使用requests模块请求网页内容,经常会出现乱码,例如:
import requests
res = requests.get("https://www.baidu.com/")
print(res.text)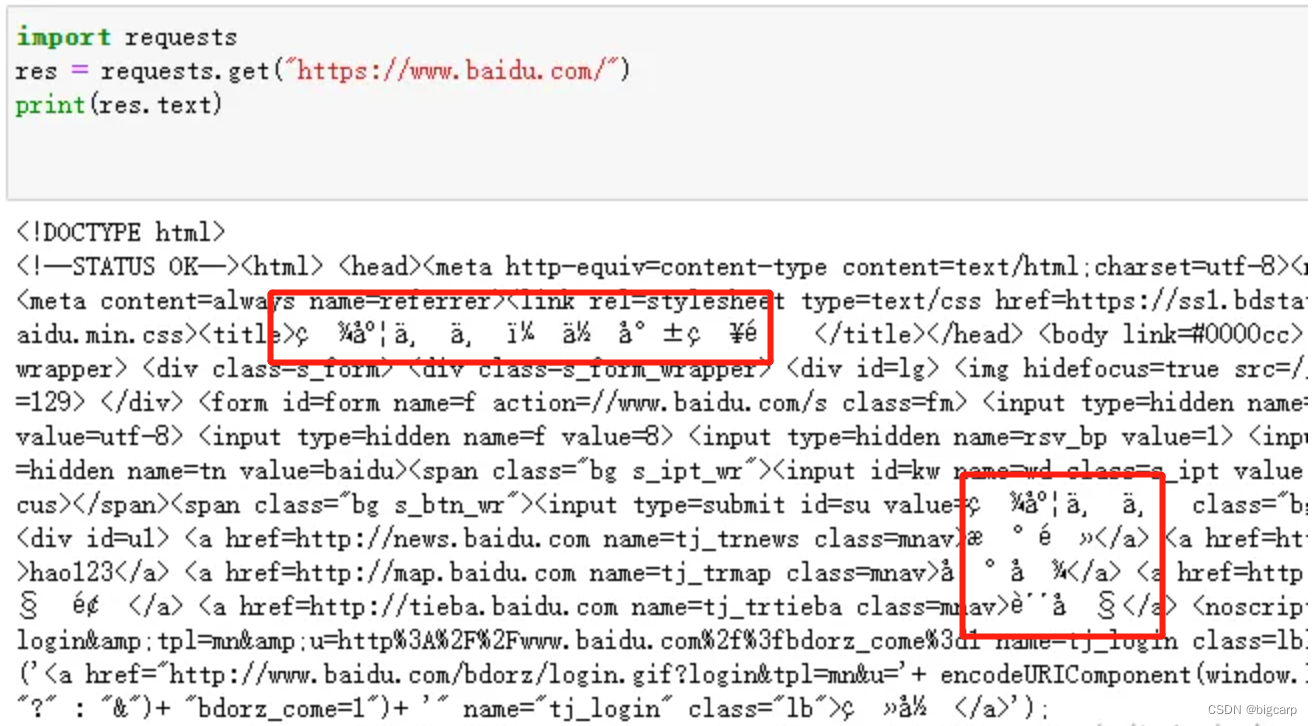
乱码的原因是内容编码和解码方式不一致导致的,解决办法有以下几种解决办法:
第一种:apparent_encoding
import requests
res = requests.get("https://www.baidu.com/")
res.encoding = res.apparent_encoding
print(res.text) 第二种:content utf-8解码
一种临时性的解决办法,不建议用这种方法,相当于写死代码了。
import requests
res = requests.get("https://www.baidu.com/")
try:
txt = res.content.decode('gbk')
except UnicodeDecodeError as e:
# print(e)
txt = res.content.decode('utf-8')
print(txt) 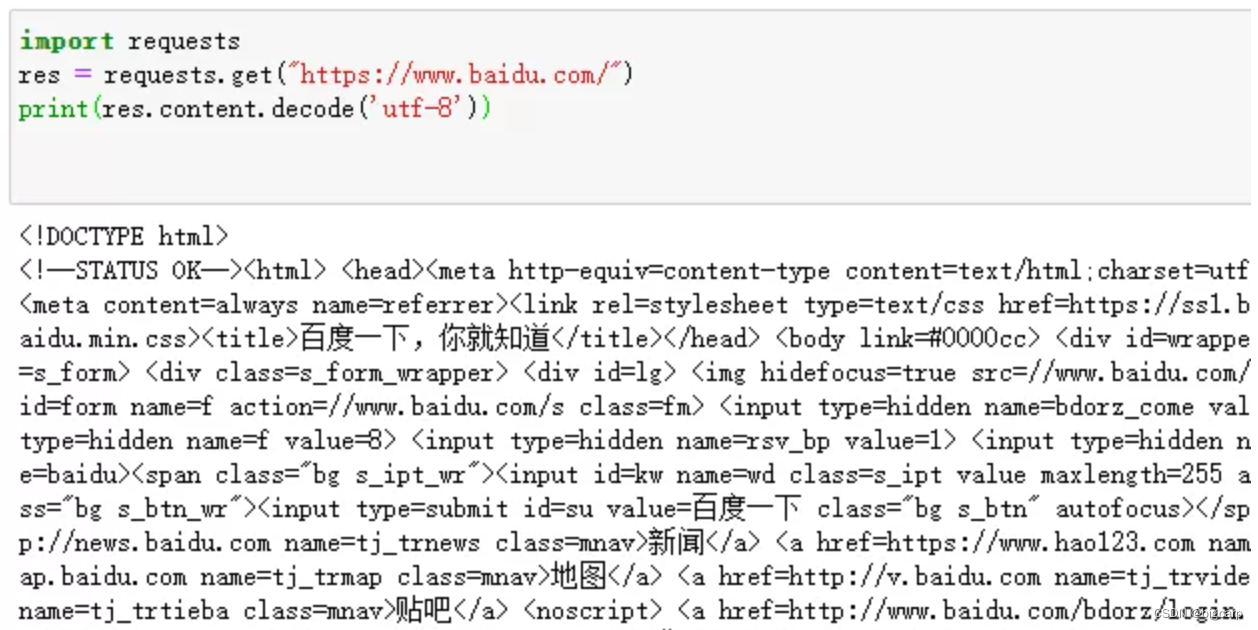
第三种:chardet
import requests
import chardet
res = requests.get("https://www.baidu.com/")
encoding = chardet.detect(res.content)['encoding']
print(res.content.decode(encoding)) 第四种:cchardet
cchardet需要提前安装一下:pip install cchardet。
import requests
import cchardet
res = requests.get("https://www.baidu.com/")
encoding = cchardet.detect(res.content)['encoding']
print(res.content.decode(encoding))第五种:encode + decode
import requests
import cchardet
res = requests.get("https://www.baidu.com/")
res_encoding = res.encoding # 响应的编码方式
con_encoding = cchardet.detect(res.content)['encoding'] # 内容的编码方式
print(res.text.encode(res_encoding).decode(con_encoding)) # 重新编解码text