Scrapy框架学习(七)—-Scrapy与scrapy-splash框架结合,快速加载js页面
一、前言
我们在使用爬虫程序爬取网页时,一般对于静态页面的爬取是比较简单的,之前写过挺多的案例。但是对于使用js动态加载的页面如何爬取呢?
对于动态js页面的爬取有以下几种爬取的方式:
通过
selenium+phantomjs实现。phantomjs是一个无头浏览器,selenium是一个自动化测试的框架,通过无头浏览器请求页面,等待js加载,再通过自动化测试selenium获取数据。因为无头浏览器非常消耗资源,所在性能方面有所欠缺。
Scrapy-splash框架:Splash作为js渲染服务,是基于Twisted和QT开发的轻量浏览器引擎,并且提供直接的http api。快速、轻量的特点使其容易进行分布式开发。
splash和scrapy爬虫框架融合,两种互相兼容彼此的特点,抓取效率较好。
二、Splash环境搭建
Splash服务是基于docker容器的,所以我们需要先安装docker容器。
2.1 docker安装(windows 10 家庭版)
如果是win 10专业版或其他操作系统,都是比较好安装的,在windows 10家庭版安装docker需要通过toolbox(需要最新的)工具安装才行。
关于docker的安装,参考文档:WIN10安装Docker
2.2 splash安装

docker pull scrapinghub/splash2.3 启动Splash服务
docker run -p 8050:8050 scrapinghub/splash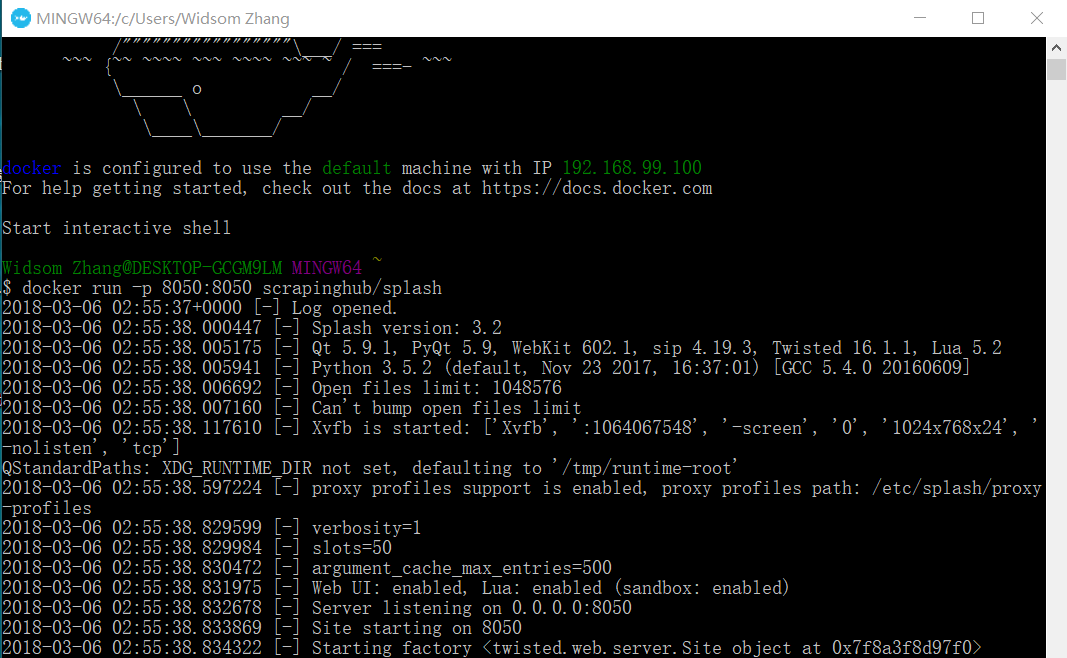
这个时候,打开你的浏览器,输入192.168.99.100:8050你会看到出现了这样的界面。
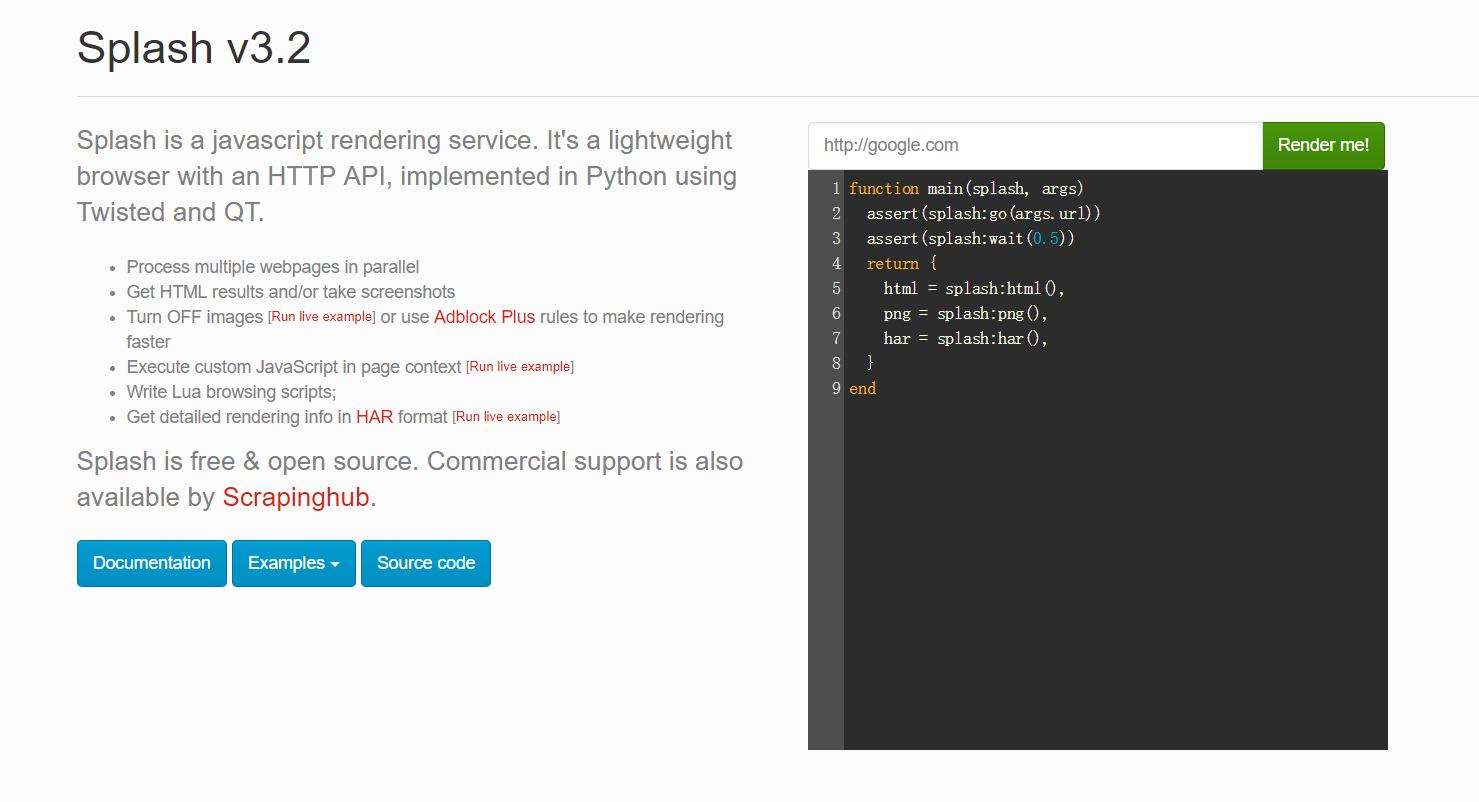
你可以在上图红色框框的地方输入任意的网址,点击后面的Render me! 来查看渲染之后的样子
2.4 安装python的scrapy-splash包
pip install scrapy-splash三、scrapy爬虫加载js项目测试,以google news为例。
由于业务需要爬取一些国外的新闻网站,如google news。但是发现居然是js代码。于是开始使用scrapy-splash框架,配合Splash的js渲染服务,获取数据。具体看如下代码:
3.1 settings.py配置信息
# 渲染服务的url
SPLASH_URL = 'http://192.168.99.100:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
#下载器中间件
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
# 请求头
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}
# 管道
ITEM_PIPELINES = {
'news.pipelines.NewsPipeline': 300,
}
3.2 items字段定义
class NewsItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 图片的url链接
image_url = scrapy.Field()
# 新闻来源
source = scrapy.Field()
# 点击的url
action_url = scrapy.Field()3.3 Spider代码
在spider目录下,创建一个new_spider.py的文件,文件内容如下:
from scrapy import Spider
from scrapy_splash import SplashRequest
from news.items import NewsItem
class GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"]
def start_requests(self):
for url in self.start_urls:
# 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1})
def parse(self, response):
for element in response.xpath('//div[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
imageUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['image_url'] = imageUrl
item['action_url'] = actionUrl
item['source'] = source
yield item
3.4 pipelines.py代码
将item的数据,存储到mysql数据库。
- 创建db_news数据库
CREATE DATABASE db_news- 创建tb_news表
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
image_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30),
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
NewsPipeline类
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,image_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["image_url"], item["action_url"], item["source"]))
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()3.5 执行scrapy爬虫
在控制台执行:
scrapy crawl google_news数据库中展示如下图:
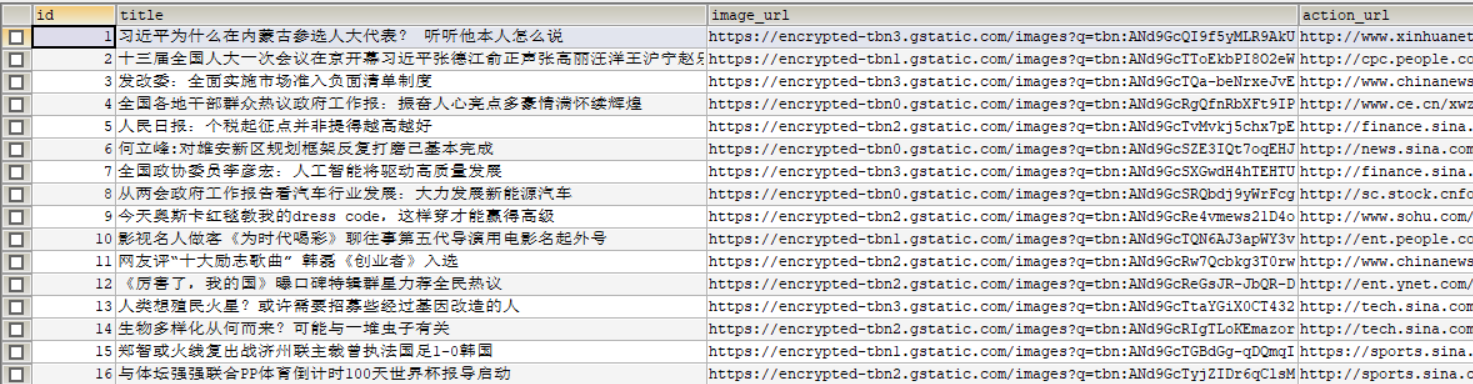
项目地址:https://github.com/zhang3550545/scrapy-spider/tree/master/news
参考文章: