前言
介绍Redis性能排查的工具和针对问题现象的分析处理;
一、常见工具及手段
Redis里面提供的命令
1. INFO命令
返回关于 Redis 服务器的各种信息和统计数值。
--主要包含以下信息:
server : 一般 Redis 服务器信息;
clients : 已连接客户端信息;
memory : 内存信息;
stats : 一般统计信息;
replication : 主/从复制信息
cpu : CPU 计算量统计信息
commandstats : Redis 命令统计信息
cluster : Redis 集群信息
keyspace : 数据库相关的统计信息
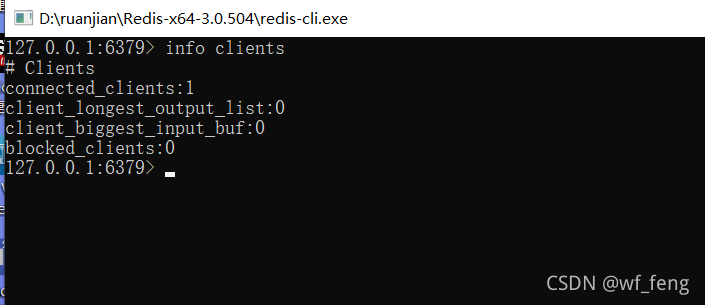
具体信息通过info message命令,比如获取redis的连接信息:
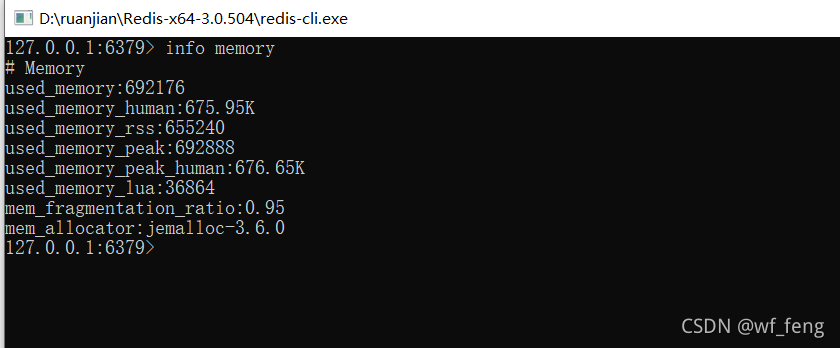
Redis的内存信息:
具体详细信息可参考中文文档 https://www.redis.net.cn/order/3676.html
2. monitor命令
实时打印出 Redis 服务器接收到的命令,我们一般用这个命令来查询当前Redis正在执行哪些命令,可以短暂开启,不会阻塞Redis,压测验证多少对性能有点性能 大概20%;
比如说Redis进程CPU高了,那我们可以利用这个命令来查询Redis正在执行哪些命令

我们分析下返回值:
1635769163.753976 [0 127.0.0.1:3337] “set” “wufeng” “aaaa”
1635769175.259109 [0 127.0.0.1:3337] “get” “wufeng”
1635769190.040828 [0 127.0.0.1:3337] “set” “wufeng” “1111”
1635769192.420104 [0 127.0.0.1:3337] “get” “wufeng”
比如第一行的1635769163.753976 为时间戳,单位为s;
