文章目录
前言
1、正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
2、Python中我们经常用match、search、findall函数搭配使用快速获取关键字符串。
一、正则表达式
1、元字符详解
pattern:匹配的关键字
| 元字符 | 描述 |
|---|---|
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。 |
| ^ | 匹配输入字行首。 |
| $ | 匹配输入行尾。 |
| * | 匹配0个或多个表达式。例:表达式 zo*能匹配“z”,也能匹配“zo”以及“zoooo…”。因为o可以是0个,也可以是多个。 |
| + | 匹配1个或多个表达式。例:表达式zo+能匹配“zo”以及“zoooo…”,但不能匹配“z”。因为o最少有1个。 |
| ? | 匹配0个或1个表达式。例:表达式zo?能匹配“z”以及“zo”,因为o可以存在0个或1个。 |
| {n} | 匹配字符n次。例:表达式o{2}能匹配“food”中的两个o。 |
| {n,} | 匹配字符至少n次。表达式o{2,}能匹配“foooood”中的所有o,不能匹配“fod”中的“o”,因为fod中只有1个o,而o{2,}要求2个o以上。 |
| {n,m} | 匹配字符最少n次且最多匹配m次。例如表达式o{1,3}能匹配“fod”,“food”以及“foood”,o存在1次或3次。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| . | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。 |
| (?=pattern) | 正向先行断言,匹配后面有pattren的内容,例:表达式\S(?=你),能匹配“我爱你”中的“爱”,因为“爱”的后面有“你”所以被成功匹配。(\S表示匹配任何可见字符) |
| (?!pattern) | 负向先行断言,匹配后面没有pattren的内容,例:表达式\S(?!你),无法匹配“我爱你”中的“爱”,我需要匹配的是字符后面没有“你”的内容。(\S表示匹配任何可见字符) |
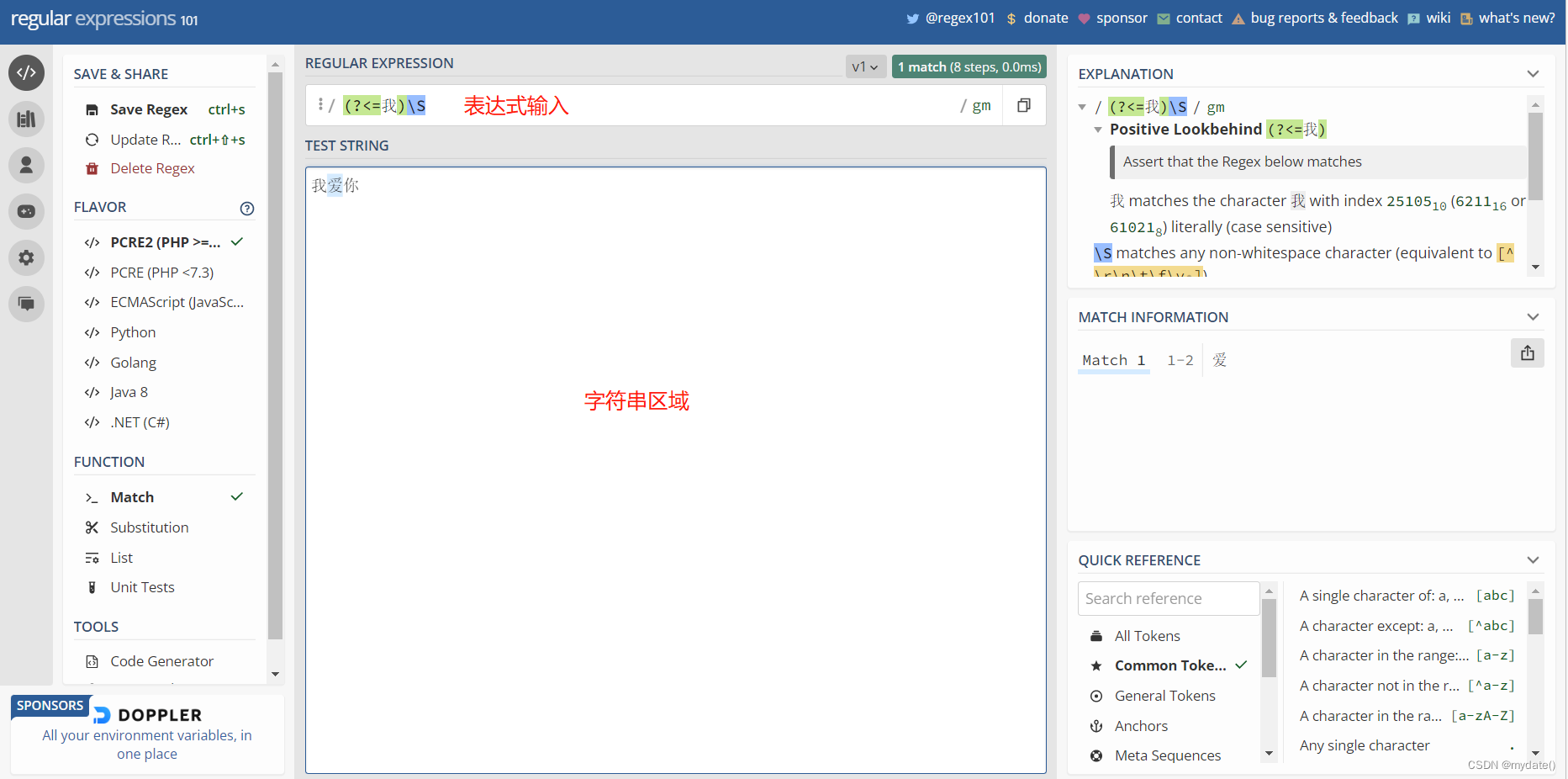
| (?<=pattern) | 正向后行断言,,匹配前面有pattren的内容,例:表达式(?<=我)\S,能匹配“我爱你”中的“爱”,因为“爱”的前面有“我”所以被成功匹配。(\S表示匹配任何可见字符) |
| (?<!pattern) | 负向后行断言,匹配前面没有pattren的内容,例:表达式\S(?!我),无法匹配“我爱你”中的“爱”,我需要匹配的是字符后面没有“我”的内容。(\S表示匹配任何可见字符) |
| x|y | 匹配x或y。例如,表达式“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。 |
| \n | 匹配一个换行符。 |
| \r | 匹配一个回车符。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等。 |
| \S | 匹配任何可见字符。 |
| \t | 匹配一个制表符。 |
| \v | 匹配一个垂直制表符。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9]”,这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| < > | 匹配词(word)的开始(<)和结束(>)。例如正则表达式<the>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(or)运算。 |
