
一、MySQL服务的安装
1.
安装mysql服务器的时候,我们将用户身份切换为root,安装好之后普通用户也是可以通过MySQL命令行式的客户端来访问mysqld服务,初期学习MySQL的时候建议直接使用root的身份来进行学习,快速上手基本的sql语句编写之后,我们在后期学习用户管理时,可以自己手动新建普通用户,给普通用户赋予一定的数据库管理权限。
2.
安装MySQL需要分为两个步骤,首先需要卸载干净掉云服务器上可能预先内置的MySQL服务,我们需要将原有的环境先卸载干净,然后在服务器上重新安装布置MySQL服务。
(1)云服务器上可能内置了mariadb(MySQL的一个开源分支)或MySQL,所以先查看一下是否有这些服务,如果有则将这些服务停止掉。查看是否存在服务的指令: ps axj | grep mariadb 停止服务的指令:systemctl stop mariadb.service 停止掉服务之后,我们可以继续ps axj | grep mariadb 或 ps axj | grep mysql 查看系统中是否有这些存储服务,如果没有,说明我们停止成功。
(2)如果你曾经安装过mysql或mariadb服务,则系统中一定会留有yum源安装时,从远端拉取到本地的安装包,这些安装包的后缀都是rpm,查看所有的yum残留安装包的指令:rpm -qa,查看mariadb或mysql残留安装包的指令:rpm -qa | grep mysql 和 rpm -qa | grep mariadb,卸载时如果一个一个卸载可能有些麻烦,所以我们可以通过rpm查询后的结果通过管道传输,然后将管道传输的内容传递给xargs指令,xargs再将这些文件名传递给yum remove指令,让yum remove统一卸载这些残留的安装包,卸载的指令为:rpm -qa | grep mysql | xargs yum -y remove,卸载成功后,我们可以再次调用rpm -qa | grep mysql查看是否还有剩余的安装包,如果没有,则说明我们已经卸载残留的安装包成功了。
(3)当系统中已经停止掉了mysqld服务,并且卸载了所有的剩余安装包,则说明原有环境已经干净了。为了检验原有环境是否完全干净,我们还可以ls /etc/my.cnf查看是否存在my.cnf这个文件,如果该文件不存在,则环境已经干净了。ls /var/lib/mysql中的内容是上一个mysql数据库中所残留的数据,MySQL服务在卸载的时候,默认不会将数据删除掉,这些数据我们可以不用管,他们并不影响我们后续MySQL服务的安装和使用。
3.
(4)接下来我们就可以正式的在我们linux机器上部署MySQL服务了,首先我们需要去官方下载官方的mysql yum源mysql yum源地址,打开地址后会有很多版本的mysql yum源,确保我们下载正确的mysql版本之前,我们需要查看一下自己linux机器的版本,cat /etc/redhat-release,点开网页之后其实是找不到centos 7.6版本的yum源的,我们需要右键查看页面源代码,显示出完整信息之后,就找el7的,el代表centos,至于MySQL服务的版本不需要选择太新的,选择MySQL5.7版本的即可,147行的yum源就正好符合我的linux机器版本以及我所需要的mysql服务版本。
下载之后我们可以将该文件ctrl+x剪切到桌面上(方便查找),然后在xshell下可以通过sudo rz命令将桌面上的yum源文件上传到linux机器上,注意xshell不支持从桌面拖拉文件到xshell界面的方式来上传文件,必须通过rz指令来上传文件到linux机器上。
上传之后我们就会得到一个以.rpm为后缀的yum源文件,然后我们需要将该yum源安装到linux机器上的yum源清单中,通过rpm -ivh mysql57-community-release-el7.rpm,安装之后,ls /etc/yum.repos.d/ -al可以查看到系统的yum源清单,更新yum源之后,我们可以通过yum list | grep mysql查看系统中相关的mysql的资源。更新yum源之后,我们就可以将上传到linux上的mysql yum文件删除掉了,这个.rpm文件现在就没什么用了。
(5)现在我们就可以使用yum命令一键安装mysql服务了,使用sudo yum install -y mysql-community-server,此时yum就会按照自己的yum源自动的帮我们一键安装MySQL服务,安装过程中可能会遇到密钥过期的问题,我们可以从网络中拿取新的密钥进行更新linux机器的密钥,rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022执行该指令即可更新Linux机器的密钥,更新之后重新yum安装MySQL服务即可。
安装成功之后,ls /etc/my.cnf可以看到my.cnf文件,并且netstat -nltp还可以看到守护进程mysqld,启动或者停止这样的守护进程mysqld,我们可以通过systemctl stop mysqld,systemctl start mysqld,systemctl restart mysqld(重启守护进程)。


上传好的yum源文件,以.rpm为文件后缀
将yum源安装到linux机器上的yum源清单中
安装MySQL服务之后,可以看到一个守护进程mysqld,该进程即为MySQL的服务进程,为我们提供MySQL数据存储服务。

在bin和sbin目录下分别存在两个可执行文件,一个是mysql,代表登录mysqld服务的客户端,一个是mysqld,代表提供网络数据存储服务的服务端。

3.
(6)安装好MySQL的整个服务之后,我们就可以通过命令行式的客户端来使用和登录mysqld服务了,mysql -uroot -p即可登录MySQL服务,但在登录时由于我们没有密码,所以还需要将my.cnf配置文件的内容更改一下,在文件末尾加入一行skip-grant-tables,即跳过鉴权,这样在登录的时候,我们就不需要输入密码,直接连续点两下回车即可登录MySQL服务了,登录MySQL服务之后,show databases;即可看到当前数据库中已有的database。(注意修改my.cnf配置文件后,需要让配置的内容生效,但此时mysqld服务进程早就已经启动了,所以我们需要让mysqld守护进程重新启动一下,这样才能使跳过鉴权的操作生效)