[0 127.0.0.1:3337],也就是连接为127.0.0.1:3337 对Redis的库0执行的命令的 set命令
那么我们可以在Redis服务有性能问题的时候,执行monitor命令几s,然后统计这些每s的并发命令和执行了哪些命令来判断问题;
3. slowlog命令
Redis Showlog 慢查询日志,
查询执行时间指的是不包括像客户端响应(talking)、发送回复等 IO 操作,而单单是执行 一个查询命令所耗费的时间。
获取当前时间点下的前最新的10条命令:slowlog get 3
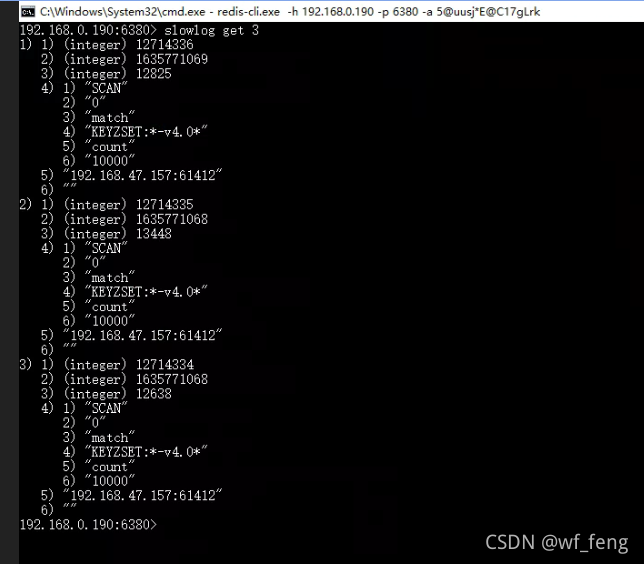
命令结果分析:
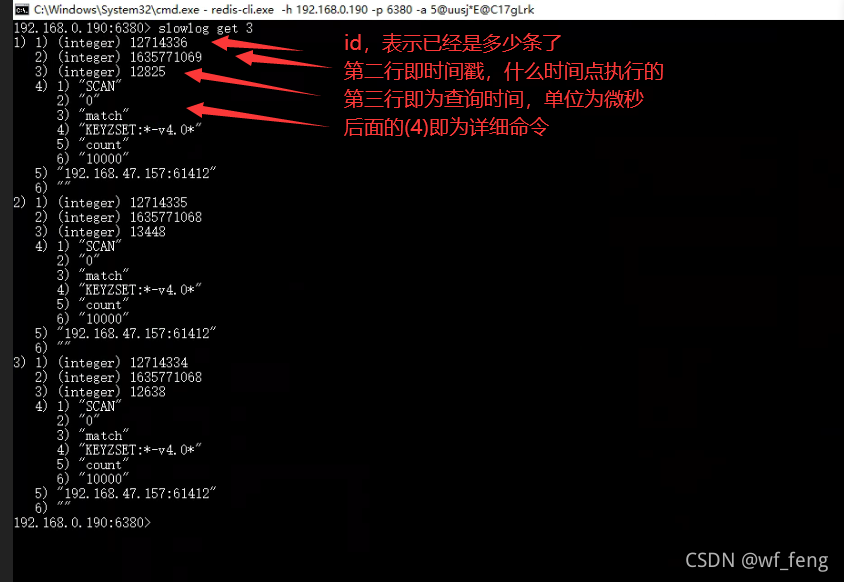
有时间点,有时间戳,那么我们就可以拿来监控分析,什么时间点执行了什么命令耗时多少;
慢查询日志队列的设置:
获取慢查询阀值,即超过多少时间记录到慢查询日志,它决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
获取时间
CONFIG GET slowlog-log-slower-than

即默认的慢查询阀值是10000微妙,即10ms
设置时间:
CONFIG set slowlog-log-slower-than 5000
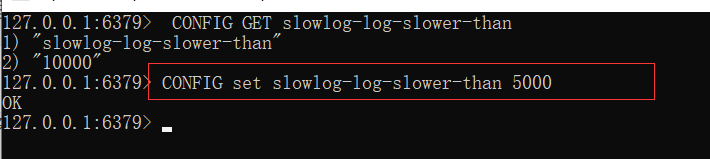
此处设置为5000微妙,即5ms,值不易太小(队列频繁置换,不好查历史值),不宜太大(容易忽略问题)
慢查询日志 FIFO 队列设置:
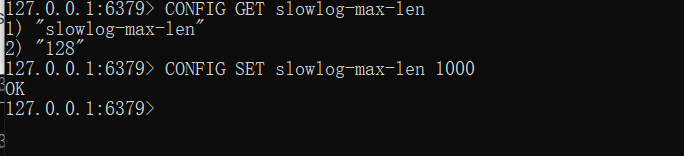
获取条数设置
CONFIG GET slowlog-max-len, 默认为128条
设置保存条数
CONFIG SET slowlog-max-len 1000 ,更改为1000条
4. bigkeys命令
--bigkeys,用来查找大对象value的命令;
哪些是bigkey?
