前言
爬虫获取m3u8视频资源的步骤
目前所要作的流程处理
先把m3u8里下载链接批量提取.png
把这几百个切片链接先批量下载.png
再批量改文件后缀为.ts
再按照m3u8文件提取所有不规则链接文件的【顺序】.png
然后改切片的文件名为0001,0002,0003......顺序.png
然后用ffmpeg或者moviepy或者其他工具合并就行.png
看起来也没有那么麻烦…(流汗黄豆)
开始操作
目前已有材料:爬下来的网页源码和从中获取的m3u8文件

把.m3u8改成.txt格式便于操作
批量正则提取和下载
写脚本从原来的m3u8文件中正则表达提取出所有干净的下载链接,将其放到另外一个.txt文件;并且从中下载所有的切片文件
程序代码如下
import requests
import re
from io import BytesIO
import urllib3
import os
t = open("b7729bb022ae5d382df1fd28ac61f1178c3f424c.txt", "r", encoding='utf-8')
data = t.readlines()
t.close()
for line in data:
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
string = str(line)
url = re.findall(pattern,string)
f1 = open("url提取.txt", "a+", encoding='utf-8')
for urls in url:
f1.write(urls+'\n')
f1.close()
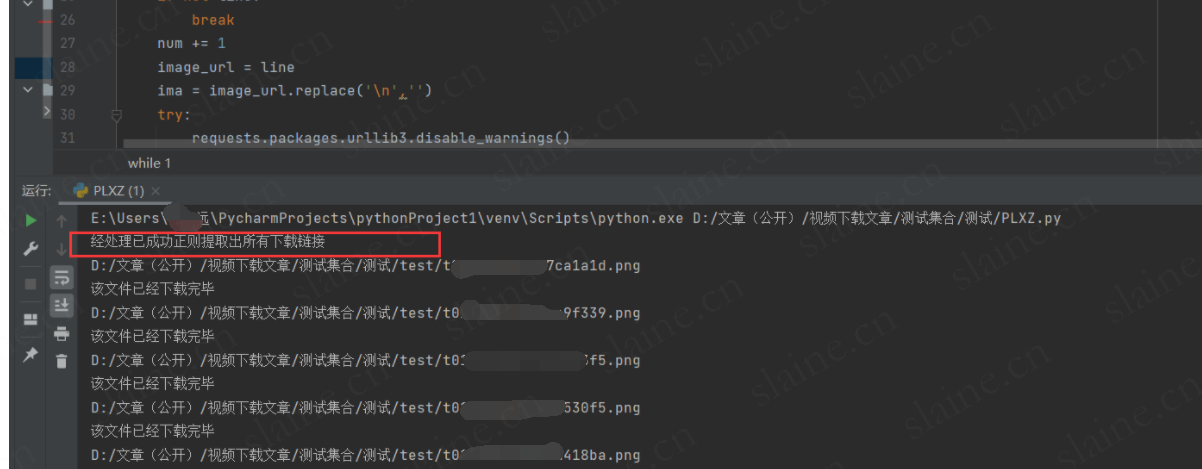
print("经处理已成功正则提取出所有下载链接")
file = open("./url提取.txt") # 打开存放链接的TXT文档
num = 0