4.
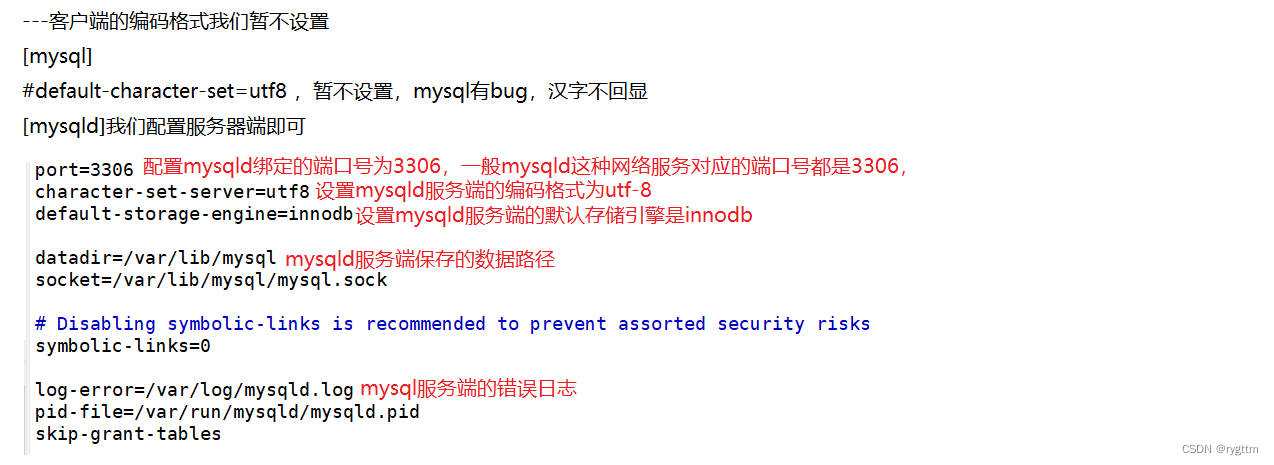
至此为止,我们就搞定了MySQL的登录问题,但还差一件事就是配置my.cnf文件,主要配置的是MySQL客户端和服务端的编码格式,我们统一使用utf8的编码格式,保证客户端和服务端使用的编码是一致的。
mysql客户端的编码格式我们先不设置,只设置mysqld服务端的即可,配置之后还是老样子,重启mysqld服务,让我们的配置生效即可。
(systemctl enable mysqld 和 systemctl daemon-reload可以设置mysqld服务为开机自启动,不过因为我们使用的是云服务器,云服务器不会关机,所以这个指令设置不设置都没什么区别,如果你用的是虚拟机,则可以设置。)
二、数据库基础
1.什么是数据库?(基于CS模式的一套数据存取的网络服务)
1.
使用命令行来登录MySQL,mysql -h127.0.0.1 -P3306 -uroot -p来进行登录,但今天我们的客户端和服务端都是在同一台linux机器上,上面的-h和-P选项可以不带,因为mysql客户端默认连接的就是本地的MySQL服务,另外my.cnf配置文件中已经有了mysqld服务的端口号3306,所以我们的客户端在连接MySQL服务时,是可以找到本地主机上的mysqld网络服务的。
所以实际在登录mysql服务时,只需要指明-u用户是谁,以及-p密码是什么即可,由于我们在my.cnf中加了skip-grant-tables,所以-p也不需要我们输密码,直接回车就可以登录。
2.
MySQL是一种基于CS(client and server)模式的网络数据存储服务,提供了客户端mysql,以及服务端mysqld,客户端可以通过网络连接到服务器上,并向服务器发送SQL语句请求,服务器负责执行SQL语句,并将执行结果返回到客户端上。
服务器是数据库的管理者,负责存储,管理,维护数据库中的数据,同时MySQL支持多种客户端的连接方式,除了我们现在所使用的命令行式的客户端连接方式外,还支持图形化界面workbench,以及语言级别的API来连接mysql_init() + mysql_real_connect(),所以mysqld可以允许多个客户端同时连接到一个数据库服务器上,实现多个客户端之间的协同操作以及数据共享。
而我们口语上所说的数据库,大多数是指在内存中或磁盘中存储的特定结构组织的数据,表和表之间互相关联而成的数据存储结构,但实际上数据库是一套在内存上运行的网络服务,用于实现数据存取。
3.
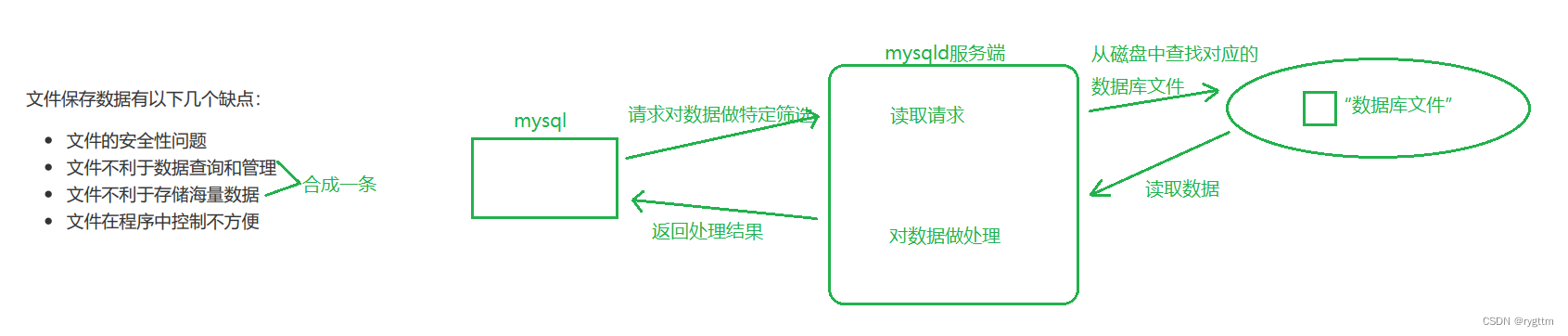
存储数据用文件就可以了,为什么还要搞个数据库呢?
(1)文件不利于数据的查询和管理,同时文件不利于存储海量数据,其实这两点说的是同一点。
因为普通的文件存储方式只适合于小规模的数据存储,例如存储文本文件,图像、视频等文件,一旦存储海量数据,文件不会对数据进行管理和组织,如果我们要查询海量数据中的某些数据时,则需要自己手动编写文件IO的代码,这太低效了,每次查询都需要重新编写文件IO的代码,同时文件存储方式也没有提供数据索引和查询功能,一旦查询,则需要在海量数据中一个一个遍历的查询,效率太低。
(2)文件非常不安全,因为文件没有加密和权限控制等方式,反观数据库通过权限,认证,加密等方式来保证数据的安全性。
(3)文件在程序控制中非常的不方便,想必这个缺点大家都感同身受吧,文件操作简直太恶心了,要处理读取内容末尾的\n,并且读取上来的内容也都是一大块放到缓冲区里的数据,同样没有对数据进行组织和管理。
所以数据库对我们来说相当于一个中间件,以往我们对数据进行存取,可能只能通过文件读写的方式来进行,但现在有了数据库之后,我们可以将自己的需求通过mysql客户端交给mysqld服务器,mysqld会和磁盘打交道,进行我们的sql语句的执行,从磁盘中拿取对应的数据或其他处理结果,将这个处理结果返回到mysql客户端,这样就完成了程序员对数据的存取需求。
程序员直接操纵mysql客户端即可完成对磁盘上数据处理的工作,不用在繁琐的进行文件IO,你给mysqld请求,mysqld给你返回结果。
2. Linux文件系统和数据库的关系 && 主流数据库
1.
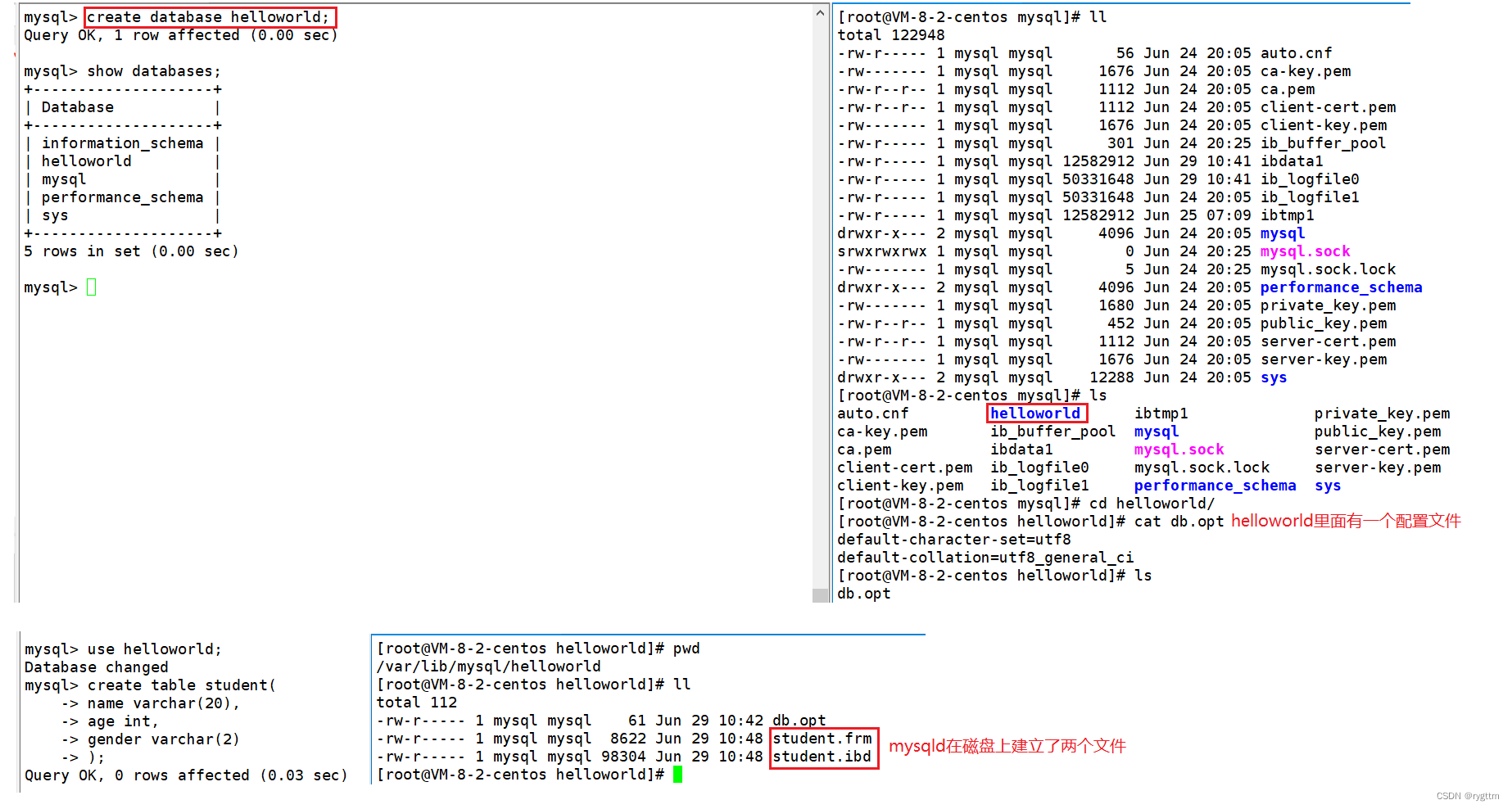
实际上所谓的在MySQL中建立database,实际就是在对应linux文件系统中的/var/lib/mysql路径下创建一个目录,所谓的在database中建立一个或多个table,实际就是在linux的mysql路径下的目录中创建对应的文件。这些工作都是由谁做的呢?实际就是由mysqld服务器做的,服务器会在linux机器的磁盘上创建出对应的目录和文件。
所以数据库的本质就是文件,每个database都会对应linux磁盘上的一个文件,只不过这些文件不应该由程序员直接手动操控,而是应该由数据库mysqld服务器来进行操控,让mysqld来进行磁盘上数据的存取。
2.
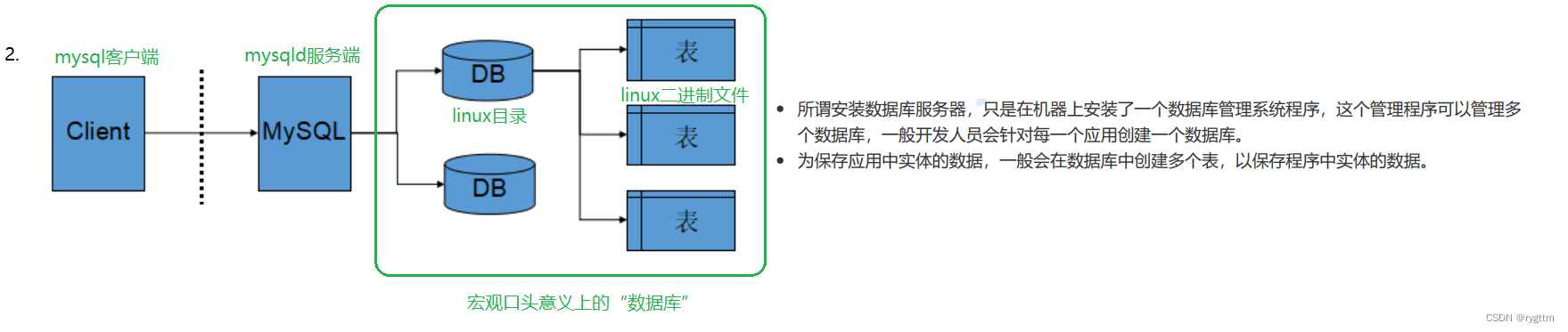
下面这张图刻画了MySQL服务和Linux文件系统的关系,对于普通的数据我们可以直接操纵文件系统来处理磁盘上的数据,而对于需要管理和组织的数据,我们则通过数据库管理系统即CS模式下来进行数据的存取。
一般开发人员会对每个特定业务都分配一个database,在每个database内部会创建多个相互级联和组织到一起的表结构,用于存储该业务所需要的数据。
3.
SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电
商,SNS,论坛。对简单的SQL处理效果好。
PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研
究使用,可以免费使用,修改和分发。
SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库
中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的
低,在嵌入式设备中,可能只需要几百K的内存就够了。
H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中
上面的数据库管理系统中,国内用的最多的还是MySQL,银行金融业用oracle比较多,MySQL的生态很完整,经过时间的考量,已经暴露出很多的bug,并且有相关活跃的社区修改这些bug,数据库也比较稳定。
3.MySQL架构 && SQL分类 && MySQL存储引擎
1.
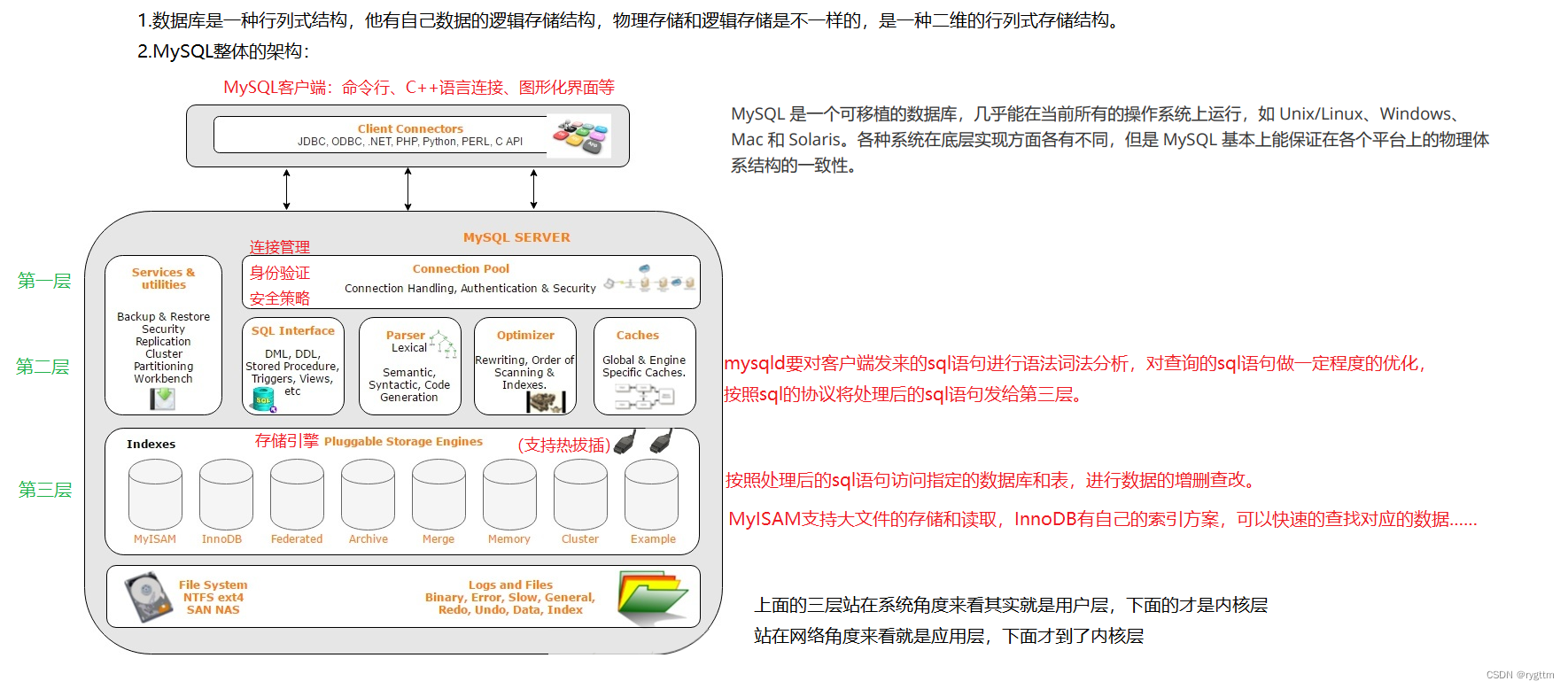
除MySQL客户端外,MySQL服务器整体的架构分为三层。
第一层是连接管理,也就是connection pool连接池,这一层会进行连接处理connection handle,身份认证authentication,安全策略security,这一层也是和MySQL客户端打交道最近的一层,对MySQL客户端发起的连接做处理。
第二层是SQL语句的接口SQL interface,sql语句的解析器parser,以及sql语句的优化optimizer,因为MySQL的sql语句的标准格式是全大写的,而我们敲的sql语句一般是小写的,所以mysqld服务在收到sql语句之后,还要对sql语句做一定的优化optimizer,除此之外mysqld也有自己的caches缓存策略,比如某一个database使用innodb存储引擎时,该缓存层会开辟一大块的buffer pool用于数据的缓存,该缓存层可以很好的解决由于多次IO导致的程序性能降低问题,他可以根据局部性原理,在加载数据时,同时加载一批相关的数据,除了缓存数据之外,caches还会进行sql语句查询的缓存,以及表信息的缓存等,是很重要的一层。
第三层是支持热拔插的存储引擎,值得注意的是,这里的热拔插并不是指物理上的某些插头进行拔插,而是指软件层面上的支持动态添加,删除和替换存储引擎的能力,可以在数据库运行时,动态的添加或删除存储引擎,而无需停止数据库服务或重启服务器,实现数据的平滑迁移。
例如我们的某个database现在使用的是MyISAM存储引擎,可以支持大量的非事务性,大文件数据的存储和读取,如果我们想让该database的数据保证完整性和一致性,则需要使用innodb存储引擎,它可以支持ACID(Atomicity、Consistency、Isolation、Durability)的事务以及快速查找时需要的B+索引结构。
而这三层站在操作系统的角度来看依旧是应用层,应用层下面才会到内核层,也就是接近linux内核的文件系统,进程管理,驱动管理,内存管理等等。如果站在网络角度来看的话,那也是应用层,在下面才会到传输层。
2.
MySQL的sql语句大体分为三类,分别是DDL(data definition language)数据定义语言,DML(data manipulation language)数据操纵语言,DCL(data control language)数据控制语言,在DML中又单独分了一个DQL(data query language)数据查询语言。
DDL:用来维护存储数据的结构,例如表table结构,数据库database结构,常用的sql语句有create drop alter
DML:用来对结构中的数据内容进行操纵,常用的sql语句有insert delete update等,其中单独分出来的select语句就属于DQL。
DCL:主要负责权限和事务的管理,不负责处理库或表结构数据,也不负责处理库或表中存储内容的数据,主要进行一些连接用户的权限或事物的回滚提交等操作,常用的sql语句有grant、revoke、create user、commit,rollback等。
3.
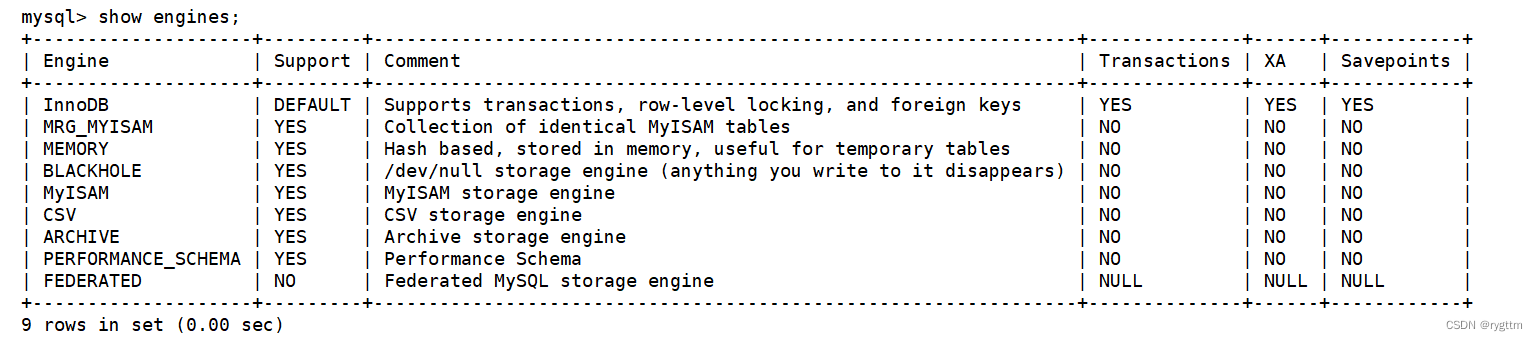
存储引擎是MySQL数据存取服务的最重要的组成部分,是mysqld进行数据存储,为存储的数据建立索引,对数据进行CURD(create update read delete)等技术的具体实现方法,mysqld数据存储服务的核心实现就是依靠热插拔的存储引擎来实现的。
通过show engines就可以看到我们当前的MySQL服务使用的默认的存储引擎就是我们当时在my.cnf中配置好的InnoDB存储引擎,除InnoDB外,另一个常用的存储引擎就是MyISAM,我们主要学习和使用的是InnoDB存储引擎,因为他支持事物transaction,行级锁定row-level locking,可以支持高并发读写的场景,而MyISAM不支持事务和行级锁定,只支持表级锁定,也就是如果有客户端对表做CUD操作,则必须串行化执行,无法进行并发式的执行,这会降低效率。所以如果有大量读写并发的场景,则建议使用InnoDB存储引擎,该存储引擎支持行级锁定,只锁定表中的某一行数据,其他未锁定的行依旧可以进行高并发的CURD操作,效率会变得比较高,但同时会增加数据库系统的开销和负责度。
4.
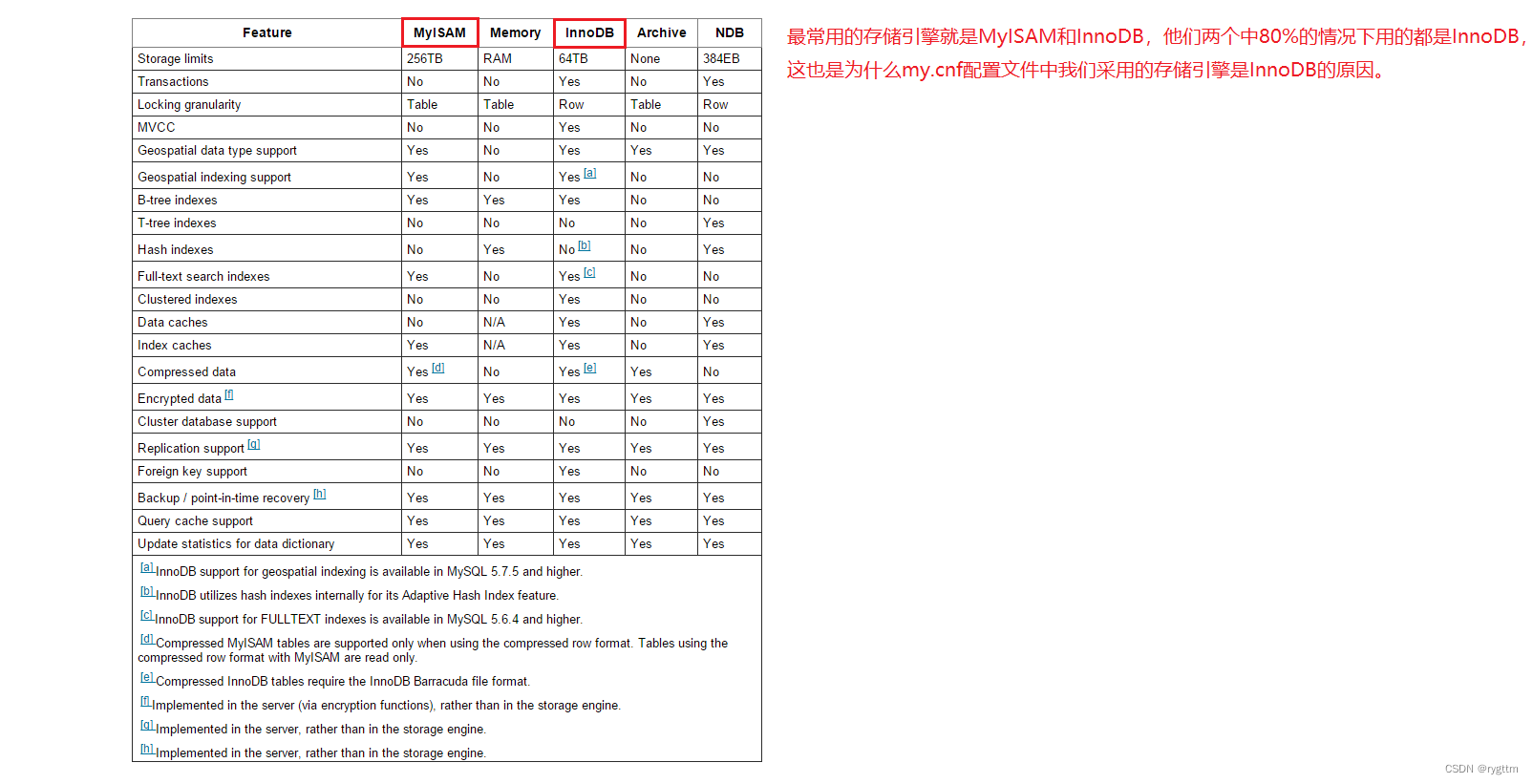
下面是各个存储引擎的功能feature,包括存储空间限制storage limits,事务transaction,锁定的粒度大小locking granularity,多版本并发控制MVCC,B+树索引B-tree indexes,T+树索引T-tree indexes,哈希索引hash indexes,数据缓存data caches,索引缓存index caches,数据复制技术replication support,外键foreign key support,查询缓存query cache support等。
三、MySQL操作库
1.库结构的CURD操作
查看MySQL中所有的数据库:show databases;