字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey,我们正式环境分析过都存在10M的String类型对象,虽说现在还没有体现问题,随着客户量的提升,始终会是隐患,后面都会沟通优化;
非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多; 正式环境也分析存在,但是这种集合类型的主要对性能影响在取一个Hash或者删除整个Hash,这种操作按正常的业务需求来说,并发不高,但不是绝对的;
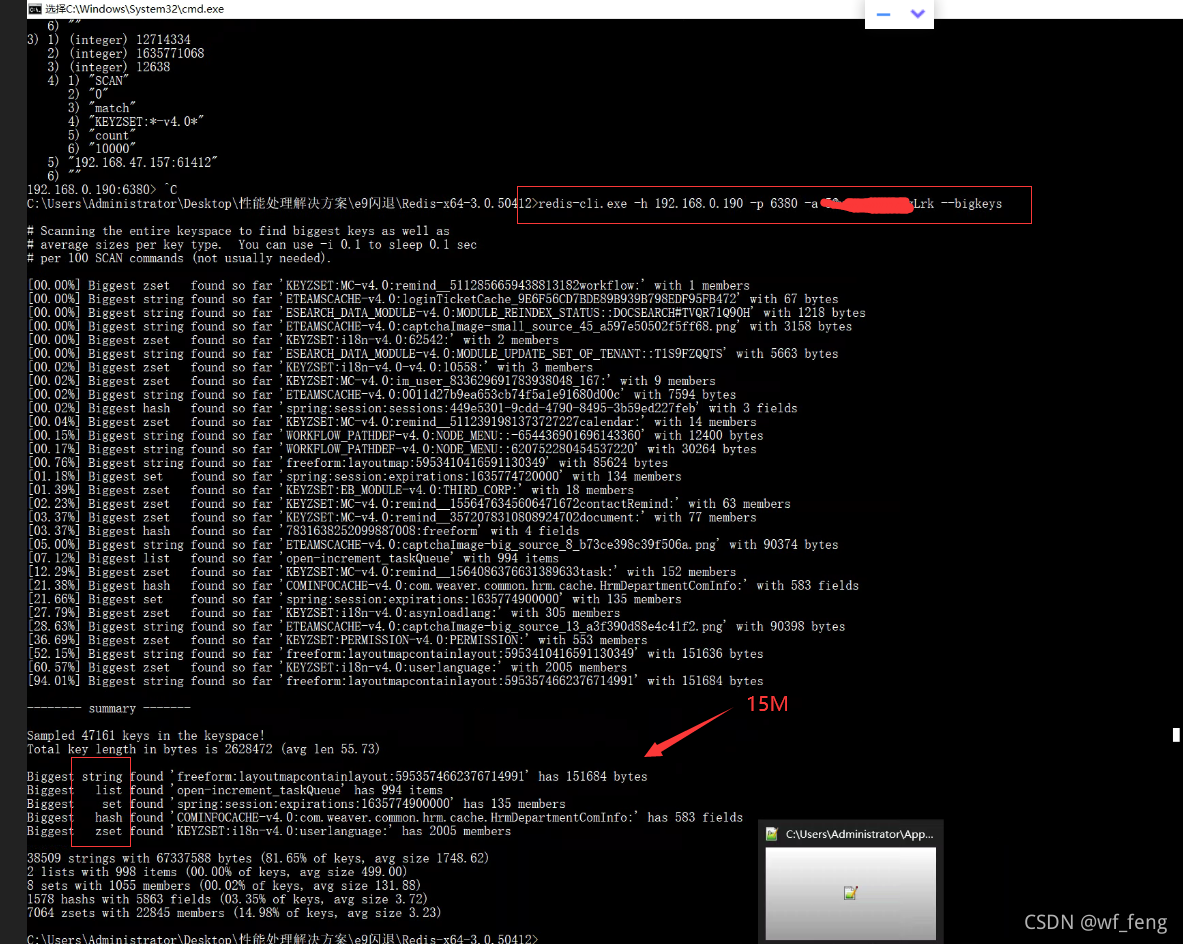
利用–bigkeys发现bigkey:
执行命令redis-cli -h ip -p port -a XXX --bigkeys
如下是拿目前的集群环境的其中一个节点抓的;
bigkey带来的隐患:
1. 由于Redis单线程的特性,操作bigkey的通常比较耗时,也就意味着阻塞Redis可能性越大,这样会造成客户端阻塞或者引起故障切换,它们通常出现在慢查询中。
2. bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说就扛不住了;且这个服务器上如果还有其他服务实例,皆会拖垮;
3. 过期删除或者主打删除的性能问题,倒是可以采取Redis4.0提供的过期异步删除(lazyfree-lazy-expire yes)策略解决;
4. 集群的情况下会造成内存分配不均,可能大部分的大key集中在一个节点吃满内存;
对这种bigkey解决方案:
1. E10新缓存提供了压缩功能策略,对数据进行压缩存储;或者业务上自行压缩处理;
2. 并发高的bigkey,采取本地缓存的方式;
3. 业务上对value进行拆分;
以上都是事后解决,事前发现的方案:
1. 缓存底层接口对value值进行判断拦截,及时反馈给业务开发;(目前未开发)
5. benchmark命令
--benchmark命令,一般是用来作基准测试的,比如新上一台服务器,测试下简单的get set命令是否可以达到官方给的10多w的qps;
详细的可参考下面这篇文章;
;Redis性能测试——redis-benchmark使用教程https://blog.csdn.net/yangcs2009/article/details/50781530
6. latency命令
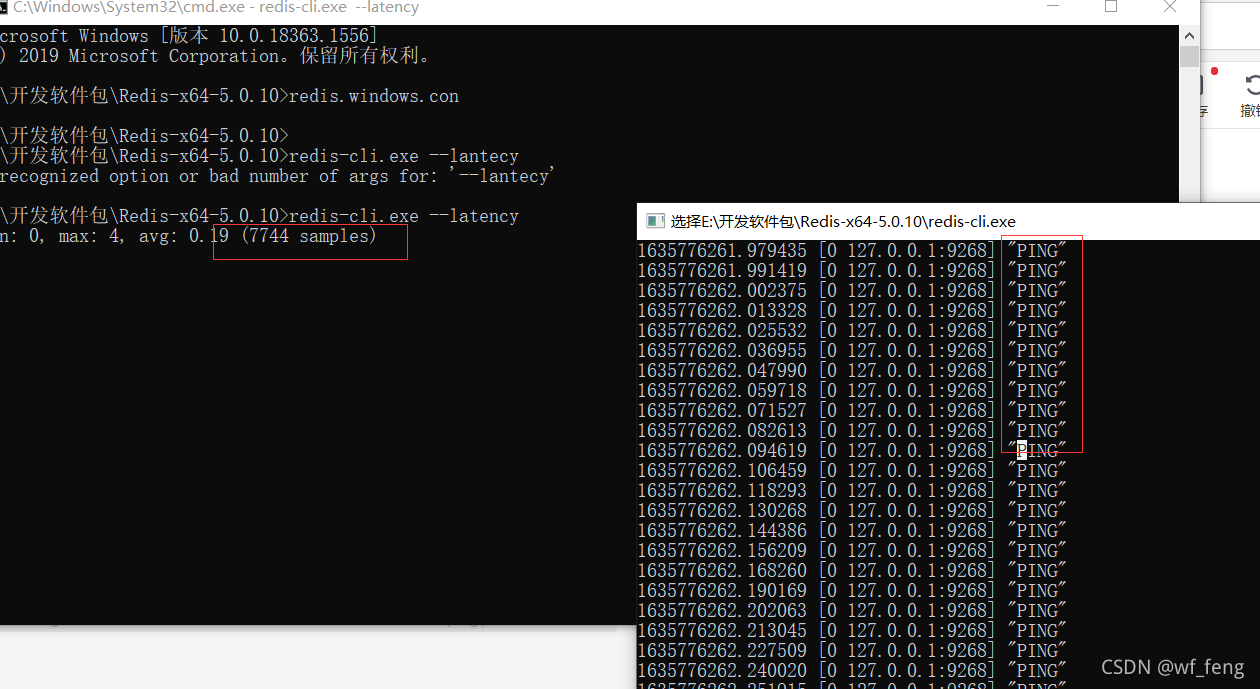
latency测试运行中Redis的延迟,实现原理是不断的发送ping命令计算平均耗时;
比如下图,是本机127.0.0.1测试,测试的同时通过右侧的窗口执行monitor命令查询正在执行的命令,发现都是ping命令,且从测试结果来说,Redis延迟本机最佳一般就是在19us左右;这个也是一个测试Redis性能的手段;
开启监控延时:
CONFIG SET latency-monitor-threshold 100 #单位毫秒,表示超过100毫秒的响应将会被监控,默认为0,表示关闭状态;
