问题:需要提取 “既往史:”后面的所有文字内容:
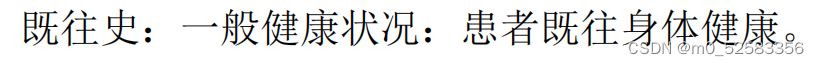
若使用:
.split(':’)
则将此句按两个分号,分为三个部分。
所以使用:
.split(':', 1)
”1“为分割次数,默认为-1,即分割所有,在此处设置为1, 即可将此句分为1+1=2个部分,
即得到:
既往史:
一般健康状况:患者既往身体健康。
问题:需要提取 “既往史:”后面的所有文字内容:
若使用:
.split(':’)
则将此句按两个分号,分为三个部分。
所以使用:
.split(':', 1)
”1“为分割次数,默认为-1,即分割所有,在此处设置为1, 即可将此句分为1+1=2个部分,
即得到:
既往史:
一般健康状况:患者既往身体健康。