对竞赛中常用得标准库进行解析和给出代码模板
目录
4.2 heapq.heappush(heap, item)
1.functools
1.1 cmp_to_key
将旧风格的比较函数转换为key函数。
-1 不变 1 交换位置
import functools
x=[1,3,2,4,5]
def cmp_rise(a,b):
'''
升序排序:
当前面的参数a小于后面的参数b返回-1,-1代表保持不变,
当前面的的参数a大于等于后面的参数b返回1,1代表交换顺序。
因此保证了前面的数子小于后面的数字,是升序排序。
'''
if a <b:
return -1
else:
return 1
def cmp_decline(a,b):
'''
降序排序:
当前面的参数a小于后面的参数b返回1,1代表交换顺序,
当前面的的参数a大于等于后面的参数b返回-1,-1代表保持不变。
因此保证了前面的数子大于后面的数字,是降序排序。
'''
if a <b:
return 1
else:
return -1
x_sorted_by_rise=sorted(x,key=functools.cmp_to_key(cmp_rise))
x_sorted_by_decline=sorted(x,key=functools.cmp_to_key(cmp_decline))
print(x) # 输出结果:[1, 3, 2, 4, 5]
print(x_sorted_by_rise) # 输出结果:[1, 2, 3, 4, 5]
print(x_sorted_by_decline) # 输出结果:[5, 4, 3, 2, 1]
1.2 lru_cache(记忆化存储,加快递归速度)
允许我们将一个函数的返回值快速地缓存或取消缓存。
该装饰器用于缓存函数的调用结果,对于需要多次调用的函数,而且每次调用参数都相同,则可以用该装饰器缓存调用结果,从而加快程序运行。
该装饰器会将不同的调用结果缓存在内存中,因此需要注意内存占用问题。
from functools import lru_cache
@lru_cache(maxsize=30) # maxsize参数告诉lru_cache缓存最近多少个返回值
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
print([fib(n) for n in range(10)])
fib.cache_clear() # 清空缓存2.collections
2.1 deque
双端队列,用于实现单调队列和BFS搜索
from collections import deque
q = deque(['a', 'b', 'c'], maxlen=10)
# 从右边添加一个元素
q.append('d')
print(q) # deque(['a', 'b', 'c', 'd'], maxlen=10)
# 从左边删除一个元素
print(q.popleft()) # a
print(q) # deque(['b', 'c', 'd'], maxlen=10)
# 扩展队列
q.extend(['i', 'j'])
print(q) # deque(['b', 'c', 'd', 'i', 'j'], maxlen=10)
# 查找下标
print(q.index('c')) # 1
# 移除第一个'd'
q.remove('d')
print(q) # deque(['b', 'c', 'i', 'j'], maxlen=10)
# 逆序
q.reverse()
print(q) # deque(['j', 'i', 'c', 'b'], maxlen=10)
# 最大长度
print(q.maxlen) # 10
2.1.1 单调对列实现
蓝桥杯 MAX最值差

import os
import sys
# 请在此输入您的代码
from collections import deque
def findMaxdiff(n,k,a):
q1,q2=deque(),deque() # 建两个单调队列
res=-sys.maxsize
for i in range (n): # 遍历每一个元素
while q1 and a[q1[-1]]>=a[i]: #q1有元素且最后一个元素都大于a[i]
q1.pop()
q1.append(i)
while q1 and i-q1[0]>=k:
q1.popleft()
Fi=a[q1[0]]
while q2 and a[q2[-1]]<=a[i]: #q1有元素且最后一个元素都大于a[i]
q2.pop()
q2.append(i)
while q2 and i-q2[0]>=k:
q2.popleft()
Gi=a[q2[0]]
#计算最大差值
res=max(res,Gi-Fi)
return res
n,k=map(int,input().split())
A=list(map(int,input().split()))
print(findMaxdiff(n,k,A))2.1.2 BFS广搜
蓝桥杯真题 跳蚂蚱

import collections
import sys
meet=False #判断是否相遇
def extend(q,m1,m2):
global meet
s=q.popleft()
ss=list(s)
index=ss.index('0') #找0的索引
for j in [1,-1,2,-2]:
ss[(index+j+9)%9],ss[index]= ss[index],ss[(index+j+9)%9]
a=''.join(ss)
if a in m2: # 找到相同的了,即相遇了
print(m1[s]+1+m2[a])
meet=True
return
if a not in m1:
q.append(a)
m1[a]=m1[s]+1 # 向字典中添加
ss[(index+j+9)%9],ss[index]= ss[index],ss[(index+j+9)%9]
# meet=False
q1=collections.deque()
q2=collections.deque()
q1.append("012345678")
q2.append("087654321")
# 字典去重,同时记录步数
mp1={'012345678':0} ; mp2={'087654321':0}
while q1 and q2 : # 两个都不为空
if len(q1)<=len(q2): extend(q1,mp1,mp2)
else: extend(q2,mp2,mp1)
if meet==True: break
3.sys
3.1 sys.maxsize
表示操作系统承载的最大int值
3.2 sys.exit()
中断程序运行
3.3 sys.stdin.readline()
快读,注意会读入回车符,感觉用处不大, 没提升多大效率
import sys
a = sys.stdin.readline()
b = input()
print(len(a), len(b))
a = sys.stdin.readline().strip('\n')
b = input()
print(len(a), len(b))
输出结果
123123 123123 adsfasdfd fefeggegeag fasdfa
123123 123123 adsfasdfd fefeggegeag fasdfa
43 42
123123 123123 adsfasdfd fefeggegeag fasdfa
123123 123123 adsfasdfd fefeggegeag fasdfa
42 423.4 sys.setrecursionlimit()
设置最大递归深度,默认的很小,有时候dfs会报错出现段错误。
sys.setrecursionlimit(10**6)4.heapq
4.1 heapq.heapify(x)
将list x 转换成堆,原地,线性时间内。
import heapq
H = [21,1,45,78,3,5]
# Use heapify to rearrange the elements
heapq.heapify(H)
print(H)
[1, 3, 5, 78, 21, 45]
4.2 heapq.heappush(heap, item)
将 item 的值加入 heap 中,保持堆的不变性。
# Add element
heapq.heappush(H,8)
print(H)
[1, 3, 5, 78, 21, 45]
↓
[1, 3, 5, 78, 21, 45, 8]
4.3 heapq.heappop(heap)
弹出并返回 heap 的最小的元素,保持堆的不变性。如果堆为空,抛出 IndexError 。使用 heap[0] ,可以只访问最小的元素而不弹出它。
# Remove element from the heap
heapq.heappop(H)
print(H)
[1, 3, 5, 78, 21, 45, 8]
↓
[3, 21, 5, 78, 45]
4.4 堆优化的Dijstra
1.蓝桥杯国赛真题 出差

import os
import sys
import itertools
import heapq
# Bellman-Ford O(mn)
'''
n,m=map(int,input().split())
stay=[0]+list(map(int,input().split()))
stay[n]=0 # 终点不需要隔离
e=[]
for i in range(m):
a,b,c=map(int,input().split())
e.append([a,b,c])
e.append([b,a,c])
dp=[sys.maxsize for i in range(n+1)]
dp[1]=0 #到起点的距离为0
for i in range(1,n+1): # n个点
for j in e: # m条边
v1,v2,cost=j
#if v2==n: # n号城市不需要隔离时间
dp[v2]=min(dp[v2],dp[v1]+cost+stay[v2])
print(dp[n])
'''
# Dijstra 临接表写法 O(n*n)
'''
n,m=map(int,input().split())
stay=[0]+list(map(int,input().split()))
stay[n]=0 # 终点不需要隔离
edge=[[]for i in range(n+1)]
for i in range(m):
a,b,c=map(int,input().split())
edge[a].append([b,c+stay[b]])
edge[b].append([a,c+stay[a]])
hp=[]
vis=[0 for i in range(n+1)]
dp=[sys.maxsize for i in range(n+1)]