创建数据库的指令和显示创建数据库时的指令

!40100 default… / 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话,其实就是设定数据库的编码集为utf8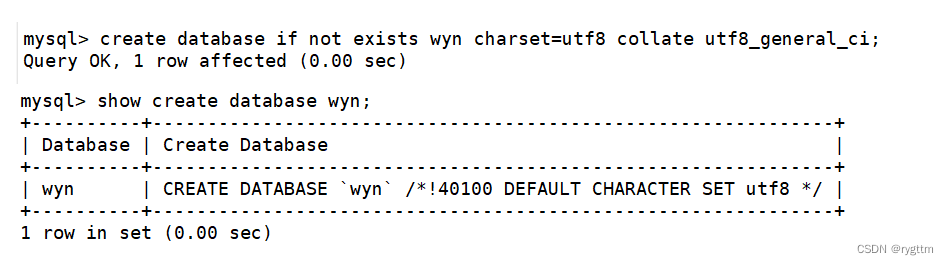
删除数据库的指令。记住绝对不要以手动直接删除linux文件系统中目录的方式来删除数据库,打死都不要这么干,因为mysqld负责管理这些特殊的文件,程序员不应该干涉mysqld的工作,而应该通过mysql客户端发送sql语句的方式来对linux磁盘上的文件进行CURD。
注意:删除数据库这样的指令非常的危险,不要轻易的删除,因为删除数据库后是无法恢复出来的,除非你提前做了数据库的备份,这条sql语句就和rm -rf ./*这样的指令一样,非常的危险!请谨慎执行!
1.
上面的sql语句说完之后,我们需要来谈一个重要的话题,就是编码集charset和校验集collate,在创建数据库的时候指定这两个字段的值。
编码集指的是数据库存储数据时所使用的编码规则,校验集指的是数据库在查找数据进行数据比对的时候,所使用的比对规则。database必须保证编码集和校验集所使用的编码格式是统一的。
2.
MySQL5.7默认的编码集和校验集分别是utf8和utf8_general_ci,在MySQL 8.0及以上版本中,utf8_general_ci被替换为utf8mb4_general_ci作为默认的校验规则,这样可以支持更为广泛的字符集和表情符号。

数据库支持的字符集和校验集,但默认都是utf8
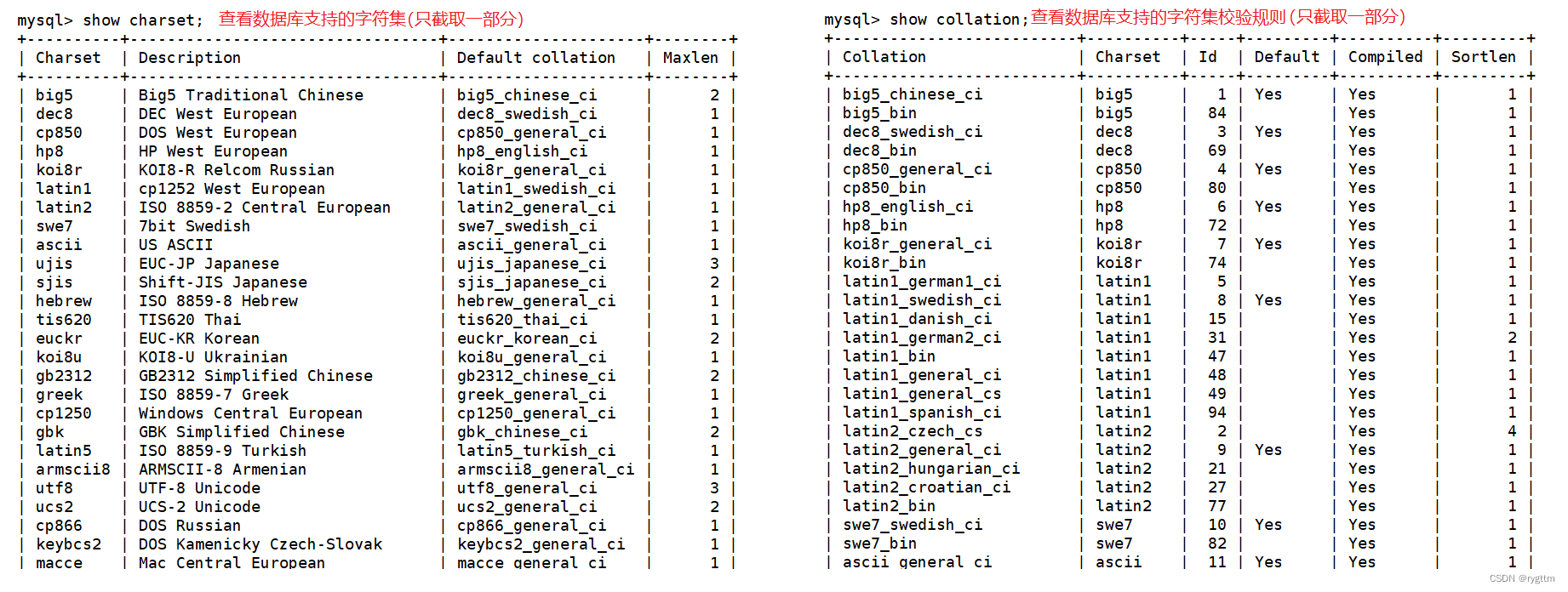
配置文件中数据库的编码默认就是utf8
3.
除了使用默认的编码和校验规则之外,我们也可以在创建数据库的时候,指定编码和校验规则,例如下面创建数据库的时候,使用到了gbk的校验规则。
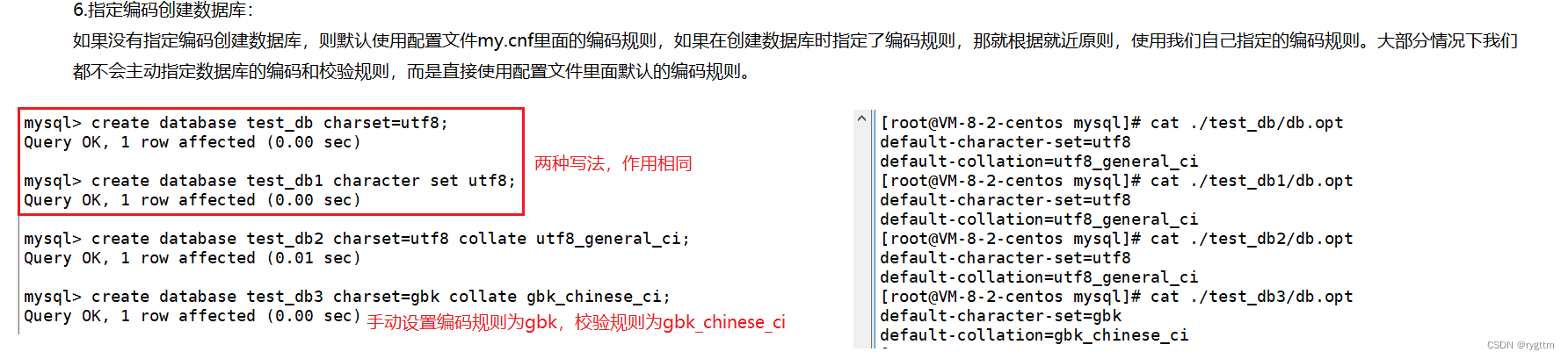
4.
下面对比了utf8_general_ci和utf8_bin校验规则不同时,数据库查询时所造成的查询结果的不同,其实就是区不区分大小写,默认数据库是不区分大小写的,也就是utf8_general_ci校验规则
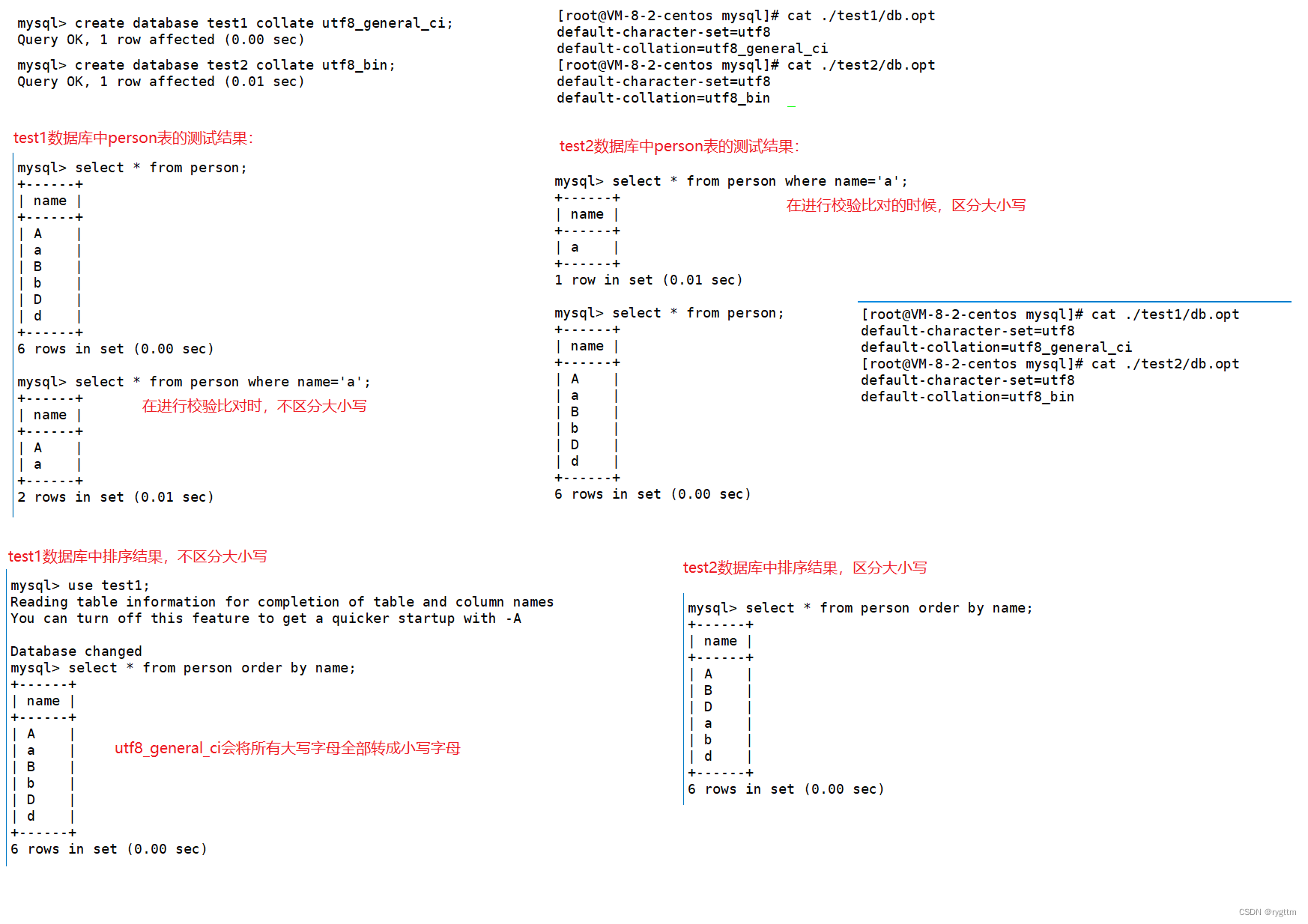
5.
使用数据库:use database_name,确认当前自己在哪个数据库里面:select database(),修改数据库的编码或校验规则:alter database database_name charset=xxx或collate xxx
注意:大部分情况下我们都不会去修改数据库的编码或校验规则,只使用my.cnf配置文件中的编码规则即可。
2.库的备份与恢复 && 数据库的连接情况
1.
数据库的重命名MySQL是不支持的,并且这是非常合理的,因为数据库的名字是量级很重的,一旦数据库的名字发生改变,则上层所有使用数据库的代码都需要做出调整,代价特别大,所以一般在项目前期讨论协商的时候,一定要确定好数据库的命名等工作,等到项目开始开发的时候,就不要更改这些量级比较重的地方了。
除非万不得已,必须要对数据库重新命名的时候,一般会采用备份与恢复的方式来进行重命名,备份的指令:mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径,备份成功后,在指定的路径下面就会存在.sql文件,打开.sql文件其实就可以看到其中备份的内容,其实就是sql语句和相对应的数据。恢复数据库的指令:source 文件路径+文件名,恢复数据库实际就是将当初创建数据库时所执行的sql语句全部重新执行一遍,这样就恢复好数据库了。
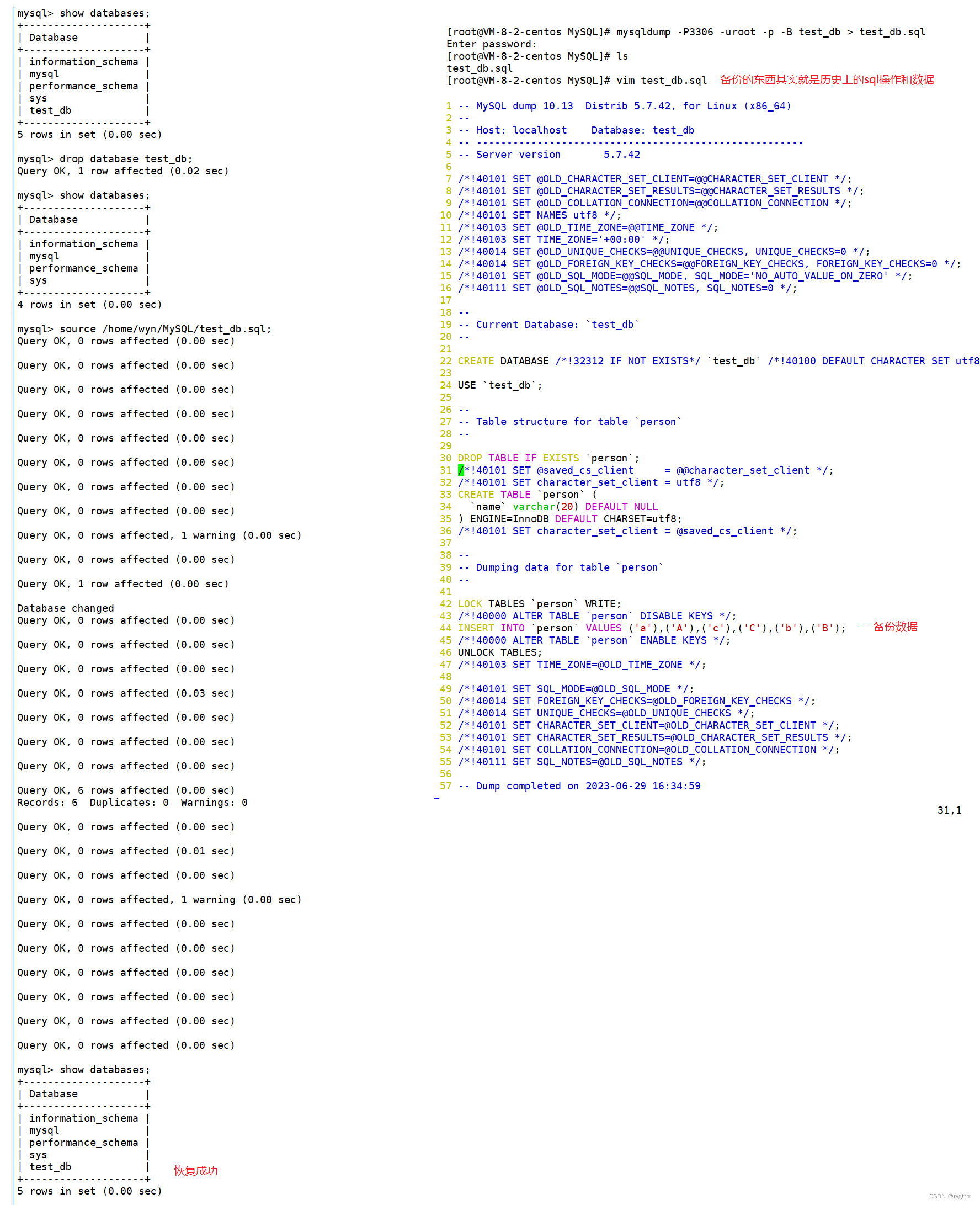
2.
如果备份的不是整个数据库的所有内容,而是一张表,则可以通过指令:mysqldump -u root -p 数据库名 表名1 表名2 > 路径/mytest.sql,也可以备份多个数据库 mysqldump -u root -p -B 数据库名1 数据库名2 … > 数据库存放路径。
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据
库,再使用source来还原。所以如果你想对数据库重命名的话,则可以在备份数据库的时候,不带上-B参数,备份成功后,删除现有的数据库,然后在恢复数据库的时候,先自己创建一个数据库(指定自己想要的数据库名称),然后在执行source sql语句进行数据库内容的恢复。
3.查看数据库的连接情况
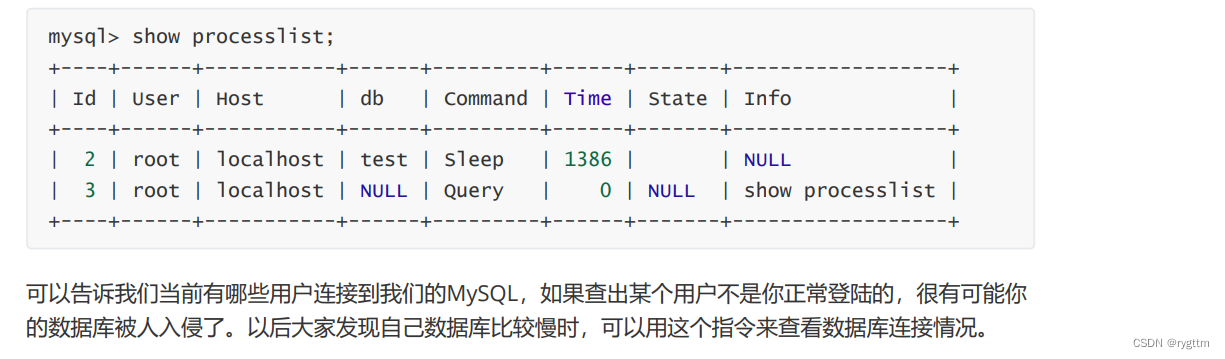
四、MySQL操作表
1.表结构的CURD操作
1.
创建表的时候,()内的内容为列名和列的属性,()后面的内容为表的属性字段,例如编码集,校验集,存储引擎等,myisam将数据和索引分开存储,innodb将数据和索引一块存储。等到后面我们会学到,MyISAM的主键索引和非主键索引都是非聚簇索引,而InnoDB的主键索引是聚簇索引,非主键索引是非聚簇索引。后面在学习到聚簇和非聚簇时,我们会详谈。

