先把主要的算法进行整理,后续会对py结合算法的实践进行整理。
第五弹,模型融合
目的是为了提高机器学习的效果,其实就是整理几个机器算法进行参考计算后续的训练。
三个模型融合思路:
1、bagging,训练多个分类器,结果取平均。并列的进行训练,所有的分类器无关并行进行训练。
分类:可以用于结果做vote。
回归:可以对这些模型结果取平均。

2、boosting,从弱学习开始加强,加权训练,这是串联的,也就说后一个训练的数据要参考或者直接就是拿前一个训练的数据结果进行训练。

上式中,arg min f(x) 是指使得函数 f(x) 取得其最小值的所有自变量 x 的集合。F是分类器
3、stacking,也是集合了多个分类器或者回归模型。
1、bagging模型
代表就是随机深林,深林是指决策树这样的算法,并行计算,随机是指1、数据随机。2、特征随机。一般可以设置为60%的量。
由于数据和特征都是随机的,并且量不是全部,所以训练出来的模型一定不一样。
优势:
1、可以处理很高维度的,也就是特征特别多的数据,并且不用做随机变量特征选择。
2、训练出来后可以对随机变量的特征进行重要性的排序。
eg:ABCD分别是随机变量的特征。
建模1:A+B+C+D——建模——error1(错误率)
建模2:A+B2+C+D——建模——error2(错误率)
这里把B2的数据进行随机生成,比如如果是年龄,这里B2可以改为0.1,290等这样不可能的随机数据,或者可以直接改为A+C+D进行建模。
结果:error1约等于或者大于error2 则认为B特征不重要,如果相反,error2大于error1,说明B重要。可以取消B特征。
有些算法不适合这个bagging,比如KNN,这个算法就不适合,因为泛化能力差。
树模型,理论上是随机数据越多越好,但是其实到一定的数量,就会出现波动,所以这点需要注意。
2、Boosting模型
代表是adaboost,xgboost(竞赛重点)
Adaboost迭代算法,分类思路是根据前一次的分类结果进行数据权重的修改,如果某个数据这次分错了,下次对这个数据更大权重。每个分类器根据自己准确性,确定自己的权重。其实对于adaboost就是一刀切。
Adaptive Boosting自适应增强的缩写。
更详细的思路如下:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N,很多人都认为是均匀分布,这样也比较好理解。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
具体的算法+公式:
给定一个训练数据集T={(x1,y1), (x2,y2)…(xN,yN)},其中实例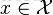

1、首先,初始化训练数据的权值分布。每一个训练样本最开始时都被赋予相同的权重:1/N。
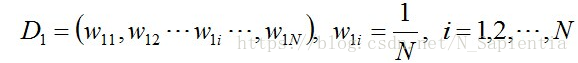
2、由于adaboost是一刀切,所以第一次训练的结束依据就是错误率最低的切割是结束的时候。
根据权重为1/N,求出最小的错误的分割线。分类器是二分类:

不是属于-1,就是1,这里后续会用到正负。
分好的标准就是求出最小错误分割线。下面式子是错误率计算,和一开始的均匀分布有联系,求出所有错误的概率之和。

当分割为em最小时候,就是这次分割的标准。
3、先对Gm进行系数迭代。后对训练数据集的权值分布修改。

am这里表示了Gm在未来模型中的重要程度。em <= 1/2时,am >= 0,且am随着em的减小而增大,意味着分类误差率越小的基本分类器在最终分类器中的作用越大。
4、对训练数据集的权值分布修改。


可以看到,其中的
新更新的权重w,是要根据两个主要方面进行确定,1、由分错概率。2、由分类器与真实的分类乘积,分错为-1,分对为1.
由log函数知道,如果em<0.5,则log中的函数为大于1,am为正数时,说明分错的小于一半,一刀切最优可以达到这样的结果:1、当yi*Gm为负数,说明分错了,exp中的数为正数,则exp是大于1的,所以权重就大。2、如果yi*Gm是正数,则exp中数为负数数,exp结果是小于1,则权重小。Zm是为了标准化归一化。

迭代。
5、组合各个分类器

最终为:

eg:
下面,给定下列训练样本,请用AdaBoost算法学习一个强分类器。

x为样本,y为正确的分类器结果。
初始化均匀分布,先计算错误率,当错误率为0,停止。不为0,就计算Gm系数和更新w。然后在新w基础上更新错误率和系数,并且Gm第二次等于第一次的迭代的系数和Gm乘积+第二次的迭代。
求解步骤为:
1、对于m=1,初始化训练数据的权值分布,令每个权值W1i = 1/N = 0.1,其中,N = 10,i = 1,2, ..., 10,然后分别对于m = 1,2,3, ...等值进行迭代。

这个时候分错最少,为三个分错了,误差率由于均匀分布,所以是e1=0.3,三个分错了。已经是最低了。
计算a1为:

更新w权值

如果某个样本被分错了,则yi * Gm(xi)为负,负负等正,结果使得整个式子变大(样本权值变大),否则变小。
由各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
2、对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
- 阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
- 阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
这次的计算是要加入上次的误差率的。判断后阈值v取8.5时误差率最低,故第二个基本分类器为:

由此得出系数:

更新权值:
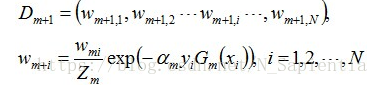
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
3、m=3时。
在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
- 阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
- 阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
- 阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为:
所以G3(x)在训练数据集上的误差率e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
系数计算为:

更新训练数据的权值分布:

D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],将上面计算得到的a1、a2、a3各值代入G(x)中,得到最终的分类器为:G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
Adaboost 还有另外一种理解,即可以认为其模型是加法模型、损失函数为指数函数、学习算法为前向分步算法的二类分类学习方法。
3、stacking模型
思想:拿前一阶段出的数据训练结果,应用到第二阶段的训练。