dp[1]=0 # 自身到自身距离为0
heapq.heappush(hp,(0,1))
while hp:
u=heapq.heappop(hp)[1]
if vis[u]:
continue
vis[u]=1
for i in range(len(edge[u])): # 遍历u的边
v,w=edge[u][i][0],edge[u][i][1]
if vis[v]:
continue
if dp[v]>dp[u]+w:
dp[v]=dp[u]+w
heapq.heappush(hp,(dp[v],v))
print(dp[n])
'''
# Dijstra临接矩阵写法 O(n*n)
'''
n,m=map(int,input().split())
stay=[0]+list(map(int,input().split()))
stay[n]=0 # 终点不需要隔离
edge=[[sys.maxsize for i in range(n+1)]for i in range(n+1)]
for i in range(m):
a,b,c=map(int,input().split())
edge[a][b]=c+stay[b]
edge[b][a]=c+stay[a]
vis=[0 for i in range(n+1)]
dp=[sys.maxsize for i in range(n+1)]
dp[1]=0 # 自身到自身距离为0
for i in range(n-1): #只需要处理n-1个点
t=-1
for j in range(1,n+1): # 找到没处理过得并且距离最小的
if vis[j]==0 and(t==-1 or dp[j]<dp[t] ):
t=j
for j in range(1,n+1):
dp[j]=min(dp[j],dp[t]+edge[t][j])
vis[t]=1
print(dp[n])
'''
# SPFA
n,m=map(int,input().split())
stay=[0]+list(map(int,input().split()))
stay[n]=0 # 终点不需要隔离
edge=[[]for i in range(n+1)] #临接表存边
for i in range(m):
a,b,c=map(int,input().split())
edge[a].append([b,c+stay[b]])
edge[b].append([a,c+stay[a]])
dp=[sys.maxsize for i in range(n+1)]
dp[1]=0 # 自身到自身距离为0
def spfa():
hp=[]
heapq.heappush(hp,1) #用堆实现相当于优先队列,加快一点效率罢了
in_hp=[0 for i in range(n+1)] # 标记数组换为了判断是否在队列中
in_hp[1]=1 # 1在队列
while hp:
u=heapq.heappop(hp)
in_hp[u]=0 # 标记为不在队列
if dp[u]==sys.maxsize: # 没有处理过的点,直接跳过,只处理邻居点
continue
for i in range(len(edge[u])): # 遍历u的边
v,w=edge[u][i][0],edge[u][i][1]
if dp[v]>dp[u]+w:
dp[v]=dp[u]+w
if in_hp[v]==0: # 他的邻居不再队列,就把他入队,方便下下次更新邻居的邻居结点
heapq.heappush(hp,v)
in_hp[v]=1
spfa()
print(dp[n])4.5 通过堆实现的Kruskal算法
1.国赛真题 通电

import os
import sys
import math
import heapq # heapq 比 优先队列要快很多
input = sys.stdin.readline
n = int(input().strip())
root = [i for i in range(n+1)]
arr = [list(map(int, input().strip().split())) for i in range(n)] # n个点坐标 高度
# 计算距离
def dist(x1,y1,h1, x2,y2,h2):
return math.sqrt((x1-x2)*(x1-x2) + (y1-y2)*(y1-y2)) + (h1-h2)*(h1-h2)
q = []
# 建立 n个点的的连通图
for i in range(n):
for j in range(i+1,n):
heapq.heappush(q, [dist(arr[i][0],arr[i][1],arr[i][2], arr[j][0],arr[j][1],arr[j][2]), i, j]) # 从 i到j牵线,并按距离排序
# 判断是否会形成环
def find(u):
if u != root[u]:
root[u] = find(root[u])
return root[u]
# Kruskal 算法实现步骤
def Kruskal():
ans = 0.00
cnt = 0
while q and cnt < n-1: # 图只需找n-1条边
c,a,b = heapq.heappop(q)
a_root = find(a)
b_root = find(b)
if a_root != b_root:
root[a_root] = b_root
ans += c
cnt += 1
print('%.2lf' % ans)
Kruskal()
"""
import os
import sys
# 请在此输入您的代码
import math
n=int(input())
def money(a,b):
ke=math.sqrt(pow(a[0]-b[0],2)+pow(a[1]-b[1],2))+pow(a[2]-b[2],2)
return ke
def prim():
global res
dist[0]=0
book[0]=1
for i in range(1,n):
dist[i]=min(dist[i],G[0][i])
for i in range(1,n):
cnt=float("inf")
t=-1
for j in range(1,n):
if book[j]==0 and dist[j]<cnt:
cnt=dist[j]
t=j
if t==-1 :
res=float("inf")
return
book[t]=1
res+=dist[t]
for j in range(1,n):
dist[j]=min(dist[j],G[t][j])
ls=[]
book=[0]*n
dist=[float("inf")]*n
res=0
for i in range(n):
ls.append(list(map(int,input().split())))
G=[[float("inf")]*n for _ in range(n)]
for i in range(n):
G[i][i]=float("inf")
for i in range(n):
for j in range(i+1,n):
G[i][j]=money(ls[i],ls[j])
G[j][i]=money(ls[i],ls[j])
prim()
print("{:.2f}".format(res))
"""5.itertools
主要使用combinations和combinations。
5.1 combinations
itertools.combinations(iterable, r):生成可迭代对象的所有长度为r的组合。
5.2 permutations
itertools.permutations(iterable, r=None):生成可迭代对象的所有长度为r的排列,默认r为可迭代对象的长度。
5.3 例题
1.算式问题
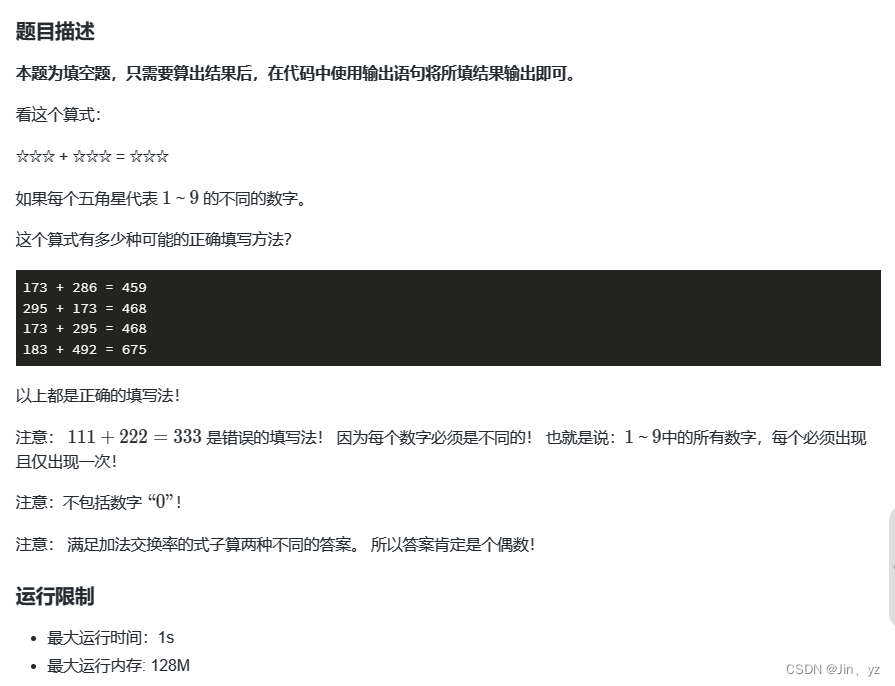
import os
import sys
import itertools
# 请在此输入您的代码
L=[str(i) for i in range(1,10)]
ans=0
for i in itertools.permutations(L):
s=''.join(i)
if int(s[:3])+int(s[3:6])==int(s[6:]):
ans+=1
print(ans)6.bisect
内置的二分查找函数,用于有序序列的插入和查找

6.1 bisect_left()
bisect.bisect_left(a, x, lo=0, hi=len(a))
若 x ∈ a,返回最左侧 x 的索引;否则返回与 x 右邻居索引,使得 x 若插入后能位于其 左侧。
6.2 bisect_right() 、bisect()
bisect.bisect(a, x, lo = 0, hi =len(a))
bisect.bisect_right(a, x, [lo=0, hi=len(a)])
若 x ∈ a,返回最左侧 x 的索引;否则返回与 x 右邻居索引,使得 x 若插入后能位于其 左侧。
6.3 insort_left()
bisect.insort_left(a, x, lo=0, hi=len(a))
bisect.bisect_left() 在序列 a 中 查找 元素 x 的插入点 (左侧)
bisect.insort_left() 就是在找到插入点的基础上,将元素 x 插入序列 a,从而改变序列 a 同时保持元素顺序。
6.4 insort_right()、insort()
bisect.insort(a, x, lo=0, hi=len(a))
bisect.insort_right(a, x, lo=0, hi=len(a))
6.5 示例
import bisect
nums = [0,1,2,3,4,4,6]
idx = bisect.bisect_left(nums,-1) # 0
idx = bisect.bisect_left(nums,8) # 7
idx = bisect.bisect_left(nums,3) # 3
idx = bisect.bisect_left(nums,3.5) # 4
idx = bisect.bisect_left(nums,4) # 4
idx = bisect.bisect_left(nums,3,1,4) # 3
a = [1,4,6,8,12,15,20]
position = bisect.bisect(a,13)
print(position) # 5
# 用可变序列内置的 insert 方法插入
a.insert(position, 13)
print(a) # 5 [1, 4, 6, 8, 12, 13, 15, 20]
查找的数不在列表中
import bisect