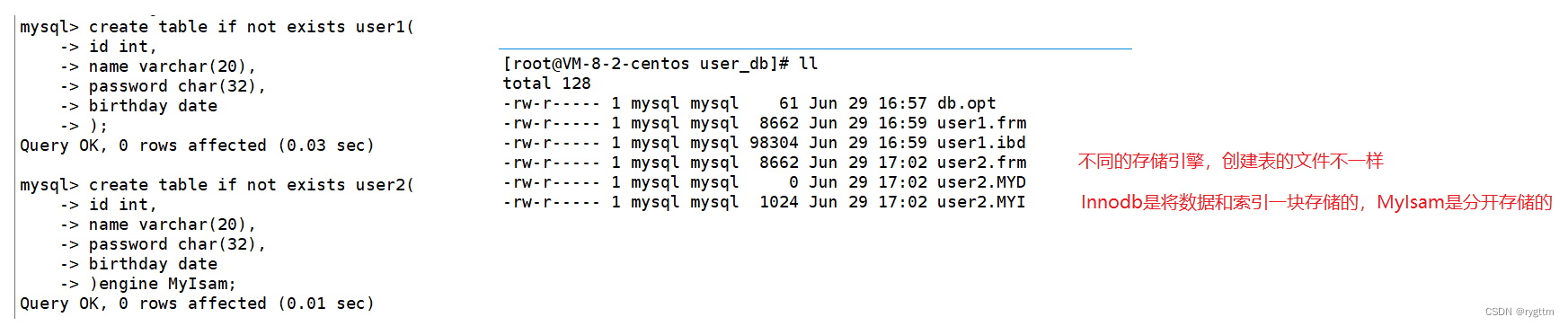
2.
查看表就是下面这三条sql语句,分号;和\G都可以作为sql语句的结束,只不过显示的方式不同,前者是以行为分隔符进行显示,后者是以二维形式的表结构来进行显示。

3.
修改表名:alter table old_table_name rename to new_table_name,to可以省略,直接rename
向表中新增一列:alter table table_name add 列名 列属性 after 表中的某一列名,如果不带after的话,则新增的一列默认是在表的尾部。
修改表中某一列的属性:alter table table_name modify 列名 新属性
删除表中的某一列:alter table table_name drop 列名
修改表中某一列的名字:alter table table_name change 新列名 新属性


4.删除表:drop table 表名
值得注意的是,删除表,删除库,修改库名,修改表名这样的操作都很危险,如果在项目开发一半的时候产品经理告知要修改表名或者库名,那就很有可能在上层出现逻辑问题或编译问题,这对程序员是一种莫大的伤害,所以在前期讨论项目构建的时候,一定要确定好库结构,表结构,库名,表名,等到项目开始开发的时候,这些就不要改动了。
2.对库结构和表结构操作的SQL语句的小总结(DDL语句)
1.
总结一下,如果我们要对表结构做修改,使用的关键字是alter,改表名字是rename,增加列是add,修改列属性是modify,修改列名是change,删除某一列是drop。
对库或表结构做查看的时候,一般会用到show和show create两个sql语句,对表结构信息查看还多了一个desc语句。
删除库或表,统一使用的是drop语句
2.
我们上面所学的都是DDL语句,即数据定义语言,不是DML,更不是DCL语句,在学习完数据类型之后,我们紧接着学习的就是DML语句,对表中存储数据的增删查改语句。
五、MySQL数据类型
1.数值类型
1.1 整数类型
1.
下面是MySQL中的整数类型,常用的数据类型是int,在MySQL里面定义列的时候,是列名在前,列属性在后,如果数据类型后面什么都没有带,则默认是有符号的,只有显示带了unsigned,则才是有符号的。

2.
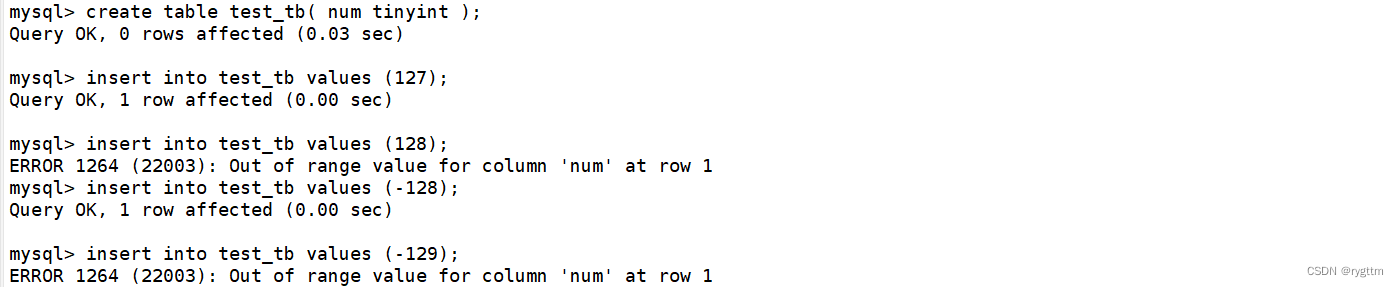
在C/C++语言中,如果我们将一个整数初始化一个char类型的变量,则默认进行隐式类型转换,发生截断,然后进行存储,但在MySQL里面并不会这样,例如下面我创建了tinyint类型的num列,当我插入的数据是合法的时候,则可以顺利的插入到表中,而如果插入的数据不合法时,MySQL会直接拦截我们,不让我们做对应数据的插入,反过来,如果有数据插入到MySQL中,则已经插入的数据一定都是合法的数据。
所以在MySQL中,数据类型本身也是一种约束,约束使用者进行合法数据的插入,通过这样的约束就可以保证数据库里面数据的可预期性和完整性。
3.
实际在建表,给某一列字段分配具体数据类型的时候,一定要结合具体使用场景来分配,如果你分配的不够合理,则很可能会出现空间浪费的情况,比如某一列只需要1字节即可完成数据的存储,但你却用了bigint属性,那存储一条数据就会浪费7字节的空间,而数据库存储的数据又是海量的数据,最后浪费的空间则会非常巨大,平白无故给系统带来很大的消耗。
所以在实际分配数据类型时,一定要合理的结合具体使用场景来分配。
4.
还有一个常用的数值类型就是bit,我们可以用一个比特位来充当某些列字段的类型,bit位的个数最多是64位,如果在列名后面加bit不带括号指定位数的话,则默认是1bit,从右边插入数据的过程可以看到,当只有一个比特位的时候,插入的数据只能是0或1,其他数据均无法正常插入,被MySQL拦截。
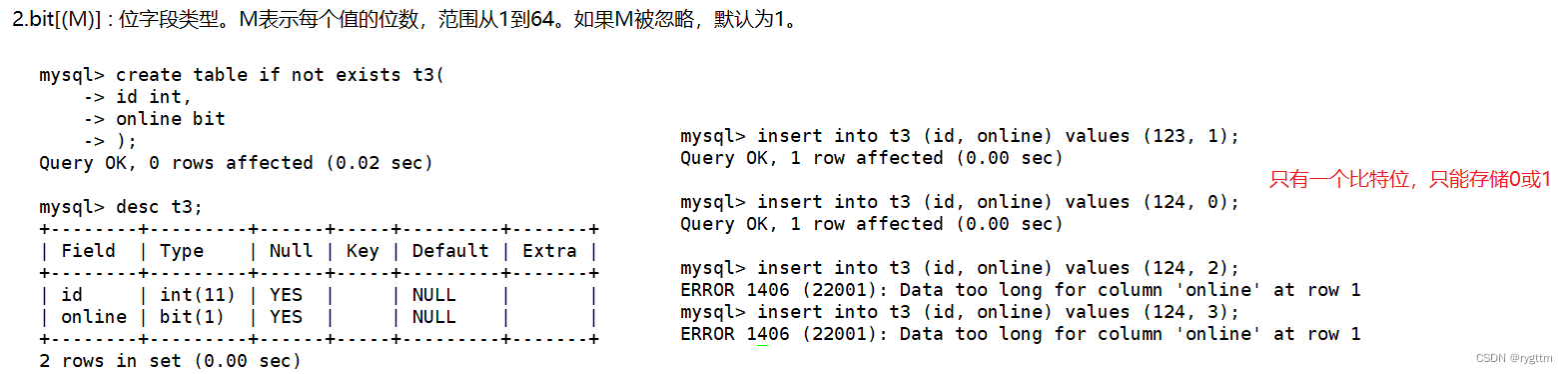
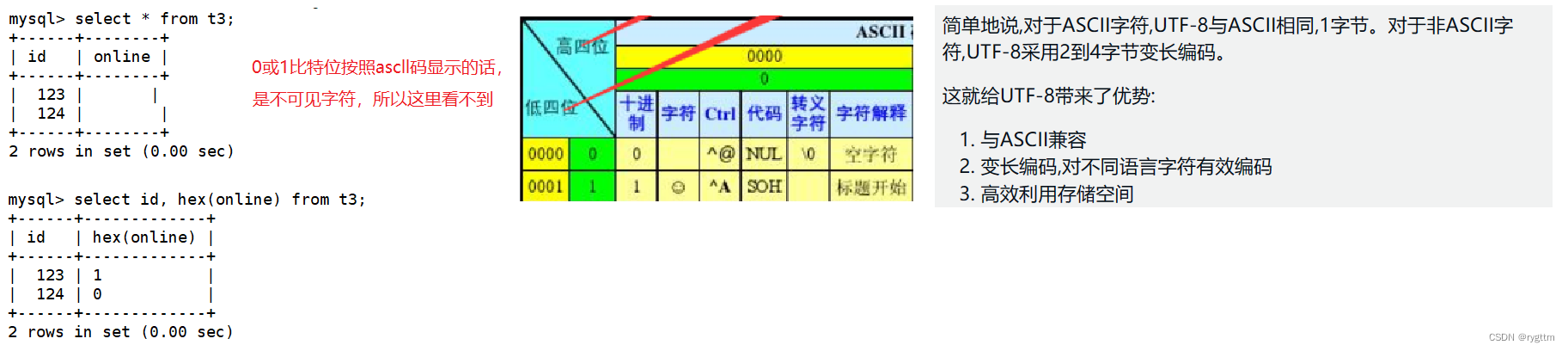
在显示表中内容的时候,我们可能看不到类型为bit的列字段的值,其实主要是因为当存储的数据大小小于1字节时,utf8编码和ascll编码是相同的,而0和1在ascll编码中属于不可见字符,所以在显示表t3内容的时候,我们看不到online的字段值。如果想要显示,则可以通过函数hex()来进行显示,该函数可以将online字段改为16进制显示,这样就可以看到online的值了。
1.2 小数类型
1.
float double decimal的使用方式均相同,float[(m, d)] [unsigned] : M指定显示长度,d指定小数位数,占用空间4个字节,decimal(m, d) [unsigned] : 定点数m指定长度,d表示小数点的位数,括号中都是两位,前者表示整体的小数长度,后者是小数点后面的位数。

2.
当类型为float(4,2)的时候,可以看到下面的数值越界测试,MySQL是允许小数部分进行四舍五入的进行插入的,但必须要满足四舍五入之后总体的长度位数不能超过4,下面插入的数据有正有负,允许插入的数据范围为-99.99到99.99,如果你插入的小数位数大于2,则先进行四舍五入,在四舍五入之后的数值如果还在数据范围内,则允许插入。

