python爬虫 m3u8的下载及AES加密的解密
前言
这里与hxdm分享一篇关于m3u8视频流的爬取下载合并成mp4视频的方法,并且支持AES加密后的ts文件解密。xdm懂的都懂,也不用感谢了,哈哈哈!!!至于m3u8_url的链接就自己去找了哈。
好了,废话不多说,直接上代码!
(注意:本篇文章只做学习思路交流,不做除此之外的任何用途!!!)

目前测试过m3u8文件的AES加密后的有:
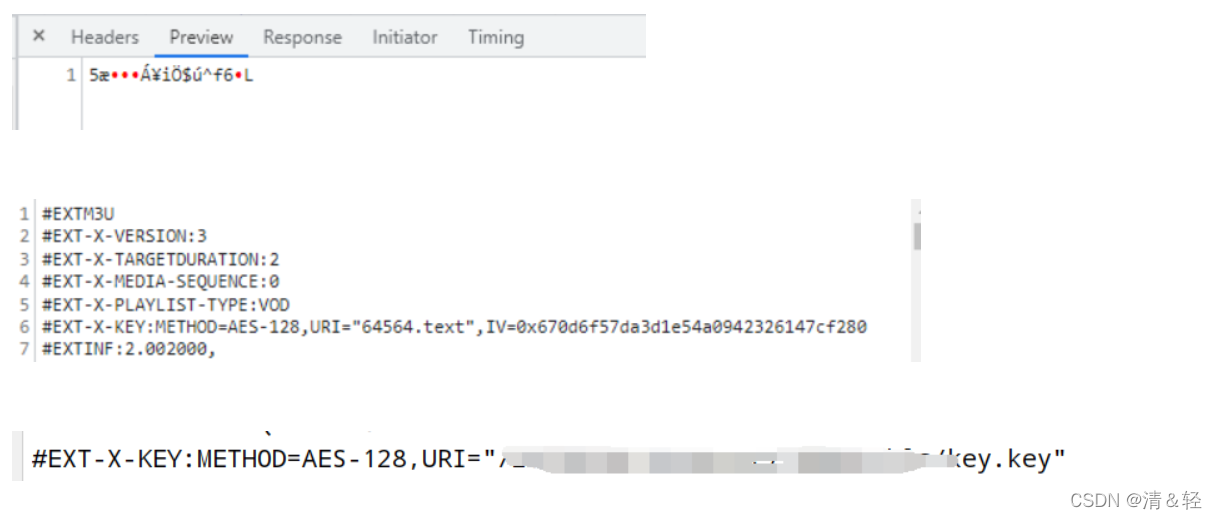
2023.1.23更新
# -*- coding:utf-8 -*-
"""
m3u8文件 视频下载 多线程 支持代理
"""
import requests, threading
import os, shutil, time, random
from Crypto.Cipher import AES
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
from anti_useragent import UserAgent
# pip install -U anti-useragent
def get_ua(platform='windows', browser_type='chrome', min_version=80, max_version=100):
'''
:param platform: 'windows', 'linux', 'android'
:param browser_type: 'chrome', 'firefox'
:param min_version:
:param max_version:
:return:
'''
ua = UserAgent(platform=platform, min_version=min_version, max_version=max_version)[browser_type]
return ua
# IP代理池,可自行封装
def get_proxy():
ip = "" #
proxies = {
"http": ip,
"https": ip,
}
# return proxies if ip else None
if ip:
return proxies
else:
print("######未设置代理!!!######")
return None
class M3u8Downloader:
"""
save_path:视频文件存放路径
save_file_name:视频文件名
m3u8_url:m3u8_url链接
isUseproxies:是否使用代理
isUseThreadPool:是否开启线程池
"""
def __init__(self, save_path:str='./', save_file_name:str="test.mp4", m3u8_url:str=None,isUseproxies=False,isUseThreadPool=False,threadPoolNum=8,proxies=None,timeOut=None, isShutilAllTsFile=True):
if not m3u8_url: raise Exception("没有传入m3u8_url链接!!!")