2、等价方法(速记)
一、等价:
等价是等同于的意思,表示同样的功能,用不同符号来书写。
?,*,+,\d,\w 都是等价字符
?等价于匹配长度{
0,1}
*等价于匹配长度{
0,}
+等价于匹配长度{
1,}
\d等价于[0-9]
\D等价于[^0-9]
\w等价于[A-Za-z_0-9]
\W等价于[^A-Za-z_0-9]。
二、常用运算符与表达式:
^ 开始
()域段
[] 包含,默认是一个字符长度
[^] 不包含,默认是一个字符长度
{
n,m} 匹配长度
. 任何单个字符(\. 字符点)
| 或
\ 转义
$ 结尾
[A-Z] 26个大写字母
[a-z] 26个小写字母
[0-9] 0至9数字
[A-Za-z0-9] 26个大写字母、26个小写字母和0至9数字
二、常用的表达式
1、常用的正则表达式
常见的正则表达式
1.验证用户名和密码:("[a-zA-Z]\w{5,15}")正确格式:"[A-Z][a-z]_[0-9]"组成,并且第一个字必须为字母6~16位;
2.验证电话号码:("(\d{3,4}-)\d{7,8}")正确格式:xxx/xxxx-xxxxxxx/xxxxxxxx;
3.验证手机号码(包含虚拟号码和新号码段):"1([38][0-9]|4[5-9]|5[0-3,5-9]|66|7[0-8]|9[89])[0-9]{8}";
4.验证身份证号(15位):"\d{14}[[0-9],0-9xX]",(18位):"\d{17}(\d|X|x)";
5.验证Email地址:("\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*");
6.只能输入由数字和26个英文字母组成的字符串:("[A-Za-z0-9]+");
7.整数或者小数:[0-9]+([.][0-9]+){
0,1}
8.只能输入数字:"[0-9]*"。
9.只能输入n位的数字:"\d{n}"。
10.只能输入至少n位的数字:"\d{n,}"。
11.只能输入m~n位的数字:"\d{m,n}"。
12.只能输入零和非零开头的数字:"(0|[1-9][0-9]*)"。
13.只能输入有两位小数的正实数:"[0-9]+(\.[0-9]{2})?"。
14.只能输入有1~3位小数的正实数:"[0-9]+(\.[0-9]{1,3})?"。
15.只能输入非零的正整数:"\+?[1-9][0-9]*"。
16.只能输入非零的负整数:"\-[1-9][0-9]*"。
17.只能输入长度为3的字符:".{3}"。
18.只能输入由26个英文字母组成的字符串:"[A-Za-z]+"。
19.只能输入由26个大写英文字母组成的字符串:"[A-Z]+"。
20.只能输入由26个小写英文字母组成的字符串:"[a-z]+"。
21.验证是否含有^%&',;=?$\"等字符:"[%&',;=?$\\^]+"。
22.只能输入汉字:"[\u4e00-\u9fa5]{0,}"。
23.验证URL:"http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?"。
24.验证一年的12个月:"(0?[1-9]|1[0-2])"正确格式为:"01"~"09"和"10"~"12"。
25.验证一个月的31天:"((0?[1-9])|((1|2)[0-9])|30|31)"正确格式为;"01"~"09"、"10"~"29"和“30”~“31”。
26.获取日期正则表达式:\\d{
4}[年|\-|\.]\d{
\1-\12}[月|\-|\.]\d{
\1-\31}日?