当数值类型加上unsigned修饰的时候,负数不允许插入,可插入的数值范围减半。

2.
float的精度大约是7位,如果插入的数据大于7位的话,则实际保存在数据库中的数据位数可能会不准。

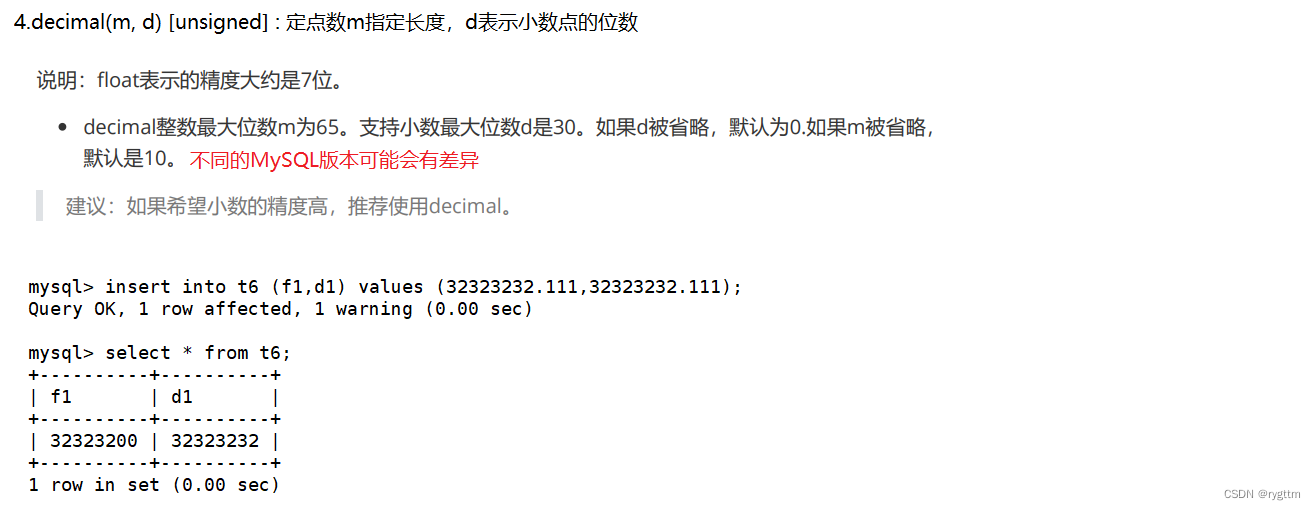
3.
如果你想让存储的数据的精度更高的话,则可以使用decimal数值类型,可以看到,当相同数值向不同类型的列字段f1和d1进行插入的时候,decimal存储的精度显然更高一些。(不同的MySQL版本,decimal的精度可能会有差异)
2.字符串类型
2.1 char和varchar
1.
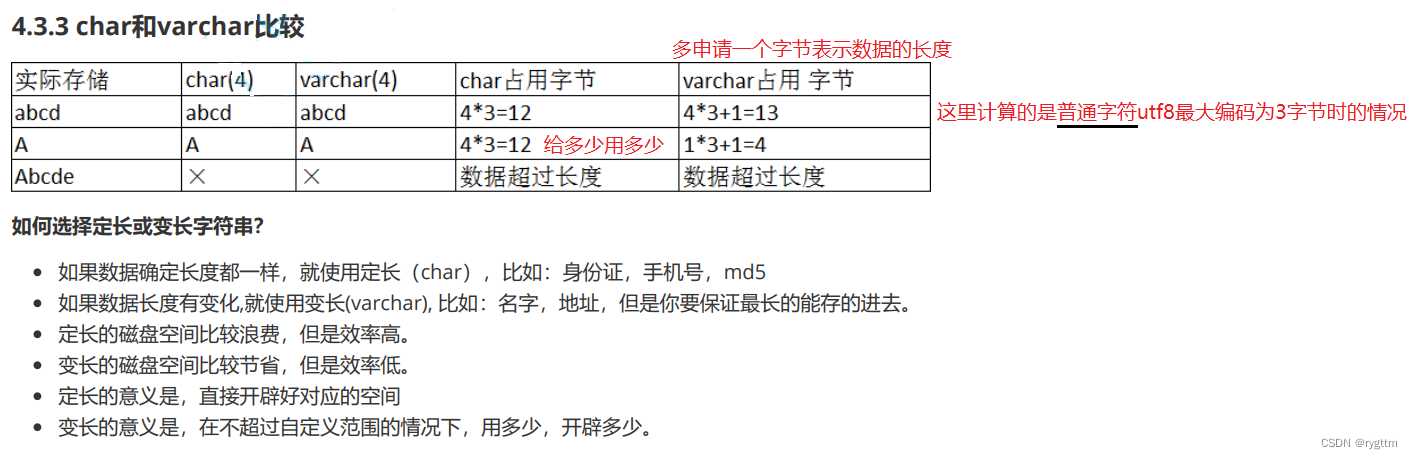
当创建表的第二个列字段为char(2)的时候,可以看到两个汉字和两个字母都可以插入到表中,但三个字母却无法插入,如果这里的字符和C语言中的字符概念相同的话,那就是2个字节的大小,那就不应该插入两个汉字,因为两个汉字在utf8编码下共占用6字节,应该会溢出的呀!
所以MySQL中的字符和C/C++语言中的字符概念是不同的,MySQL中的字符指的是一个字节序列,这个字节序列可以由多个字节构成,例如一个字符,一个ascll字符,或一个四字节的象形文字,表情符号等等,都算是一个字节序列。
char最大允许255个字符长度进行插入,如果你想要更大的数值类型,则可以使用blob(binary large object)和text,blob适合存储二进制数据,例如图像,声音,视频等多媒体数据,text适合存储文本数据,例如文章,日志等数据。
文本数据在存储时,一般会先按照对应的编码格式,例如utf8或ascll等,进行文本数据的编码,然后将编码后的数据按照对应编码的二进制表示形式存储到磁盘上,在取数据时,按照对应的编码格式进行解码,即可得到原始的文本数据。

2.
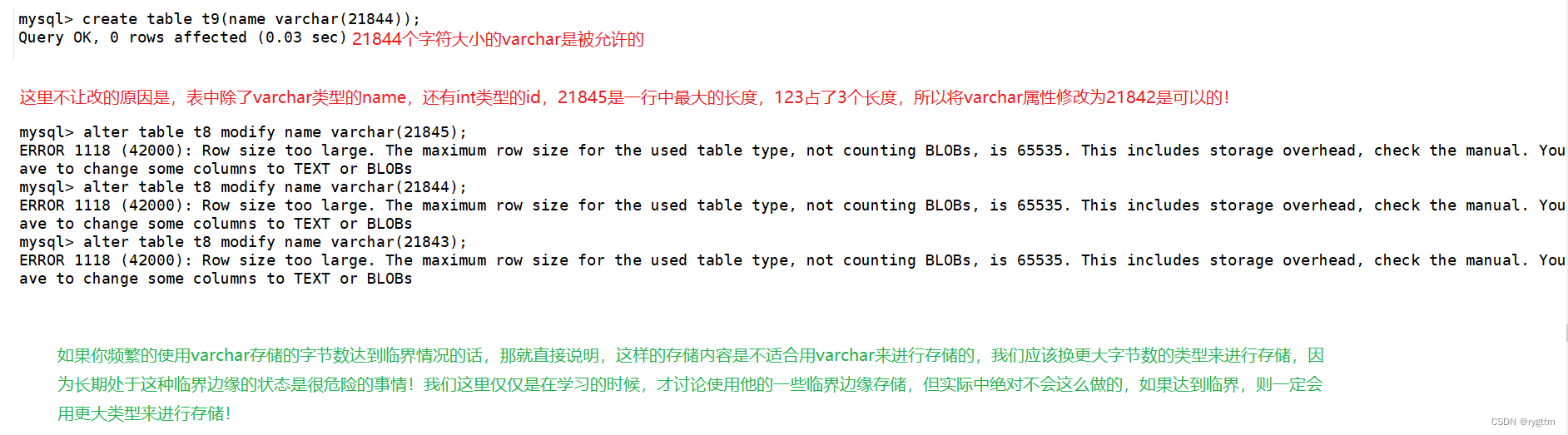
varchar是可变长度字符串,支持的最大字节数为65535,同时varchar还需要1-3个字节来记录数据的大小,所以有效字节数为65532,utf8中一个普通字符最大所占字节数为3字节,所以varchar的参数最大值是21844。

3.
21844个字符长度指的是表中一行的长度,如果表中一行里面还有其他的字段,则创建varchar时的参数还要比21844再小一些。值得注意的是,如果你使用某一数据类型,频繁的达到临界存储条件的话,则应该更换更大的数据类型进行存储。
4.
char和varchar的使用要结合具体场景来看,比如存储某些长度不变的数据时,则可以直接使用char,如果要存储长度变化的数据时,则可以使用varchar,但同时要保证varchar能够存储的下长度变化最大时的数据。
2.2 日期和时间类型
1.
常用的日期时间类型分别为date,datetime,timestamp,前两个为固定值,一旦插入到表后,除非你用update语句进行修改,否则不会发生变化,而timestamp是时间戳,只不过这里的时间戳的表示形式是年月日时分秒,而不是一长串表示秒的数字,当时间戳的数值插入到表后,该时间戳会随着表中任意数值内容的改动而发生改动,换句话说,只要表中内容被修改,则时间戳会自动更新为当前最新的时间。
timestamp字段由自己的默认值,所以在插入数据的时候,我们可以不用管这一列的值,后面我们学到约束的时候,就知道Default字段的含义了。
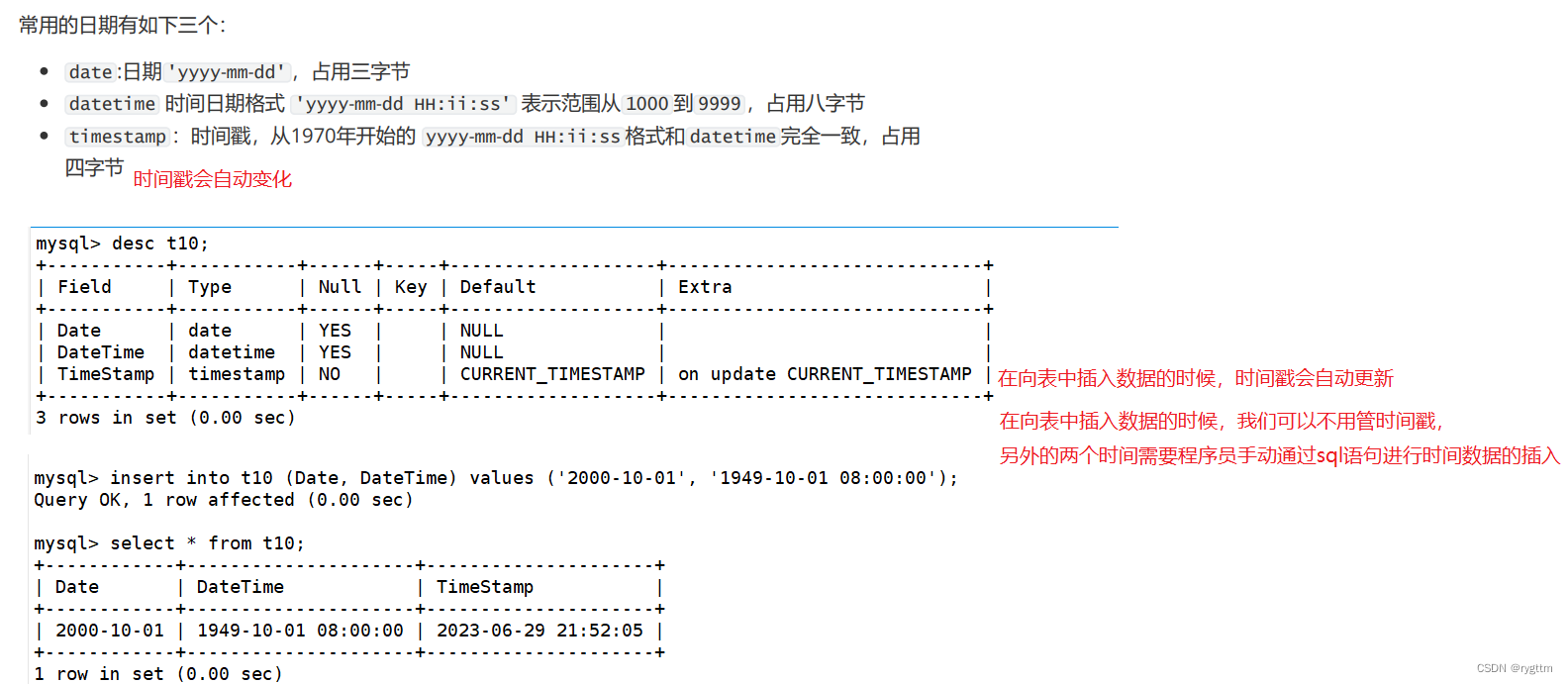
当我对表中第一行信息更新的时候,timestamp自动更新为当前的时间。
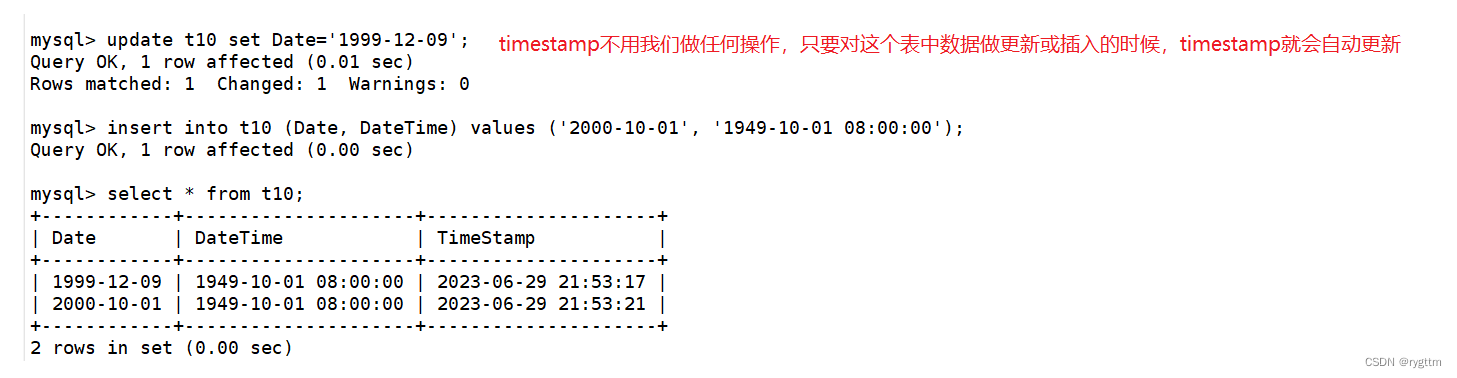
2.
时间戳一般可以用来实现评论,比如某个用户发表了自己的评论,当他对自己评论做修改的时候,该评论对应的timestamp会自动更新。
比如下面的例子中,我将评论”C++好找工作吗?“修改为“学好的话肯定是好找工作的”,则对应的timestamp类型的time字段的值会自动更新为当前最新时间。

3.
datetime时间日期类型一般用于记录某个固定的时间日期,比如员工的入职时间,办理身份证的时间,这些时间是不能随表的内容更改而更改的。
而date日期类型一般用于记录某个不需要时间,只需要日期的固定数值,例如你女朋友的生日,只需要记录日期即可,不需要记录几分几时几秒。
2.3 枚举和集合类型
1.
enum是枚举类型,可以在枚举的选项中单选出一个作为数值插入到表中,set是集合类型,可以在集合的选项中多选或单选出某些数值插入到表中。
enum在插入数值时,除插入枚举所给的选项外,也可以插入每个选项值对应的数字,从1开始依次向后为每个选项对应的数字下标。
set在插入数值时,除插入集合所给的选项外,也可以插入每个选项值对应的数字,每个选项值通过唯一的比特位来标识,也就是位图,用一个比特位来标识当前选项是否被选中。