self.save_path= save_path
self.save_file_name=str(save_file_name).replace(".mp4",'')+".mp4"
self.save_file_name2=str(save_file_name).replace(".mp4",'')
self.m3u8_url= m3u8_url
self.isUseproxies= isUseproxies
self.isUseThreadPool= isUseThreadPool
self.threadPoolNum= threadPoolNum
self.proxies= proxies
self.proxies_usable_flag= False
self.timeOut= timeOut if timeOut else 5
if not isUseproxies: self.timeOut=None
self.isShutilAllTsFile = isShutilAllTsFile
self.proxies_usable_flag = False
self.proxies_fail_num= 0
self.download_ok_num = 0
self.lock = threading.Lock()
self.lock2 = threading.Lock()
self.headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Not?A_Brand\";v=\"8\", \"Chromium\";v=\"108\", \"Google Chrome\";v=\"108\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
self.session = None
self.set_session()
self.lock2.release()
# 视频文件存放路径
if not os.path.exists(fr'{
self.save_path}/mp4'): os.mkdir(fr'{
self.save_path}/mp4')
if not os.path.exists(fr'{
self.save_path}/ts'): os.mkdir(fr'{
self.save_path}/ts')
self.all_ts_path = fr'{
self.save_path}/ts/{
self.save_file_name2}'
if not os.path.exists(self.all_ts_path):
os.mkdir(self.all_ts_path)
def set_session(self):
self.lock2.acquire()
if not self.proxies_usable_flag:
try:
self.session.close()
except: pass
self.session = requests.session()
self.UA = get_ua()
self.UA_V = self.UA.split("Chrome/")[1].split('.')[0]
self.headers['User-Agent'] = self.UA
self.headers['sec-ch-ua'] = f'"Not?A_Brand";v="8", "Chromium";v="{
self.UA_V}", "Google Chrome";v="{
self.UA_V}"'
def send_request(self, url):
while True:
time.sleep(random.random()+0.2)
if self.proxies_fail_num > 20:
raise Exception(f"异常:{
url} 连续请求次数超过20次失败>>>异常退出!!!")
if self.isUseproxies:
self.lock.acquire()
if not self.proxies_usable_flag:
self.proxies = get_proxy() # 使用IP代理池
self.proxies_usable_flag = True
self.lock.release()
try: self.lock2.release()
except: pass
try:
response = self.session.get(url=url, headers=self.headers, proxies=self.proxies, timeout=self.timeOut)
if response.status_code == 200:
self.proxies_usable_flag = True
self.proxies_fail_num = 0
break
else:
raise Exception(f'{
response}>>>响应异常!')
except Exception as e:
print(f"异常:{
url}请求异常!!!\n{
e}")
if self.isUseproxies:
self.proxies_usable_flag = False
self.proxies_fail_num += 1
self.set_session()
else:
raise Exception(f"异常:{
url} >>>异常退出!!!\n{
e}")
return response
# 有加密则进行解析
def parse_aes_encryption(self, key_content):
encryption_method = None
self.m3u8_key_url = None
self.iv = None
print('key_content:', key_content)
try:
split_result = key_content.split(',')
encryption_method = split_result[0].split('=')[1]
self.m3u8_key_url = urljoin(self.m3u8_url,split_result[1].split('"')[1])
if 'IV' in key_content or 'iv' in key_content:
iv = split_result[2].split('=')[1]
print("m3u8文件里面的iv:", iv)
self.iv = iv[2:18].encode()
else:
self.iv = b'0000000000000000'
except Exception as e:
print(e)
print('加密方法未知!')
print('加密方法:', encryption_method)
print('m3u8_key_url:', self.m3u8_key_url)
print('解密使用的iv:', self.iv)
print()
def get_m3u8_txt(self):
txt = self.send_request(self.m3u8_url).text
# print(txt)
each_line_list = txt.strip('\n').split('\n') # 对m3u8里面的内容提取出每一行数据
self.all_ts_list = []
video_time = []
if '#EXTM3U' != each_line_list[0]:
print(f"请求m3u8得到的内容:\n{
txt}")
raise Exception("异常:请求的m3u8文件数据存在异常!!!")