评注:可用来匹配大多数年月日信息。
27.匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
28.匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
29.匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</>|<.*? />
30.匹配首尾空白字符的正则表达式:\s*|\s*
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
31.匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
32.匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):[a-zA-Z][a-zA-Z0-9_]{
4,15}
评注:表单验证时很实用
33.匹配腾讯QQ号:[1-9][0-9]{
4,}
34.匹配中国邮政编码:[1-9]\\d{
5}(?!\d)
评注:中国邮政编码为6位数字
35.匹配ip地址:([1-9]{
1,3}\.){
3}[1-9]。
评注:提取ip地址时有用
36.匹配MAC地址:([A-Fa-f0-9]{
2}\:){
5}[A-Fa-f0-9]
37.匹配括号内的内容(懒惰匹配):\((.*?)\)
38.匹配括号内的内容(贪婪匹配):\((.*)\)
2、先行断言和后行断言
在使用正则表达式的过程中发现先行断言和后行断言比较好用,但是也比较难理解,这里刚好做一下解释。
1)正向先行断言:(?=pattren)
正向先行断言,匹配后面有pattren的内容。
如何匹配python yyds,what is the python中第一个python?这时可以用到正向先行断言。

根据上图,因为第一个python 的后面紧接着yyds,因此直接使用.*(?=yyds),就能直接匹配到第一个python 。
2)负向先行断言:(?!pattren)
负向先行断言,匹配后面没有pattren的内容。
如何匹配python yyds,what is the pycharm中含有py的pycharm,这时可以用到负向先行断言。
 根据上图,py后面没有thon的只有
根据上图,py后面没有thon的只有pycharm 。
3)正向后行断言:(?<=pattren)
正向后行断言,匹配前面有pattren的内容。
如何匹配python yyds,what is the pycharm中前面有python的内容,这时可以用到正向后行断言。

根据上图,前面有python的字符串为 yyds,what is the pycharm。
4)负向后行断言:(?<!pattren)
负向后行断言,匹配字符串前面没有pattren的内容。
如何匹配python yyds,what is the pycharm yyds中前面没有python 的yyds,这时可以用到负向后行断言。

根据上图,前面没有python的yyds为pycharm之后的yyds。
.*是匹配所有(除换行符外)的所有字符串。
三、Python匹配函数
注:使用这三个函数需要使用re库
1、Match函数
1)re.match函数介绍
re.match从字符串的起始位置开始匹配,如果没有在起始位置匹配成功的话则会返回None。
import re
#如果成功匹配字符串会返回一个对象,如果没有则会返回None;
matchobj = re.match(pattern,string,flags=0)
参数
1)pattern:匹配的正则表达式
2)string:需要匹配的字符串
3)flags参数:标志位,用于选择正则表达式的匹配方式(大小写,多行匹配)
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和#后面的注释
#返回结果的调用方法
matchobj.groups()
matchobj.group(num=0)
matchobj.span()
2)re.match函数方法案例
import re
#re.match方法
#注意1:group用法
string="python yyds"
matchobj = re.match("python",string)
print(matchobj.group(0))
>>>python
#注意2:需要从字符串开始的地方匹配
string="python yyds"
matchobj = re.match("yyds",string)
print(matchobj.group(0))
>>>AttributeError: 'NoneType' object has no attribute 'group'
#re.match是从字符串的起始位置开始匹配,如果字符串开始未匹配到字符串,则会报错。
#注意3:需要优化一下
string="python yyds"
matchobj = re.match("Python",string,re.I)
#如果没有匹配到结果就使用matchobj.group(0)属性报错。
if matchobj:
print(matchobj.group(0))
#注意4:flags大小写设置
string="python yyds"
matchobj = re.match("Python",string,re.I)
if matchobj:
print(matchobj.group(0))
>>>python
#这里匹配到了python,因为re.I忽略大小写匹配。
2、Search函数
1)Search函数介绍
re.search扫描整个字符串并返回第一个成功的匹配;re.search和re.match的区别在于re.match只匹配字符串的开始,如果开始匹配不上,则匹配失败;而re.search从任何地方找。
import re
#同样的正则表达式,看看re.match和re.search的区别
#re.match
string="python yyds"
matchobj = re.match("yyds",string)
if matchobj:
print(matchobj.group(0))
>>>AttributeError: 'NoneType' object has no attribute 'group'
#re.match是从字符串的起始位置开始匹配,如果字符串开始未匹配到字符串,则会报错。
#re.search
string="python yyds"
matchobj = re.search("yyds",string)
if matchobj:
print(matchobj.group(0))
>>>yyds
3、Findall函数
1)Findall函数介绍
re.findall会返回所有匹配到的结果,匹配的结果为列表(,re.findall与search、match的区别在于:search和match是一次匹配,找到后返回匹配对象;而findall则会多次匹配,返回匹配列表。
import re
string = "python is the best language,python yyds"
matchobj = re.findall("python",string)
if matchobj is not None:
print(matchobj)
print(matchobj[0])
>>>['python', 'python']
>>>python
四、regex101网站推荐
在这个网站可以输入正则表达式来匹配函数,能够快速匹配到结果,非常好用。