while 1:
line = file.readline()
if not line:
break
num += 1
image_url = line
ima = image_url.replace('\n','')
try:
requests.packages.urllib3.disable_warnings()
r = requests.get(ima,verify=False)
path = re.sub("https://p0.ssl.cdn.btime.com/|https://p1.ssl.cdn.btime.com/|https://p2.ssl.cdn.btime.com/|https://p3.ssl.cdn.btime.com/|https://p4.ssl.cdn.btime.com/", "D:/文章(公开)/视频下载文章/测试集合/测试/test/", line)
path = re.sub('\n', '',path)
path = path.replace("?size=1x1", "")
print(path)
f = open(path, "wb")
f.write(r.content) # 将响应对象的内容写下来
print("该文件已经下载完毕")
f.close()
except Exception as e:
print('无法下载,%s' % e)
continue
print("经处理所有切片文件已经下载完毕")
file.close()
正常运行
生成提取出的下载链接
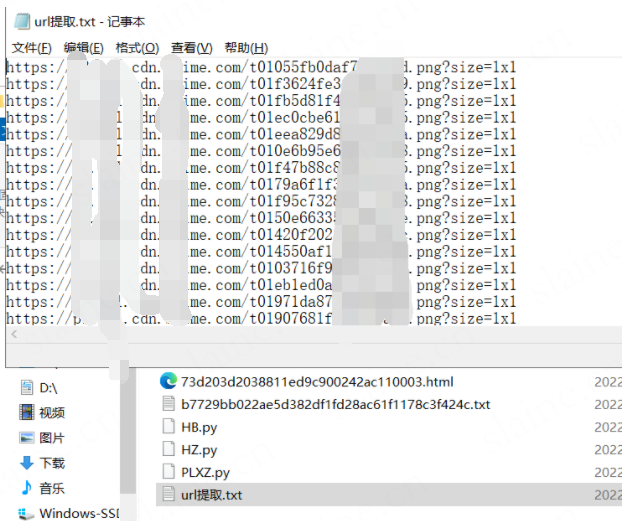
并且下载到指定位置
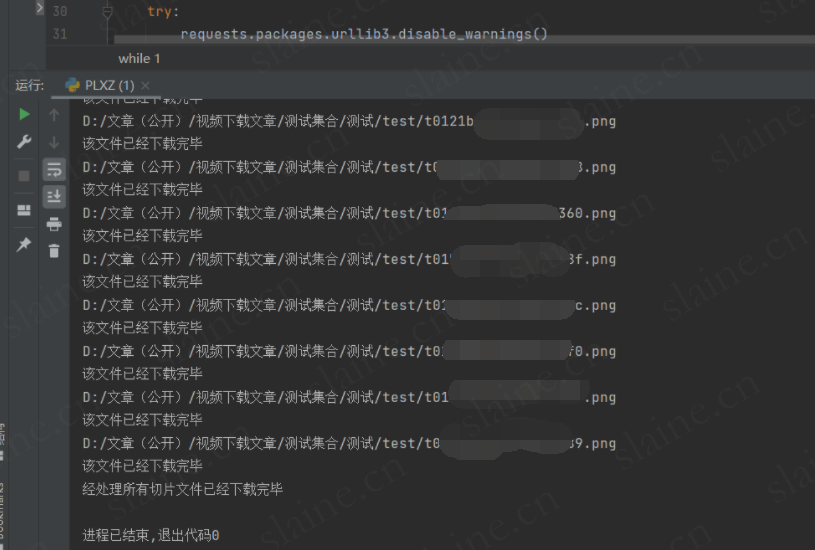
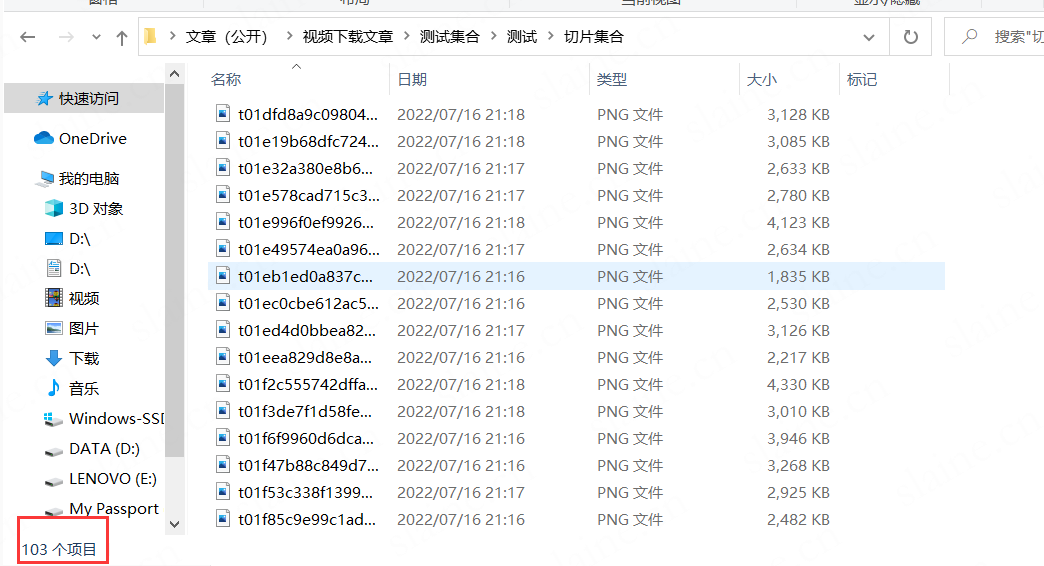
运行结束
批量改后缀
程序代码如下
import os
files = os.listdir('.')
