文章目录
什么是隐私求交PSI
隐私求交是多方安全计算中的密码学技术,它允许数据持有方通过比较加密集合计算得到交集,且任何一方都不会获得其他信息。PSI还存在一种变体,即CS场景。客户端可以获取其与服务器的交集但是服务器无法学习到该集合。如果在一个小的可以预测的域上通过密码哈希比较数据集合,应该采取预防措施来防止字典攻击。
PSI在日常生活中也有许多应用案例。Apple 在密码监控中使用了这种技术。 它已提议将该技术用于其宣布的扩大对儿童的保护。
PSI协议分类
根据数据的托管方式,PSI 协议可分为两大类:传统 PSI 和 委托 PSI。
- 在传统的 PSI 类别中,数据所有者直接相互交互,并且在计算时需要拥有其集合的副本,参考论文《Efficient Private Matching and Set Intersection》。
- 在委托 PSI 中,PSI 的计算和/或集合的存储可以委托给第三方服务器(它本身可能是被动或主动的对手)。 委托 PSI 类别可以进一步分为两类:(a) 支持一次性委托的类别,以及 (b) 支持重复委托的类别。 支持一次性委托的 PSI 协议要求数据所有者重新编码其数据并将编码后的数据发送到服务器以进行每次计算。 那些支持重复委托的允许数据所有者只将他们的(加密的)数据上传到服务器一次,然后在服务器之外的每次计算中多次重复使用它。
最近,研究人员提出了一种支持数据更新的 PSI 协议变体(包括传统类别和委托类别。 这种类型的 PSI 协议允许数据所有者以低开销和保护隐私的方式将集合元素插入/删除其数据。参考论文《Updatable Private Set Intersection》、《Multi-party Updatable Delegated Private Set Intersection》。
PSI算法的分类
PSI算法大致可用分为以下4类。
-
基于哈希函数的PSI算法:这类算法使用哈希函数对数据集中的元素进行哈希,并将哈希值发送给其他参与方进行比对。其中一种常见的算法是Bloom Filter,它使用多个哈希函数将元素映射到一个位向量中。该类型的方法是一种不安全的交集协议,当双方输入域很小的时候,存在字典攻击的风险。
-
基于不经意传输(OT)的 PSI算法:这类算法利用零知识证明或者类似的技术,使得参与方可以获取另一方拥有的特定元素,而不了解其他元素的信息。最早提出基于OT的PSI算法是在2014年《Faster Private Set Intersection Based on OT Extension》中。在安全的PSI算法中,基于OT的PSI算法是最快速的,但是通信代价并不是最低的。
-
基于GC PSI算法:该算法采用Garbled Circuit(GC)协议作为核心方法,并结合了OT协议来实现PSI。此类协议的每一个交集内元素会带有一个“负载”(payload),可以用来计算交集的一些函数。然而,基于GC方案的性能与其他类型的方案相比仍有较大差距,随着数据规模的增加,电路深度不断增加,导致电路规模快速膨胀,通信、计算、内存开销都随之膨胀。基于GC的PSI方案虽然不如基于OT的PSI算法快速高效,但是其更灵活,并且可以轻松适应计算集合交集功能的变体。
-
基于公钥加密的PSI算法:在基于公钥的PSI算法中,参与方通常采用非对称加密算,如RSA、椭圆曲线或同态加密技术将隐私集合中的原始进行加解密计算,找到共同的元素。基于公钥的PSI算法是相对安全且通信消耗最少的PSI算法。
-
基于差分隐私的PSI算法:为了防止PSI结果的隐私泄露,提出了交集满足差分隐私的方法,即在PSI结果中添加一定要求的噪声,从而保证敌手无法通过交集结果推测数据集合。交集满足差分隐私广泛应用于数据分析场景,比如社交网络分析、医疗研究、用户行为分析等。基于差分隐私的PSI方案在前述的PSI算法中提供了对结果的安全保护,具有更严格的隐私保护。可以通过需求调整噪声参数平衡隐私保护和数据准确性要求。
基于哈希函数的PSI算法
基于哈希函数的PSI(Private Set Intersection)算法主要包括以下几种常见算法:
-
Bloom Filter:Bloom Filter是一种经典的基于哈希函数的PSI算法。它使用多个哈希函数对数据集中的元素进行哈希,并将哈希值映射到一个位向量中。通过比对位向量,可以确定两个数据集之间的交集元素。参考文献《Private set intersection with Bloom filters》进行详细了解。
-