2.
可以看到在插入数据时,如果你插入的gender字段不在枚举选项里面,则MySQL会直接拦截你对数据的插入,这再一次说明了类型本身就是约束,同时也可以看到枚举选项也可以用数字下标来代替,例如12分别代表枚举选项中的男和女,下标一般从1开始,这里与C或C++语言有所不同。

插入set集合的选项时,如果要插入多个则需要用逗号分隔开来,注意不能含有空格,必须只有逗号来作为多个选项之间的分隔,同时所有选项外面用单引号括住,或双引号括住,无论是单引号还是双引号,MySQL都是支持的。


3.
值得注意的是,在插入set选项时,是可以用0来作为数字插入的,只不过插入的是空串,在MySQL这里空串和NULL是由区别的,NULL指的是该列字段彻底为空,没有该列字段,如果赵六的hobby是NULL的话,则说明赵六没有hobby这一字段值,如果赵六的hobby是""的话,则说明赵六有hobby这一字段值,只不过hobby为空,这两个是不同的概念。
在插入set选项时,强烈不建议插入数字,因为插入数字的可读性太差。

4.
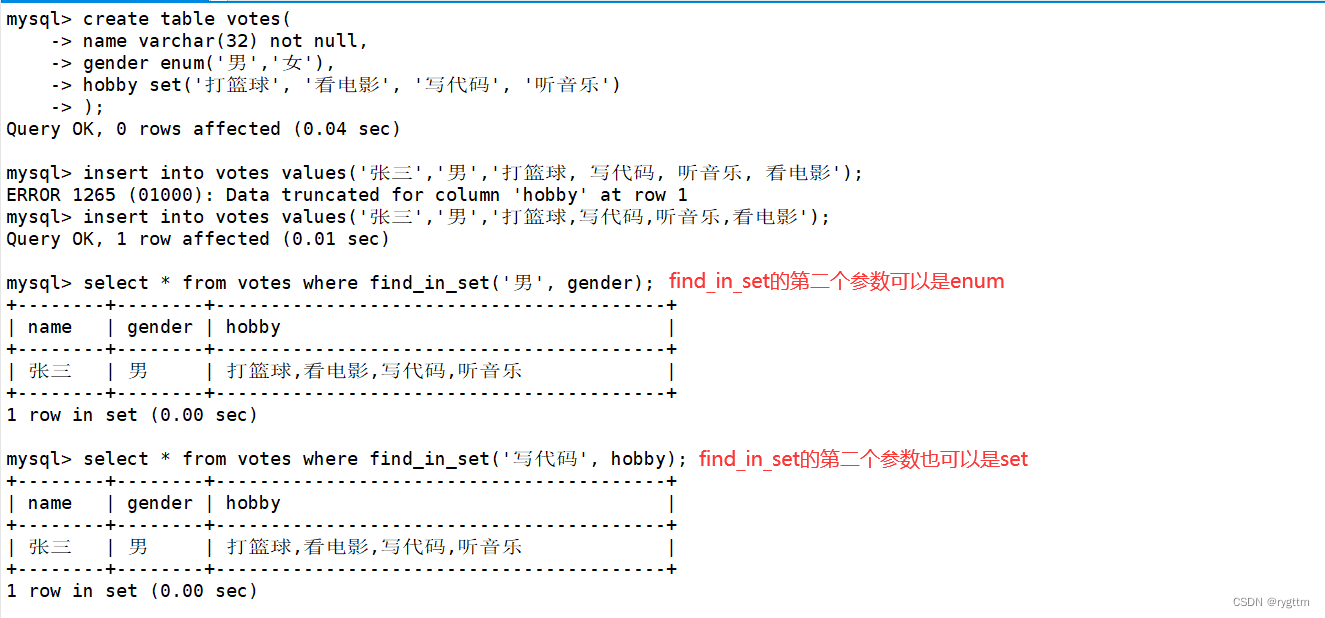
枚举和集合的查询,枚举在进行查询的时候,直接在where子句中添加筛选条件即可完成查询,不过where子句中的筛选条件是一种绝对的匹配,适用于枚举的严格匹配查询,因为枚举只能单选,比如gender只能有男或女,则匹配的时候直接绝对匹配即可。
如果在集合中进行查询时,则就不符合条件了,例如我想找出爱好中包括打篮球的人,如果使用where子句进行筛选的话,则查询出来的人的爱好就只有打篮球,所以仅仅使用where是不行的。还需要配合一个函数叫做find_in_set(sub,str_list) :如果 sub 在 str_list 中,则返回下标;如果不在,返回0;str_list 是用逗号分隔的字符串。
则使用select * from votes where find_in_set(‘打篮球’, hobby)即可查询到hobby里面包含打篮球的人,find_in_set会遍历表中所有人的hobby,只要包含打篮球字段,则返回大于等于1的值,则where条件判断为真,select此时会显示出来,如果不包含打篮球字段,则返回0,where条件判断为假,select就不会显示出来了,这也就是为什么枚举的下标是从1开始的了,因为MySQL中某些函数想要用0来作为查询结果是否存在的判断值。

find_in_set的第二个参数为以逗号分隔的字符串,也可以是set集合,或enum枚举,他俩也都是以逗号分隔的多个字符串。

六、MySQL表的约束
1.not null约束 && default约束
1.
约束的唯一目的其实就是为了保证数据库中数据的有效性,可预期性和完整性,一旦插入的数据不符合表约束,则MySQL直接拦截数据的插入,倒逼程序员向数据库中插入有效的数据。让数据库中的数据都是符合约束的。
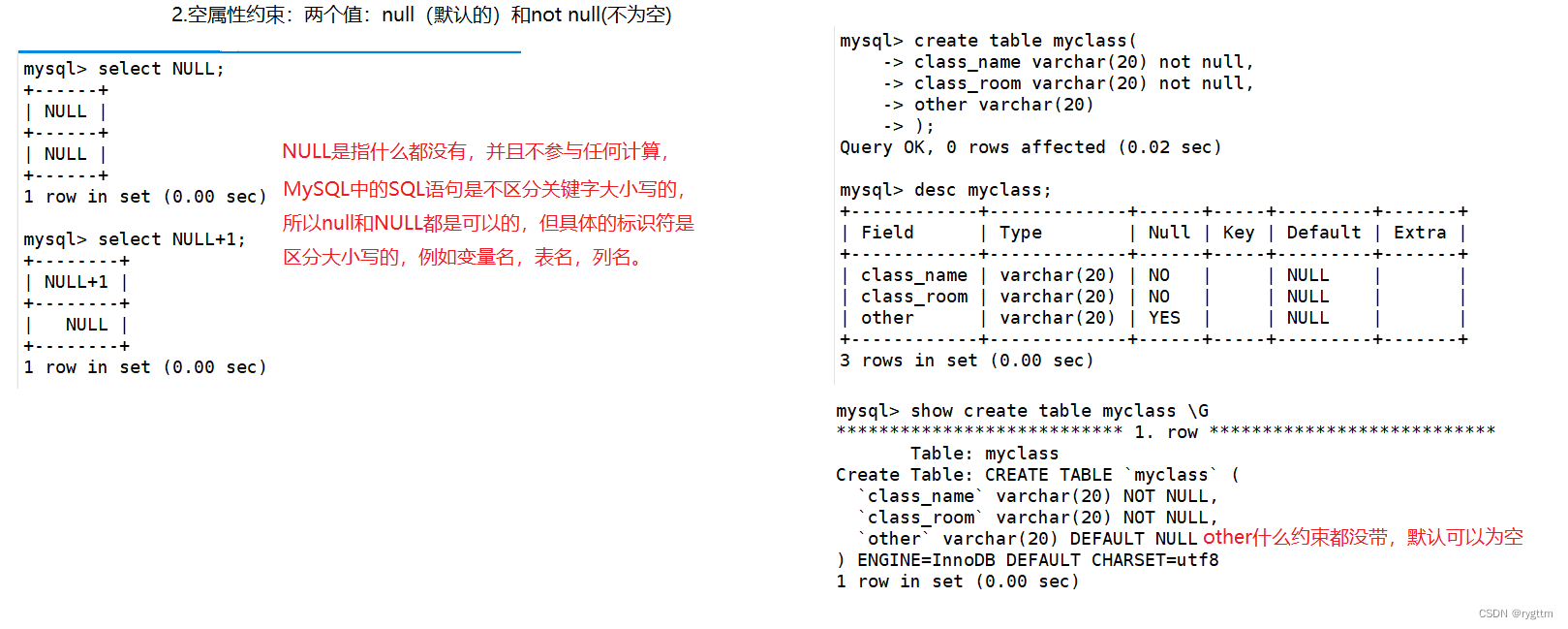
1.
not null一般约束的是,当我们在插入对应的列字段时,该列字段的数值不能为null值,必须是有效值,同时当我们创建一个表添加列字段的时候,如果什么属性都不带,则会有一个默认属性default,default的值为null,这点我们可以通过show create table xxx \G SQL语句看到。
同时null是指什么都没有,并且不参与任何计算。
2.
other列什么属性都没有带,则sql默认会给他带上一个default属性,该属性字段值为null,所以在插入数据的时候,values的右边可以忽略掉other列,忽略掉这一列,则实际插入数据时,该列字段使用默认值null来进行插入。
我们也可以选择不忽略掉other列,如果不忽略的话,则使用我们自己插入的数据,不使用默认值,other列也没有not null约束,所以在插入数据的时候,我们也可以显示的插入null值。
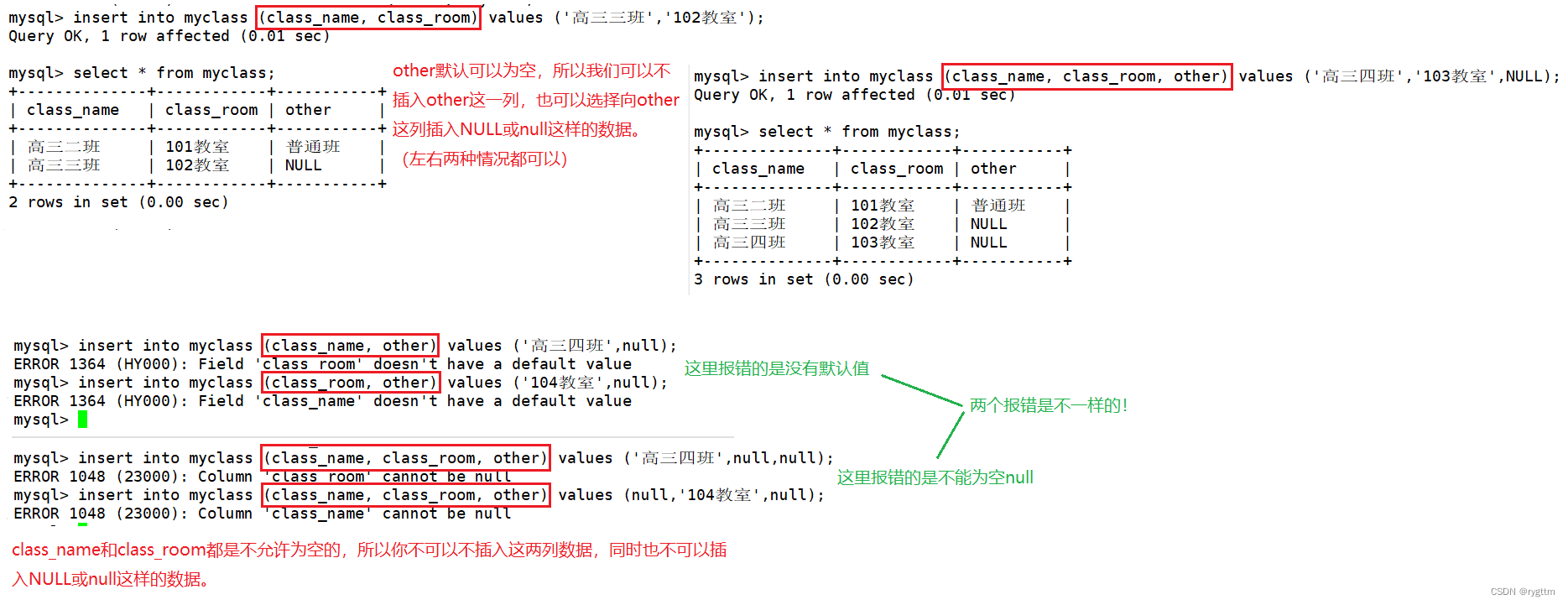
通过下面的报错也可以看到default和not null分别控制的是什么,当我们忽略掉class_name或class_room列字段时,MySQL报错的是doesn’t have a default value,告诉我们该列字段没有默认值,所以你是不可以忽略这列字段的。
而当values左面的括号进行全列插入的时候,插入class_name或class_room列字段值为null时,此时MySQL报错的才是cannot be null,不允许为空值,因为有not null非空约束。
3.
default默认值约束,如果用户在插入数据时,想要忽略这一列字段的插入,则可以使用default,例如一个程序员相亲网站,大部分用户肯定都是男性,所以我们可以默认用户的gender为男。
default的使用方式有两种,一种是忽略该字段插入,默认使用default的值,一种是不忽略该字段插入,手动的插入自己想要的值。

4.
当not null和default属性叠加到一块时,其实就是如果你忽略该列,则直接使用default的值,如果你不忽略该列,则插入的值不能为null值。就这么简单。