Latency Latest命令
127.0.0.1:6379> latency latest
1) 1) "command" #事件名称
2) (integer) 1405067976 #延迟发生的时间戳
3) (integer) 251 #延迟 毫秒
4) (integer) 1001 #事件的最大延迟
Latency History命令
127.0.0.1:6379> latency history command #查看commend事件的历史延迟 返回160个元素
1) 1) (integer) 1405067822 #时间戳
2) (integer) 251 #延迟
2) 1) (integer) 1405067941
2) (integer) 1001
个人觉得,还不如关闭,没有感受到这个命令的可用之处,还不如slowlog;
其他手段
1. Redis内存dump分析
主要是依赖一些现有开源的工具,此处推荐链接:
- 使用RDR工具查看Redis中key占用的内存https://blog.csdn.net/huantai3334/article/details/113464340
- 使用rdbtools工具来解析redis rdb文件https://www.cnblogs.com/cheyunhua/p/10598181.html
二、CPU高问题
- 大并发下CPU高;
如何确定并发高:
查看redis每秒的查询次数;–info stat
192.168.0.190:6382> info stats
# Stats
total_connections_received:3578768 ##所有连接数 累积
total_commands_processed:29111456557 ##服务器执行的命令数 累积
instantaneous_ops_per_sec:18570 ## 每秒执行的命令数
total_net_input_bytes:8788037875385 ## 网络流量-流入
total_net_output_bytes:162162655775051 ##网络流量-流出
instantaneous_input_kbps:5034.16 ##网络流量-流入-KB/sec
instantaneous_output_kbps:16361.97 ## 网络流量-流出-KB/sec
rejected_connections:0
sync_full:1
sync_partial_ok:0
sync_partial_ok:0
sync_partial_err:1
expired_keys:427378621
expired_stale_perc:1.11
expired_time_cap_reached_count:8
evicted_keys:1050467
keyspace_hits:11020187003 ## 命中的 Key数量
keyspace_misses:1112525439 ## 未命中的 Key数量
pubsub_channels:5
pubsub_patterns:2
