另一种方法应用比较广的就是深度学习方法,深度学习方法是将OCR识别划分为文字检测和文本识别部分
,这也是深度学习技术可以充分发挥功效的地方。使用比较广泛的网络结构是Differentiable Binarization+ CRNN。
Differentiable Binarization简称DB,是一种基于分割的文本检测算法。在文本检测算法中,基于分割的检测算法可以更好的处理弯曲等不规则形状的文本,因此往往能取得更好的检测效果。但是分割法后处理步骤中将分割结果转化为检测框的流程十分复杂,而且耗时严重,因此有人提出了一个可微的二值化模块(Differentiable Binarization),它可以在分割网络中执行二值化过程。将二值化阈值加入训练中学习,它将分割方法生成的概率图转换为文本的包围框/区域。分割网络结合DB模块进行优化,可以自适应设置二值化阈值,不仅简化了后处理,而且提高了文本检测的性能。可以获得更准确的检测边界,从而简化后处理的流程。主干网采用ResNet-18。

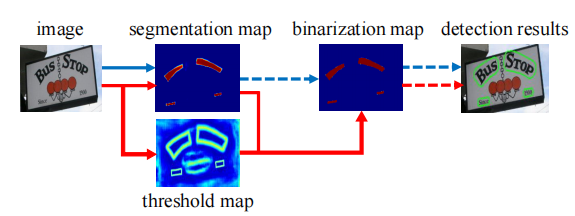
如图2所示(蓝色箭头所示):首先,设置一个固定的阈值,将分割网络产生的概率图转换为二值图像;
然后,使用一些启发式技术(如像素聚类)将像素分组到文本实例中。或者,我们的管道(图2中红色箭头所示)旨在将二值化操作插入分割网络中进行联合优化。通过这种方法,可以自适应预测图像中每个位置的阈值,从而充分区分前景和背景像素。然而,标准的二值化函数是不可微的,我们提出了一个近似的二值化函数,称为可微二值化(DB),当它与分割网络一起训练时是完全可微的。
通过结合简单的语义分割网络和DB模块,得到了一种鲁棒快速的场景文本检测器。