5.
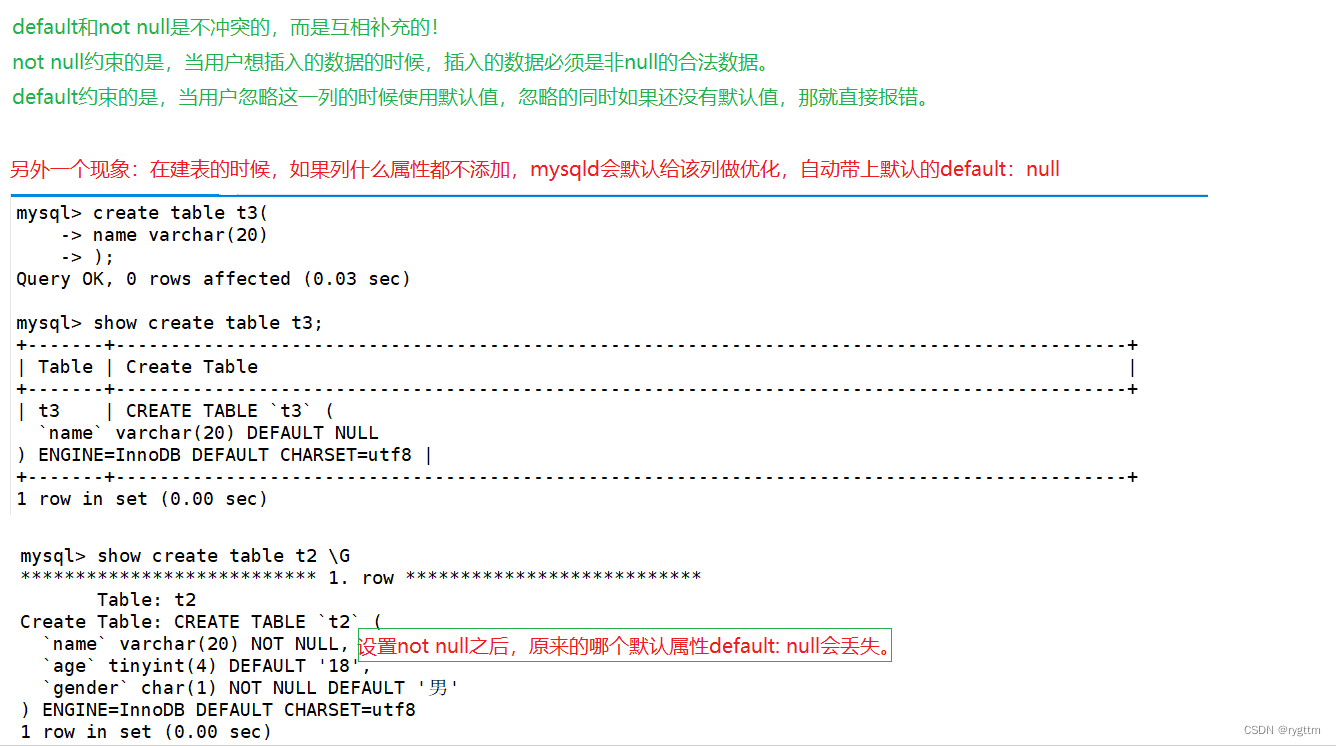
有一些MySQL的默认行为还需要给大家说一下,当创建一个表的时,如果什么属性都不带,则默认会有一个default:null的属性,一旦添加任意一个属性,则MySQL给该列自带的default属性就会消失。
not null和default分别约束的是,插入数据的值不能为null和忽略该字段的插入时,直接使用default值。
2.comment约束 && zerofill
1.
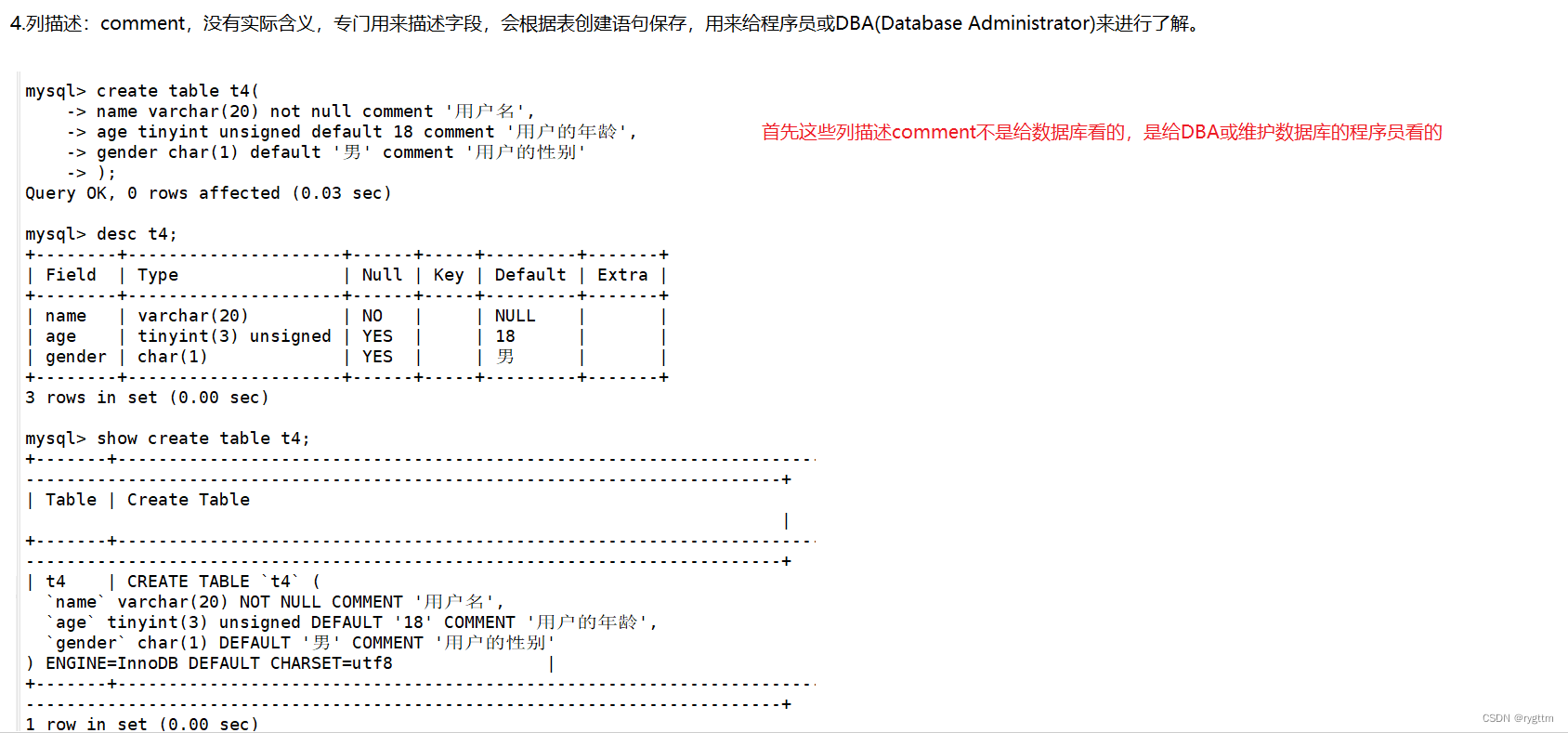
comment约束并没有什么实际的含义,在建表的时候,可以在列字段后面加上一些内容上的描述,此时就可以使用comment约束来实现。
不过这些字段值在desc查看表结构的时候,并不会显示出来,只有在show create table xxx显示创建表结构时的sql语句时候才会显示出来,所以comment的值不是给数据库看的,而是给数据库管理员(DBA)或维护数据库的程序员看的。
2.
zerofill是关于显示方面的约束,并不会更改数据实际在磁盘上的存储结果,仅仅只是更改显示的结果而已,默认的int unsigned数值类型,在desc查看时,int后面会有个括号,里面的数字是10,其实10代表的是数字字符的个数,如果你在创建表的时候,不显式指定括号里面的数字的话,则MySQL默认会认为int unsigned是10位,此时如果给列字段增加zerofill,则显示出来的结果会变成10位的数字,高位用0来进行填充。

3.
如果显示的数字位数小于int括号里面的数字的话,则空余位全部用zero填充,如果显示的数字位数大于int括号里面的数字的话,该怎么显示就怎么显示,此时zerofill约束不起作用。
当你不指定int后面的括号时,如果是有符号int,则括号内的数字默认是11位,如果是无符号int,则括号内的数字默认是10位。
因为int是4字节,所以无符号int默认的最大数字字符个数就是10个,如果是有符号则还要多个符号字符,所以默认就是11位。

3.primary key约束 && auto_increment约束
1.
primary key主键用来唯一的约束该列字段里面的数据,这些数据不能重复,同时也不能为空,并且主键约束的字段都是整数类型,不会是浮点数、字符串、日期时间等类型,一张表里面最多只能由一个主键。
例如在建表test_key的时候,一旦给id加上了primary key约束,则表还会自动的增加not null属性,这点可以通过show create table test_key\G看出来,sql优化后的主键标准格式为在表括号内的最后一行加上primary key(‘id’)。
如果在表中第二次插入id为1的数据,则MySQL会直接拦截,并报错duplicate entry ‘1’ for key ‘PRIMARY’,指的是条目1对于主键重复,不允许我们插入数据,这就是primary key的约束。

2.
除了在建表的时候添加主键,我们也可以在建表之后添加主键或删除主键,使用sql语句alter+drop primary key或alter+add primary key(xxx)。

3.
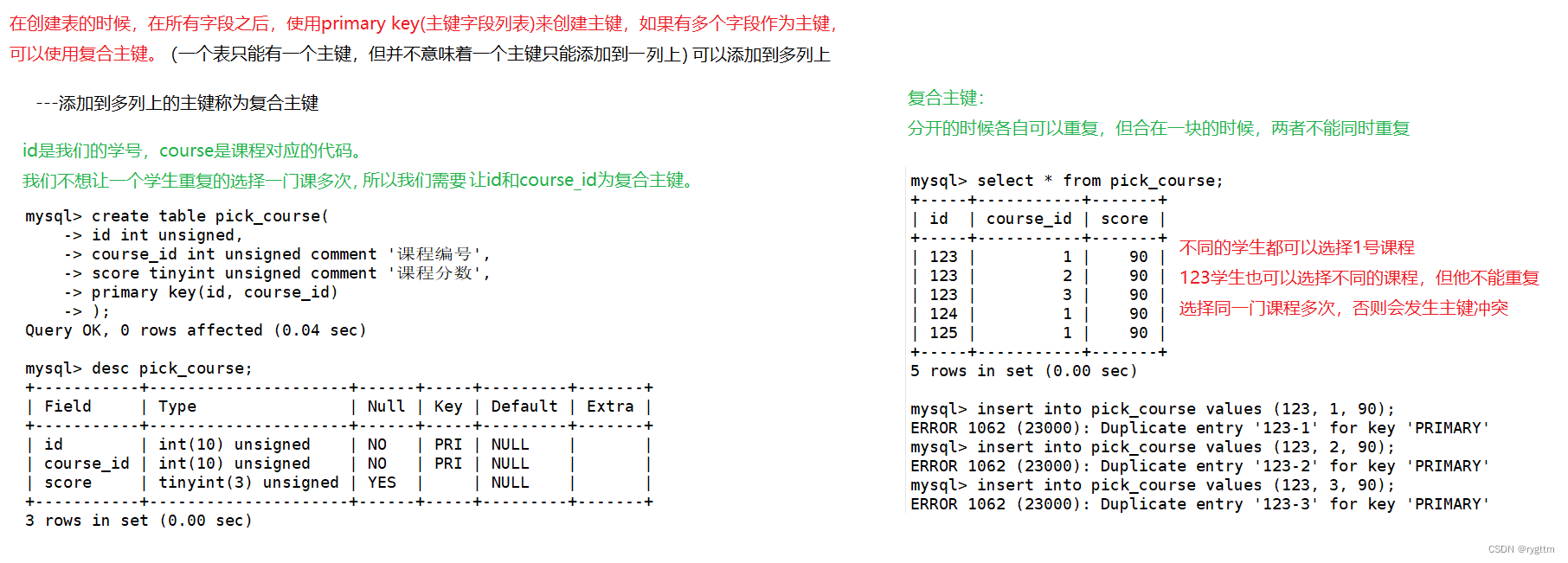
我们除了给一个字段添加主键外,也可以给多个字段同时添加上主键,这样的主键我们称之为复合主键(一张表确实只能有一个主键,但这一个主键可以添加到多列上)
例如id是学生的学号,course是课程的课号,我们不想让一个学生重复的选择一门课程多次,但我们可以允许一个学生选择多门课程,或不同的学生选择同一门课程,在这样的场景下,就适合用复合主键,在表中添加primary key(id, course)复合主键
4.
自增长auto_increment可以和主键或唯一键搭配使用,与主键相同的是:一张表中只能有一个自增长auto_increment,自增长的字段必须是整数。
当自增长与主键搭配使用时,我们称主键为自增主键。
建表的时候,可以在圆括号外面指定自增长的初始值,如果没指明也没有关系,默认从1开始,在插入数据的时候,我们可以忽略有自增长字段的列,该列会自动每次从当前字段中已有的最大值,加上1然后分配给新插入的数据。show create table时,也可以看到下一个插入数据时,对应的auto_increment的值。
实际上像QQ号这样的注册模式,使用的就是自增长,保证QQ号具有唯一性,不允许出现重复的QQ号


5.
与主键相同的是,一张表也只能有一个自增长,如果一张表出现多个自增长,则建表也会不成功。
除此之外还有一个函数last_insert_id(),该函数用于获取上次插入的自增长的值,如果上次是批量化插入的,则获取插入的第一条数据所对应的自增长的值。
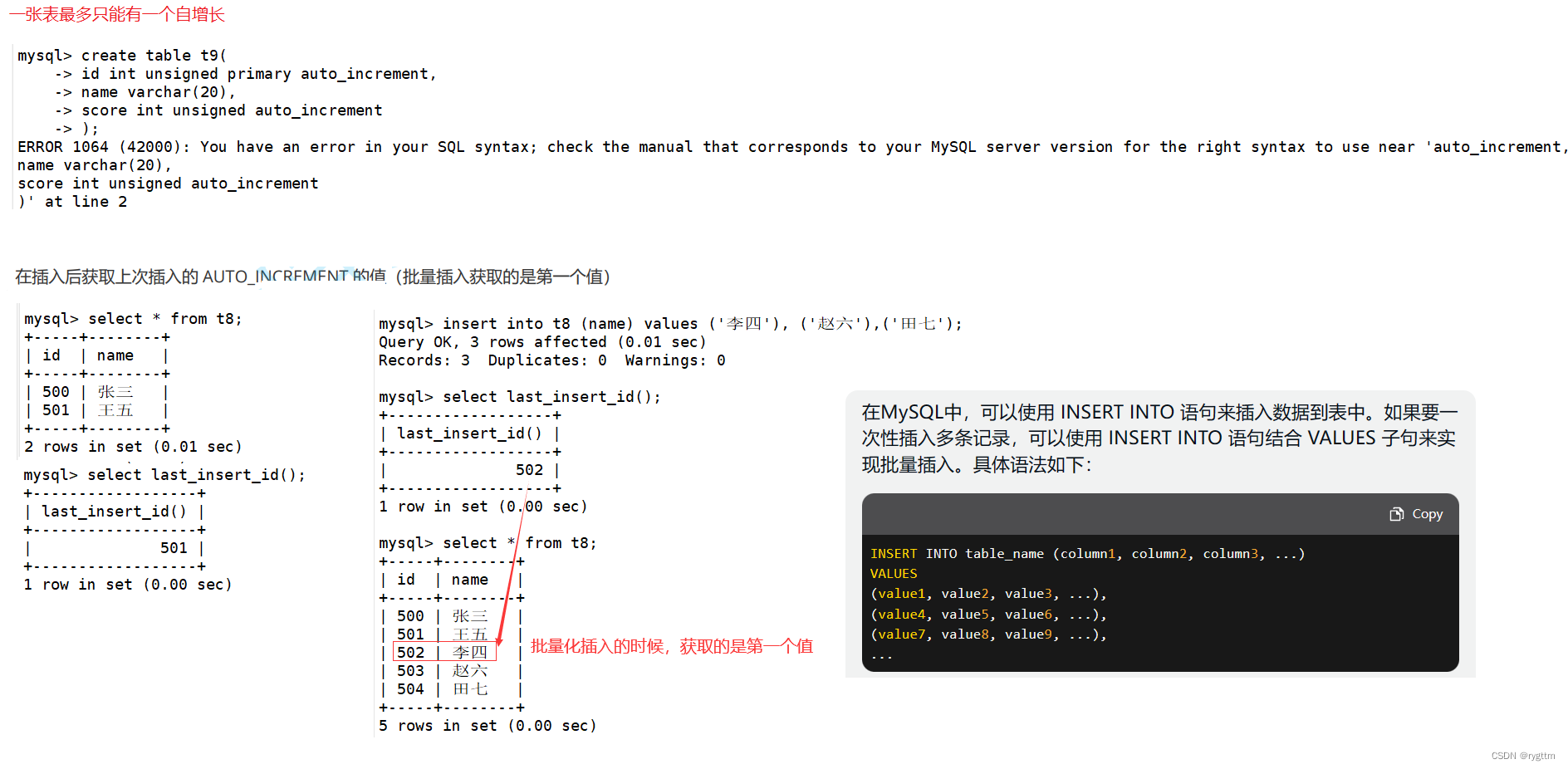
4.unique key约束 && foreign key references约束
1.
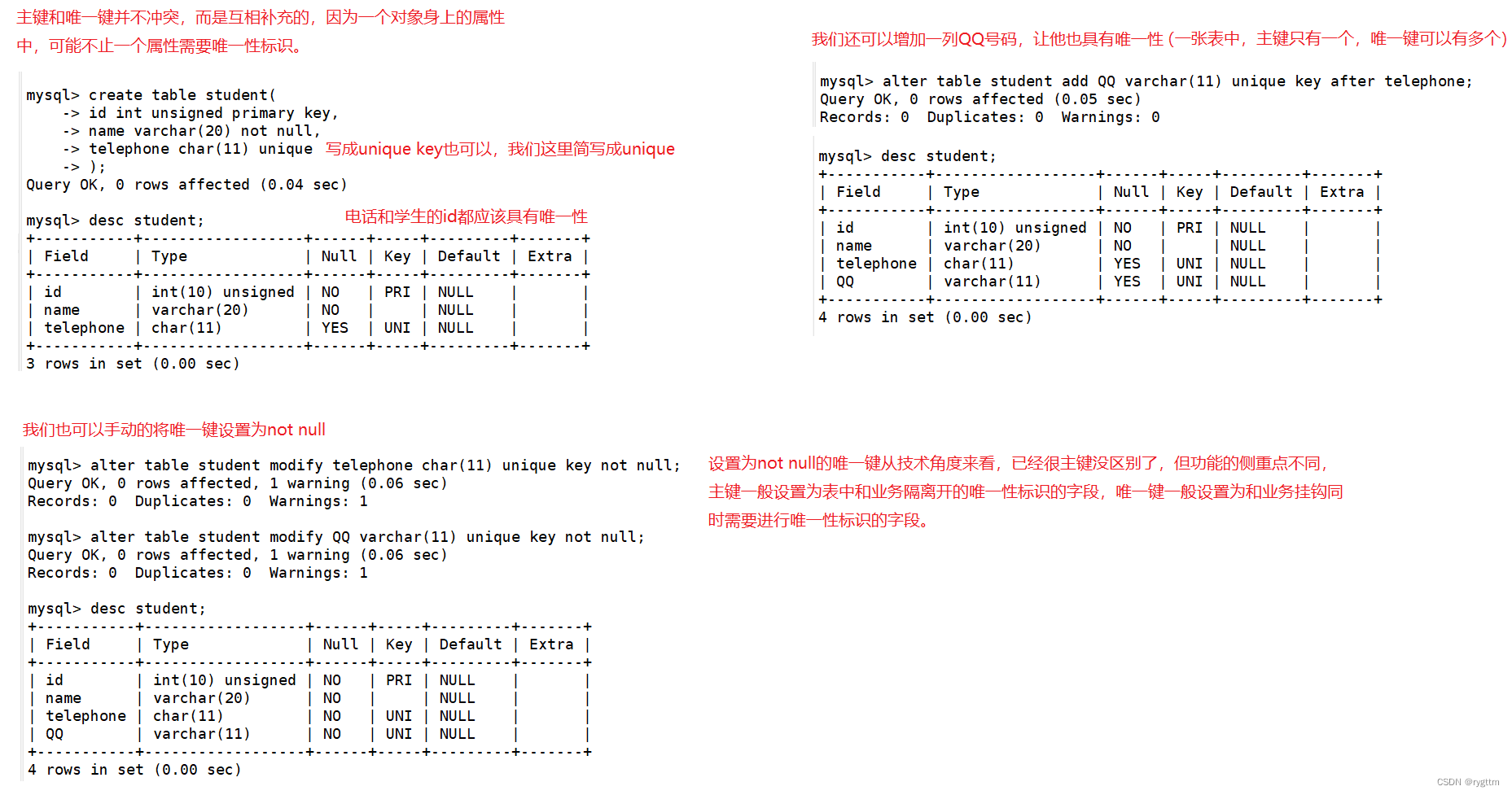
一张表中往往有多个字段需要唯一性标识,一张表只能有一个主键,但一张表可以有多个唯一键,所以唯一键就可以很好的约束表中多个需要唯一性标识的字段,唯一键和主键比较相似,从功能上来讲,唯一键允许为空null,主键不允许为空null,不过空字段是不做唯一性比较的,判断表中唯一键是否重复时,NULL肯定是不作比较的,这非常合理。
例如student表中的唯一键约束的id,可以是多个NULL,因为我们知道NULL不参与任何比较和计算,所以可以出现id为多个NULL的情况。
2.
举一个例子,一张表中假设有两列信息,一个是员工的身份证号码,一个是员工的工号,这两个信息都需要唯一性标识,我们便可以将身份证号码设置为主键约束,员工工号设置为唯一键约束,一般而言,我们都会将主键设置成为和当前业务无关的字段,这样的话,当业务发生变化的时候,主键可以不用做过多的调整。

