recall/(c3_precise+c3_recall);
% 计算第四类的评价指标
c4_precise = m(4,4)/sum(m(:,4));
c4_recall = m(4,4)/sum(m(4,:));
c4_F1 = 2*c4_precise*c4_recall/(c4_precise+c4_recall);
% 计算第五类的评价指标
c5_precise = m(5,5)/sum(m(:,5));
c5_recall = m(5,5)/sum(m(5,:));
c5_F1 = 2*c5_precise*c5_recall/(c5_precise+c5_recall);
% 计算第六类的评价指标
c6_precise = m(6,6)/sum(m(:,6));
c6_recall = m(6,6)/sum(m(6,:));
c6_F1 = 2*c6_precise*c6_recall/(c6_precise+c6_recall);
% 计算第七类的评价指标
c7_precise = m(7,7)/sum(m(:,7));
c7_recall = m(7,7)/sum(m(7,:));
c7_F1 = 2*c7_precise*c7_recall/(c7_precise+c7_recall);
macroPrecise = (c1_precise+c2_precise+c3_precise+c4_precise+c5_precise+c6_precise+c7_precise)/7;
macroRecall = (c1_recall+c2_recall+c3_recall+c4_recall+c5_recall+c6_recall+c7_recall)/7;
macroF1 = (c1_F1+c2_F1+c3_F1+c4_F1+c5_F1+c6_F1+c7_F1)/7;
MATLAB默认的混淆矩阵是使用数字表示类别,也可以自己进行更改,上面代码中的第六和第八行是更改混淆矩阵类别的关键,如果使用MATLAB默认的混淆矩阵,结果就是下面第一张图,如果按照本文代码生成的混淆矩阵则是第二张图

完整源代码
clear all
close all
%% 数据加载和生成
% 数据说明:人体活动加速度数据,包括三轴加速度的X、Y、Z轴和合加速度
train_a = xlsread('dataset\train\A.xlsx');
train_x = xlsread('dataset\train\X.xlsx');
train_y = xlsread('dataset\train\Y.xlsx');
train_z = xlsread('dataset\train\Z.xlsx');
train_label = xlsread('dataset\train\label.xlsx');
test_a = xlsread('dataset\test\A.xlsx');
test_x = xlsread('dataset\test\X.xlsx');
test_y = xlsread('dataset\test\Y.xlsx');
test_z = xlsread('dataset\test\Z.xlsx');
test_label = xlsread('dataset\test\label.xlsx');
% 获取数组维度
[trainRow, trainCol] = size(train_a);
[testRow, testCol] = size(test_a);
% 创建存储加速度数据的元组
train = cell(trainRow,1);
test = cell(testRow, 1);
% 数据集生成
for i = 1:trainRow
train{
i, 1} = [train_a(i,:); train_x(i,:); train_y(i,:); train_z(i,:)];
end
for i = 1:testRow
test{
i, 1} = [test_a(i,:); test_x(i,:); test_y(i,:); test_z(i,:)];
end
%% 训练数据处理
% 标签类型转换
train_label = string(train_label);
train_label = categorical(train_label);
test_label = string(test_label);
test_label = categorical(test_label);
% 训练集测试集划分,选择总训练集的80%的数据用来作训练集,20%的数据作验证集
row_trian_1 = length(train)*0.8;
row_trian = int64(row_trian_1);
XTrain = train(1:row_trian, 1);
TTrain = train_label(1:row_trian, 1);
XValidation = train(row_trian:length(train), 1);
TValidation = train_label(row_trian:length(train), 1);
% 类别数量获取
numClasses = numel(categories(test_label));
%% 网络设计
kernelSize = 9;
layers = [
sequenceInputLayer(4,"Name","sequence","MinLength",128)
convolution1dLayer(kernelSize,32,"Name","conv1d","Padding","same")
batchNormalizationLayer("Name","batchnorm")
reluLayer("Name","relu")
maxPooling1dLayer(2,"Name","maxpool1d","Padding","same","Stride",2)
convolution1dLayer(kernelSize,64,"Name","conv1d_1","Padding","same")
batchNormalizationLayer("Name","batchnorm_1")
reluLayer("Name","relu_1")
maxPooling1dLayer(2,"Name","maxpool1d_1","Padding","same","Stride",2)
