HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、 实时读写的分布式数据库
利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理 HBase中的海量数据,利用Zookeeper作为其分布式协同服务
主要用来存储非结构化和半结构化的松散数据
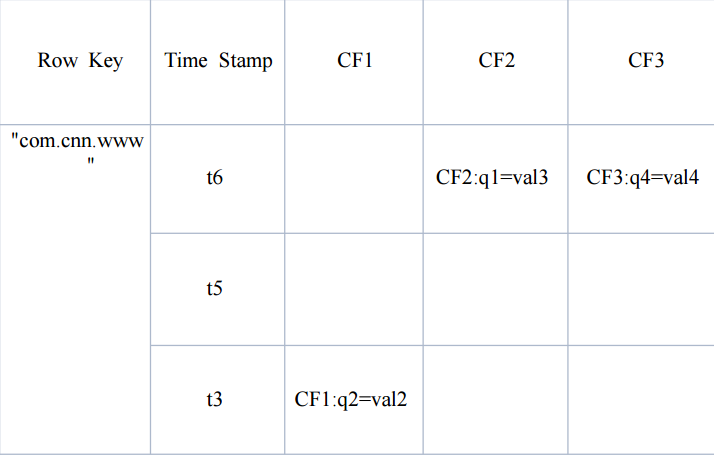
ROW KEY:
决定一行数据,按照字典顺序排序的,只能存储64k的字节数据
Column Family列族 & qualifier列:
CF1,CF2,CF3就是列族 q1,q2,q4就是列
权限控制、存储以及调优都是在列族层面进行的,HBase把同一列族里面的数据存储在同一目录下,由几个文件保存
Timestamp时间戳:
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间 戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序, 最新的数据版本排在最前面。
Cell单元格:
由行和列的坐标交叉决定,单元格是有版本的,单元格的内容是未解析的字节数组
由{row key, column( = +), version} 唯一确定的单元。cell中的数据是没 有类型的,全部是字节码形式存贮。
HLog:
记录的不仅仅是操作,而且还记录数据
HBase伪分布式搭建,使用的是HBase内置的zookeeper:
所以为了不端口冲突,伪分布式不要部署在zookeeper服务器上
解压HBase包:注意配置环境变量
conf/hbase-env.sh:
JAVA_HOME=实际安装jdk路径
conf/hbase-site.xml:
<property>
<name>hbase.rootdir</name>
<value>file:///opt/testuser/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/testuser/zookeeper</value>
</property>
bin/
start-hbase.sh 启动
stop-hbase.sh 停止
hbase shell 进入hbase
quit 退出
node1:60010 访问端口
完全分布式:
准备几台服务器,解压,配置环境变量
conf/hbase-env.sh:
export HBASE_MANAGES_ZK=false 是否使用自带默认的zookeeper
conf/hbase-site.xml:
<property>
<name>hbase.rootdir</name>
<value>hdfs://yuntian/hbase</value> <!-- 和hadoop集群core-site.xml保持一致-->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2:4180,node3:4180,node4:4180</value> <!-- 和zookeeper集群保持一致-->
</property>
conf/regionservers: //设置Region
node2
node3
node4
conf/backup-masters: //设置备master(RegionServer)
node2
注意:复制hadoop的etc/hadoop/
hdfs-site.xml复制到Hbase的conf下
几台服务器HBase配置文件要一样
bin/start-hbase.sh 启动
hbase shell 进入hbase
node1:60010 访问
主master和其他几台服务器要做免密码
ssh-copy-id node2 做免密