for filename in files:
portion = os.path.splitext(filename)
if portion[1] == ".png":
newname = portion[0] + ".ts"
os.rename(filename,newname)
正常运行
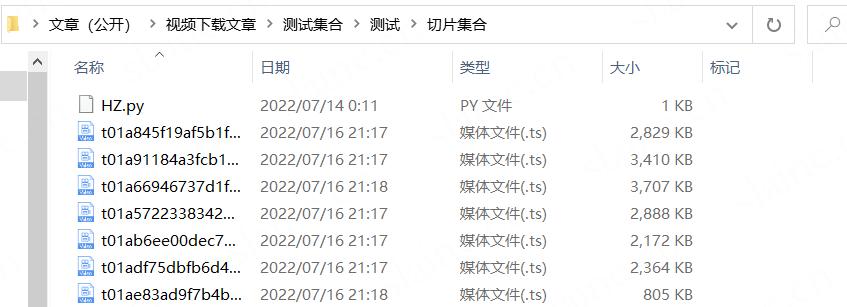
按m3u8指定顺序改文件切片名
接下来就是最关键的根据.m3u8里文件下载链接顺序批量修改文件名的环节
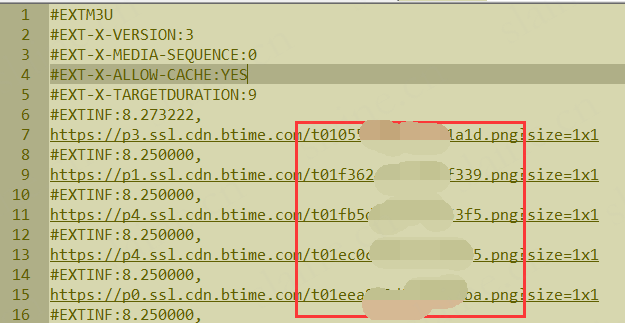
根据已有顺序改文件名为0001,0002,0003…顺序,这对之后的文件合并至关重要
这里就用到刚才提取的url文件
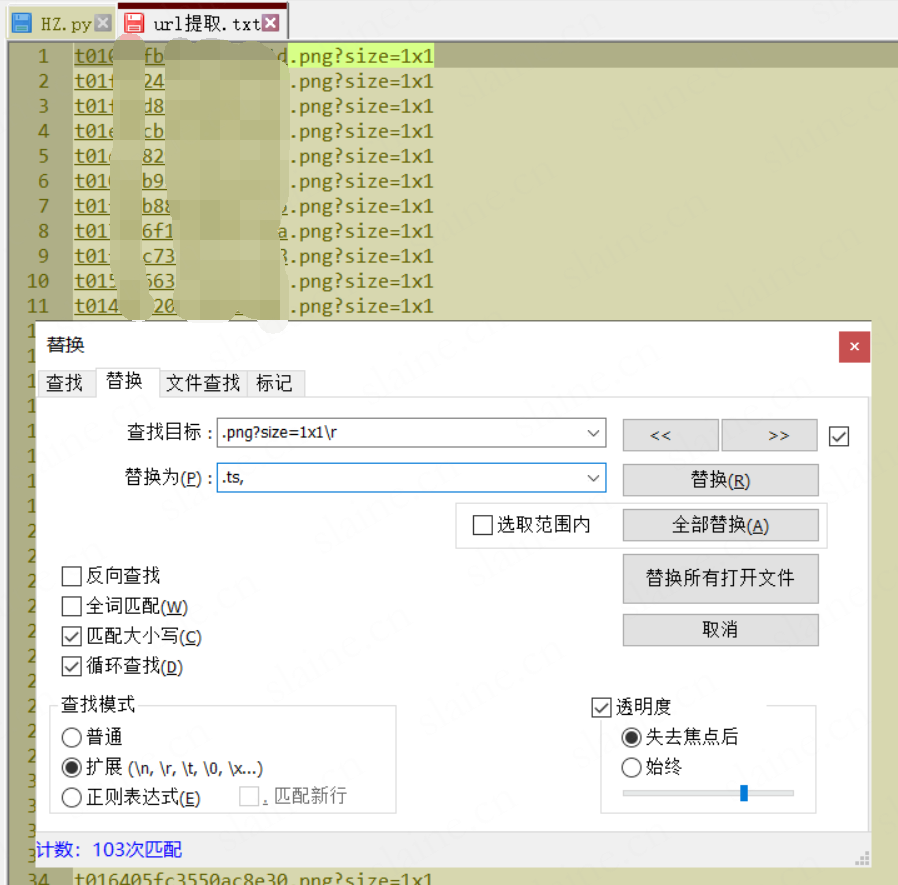
全部替换为.ts结尾且 , 间隔,整理为一行的队列形式

前提需要都准备好了,现在开始批量按照顺序改文件名
程序代码如下
import os