latest_fork_usec:845
migrate_cached_sockets:0
slave_expires_tracked_keys:0
active_defrag_hits:0
active_defrag_misses:0
active_defrag_key_hits:0
active_defrag_key_misses:0
192.168.0.190:6382>
查看当前都是在执行什么命令;--monitor
查看当前是否存在慢查询; --- slowlog get
通过以上命令来排查,比如有什么业务并发死循环查询redis,且都是一些慢查询导致等;
2. 小并发下CPU高;
redis的qps较低的情况下,CPU高,那就是存在慢查询,慢查询无非是算法复杂度和IO的问题;
这个时候用slowlog命令查询
3. 有时候CPU100的进程是Redis的RDB持久化的线程,注意下区分;
三、连接数问题
Redis连接数高的问题,那么还是先谈如何监控Redis的连接数问题,使用info clients 命令;
192.168.0.190:6381> info clients
# Clients
connected_clients:2311 ###保持连接数
client_longest_output_list:0 ### 最大的输出缓冲区
client_biggest_input_buf:0 ### 最大的输入缓冲区
blocked_clients:0 ###阻塞的连接数
192.168.0.190:6381>
比如上述连接数2311是公司测试环境集群某一节点的连接数,看起来是挺大的,那如何判断是否正常,我们可以利用命令 clients list,来输出连接的详细信息,比如IP,执行的是什么命令等;
比如下面的命令结果,基本都是在执行ping,auth命令,是因为公司几十个服务都在连接一个Redis集群,客户端有开启连接检测功能,还有就是集群之间的通讯等维持着一定的连接数,所以整体是正常的;
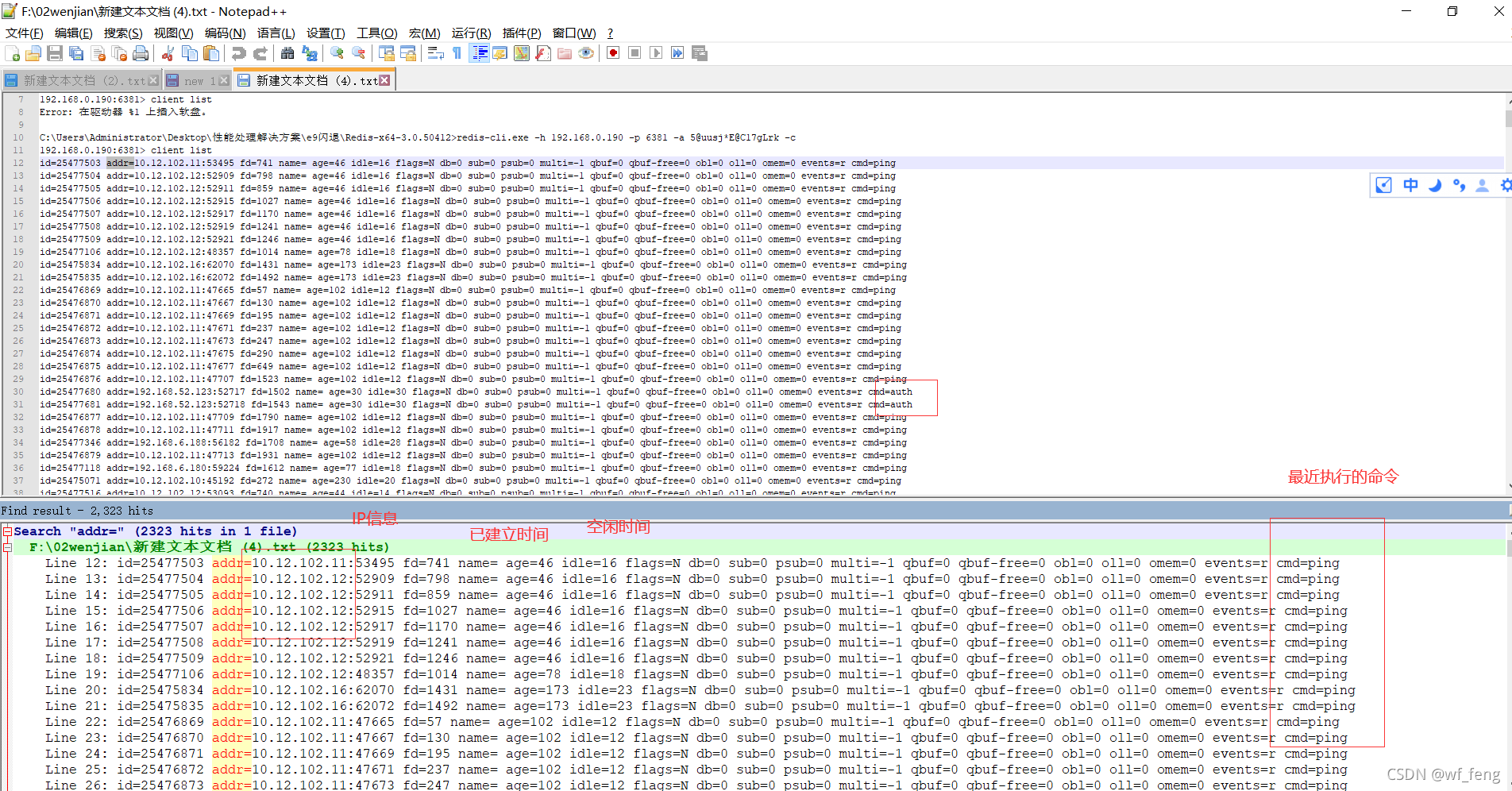
如何判断有异常,主要是看这些连接是否是空闲很长的,即上面截图的idle=,空闲异常长极大说明连接泄漏了;
临时的解决方案:
修改redis.conf 里面的 time out 参数,使redis服务器主动断开连接;
然后看这个cmd= 一般是什么命令,结合redis操作的相关代码,进行排查;
另外此处还有一个性能点,也就是输入缓冲区和输出缓冲区的问题;案例后续下文可见monitor命令导致内存问题;
Redis5.0关于INFO命令Clients模块缓存统计的优化https://www.cnblogs.com/chou1214/p/14470057.html
四、内存问题
- 内存不足,频繁置换到swap
redis读写慢,磁盘io读写比内存读写慢很多;
如何判断使用了swap:
当 used_memory > used_memory_rss,这时Redis已经在使用SWAP,运行性能会受到影响;