for i in each_line_list:
if '#EXT-X-KEY' in i: # 判断是否加密
self.parse_aes_encryption(i)
elif not i.startswith('#') or i.startswith('http') or i.endswith('.ts'):
each_ts_url = urljoin(self.m3u8_url, i)
self.all_ts_list.append(each_ts_url)
elif i.startswith('#EXTINF'):
time_ = float(i.strip().split(':')[1][:-1])
video_time.append(time_)
print('视频时长约为:{:.2f}分钟\n'.format(sum(video_time) / 60))
def get_m3u8_key_decode_data(self, key_url=None):
try:
key_url = key_url if key_url else self.m3u8_key_url
key = self.send_request(key_url).content
print("请求m3u8_key_url得到的加密密钥:", key)
self.aes_decode_data = AES.new(key, AES.MODE_CBC, self.iv)
print("解密后的密钥:", key)
print()
except Exception as e:
self.aes_decode_data = None
print(e)
print("m3u8_key解密失败!!!\n")
# 下载并保存ts
def download_ts(self, i, ts_url):
if self.aes_decode_data:
ts_data = self.send_request(ts_url).content
ts_data = self.aes_decode_data.decrypt(ts_data)
else:
ts_data = self.send_request(ts_url).content
with open(fr'{
self.save_path}/ts/{
self.save_file_name2}/{
i}.ts', mode='wb+') as f:
f.write(ts_data)
print(f'{
i}.ts下载完成!')
self.download_ok_num += 1
return 0
# 最后合并所有的ts文件
def merge_all_ts_file(self):
print('开始合并视频……')
ts_file_list = os.listdir(self.all_ts_path)
ts_file_list.sort(key=lambda x: int(x[:-3])) # 进行排序
with open(self.save_path + f'/mp4/{
self.save_file_name}', 'wb+') as fw:
for i in range(len(ts_file_list)):
fr = open(os.path.join(self.all_ts_path, ts_file_list[i]), 'rb')
fw.write(fr.read())
fr.close()
if self.isShutilAllTsFile:
shutil.rmtree(self.all_ts_path) # 删除所有的ts文件
print("所有的ts文件删除完成!")
print('视频合并完成!')
def main(self):
self.get_m3u8_txt()
self.get_m3u8_key_decode_data()
print(f"######开始下载ts文件 数量:{
len(self.all_ts_list)}######")
t_future = []
def handle_result(future):
pass
pool = ThreadPoolExecutor(max_workers=self.threadPoolNum)
for i, ts_url in enumerate(self.all_ts_list):
# if i > 3: # 测试
# break
try:
if not self.isUseThreadPool:
self.download_ts(i, ts_url)
else:
future = pool.submit(self.download_ts, i, ts_url)
t_future.append(future)
except Exception as e:
print(e)
print(f"<{
i},{
ts_url}> 获取失败!!!")
break
if self.isUseThreadPool:
for future in as_completed(t_future):
future.add_done_callback(handle_result)
pool.shutdown()
print(f"######{
self.download_ok_num}个ts文件下载完成######")
self.merge_all_ts_file()
try:
self.session.close()
except:
pass
if __name__ == '__main__':
m3u8_url = ""
m3u8_downloader = M3u8Downloader(m3u8_url=m3u8_url,isUseproxies=True, isUseThreadPool=True, threadPoolNum=10)
m3u8_downloader.headers['Origin'] = '' # 可能需要根据实际情况添加
m3u8_downloader.headers['Referer'] = ''
m3u8_downloader.main()
线程池版
完整代码
import os,shutil,time,requests
from Crypto.Cipher import AES
from fake_useragent import UserAgent
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor
video_download_path = './m3u8Download'
save_mp4_path = './m3u8Download/testVideo'
save_temporary_ts_path = './m3u8Download/temporary_ts'
if not os.path.exists(video_download_path):
os.makedirs(save_mp4_path)
os.mkdir(save_temporary_ts_path)
if not os.path.exists(save_temporary_ts_path):
os.mkdir(save_temporary_ts_path)
#先定义一个发送请求方法,方便后面的重复调用
def send_request(url):
headers = {
'User-Agent': UserAgent().Chrome,
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
try:
response = requests.get(url=url,headers=headers)
if response.status_code == 200:
return response
else:
print(response,'响应异常!')
exit()
except Exception as e:
print('m3u8链接请求异常!!!')
print(e)
#这里先发送m3u8链接请求,得到返回的响应数据
def get_m3u8_response_data():
m3u8_data = send_request(m3u8_url).text
return m3u8_data
#然后对得到的m3u8数据进行解析,得到每一个ts_url链接,和视频的时长,有加密则提取出
def parse_m3u8_data():
m3u8_data = get_m3u8_response_data()
each_line_list = m3u8_data.strip('\n').split('\n') #对m3u8里面的内容提取出每一行数据
all_ts_list = []
video_time = []
AES_decode_data = None
if '#EXTM3U' in each_line_list:
for i in each_line_list:
if '#EXT-X-KEY' in i: #判断是否加密
encryption_method,key_url, iv = parse_AES_encryption(i)
print('加密方法:',encryption_method)
key_url = urljoin(m3u8_url,key_url)
AES_decode_data = AES_decode(key_url,iv)
if not i.startswith('#') or i.startswith('http') or i.endswith('.ts'):
each_ts_url = urljoin(m3u8_url, i)
all_ts_list.append(each_ts_url)
if i.startswith('#EXTINF'):
time_ = float(i.strip().split(':')[1][:-1])
video_time.append(time_)
print('视频时长约为:{:.2f}分钟'.format(sum(video_time) / 60))
return all_ts_list,AES_decode_data
#再对每一个ts_url链接发送请求(用线程池)
def get_each_ts_response_data():
print('开始下载视频……')
all_ts_list,AES_decode_data = parse_m3u8_data()
###初始化一个线程池,并设置最大线程数为30
with ThreadPoolExecutor(max_workers=30) as executor:
for i,ts_url in enumerate(all_ts_list):
executor.submit(download_ts, i,ts_url,AES_decode_data)
'''这里可以使用单线程来下载3个ts文件做测试'''
# i = 0
# for ts_url in all_ts_list:
# download_ts(i,ts_url,AES_decode_data)
# i += 1
# if i > 3:
# break
print('视频下载结束!')
return True
#下载并保存ts
def download_ts(i,ts_url,AES_decode_data):
if AES_decode_data:
ts_data = send_request(ts_url).content
ts_data = AES_decode_data.decrypt(ts_data)
else:
ts_data = send_request(ts_url).content
with open(f'{
save_temporary_ts_path}/{
i}.ts',mode='wb+') as f:
f.write(ts_data)
print(f'{
i}.ts下载完成!')
#解析加密内容
def parse_AES_encryption(key_content):
if 'IV' in key_content or 'iv' in key_content:
parse_result = key_content.split('=')
encryption_method = parse_result[1].split(',')[0]
key_url = parse_result[2].split('"')[1]
iv = parse_result[3]
iv = iv[2:18].encode()
else:
parse_result = key_content.split('=')
encryption_method = parse_result[1].split(',')[0]
key_url = parse_result[2].split('"')[1]
iv = None
return encryption_method, key_url, iv
#AES解密
def AES_decode(key_url,iv):
print("key_url:", key_url)
print("iv:",iv)
key = send_request(key_url).content
if iv:
AES_decode_data = AES.new(key, AES.MODE_CBC, iv)
else:
AES_decode_data = AES.new(key, AES.MODE_CBC, b'0000000000000000')
return AES_decode_data
#最后合并所有的ts文件
def merge_all_ts_file():
print('开始合并视频……')
ts_file_list = os.listdir(save_temporary_ts_path)
ts_file_list.sort(key=lambda x: int(x[:-3]))
with open(save_mp4_path+'/video.mp4', 'wb+') as fw:
for i in range(len(ts_file_list)):
fr = open(os.path.join(save_temporary_ts_path, ts_file_list[i]), 'rb')
fw.write(fr.read())
fr.close()
shutil.rmtree(save_temporary_ts_path) #删除所有的ts文件
print('视频合并完成!')
def begin():
if get_each_ts_response_data():
merge_all_ts_file()
if __name__ == '__main__':
start_time = time.time()
###m3u8_url链接自己找哈!
m3u8_url = 'https://xxx.m3u8'
begin()
end_time = time.time()
print(f'总共耗时:{
end_time-start_time}秒')
异步协程版
import os,shutil,time
import asyncio,aiohttp,aiofiles
from Crypto.Cipher import AES
from fake_useragent import UserAgent
from urllib.parse import urljoin
class asyncioDownloadM3u8:
def __init__(self,m3u8_url):
self.m3u8_url = m3u8_url
self.AES_decode_data = None #AES解密数据
self.video_download_path = './m3u8Download'
self.save_mp4_path = './m3u8Download/testVideo'
self.save_temporary_ts_path = './m3u8Download/temporary_ts'
if not os.path.exists(self.video_download_path):
os.makedirs(self.save_mp4_path)
os.mkdir(self.save_temporary_ts_path)
if not os.path.exists(save_temporary_ts_path):
os.mkdir(save_temporary_ts_path)
async def send_request(self,url):
async with aiohttp.ClientSession() as session:
try:
headers = {
'User-Agent': UserAgent().Chrome,
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
async with session.get(url, headers=headers) as response:
assert response.status == 200
content = await response.read()
return content
except Exception as e:
print('m3u8链接请求异常!!!')