Count-Min Sketch:Count-Min Sketch是一种概率型数据结构,常用于基于哈希函数的PSI算法。它利用多个哈希函数将元素映射到一个二维计数表中,通过对计数进行累加,可以估计元素的出现频率。在PSI中,Count-Min Sketch可以用于判断两个数据集是否存在交集。参考文献《 An improved data stream summary: the CountMin sketch and its applications》。
-
Cuckoo Filter:Cuckoo Filter是一种近似集合成员检测的数据结构,也可以应用于基于哈希函数的PSI算法。它使用两个哈希函数将元素映射到一个哈希表中,通过检查哈希表中的位来判断元素是否存在。参考文献《Efficient Circuit-based PSI via Cuckoo Hashing》。
-
MinHash:MinHash是一种用于近似计算集合相似度的算法,也可以用于PSI。它通过将元素进行哈希,选择哈希值中的最小值,将最小值组成一个签名,通过比对签名来判断集合之间的交集。参考文献《EsPRESSo: Efficient Privacy-Preserving Evaluation of Sample Set Similarity∗》。
基于哈希的PSI算法,由于需要随时随机访问操作,所以需要将过滤器全部存储在内存中,所以会占用一定的内存空间。基于布谷鸟哈希的PSI算法空间占用优于基于布隆过滤的PSI算法方案。
基于不经意传输(OT)的 PSI算法
基于OT的PSI算法流程如下:
假设有两个集合 A A A和 B B B,其中 A A A包含元素 a 1 , a 2 , . . . , a n a_1,a_2,...,a_n a1,a2,...,an; B B B包含元素 b 1 , b 2 , . . . , b m b_1,b_2,...,b_m b1,b2,...,bm。使用OT方式计算PSI,相当于求解 m m m 次 ( N 1 ) O T \binom{N}{1} OT (1N)OT 问题,其中 B B B 中的元素 b i b_i bi 就是每次的选择队列。
基于OT的PSI算法可以分为以下几类:
-
基于哈希技术的OT PSI算法:该算法利用哈希函数来生成OT所需的参数,并使用它们执行OT协议,该算法可以降低通信次数到 O ( n l o g n ) O(nlogn) O(nlogn)。参考文献《Phasing: Private Set Intersection using Permutation-based Hashing》。
-
基于伪随机函数(Pseudo Random Function, PRF)的OT PSI算法:该算法使用PRF来生成OT所需的参数,然后利用这些参数执行OT协议来实现PSI,该算法为KKRT PSI 算法。参考文献2016年《Efficient batched oblivious PRF with applications to private set intersection》,该算法是将《Phasing: Private Set Intersection using Permutation-based Hashing》中的组件使用BaRK-OPRF(来源于IKNP OT)进行替换,从而提高了长数据和大数据集的效率,比起高2.3至3.6倍。
-
基于承诺方案(Commitment Scheme)的OT PSI算法:该算法使用承诺方案来实现随机选择,然后利用这些随机数执行OT协议来实现PSI。参考文献《Malicious-Secure Private Set Intersection via Dual Execution》(该算法目前是恶意敌手模型下最快的PSI算法)、《Actively Secure 1-out-of-N OT Extension with Application to Private Set Intersection》。
-
基于Bloom Filter的PSI算法:Bloom Filter是一种可以高效地判断某个元素是否在集合中的数据结构。这类算法使用Bloom Filter存储集合元素的哈希值,从而减少通信和计算成本。该想法首先通过《Fast private set operations with sepia》提出。在《Outsourced private set intersection using homomorphic encryption》中又将Bloom Filter与同态加密方法进行结合。