或者当 mem_fragmentation_ratio < 1的时候;
192.168.0.190:6381> info memory
# Memory
used_memory:166958840 ## 是Redis使用的内存总量,它包含了实际缓存占用的内存和Redis自身运行所占用的内存(如元数据、lua)。它是由Redis使用内存分配器分配的内存,所以这个数据并没有把内存碎片浪费掉的内存给统计进去
used_memory_human:159.22M ##redis现在占用的内存,有可能包括SWAP虚拟内存。
used_memory_rss:196255744 ##从操作系统上显示已经分配的内存总量。或者系统已分配的内存
used_memory_rss_human:187.16M ## 好看点的方式展示内存使用M为单位
used_memory_peak:247161800 ##redis的内存消耗峰值(以字节为单位)
used_memory_peak_human:235.71M
used_memory_peak_perc:67.55% ##used_memory_peak_perc:使用内存达到峰值内存的百分比,即(used_memory/ used_memory_peak) *100%
used_memory_overhead:55086750
used_memory_startup:6802568
used_memory_dataset:111872090
used_memory_dataset_perc:69.85%
total_system_memory:33566666752
total_system_memory_human:31.26G
used_memory_lua:83968
used_memory_lua_human:82.00K
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction ##淘汰策略
mem_fragmentation_ratio:1.18 ##内存的碎片率,used_memory_rss/used_memory --4.0版本之后可以使用memory purge手动回收内存
mem_allocator:jemalloc-4.0.3
active_defrag_running:0 ##表示没有活动的defrag任务正在运行,1表示有活动的defrag任务正在运行(defrag:表示内存碎片整理)
lazyfree_pending_objects:0 ##表示redis执行lazy free操作,在等待被实际回收内容的键个数
192.168.0.190:6381>
解决方案:
1. 适当增加内存,限制maxmemory,调整合适的内存置换策略;
2. 分析rdb文件,排查是哪些key占用始终在占用内存,是否正常;可参考前面的
-
内存不足,缓存key频繁置换出内存
会导致应用慢即缓存命中率低,Redis的频繁写;
如何判断有key被置换出内存了:
可以通过info stats命令结果的 evicted_keys 的值来判断,该值表示因为maxmemory限制导致key被回收删除的数量,回收key的情况只会发生在设置maxmemory值后,不设置会发生内存交换;
当置换的key的数量已经很接近于dbsize的数量,说明内存置换很频繁;解决方案:
- 适当增加内存,限制maxmemory,调整合适的内存置换策略;
- 分析rdb文件,排查是哪些key占用始终在占用内存,是否正常;可参考前面的
-
内存碎片问题及解决方案
这个我个人认为是很难调优的,但是可以做的处理是 处理更新频繁的bigkey,不适合放缓存;
redis内存碎片产生原因及解决方案https://www.manongdao.com/article-2429933.html
可缓解内存碎片率的方案(Redis4以后):
Redis专门为自动内存碎片清理机制提供参数设置。可以通过设置参数,来控制碎片清理的开始和结束时机,以及占用的CPU比例,从而减少碎片清理对Redis请求处理的性能影响。
首先,开启自动内存碎片清理:
config set activedefrag yes
然后,设置触发内存清理的条件:
active-defrag-ignore-bytes 100mb:表示内存碎片的字节数达到100MB时,开始清理;
active-defrag-threshold-lower 10:表示内存碎片空间占操作系统分配给Redis的总空间比例达到10%时,开始清理。
最后,控制清理操作占用CPU时间比例的上、下限:
active-defrag-cycle-min 25: 表示自动清理过程所用CPU时间的比例不低于25%,保证清理能正常开展;
active-defrag-cycle-max 75:表示自动清理过程所用CPU时间的比例不高于75%,一旦超过,就停止清理,从而避免在清理时,大量的内存拷贝阻塞Redis,导致响应延迟升高。
五、持久化问题
Redis的持久化的两种方式:
- RDB
- AOF
详情可以参考博客 RDB及AOF流程https://www.cnblogs.com/iamsach/p/8490387.html
这两种持久化来看,都有一个比较共性的性能点,即Fork子进程的过程,RDBFork子进程、AOF重写Fork子进程;
主进程创建子进程,会调用操作系统提供的 fork 函数。
而fork 在执行过程中,主进程需要拷贝自己的内存页表给子进程,如果这个实例很大,那么这个拷贝的过程也会比较耗时。
而且同时这个 fork 过程会消耗大量的 CPU 资源,在完成 fork 之前,整个 Redis 实例会被阻塞住,无法处理任何客户端请求。如果此时你的 CPU 资源本来就很紧张,那么 fork 的耗时会更长,甚至达到秒级,这会严重影响 Redis 的性能。
如何确定Fork子进程带来影响:
执行INFO命令,里面的Stats域有 latest_fork_usec 即标识上一次 fork 耗时,单位微秒;
这个时间就是主进程在 fork 子进程期间,整个实例阻塞无法处理客户端请求的时间。如果你发现这个耗时很久,就要警惕起来了,这意味在这期间,你的整个 Redis 实例都处于不可用的状态。
