一、性能问题
1、概述
Redis使用的是客户端-服务端这种CS模型和请求/响应的TCP服务器。这意味着通常情况下一个请求会遵循以下步骤:
- 客户端向服务端发送一个请求,并监听SOCKET返回,通常是阻塞模式,等待服务端响应。
- 服务端处理客户端发来的命令并进行处理,最终将结果返回给客户端。
redis确实是非阻塞,但是redis服务端处理是非阻塞,用户端来讲还是阻塞。
至于redis为什么这么快,可以看这个一文带你彻底掌握Redis为什么这么快?
2、举例
也就是说一个客户端可以通过一个socket连接发起多个请求命令,每个请求命令发出后客户端通常会阻塞并等待redis服务器处理,redis处理完请求命令后会将结果通过响应报文返回给客户端。因为当执行多条命令的时候都需要等待上条命令执行完毕才能执行,比如:
set k1 1
keys *
get k1
Redis采取IO由于通信会有网络延迟,假如 client 和 server 之间的包传输时间需要0.125秒。那么上面的三个命令6个报文至少需要0.75秒才能完成。这样即使 redis 每秒能处理100个命令,而我们的 client 也只能一秒钟发出四个命令。这显然没有充分利用 redis 的处理能力。
二、什么是Pipeline
我们已经知道上面的问题了,也知道性能是耗费再了通信上,这时候pipeline横空出世,他的目的是将一批命令打包到一个内部维护的queue里,然后建立socket与server交互,这时候是只会发送一次命令,也就是只会交互一次,然后queue内的命令都执行完后会一起返回结果,这样大大减少了通信的次数,自然降低了通信所耗费的时间。queue是先进先出,所以可以保证执行顺序。
三、说明
并不是pipeline就无敌了,以后都用这个。这需要看需求的。比如你的需求get key 实时性很高,而且要用他的返回值做处理。那你把get key这个命令与其他100个命令放到一起去批处理进行,那反而在业务角度分析,效率更为低下。
四、测试
如下demo是从https://blog.csdn.net/u011489043/article/details/78769428这个地址而来,如有侵权请联系我~
/*
* 测试普通模式与 PipeLine 模式的效率:
* 测试方法:向 redis 中插入 10000 组数据
*/
public static void testPipeLineAndNormal(Jedis jedis) throws InterruptedException {
Logger logger = Logger.getLogger("javasoft");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
jedis.set(String.valueOf(i), String.valueOf(i));
}
long end = System.currentTimeMillis();
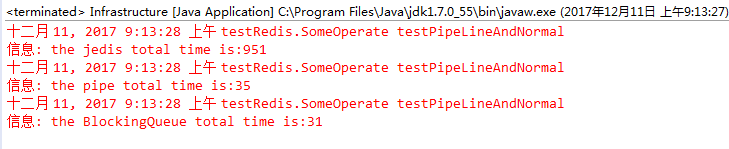
logger.info("the jedis total time is:" + (end - start));
Pipeline pipe = jedis.pipelined(); // 先创建一个 pipeline 的链接对象
long start_pipe = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
pipe.set(String.valueOf(i), String.valueOf(i));
}
pipe.sync(); // 获取所有的 response
long end_pipe = System.currentTimeMillis();
logger.info("the pipe total time is:" + (end_pipe - start_pipe));
BlockingQueue<String> logQueue = new LinkedBlockingQueue<String>();
long begin = System.currentTimeMillis();
for (int i = 0; i < 10000; i++) {
logQueue.put("i=" + i);
}
long stop = System.currentTimeMillis();
logger.info("the BlockingQueue total time is:" + (stop - begin));
}
五、使用场景
不适用场景:
- 要求可靠性高,每次都需要实时知道这次操作是否成功,数据是否写入redis了等对实时性的这种需求都不适合。
适用场景:
- 对实时性要求不高的
- 批量的将数据写入 redis,允许一定比例的写入失败
比如群发短信、邮件这种,失败了我补偿,我不需要及时知道发送结果的,这种用pipeline合适 。
六、总结
- 什么是Pipeline
- Pipeline可以性能调优
- 使用场景
