本文是基于一家饭店的菜品点单量来进行数据分析
数据集是meal_order_detail.xlsx,可以在网上下载
加载第三方库
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']='SimHei'
数据预处理
data1 = pd.read_excel('F:/谷歌浏览器下载/meal_order_detail.xlsx',sheet_name = 'meal_order_detail1')
data2 = pd.read_excel('F:/谷歌浏览器下载/meal_order_detail.xlsx',sheet_name = 'meal_order_detail2')
data3 = pd.read_excel('F:/谷歌浏览器下载/meal_order_detail.xlsx',sheet_name = 'meal_order_detail3')
sheet_name可以是从哪一个子表中获取数据
#合并数据集,并且删除空值列
data = pd.concat([data1,data2,data3],axis=0)
data.dropna(axis=1,inplace=True)
data.head()
数据分析
# 统计8月卖出菜品的平均值
# sum(data.amounts)
# round(data['amounts'].mean(),2)
round(np.mean(data['amounts']),2)
# 频数统计,什么菜最受欢迎
# 对菜名进行频数统计
dishs_count = data['dishes_name'].value_counts()[:10]
dishs_count
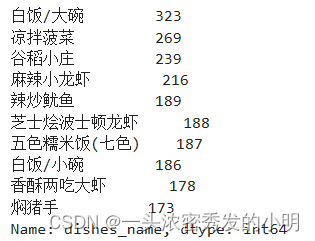
可以看出,顾客对大碗米饭的需求是比较高的,但是对小碗米饭的需求不是特别的高,素菜的需求比荤菜的高,可能是因为消费的时间正直夏季,比较炎热。
数据可视化
dishs_count.plot(kind='bar',color=['r'])
dishs_count.plot(kind='line',color=['g'])
for x,y in enumerate(dishs_count):
# 打印出的值的形状是(x,y)
print(x,y)
# 给数据图加数字
plt.text(x,y,y,ha='center',fontsize=14)
# x,y是位置,而y是所要呈现的内容
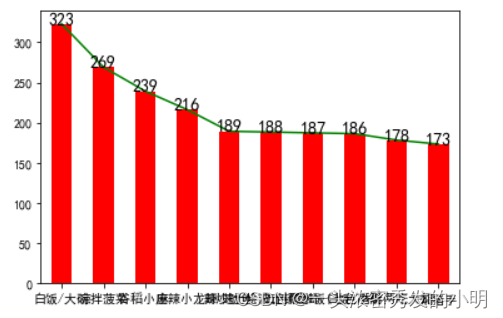
其中,ha参数是用来设置柱状图顶部的数据的位置,text()函数,第一个参数第二个参数是设置xy轴的数据,第三个参数是整个数据表所要呈现的数据。
# 订单点菜的种类最多
detail_group = data['order_id'].value_counts()[:10]
# detail_group
detail_group.plot(kind='bar',fontsize=14,color=['r','b','y','g','m'])
detail_group.plot(kind='line',color=['g'])
for x,y in enumerate(detail_group):
print(x,y)
plt.text(x,y,y,ha='center')
plt.title('订单点菜统计')
plt.xlabel('订单id',fontsize=16)
plt.ylabel('菜品名称',fontsize=16)
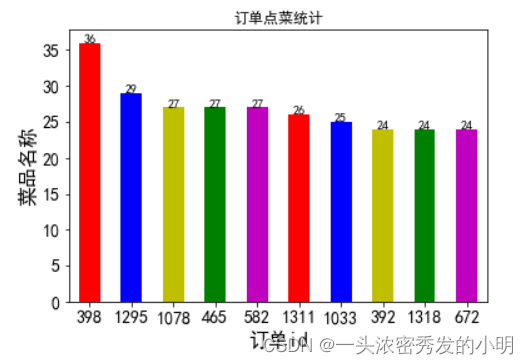
下面我们来看哪个订单id平均菜品最贵,我们排出他的前十名,并且统计消费总额
data['total_amounts'] = data['counts']*data['amounts']
datagroup = data[['order_id','counts','total_amounts']].groupby(by='order_id')
group_sum = datagroup.sum()
sort_counts = group_sum.sort_values(by='counts',ascending=False)
sort_counts['counts'][:10].plot(kind = 'bar')``
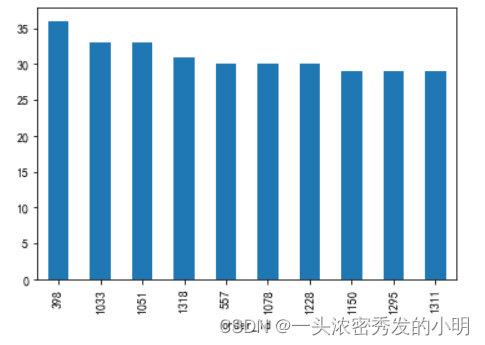
我们可以看到order_id为398的菜品是销量最好的.
那么一天中什么时间点,点菜量比较集中呢?
data['hourcount'] = 1
# 将时间转化成日期类型存储
data['time']=pd.to_datetime(data['place_order_time'])
data['hour']=data['time'].map(lambda x:x.hour)
# data.head()
gp_by_hour = data.groupby(by='hour').count()['hourcount']
gp_by_hour.plot(kind='bar',fontsize=12,color='b')
plt.xlabel('下单数量')
plt.ylabel('小时')
plt.title('下单数和小时的关系图')
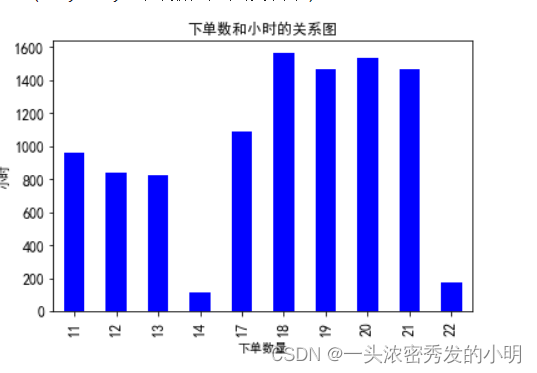
可以看出,在18点到21点的时候,点单消费量占一整天的点单量的比重是最大的,一天辛苦的工作结束之后,人们都想犒劳犒劳自己。
查看周几的点单人数最多,映射到具体星期几
data['weekcount'] = 1
# 把信息存储到
data['weekday'] = data['time'].map(lambda x:x.weekday())
# gp_by_weekday = data.drop(columns=['weekend'],axis=1)
gp_by_weekday=data.groupby('weekday').count()['weekcount']
gp_by_weekday.plot(kind='bar')
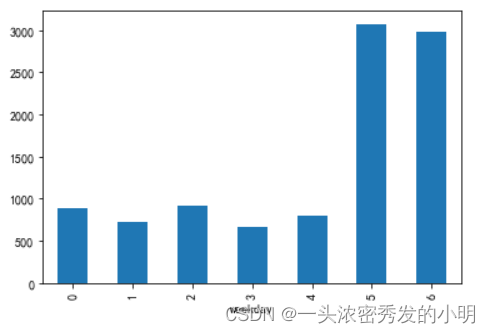
weekday()函数返回的是0到6的数值,来代表周一到周日,可以看出56也就是周六周天的点单量是最大的