为了解决论文上述两篇文章中的安全和效率问题,《When Private Set Intersection Meets Big Data: An Efficient and Scalable Protocol》提出一种Oblivious Bloom Filter算法,在该算法中,客户端使用Bloom Filter(BF)对其私有集进行编码,服务端使用GBF(Garbled Bloom Filter)对其私有集合进行编码,再通过OT协议进行求交运算。该算法有标准和增强版本,可以从半诚实敌手模型扩展到敌手模型。该算法拥有较好的效率,计算 200 万个元素集的交集,在并行模式下的中等硬件上仅需要 41 秒(80 位安全性)和 339 秒(256 位安全性)。在《Quantum private set intersection cardinality based on bloom filter》中还提出了抗量子攻击的基于Bloom Filter的PSI算法。
《When Private Set Intersection Meets Big Data: An Efficient and Scalable Protocol》的硬件配置:服务器是 Mac Pro,配备 2 个 Intel E5645 6 核 2.4GHz CPU、32 GB RAM,运行 Mac OS X 10.8。 客户端是一台 Macbook Pro 笔记本电脑,配备 Intel 2720QM 四核 2.2 GHz CPU、16 GB RAM,运行 Mac OS X 10.7。 两台电脑通过1000M以太网连接。
基于GC的PSI算法
基于GC的PSI算法最早在2012年《Private set intersection_Are garbled circuits better than custom protocols?》中提出。该方案基于半诚实敌手模型,文中提出的基于GC的PSI算法主要思想是各方在本地对他们的集合进行排序,私下将他们的排序集合并到一个排序列表中。 然后不经意地比较每个相邻的元素对,如果该对中的元素相等,则保留该值,否则用虚拟值替换。 最后,在显示整个列表之前,所得到的匹配元素列表会被明显地打乱。 这个混洗步骤是必要的,因为否则有关匹配元素的位置信息会泄漏有关各方集合中不匹配元素的信息。该过程中,GC过程可以看作是一个黑盒。
基于GC的PSI算法由于比较和混洗步骤不同,其对应的复杂度也不相同。
- 比较算法Bitwise-AND(BWA),只适用于小数量级。
- 比较算法Pairwise-Compare (PWC) protocol,最坏的情况下复杂度是 Θ ( n 2 ) Θ(n^2) Θ(n2),其中 n n n 是输入数据集大小。
- 不经意洗牌算法Sort-Compare-Shuffle, 在小数量级的情况下是 Θ ( n log n ) Θ(n\log n) Θ(nlogn)。该算法的主要思想是各方在本地对他们的集合进行排序,然后(私下)将他们的排序集合并到一个排序列表中。
| Protocol | Number of Non-Free Gates |
|---|---|
| BWA | 2 σ 2^σ 2σ |
| PWC | ( ( 2 n − n ^ ) 2 + n ^ ) ( σ − 1 ) / 4 ((2n-\hat{n})^2+\hat{n})(σ-1)/4 ((2n−n^)2+n^)(σ−1)/4 |
| Sort-Compare-Shuffle-SORT | 2 σ n l o g ( 2 n ) + ( ( 3 n − 1 ) σ − n ) + 2 σ n l o g 2 ( 2 n ^ ) 2\sigma nlog(2n)+((3n−1)\sigma −n) + 2\sigma nlog^2(2\hat{n}) 2σnlog(2n)+((3n−1)σ−n)+2σnlog2(2n^) |
| Sort-Compare-Shuffle-HE | 2 σ n l o g ( 2 n ) + ( ( 3 n − 1 ) σ − n ) + ( σ + 32 ) n 2\sigma nlog(2n)+((3n−1)\sigma −n) + (\sigma +32)n 2σnlog(2n)+((3n−1)σ−n)+(σ+32)n |
| Sort-Compare-Shuffle-SORT | 2 σ n l o g ( 2 n ) + ( ( 3 n − 1 ) σ − n ) + σ ( n log n − n + 1 ) 3 2\sigma nlog(2n)+((3n−1)\sigma −n) + \frac{\sigma (n\log n-n+1)}{3} 2σnlog(2n)+((3n−1)σ−n)+3σ(nlogn−n+1) |