with open("01.txt","r",encoding="utf-8") as f:
list =f.readline().split(",")
list
print("01.txt内文件名数量:",len(list))
filelist=os.listdir(os.getcwd()+"/test")
print("test文件夹内文件数量:",len(filelist))
a=1
for i in list:
old_name=os.getcwd()+"\\test\\"+i
print("修改旧文件:",old_name)
if len(str(a))==1:
temp="000"+str(a)
elif len(str(a))==2:
temp="00"+str(a)
elif len(str(a))==3:
temp="0"+str(a)
else:
temp=str(a)
#print(temp)
new_name=os.getcwd()+"\\test\\"+temp+".ts"
print('新文件:',new_name)
a+=1
os.rename(old_name, new_name) # 用os模块中的rename方法对文件改名
正常运行完成
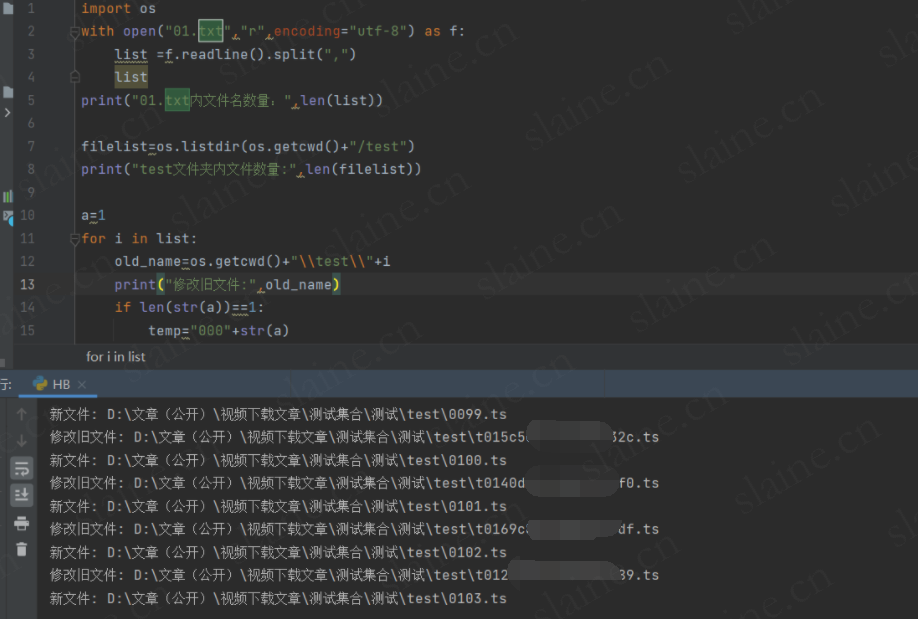
所有视频文件按照指定顺序排列完成
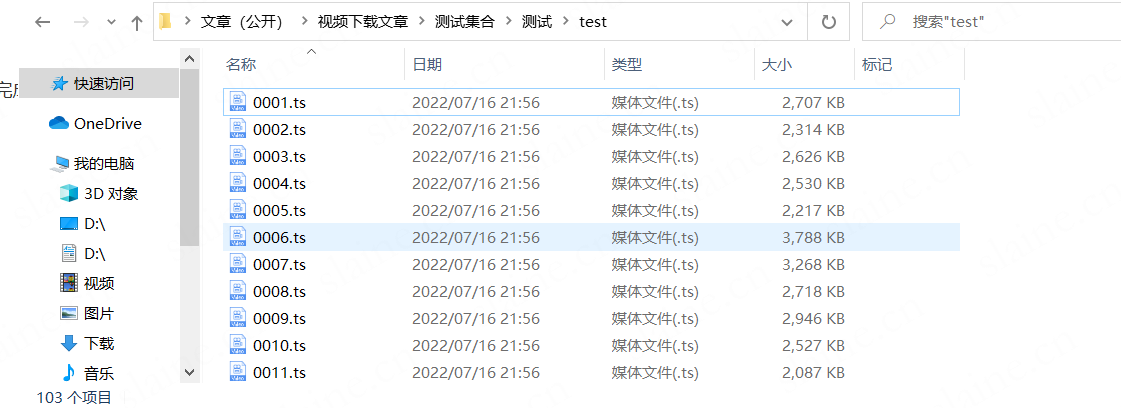
文件合并
然后用ffmpeg或者moviepy包或者其他工具合并就行
注意:前提必须是按照m3u8里下载链接的顺序改文件名(上操作)后才能正常合并出成品视频,否则会导致视频片段混乱(作者亲测)
这里网上随便一搜就找到了
小东西真不错
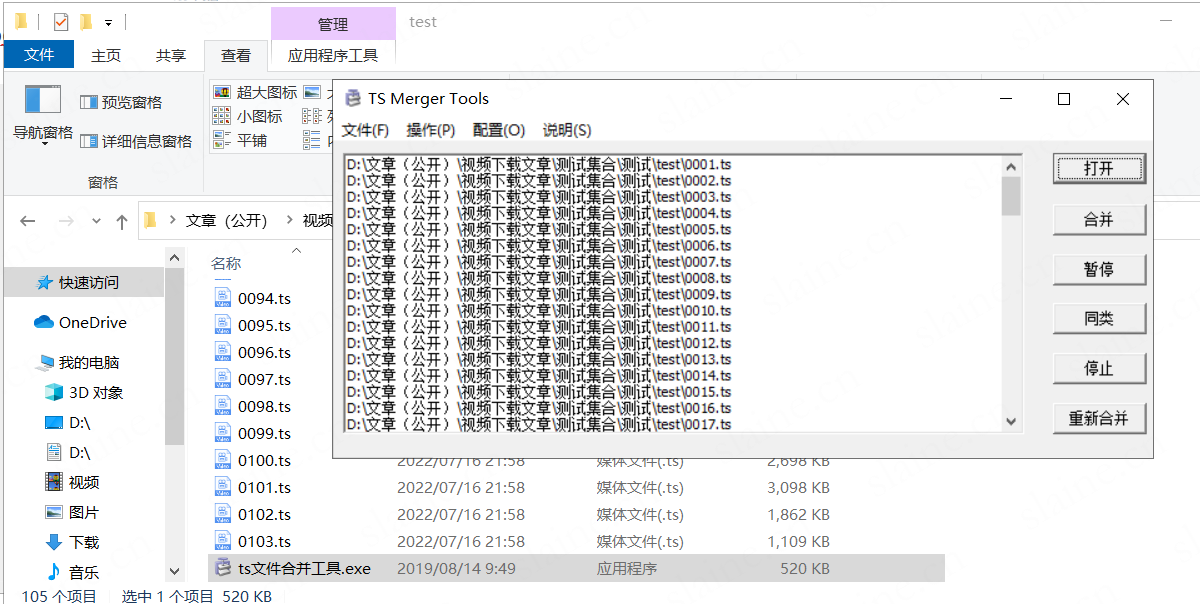
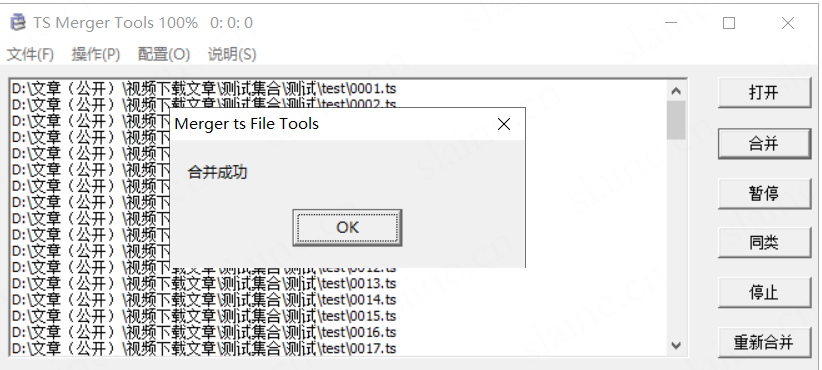
完成
然后就得到成品的文件了
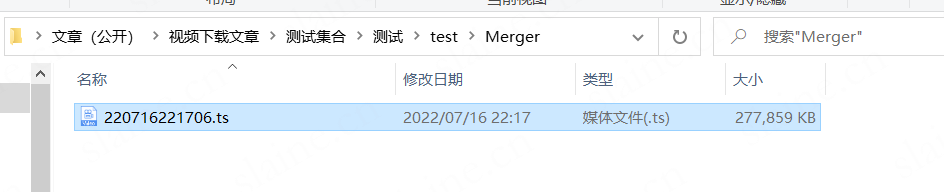
打开看看

内容清晰,完整流畅,达到目的
OVER
老工具人了