list1 = [1,3,5,7,9,11,11,11,11,11,13]
a = bisect.bisect(list1,6)
b = bisect.bisect_left(list1,6)
c = bisect.bisect_right(list1,6)
print(a,b,c)
# 输出为 3,3,3查找的数在列表中只有一个
import bisect
list1 = [1,3,5,7,9,11,11,11,11,11,13]
a = bisect.bisect(list1,9)
b = bisect.bisect_left(list1,9)
c = bisect.bisect_right(list1,9)
print(a,b,c)
# 输出 5,4,5查找的数在列表中有多个
import bisect
list1 = [1,3,5,7,9,11,11,11,11,11,13]
a = bisect.bisect(list1,11)
b = bisect.bisect_left(list1,11)
c = bisect.bisect_right(list1,11)
print(a,b,c)
# 输出是 10,5,106.6 例题1 最长上升子序列
1.蓝桥骑士

import os
import sys
'''
# 最长上升子序列
n = int(input())
a = list(map(int,input().split()))
f = [1]*n
for i in range(1,n):
for j in range(i):
if a[i] > a[j]:
f[i] = max(f[i],f[j]+1)
print(max(f))
'''
# 超时
'''
import bisect
n = int(input())
a = list(map(int,input().split()))
b = [a[0]]
for i in range(1,n):
t = bisect.bisect_left(b,a[i])
# 若b中不存在a[i],t是适合插入的位置
# 若b中存在a[i],t是a[i]第一个出现的位置
if t == len(b): # 插入的位置是否是末尾
b.append(a[i])
else:
b[t] = a[i]
print(len(b))
'''
import bisect
#蓝桥骑士 dp lis(Longest Increasing Subsequence)
n = int(input())
alist = list(map(int,input().split()))
dp = []
for i in alist:
if not dp or i > dp[-1]:
dp.append(i)
else:
index = bisect.bisect_left(dp,i)
dp[index]=i
print(len(dp))2.蓝桥勇士

import sys #设置递归深度
import collections #队列
import itertools # 排列组合
import heapq #小顶堆
import math
sys.setrecursionlimit(300000)
n=int(input())
save=[0]+list(map(int,input().split()))
dp=[1]*(n+1) # 注意初始化从1开始
for i in range(2,n+1):
for j in range(1,i):
if save[i]>save[j]:
dp[i]=max(dp[i],dp[j]+1)
print(max(dp)) #最长公共子序列,dp[n]不一定是最大的
# 1 4 5 2 1
# 1 2 3 2 16.7 例题2 最长上升子序列变形

import bisect # 内置二分查找
zifu = input()
A = [chr(65 + i) for i in range(26)]
s = ""
name = []
i = 0
zifu = zifu + "A" # 以后一个大写字符进行提取分隔
while i < len(zifu) - 1: # 提取数据格式为 name=[Wo,Ai,Lan,Qiao,Bei]
s += zifu[i]
if zifu[i + 1] in A:
name.append(s)
s = ""
i += 1
d = [name[0]]
p=[1] #存储下标
for i in name[1:]: # 遍历每一个字符
if i > d[-1]: # 大于,可以直接在后面接着
d.append(i) # 后面添加
p.append(len(d)) # 记录索引
else: # 查找第一个
k = bisect.bisect(d, i) # 使用bisect查找d中第一个大于等于i的元素,让其称为递增序列,有多个就是最右边的那个
if k > 0 and d[k - 1] == i: # 如果右索引的前一个数等于这个i的话,就将它替换掉,相等的不算递增????
k -= 1
d[k] = i
p.append(k+1) # 记录替换的索引
p0=p[::-1] #逆序遍历输出
s=len(d) # 最长有多少个递增子序列
ans=""
for i in range(len(p0)): #逆序遍历
if s==0:
break
if p0[i]==s:
ans=name[len(p)-i-1]+ans #加上name
s=s-1
print(ans)