在GC中,计算过程需要转换为一系列的门,而门可以是 Free Gates 和 Non-Free Gates。Free Gates 表示计算结果直接从密文获得,不需要解密密钥,所以计算成本极低。而Non-Free Gates 表示具有更高的计算成本,Non-Free Gates越多,计算成本越高,所需计算量更大,所以Non-Free Gates的数量代表了GC的计算效率和速度。所以在GC中通过控制Non-Free Gates的数量可以优化GC的效率和速度。
为了解决基于GC的PSI算法中通信开销、计算和内存开销都较大的问题,有如下的改进方案提出:
-
基于哈希的改进算法:这类算法采用哈希函数将集合中的元素映射到一个固定长度的哈希值,并在比较时只比较哈希值,从而减少通信和计算成本。比如2015年的《Phasing: Private Set Intersection using Permutation-based Hashing》一文中通过应用Phasing(使用基于排列的散列来减少表示的位长度) 改进上述不经意洗牌过程,减低了Non-Free Gates的数量和电路门的深度,从而使得效率比Sort-Compare-Shuffle算法快5倍以上。2018年的《Efficient Circuit-Based PSI via Cuckoo Hashing》优化 Cuckoo 哈希算法,将参与方扩展到多方。
-
基于OT的改进算法:2019年Benny Pinkas等人通过《Efficient Circuit-based PSI with Linear Communication》一文提出了线性复杂度的基于GC的PSI算法。该算法基于用于计算不经意的可编程伪随机函数 (OPPRF) 的协议的使用,将多次调用 OPPRF 的成本分摊到一起,从而使得通信成本是线性的。
基于公钥加密的PSI算法
基于DH的PSI算法
基于DH的PSI算法是在通信条件受限下最好的PSI协议,参考《Enhancing privacy and trust in electronic communities》(1999年)。该算法流程是双方计算其集合中每个隐私元素的共享密钥值,并将该共享密钥值组成散列,接收方进行比较,得到对应的交集。《Private set intersection with ECDH》(2020年)通过将隐私集合中每个元素映射为椭圆曲线上的点后再计算对应的共享密钥散列,从而得到对应的交集。ECDH算法使用椭圆曲线只需要更小的私钥来实现相同级别的安全性。
基于RSA盲签名的PSI算法
2009年《Practical Private Set Intersection Protocols with Linear Computational and Bandwidth Complexity》中提出了基于RSA盲签名的PSI算法,该算法在上述DH-PSI算法基础上,通过盲签名机制对隐私元素进行盲化和签名,从而计算隐私集合交集。
基于同态加密的PSI算法
同态加密是一种加密技术,允许在密文状态下进行计算,而无需解密。这类算法使用同态加密技术对数据进行加密,并在加密状态下执行集合交集运算。代表性的同态加密算法包括基于Paillier、BGV、BFV同态加密的PSI算法。
-
首先将同态加密用于PSI的是在2004年《Efficient Private Matching and Set Intersection》中。该文提出了基于同态加密技术和平衡散列的PSI协议,可以对抗两方的恶意敌手模型。在半诚实敌手模型下,该算法中,双方首先通过多项式对数据集合中每项展开得到加密值 P ( y ) P(y) P(y),然后生成随机扰动 r r r,最后通过同态加得到每项的加密值 E n c ( r ⋅ P ( r ) + y ) Enc(r\cdot P(r)+y) Enc(r⋅P(r)+y)。在恶意安全模型下,客户端和服务端都增加一个 k c k_c kc和 k s k_s ks根校验,从而对抗恶意的客户端或服务端。
-
2010年《Efficient Set Operations in the Presence of Malicious Adversaries》提出了一种基于同态加密和零知识证明的方案,可以保证在恶意攻击者存在的情况下仍然能够保护集合的隐私并实现高效的集合操作。
-
《Fast Private Set Intersection from Homomorphic Encryption》(2017年)中提出了一种基于同态加密的高效私有集合交集算法,该算法使用 Paillier 同态加密算法对集合元素进行加密,并利用同态加法和同态乘法实现集合交集计算。该算法通过将批处理与布谷鸟散列和基于排列的散列结合使用优化同态加密算法,同时通过加窗和分区技术将同态加密的电路深度从原来的 O ( log N x ) O(\log N_x) O(logNx)降低到:
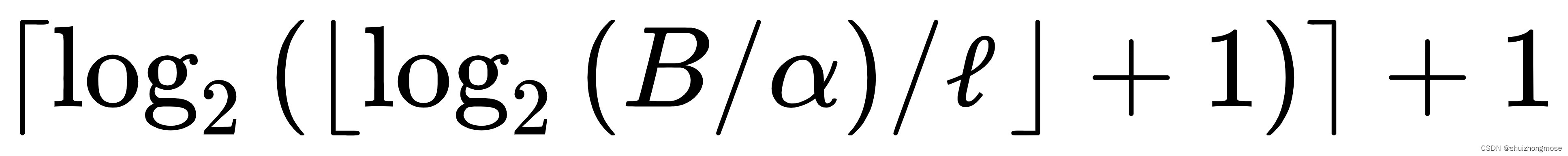
其中 N x N_x Nx 是 X X X 数据集大小, B B B是数据集切分之后的大小, α \alpha α 是电路切分后子集大小。
-
《Outsourced Private Set Intersection Using Homomorphic Encryption》(2017年)通过同态加密技术将集合交集计算任务安全地外包给第三方计算服务商,该算法具有较低的计算和通信开销,但是需要信任第三方计算服务商,并且在实现中需要解决数据隐私保护和安全性等问题。
-
《Private set intersection with linear communication from general assumptions》(2019年)提出了一种基于广义假设的线性通信私有集合交集算法,使用同态加密实现加密和计算,并通过引入新的技术,将通信复杂度降低到线性级别。
-
《Labeled PSI from Fully Homomorphic Encryption with Malicious Security》(2018)和《Labeled PSI from Homomorphic Encryption with Reduced Computation and Communication》(2021)分别实现了基于层次全同态的PSI算法。二者底层采用标记PSI(LPSI)技术,该技术为每个数据项增加标记,然后使用HE技术等进行加密。LPSI技术可以应用于有针对性的价格歧视、移动通信中的密钥检索等。二者都使用层次同态(leveled FHE)BFV或BGV算法(SEAL库),文章2通过改进SIMD打包技术,使用Paterson-Stockmeyer 算法降低计算复杂度,修改窗口技术降低通信成本,从而提高计算效率。
基于差分隐私的PSI算法
差分隐私最早是微软研究院Cynthia Dwork在2006年《Differential Privacy》中提出,该论文提出差分隐私算法的目的是为了防止恶意敌手从直方图、K-匿名化结果等中预测出其他隐私数据信息,从而造成数据库的隐私泄露。
2012年,《DJoin: Differentially Private Join Queries over Distributed Databases》首次将差分隐私应用用于PSI中,该论文提出的DJoin 可以支持许多 SQL 风格的查询,包括由不同实体维护的数据库的联接,只需要将原SQL转换为其对应的原语表达即可:BN-PSI-CA(私有集交集基数的差分私有形式)和 DCR(多方组合运算符,可以聚合噪声基数而不复合各个噪声项。2019年《Cheaper Private Set Intersection via Differentially Private Leakage》提出了一种用于恶意安全 2PC 中差分隐私泄露的安全模型,同时还引入了两种新的改进机制,用于“差分隐私直方图高估”,这是差分隐私 PSI 的主要技术挑战。2020年《Differentially Private Two-Party Set Operations》将差分隐私、同态加密和电路进行结合,使得通信复杂度能达到 O ( m ) O(m) O(m),其中 m m m是数据集最小的规模。2023年《Split, Count, and Share: A Differentially Private Set Intersection Cardinality Estimation Protocol》介绍了如何通过差分隐私PSI进行交集基数的估计,通过其测试结果,该算法可以较好地替代传统交集基数(PSI-CA)协议。
私有交集基数(PSI-CA)协议是计算两个隐私集合中同时存在的隐私元素数量,即这两个隐私集合的交集的大小。
总结
在实际应用中,需要权衡通信复杂度、计算复杂度、安全性要求:(1)如果网络是计算瓶颈,则可以考虑通信复杂度低的基于公钥加密的PSI算法;(2)如果计算资源是瓶颈可以考虑基于哈希或OT的PSI算法;(3)而对安全性较高的应用场景,推荐使用基于GC、同态和差分的PSI算法。同时,在考虑选择PSI的时候,需要考虑双方数据集大小是否一致,上述许多论文中的算法是在假设双方数据集一致的情况下(平衡PSI)。而非平衡PSI场景下,通信量和计算量一般是受数据集较大一方决定的。
目前PSI在社交网络中的关系路径发现、 僵尸网络检测、全测序人类基因组测试、接近度测试、在线作弊者检测游戏、情报收集等方面都有显著应用。