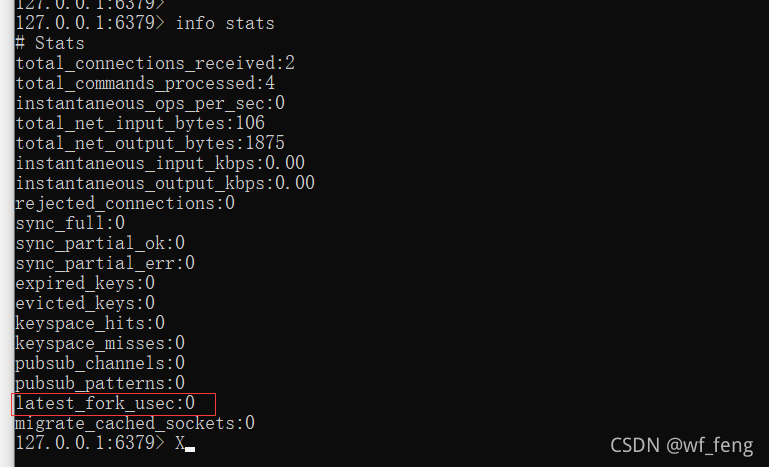
另外还有一个就是RDB会把Redis的内存快照写入磁盘,这个过程磁盘IO是很讲究的;虽然这个过程不阻塞Redis的进程,但是该服务器上如果有其他实例或者服务,就会收到影响;比如前段时间排查的一个案例,特有意截图了下,可参考下述第六章的案例演示,RDB引起的磁盘IO负载高问题;
还有什么地方会有RDB的操作:
除了数据持久化会生成 RDB 之外,当主从节点第一次建立数据同步时,主节点也创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响;
还有就是手动的执行save命令或者bgsave命令,一般是用于运维备份使用;备份 缓存场景是否有必要性?
解决方案:
1. 控制 Redis 实例的内存:尽量在 10G 以下,执行 fork 的耗时与实例大小有关,实例越大,耗时越久
2. 合理配置数据持久化策略:在 slave 节点执行 RDB 备份,推荐在低峰期执行,而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭 AOF 和 AOF rewrite
3. Redis 实例不要部署在虚拟机上:fork 的耗时也与系统也有关,虚拟机比物理机耗时更久
4. 降低主从库全量同步的概率:适当调大 repl-backlog-size 参数,避免主从全量同步
六、案例现场演示,一起分析;待完善
案例一:RDB引起的linux IO负载高问题,https://blog.csdn.net/wf_feng/article/details/121182522;
案例二:redis Timeout wait for idle object问题排查,https://blog.csdn.net/wf_feng/article/details/121046703?spm=1001.2014.3001.5501
案例三:
七、总结一份关于Redis变慢的Checklist
- 获取Redis实例在当前环境下的基线性能来判断是否慢了。
- 是否用了慢查询命令?如果是的话,就使用其他命令替代慢查询命令,或者把聚合计算命令放在客户端做。
- Fork子进程耗时;
- 并发是不是很高,每秒的查询数量;
- 网络流量是否峰值;
- 内存满了,发生了swap置换
- 是否存在bigkey?
- Redis AOF配置级别是什么?业务层面是否的确需要这一可靠性级别?如果我们需要高性能,同时也允许数据丢失,可以将配置项no-appendfsync-on-rewrite设置为yes,避免AOF重写和fsync竞争磁盘IO资源,导致Redis延迟增加。当然, 如果既需要高性能又需要高可靠性,最好使用高速固态盘作为AOF日志的写入盘。
- 在Redis实例的运行环境中,是否启用了透明大页机制?如果是的话,直接关闭内存大页机制就行了。
- 是否运行了Redis主从集群?如果是的话,把主库实例的数据量大小控制在2~4GB,以免主从复制时,从库因加载大的RDB文件而阻塞。