3.
一张表中,主键只能有一个,唯一键可以有多个,所以例如学生id,电话号码,QQ号码等都可以进行唯一键约束,如果你不想让唯一键中出现NULL值,则可以在唯一键约束的基础上再多添加一个not null非空约束。
设置为not null约束的唯一键从功能上来讲,已经和主键没有区别了,都是保证字段的唯一性,但从数量上来讲,一个表中主键只能有一个,唯一键可以有多个。从业务上来讲,主键一般设置为和当前业务无关的字段,唯一键一般设置为和当前业务挂钩的字段。
3.
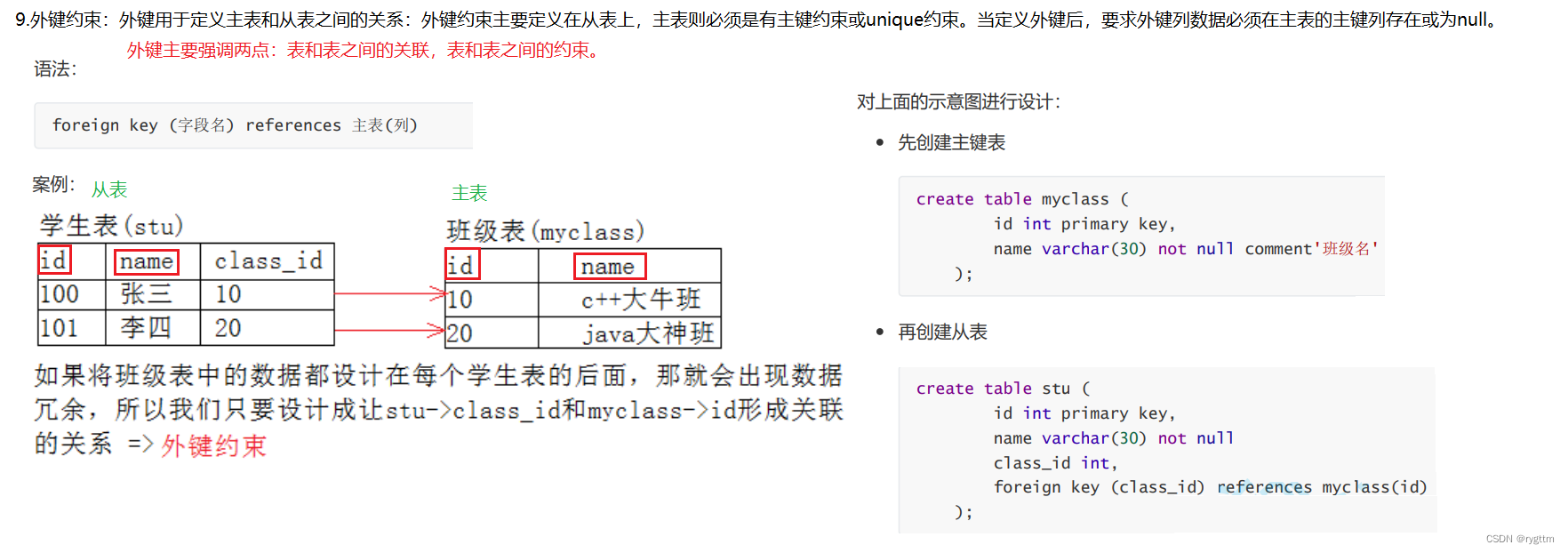
外键约束是innodb存储引擎的一个重要特性,外键一般用于进行表和表之间的关联,用于约束具有关联性的表,比如下面的学生表和班级表,学生是隶属于班级的,比较合理的做法就是创建外键约束,外键为学生表中的class_id,引用自班级表中的主键列id。
4.
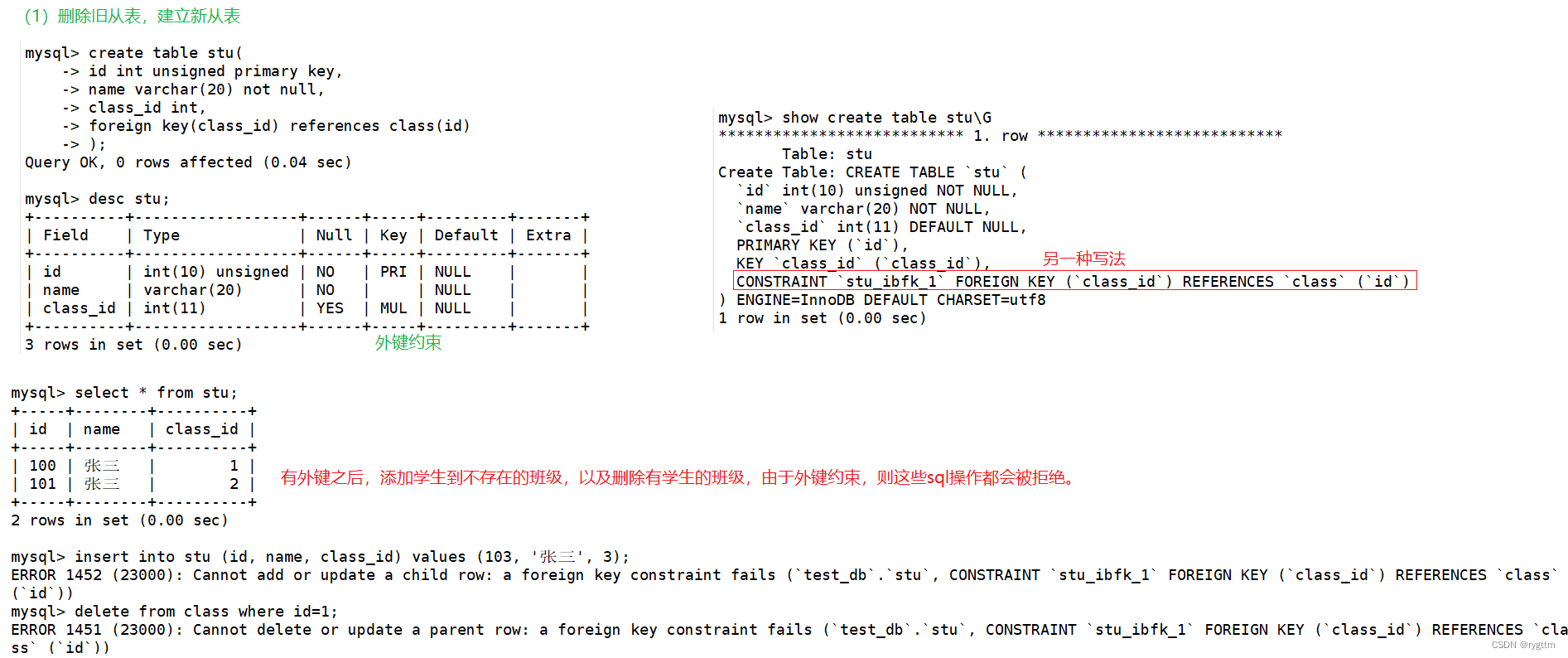
下面是外键约束的探究过程。
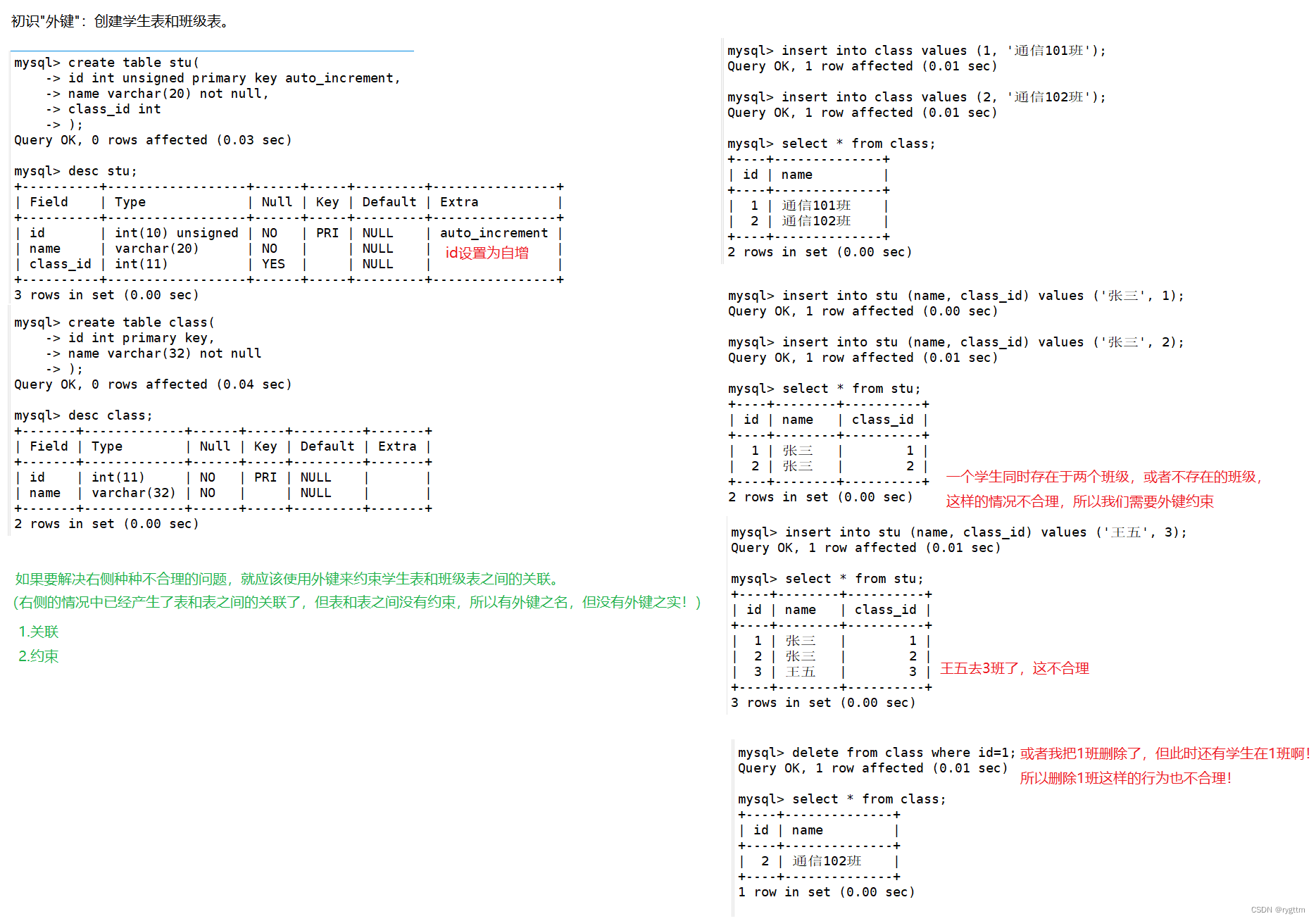
如果stu和class表之间没有外键约束的话,则向stu表中插入数据时,有可能误操作将一个学生插入到两个班级,或者将学生插入到不存在的班级,以及删除班级,但班级此时还有学生,如果不添加约束,则学生又到了不存在的班级中了,这些都是不合理的,所以显而易见,班级表和学生表之间一定需要某种约束关系,而这个约束实际就是外键约束!
5.
当建立外键约束后,外键为stu表中的class_id,引用自class表中的id,如果此时将学生插入到不存在的班级,或者删除某个班级,一个学生插入到两个班级等等不合逻辑的操作,都会被MySQL拦截掉,保证表与表之间正确的关联关系。
其实这里的外键,个人觉得和复合主键有那么一点点相似,必须保证外键和引用之间的唯一性,但外键的约束显然是要比复合主键更严格的,比如删除引用(引用中还存在着外键)是不被允许的,一个外键列中的字段只能配一个引用列中的字段,必须是一对一的,就像离散数学里面的双射关系一样,严格的一对一。
5.综合案例
1.
有一个商店的数据,记录客户及购物情况,由以下三个表组成:
商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商provider)
客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
要求:
每个表的主外键。客户的姓名不能为空值。邮箱不能重复。客户的性别(男,女)
2.
订单中的商品编号和客户编号需要外键约束,引用到goods和customer各自的goods_id和customer_id中。
