系列文章主要目的快速厘清不同方法的原理差异和应用场景,
对于理论的细节请参考文末的Reference,
Reference中也会筛选较为正确,细节的说明
在大模型微调的众多方法中,RLHF一直都被认为是ChatGPT成功的关键,但成本与训练门槛最高。GPT系列的RLHF方案一直未开源,因此研究到这一步的团队只能基于Fine-Tuning Language Models from Human Preferences进行魔改,而且过程复杂又昂贵。
AlpacaFarm的提出无疑是解决开源社区这一大痛点,这个框架主要的目标是有效的整合目前常见的基于人类反馈(Human feedback)的Instruction-fowllowing 模型训练技术,以及提供完善统一的pipeline,大幅降低训练门槛。以下是整体框架,号称完整的RLHF训练只需要24小时,成本约200美元
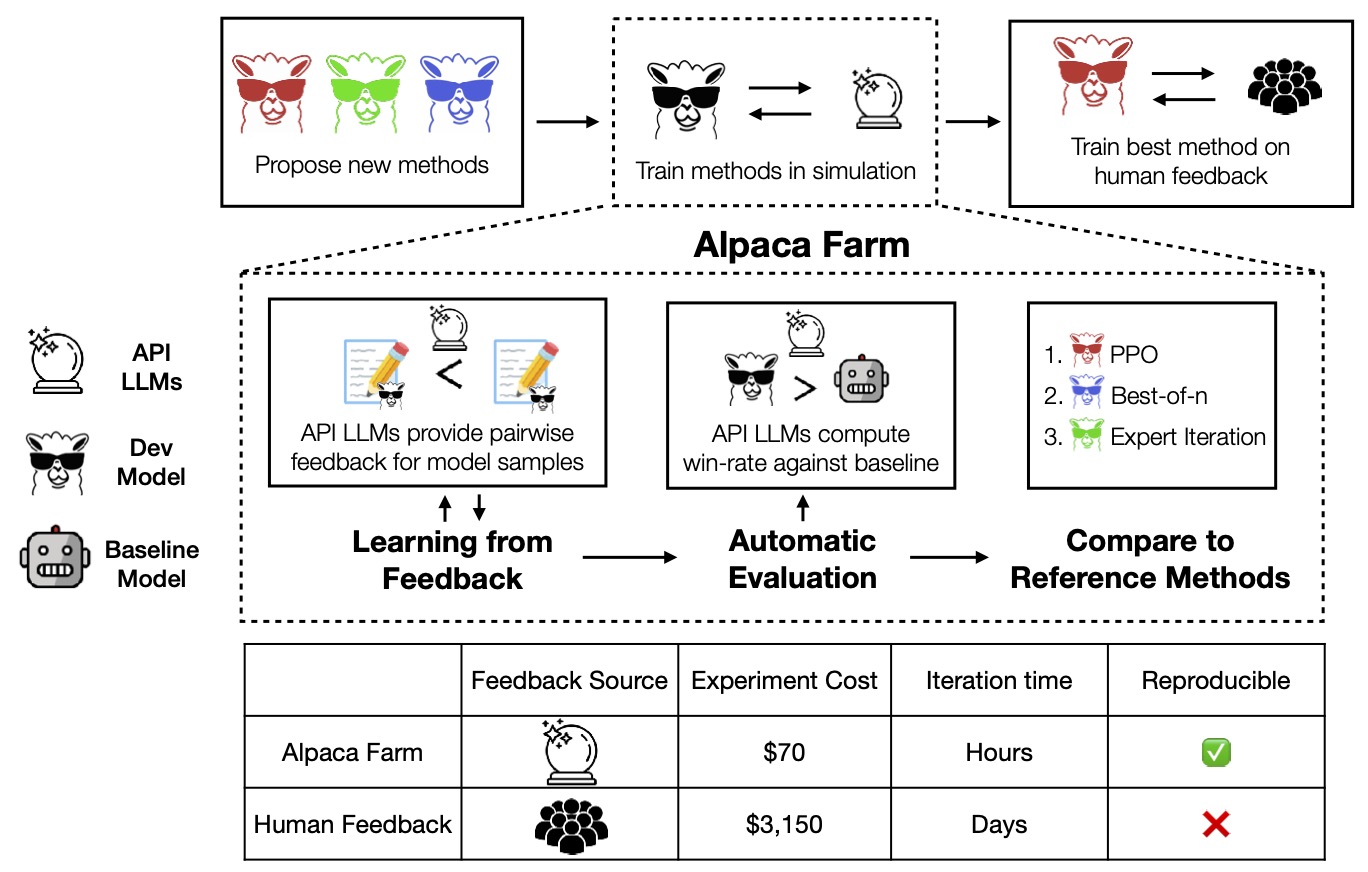
简单说明一下整个训练流程,开源的内容同样延续Aplaca的训练流程,使用Alpaca5.2K数据集,但提取其中10K进行SFT(Supervised Finetune),剩下的42K数据用来作人工偏好标注以及测试,整个数据集已经可以在HuggingFace上获取。
其主要降低的关键,主要就是使用模拟人工标注的方式,有点类似self-instruct的方法,这个流程相比人工标注降低45倍。比较模拟标注的方式与实际人工标注数据的训练结果,整体结果表现非常一致:

结论
AlpacaFarm主要的贡献包含:
- 模拟人工标注方式:降低成本与效率
- 模型自动化评估系统:融合Alpaca交互数据和公开数据集对RLHF结果进行评估
- 实现主流RLHF方法,包含:PPO,Expert Iteration, Best-of-n sampling...等
完整代码已经公开:GitHub - tatsu-lab/alpaca_farm: A Simulation Framework for RLHF and alternatives.
Reference
https://crfm.stanford.edu/2023/05/22/alpaca-farm.html