convolution1dLayer(kernelSize,128,"Name","conv1d_2","Padding","same")
batchNormalizationLayer("Name","batchnorm_2")
reluLayer("Name","relu_2")
maxPooling1dLayer(2,"Name","maxpool1d_2","Padding","same","Stride",2)
convolution1dLayer(kernelSize,256,"Name","conv1d_3","Padding","same")
batchNormalizationLayer("Name","batchnorm_3")
reluLayer("Name","relu_3")
maxPooling1dLayer(2,"Name","maxpool1d_3","Padding","same","Stride",2)
convolution1dLayer(kernelSize,512,"Name","conv1d_3","Padding","same")
batchNormalizationLayer("Name","batchnorm_3")
reluLayer("Name","relu_3")
maxPooling1dLayer(2,"Name","maxpool1d_3","Padding","same","Stride",2)
globalAveragePooling1dLayer("Name","gapool1d")
fullyConnectedLayer(128,"Name","fc")
reluLayer("Name","relu_4")
fullyConnectedLayer(64,"Name","fc_1")
reluLayer("Name","relu_5")
fullyConnectedLayer(numClasses,"Name","fc_2")
softmaxLayer("Name","softmax")
classificationLayer("Name","classoutput")];
%% 网络训练参数设置
% 批大小
miniBatchSize = 128;
% 优化器设置
options = trainingOptions("adam", ...
MiniBatchSize=miniBatchSize, ...
MaxEpochs=10, ...
ValidationData={
XValidation,TValidation}, ...
Plots="training-progress", ...
Verbose=0, ...
LearnRateSchedule="piecewise",...
LearnRateDropPeriod=10);
% 模型训练
[net, info] = trainNetwork(XTrain,TTrain,layers,options);
%% 模型保存
save('model.mat', "net")
%% 模型加载
net = load("model.mat").net;
%% 模型评估
YPred = classify(net, test);
YPred = categorical(YPred);
acc = mean(YPred == test_label);
% 混淆矩阵
m = confusionmat(test_label,YPred);
% 绘制混淆矩阵
confusionchart(m,["类别1","类别2","类别3","类别4","类别5","类别6","类别7","类别8"])
% 计算第一类的评价指标
c1_precise = m(1,1)/sum(m(:,1));
c1_recall = m(1,1)/sum(m(1,:));
c1_F1 = 2*c1_precise*c1_recall/(c1_precise+c1_recall);
% 计算第二类的评价指标
c2_precise = m(2,2)/sum(m(:,2));
c2_recall = m(2,2)/sum(m(2,:));
c2_F1 = 2*c2_precise*c2_recall/(c2_precise+c2_recall);
% 计算第三类的评价指标
c3_precise = m(3,3)/sum(m(:,3));
c3_recall = m(3,3)/sum(m(3,:));
c3_F1 = 2*c3_precise*c3_recall/(c3_precise+c3_recall);
% 计算第四类的评价指标
c4_precise = m(4,4)/sum(m(:,4));
c4_recall = m(4,4)/sum(m(4,:));
c4_F1 = 2*c4_precise*c4_recall/(c4_precise+c4_recall);
% 计算第五类的评价指标
c5_precise = m(5,5)/sum(m(:,5));
c5_recall = m(5,5)/sum(m(5,:));
c5_F1 = 2*c5_precise*c5_recall/(c5_precise+c5_recall);
% 计算第六类的评价指标
c6_precise = m(6,6)/sum(m(:,6));
c6_recall = m(6,6)/sum(m(6,:));
c6_F1 = 2*c6_precise*c6_recall/(c6_precise+c6_recall);
% 计算第七类的评价指标
c7_precise = m(7,7)/sum(m(:,7));
c7_recall = m(7,7)/sum(m(7,:));
c7_F1 = 2*c7_precise*c7_recall/(c7_precise+c7_recall);
macroPrecise = (c1_precise+c2_precise+c3_precise+c4_precise+c5_precise+c6_precise+c7_precise)/7;
macroRecall = (c1_recall+c2_recall+c3_recall+c4_recall+c5_recall+c6_recall+c7_recall)/7;
macroF1 = (c1_F1+c2_F1+c3_F1+c4_F1+c5_F1+c6_F1+c7_F1)/7;