度量学习
定义
计算特征之间的距离(特征之间相乘),通过距离损失优化模型——>度量距离相关的损失函数
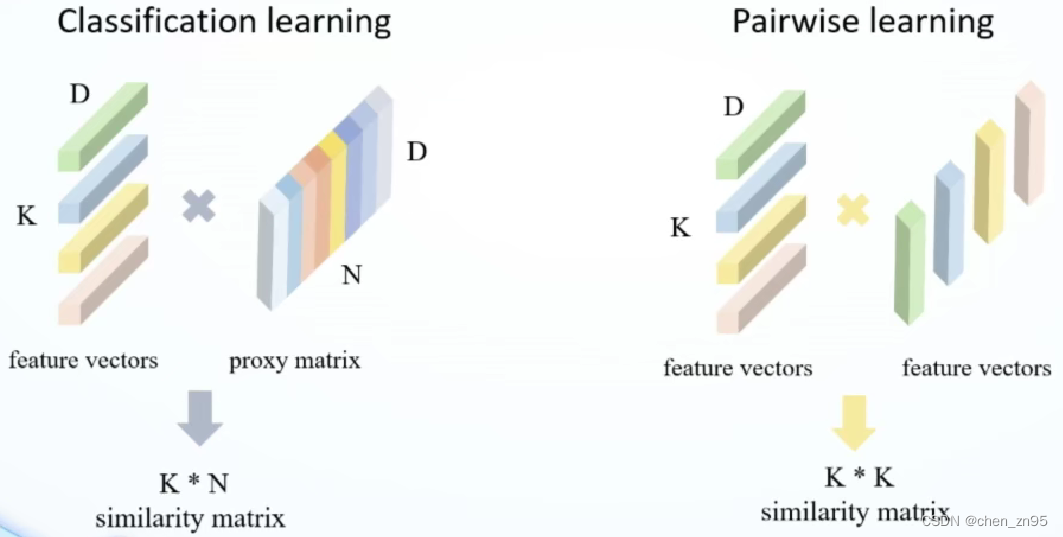
图片出自《【极市】张宇涵-CVPR2020 Oral|Circle Loss,从统一视角提升深度特征学习能力_哔哩哔哩_bilibili》
损失函数
对比学习损失函数
以SimCLR中的损失函数为例,公式如下,
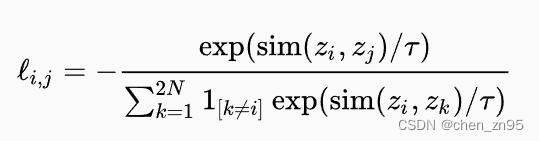
其中图片1与图片N+1是同一张图片进行两种不同的数据增强后得到的图片,因此便将它们视为正样本
三元组损失函数
三元组损失和对比学习损失一样,都是为了提高模型的性能。不同的是,三元组损失是在三个样本之间比较,而对比学习损失则是在两个样本之间比较。三元组损失和对比学习损失都是使用差异性的度量来判断模型是否正确学习。三元组损失的公式如下,

其中,:距离度量,
:anchor,
:为anchor的正样本,
:为anchor的负样本,
:大于0的常数
难例挖掘三元组损失函数
类似于三元组损失,带难例挖掘的三元组损失也是求anchor与positive、negative之间的距离,随后进行优化。不同点是,带难例挖掘的三元组损失中的为最难的正样本对(可以理解成该正样本对的欧式距离在所有正样本对中是最大的),
为最难的负样本对(可以理解成该负样本对的欧式距离在所有负样本对中是最小的),相当于挑选出最难的示例去优化模型,既然模型能够辨别最难区分的样本,那辨别其它相对容易区分的样本也肯定不在话下
表征学习
定义
将问题作为分类问题(特征与权重进行矩阵相乘,输出特征的维数为训练集的ID总数)——> softmax loss及其变种损失函数
损失函数
Circle Loss
该损失函数可以归类为度量学习或者表征学习,因为在特定条件下,它可以转化为triplet loss或者cosface loss。公式如下,

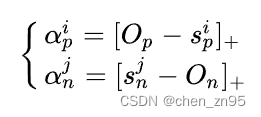

其中,:
的权重因子,
:
的权重因子,
:
的最优状态,
:
的最优状态。如果相似性分数远离它的最优状态时,这时它应该获得更大的权重因子,以便于更好优化使相似性分数趋近于最优值