print(e)
exit()
async def parse_m3u8_data(self):
content = await self.send_request(self.m3u8_url)
m3u8_data = content.decode('utf-8')
each_line_list = m3u8_data.strip('\n').split('\n')
all_ts_list = []
video_time = []
AES_decode_data = None
if '#EXTM3U' in each_line_list:
for i in each_line_list:
if '#EXT-X-KEY' in i: # 判断是否加密
encryption_method, key_url, iv = await self.parse_AES_encryption(i)
print('加密方法:', encryption_method)
key_url = urljoin(m3u8_url, key_url)
self.AES_decode_data = await self.AES_decode(key_url, iv)
if not i.startswith('#') or i.startswith('http') or i.endswith('.ts'):
each_ts_url = urljoin(m3u8_url, i)
all_ts_list.append(each_ts_url)
if i.startswith('#EXTINF'):
time_ = float(i.strip().split(':')[1][:-1])
video_time.append(time_)
print('视频时长约为:{:.2f}分钟'.format(sum(video_time) / 60))
return all_ts_list, AES_decode_data
async def get_each_ts_response_data(self):
print('开始下载视频……')
all_ts_list, AES_decode_data = await self.parse_m3u8_data()
tasks = []
i = 0
for ts_url in all_ts_list:
task = asyncio.create_task(self.download_ts(i,ts_url))
tasks.append(task)
i += 1
#await asyncio.sleep(1) #担心爬取太快,可以使用异步休眠
# if i > 2:
# break
await asyncio.wait(tasks)
print('视频下载结束!')
async def download_ts(self,i,ts_url):
if self.AES_decode_data:
ts_data = await self.send_request(ts_url)
ts_data = self.AES_decode_data.decrypt(ts_data)
else:
ts_data = await self.send_request(ts_url)
async with aiofiles.open(f'{
self.save_temporary_ts_path}/{
i}.ts', mode="wb") as f:
await f.write(ts_data)
print(f'{
i}.ts下载完成!')
async def parse_AES_encryption(self,key_content):
if 'IV' in key_content or 'iv' in key_content:
parse_result = key_content.split('=')
encryption_method = parse_result[1].split(',')[0]
key_url = parse_result[2].split('"')[1]
iv = parse_result[3]
iv = iv[2:18].encode()
else:
parse_result = key_content.split('=')
encryption_method = parse_result[1].split(',')[0]
key_url = parse_result[2].split('"')[1]
iv = None
return encryption_method, key_url, iv
async def AES_decode(self,key_url, iv):
print("key_url:", key_url)
print("iv:",iv)
key = await self.send_request(key_url)
if iv:
AES_decode_data = AES.new(key, AES.MODE_CBC, iv)
else:
AES_decode_data = AES.new(key, AES.MODE_CBC, b'0000000000000000')
return AES_decode_data
async def merge_all_ts_file(self):
print('开始合并视频……')
ts_file_list = os.listdir(self.save_temporary_ts_path)
ts_file_list.sort(key=lambda x: int(x[:-3]))
async with aiofiles.open(self.save_mp4_path + '/video.mp4', 'wb+') as fw:
for i in range(len(ts_file_list)):
fr = open(os.path.join(self.save_temporary_ts_path, ts_file_list[i]), 'rb')
await fw.write(fr.read())
fr.close()
shutil.rmtree(self.save_temporary_ts_path)
print('视频合并完成!')
async def begin(self):
await self.get_each_ts_response_data()
await self.merge_all_ts_file()
if __name__ == '__main__':
start_time = time.time()
###m3u8_url链接自己找哈!
m3u8_url = 'https://xxx.m3u8'
adm = asyncioDownloadM3u8(m3u8_url=m3u8_url)
loop = asyncio.get_event_loop()
loop.run_until_complete(adm.begin())
end_time = time.time()
print(f'总共耗时:{
end_time - start_time}秒')
