1.麻雀搜索算法算法思想
1.1算法来源
麻雀搜索算法(Sparrow Search Algorithm, SSA)是一种新型的群智能优化算法,在2020年提出,主要是受麻雀的觅食行为和反捕食行为的启发。其期刊为:A novel swarm intelligence optimization approach: sparrow search algorithm https://www.tandfonline.com/doi/full/10.1080/21642583.2019.1708830。以下内容都基于本文章进行讲解及拓展。
注(以下图片中,@mu_54176616是本账号改名前的名称)
1.2鸟类种群的特点
麻雀通常是群居鸟类,种类繁多。它们分布在世界大部分地区,喜欢生活在人类生活的地方。此外,它们是杂食性鸟类,主要以谷物或杂草的种子为食。众所周知,麻雀是常见的留鸟。与许多其他小型鸟类相比,麻雀非常聪明,记忆力很强。
研究表明,个体会监控群体中其他人的行为。与此同时,鸟群中的攻击者想要提高自己的捕食率,被用来争夺高摄入量同伴的食物资源。
当麻雀选择不同的觅食策略时,个体的能量储备可能发挥重要作用,能量储备低的麻雀搜寻更多。值得一提的是,位于种群外围的鸟类更容易受到捕食者的攻击,并不断尝试获得更好的位置。请注意,位于中心的动物可能会靠近邻伴,以尽量减少它们的危险领域。我们也知道,所有的麻雀都表现出对一切事物好奇的天生本能,同时它们总是保持警惕。
1.3 六大原则
原文中给出了六条规则:
1.在整个种群中,探索者通常拥有较高的能源储备并且负责搜索食物丰富的区域,为所有的追随者提供觅食的区域和方向。在算法中能量储备的高低与麻雀个体适应度值息息相关。
2.一旦麻雀发现天敌,即发出鸣叫作为报警信号。当报警值大于安全值时,探索者将会引导追随者到其它安全区域进行觅食。
3.算法中根据能否找到更好的食物来定义麻雀的身份,虽然麻雀的身份会随时转变,但是探索着与追随者在种群内的比重是不变的。
4.能量储备较高的麻雀将充当探索者。为了获得更多的能量,能量较低的追随者有可能飞到其他地方觅食。
5.在觅食过程中,追随者总是能够跟随能量储备较高的探索者进行觅食。为了提高自己的捕食率,某些个体吃着碗里瞧着锅里,它们可能会监视探索者进而争夺更多的食物资源。
6.当天敌构成一定的威胁时,位于群体边缘的麻雀为了获得更好的位置会迅速向安全区域移动,而位于种群中间的麻雀则会随机移动。
1.4 数学模型
在每次迭代的过程中,发现者的位置更新描述如下:
 其中,Xij 为麻雀个体位置,i 为当前迭代次数,itermax 为最大迭代次数;α为[0,1]内一随机数;R2 (R2 ∈ [0,1]) 、ST (ST ∈ [0.5,1])分别为预警值和安全值;Q 为服从正态分布的随机数;L 为一个 1×d 的矩阵,其中每个元素均为1。
其中,Xij 为麻雀个体位置,i 为当前迭代次数,itermax 为最大迭代次数;α为[0,1]内一随机数;R2 (R2 ∈ [0,1]) 、ST (ST ∈ [0.5,1])分别为预警值和安全值;Q 为服从正态分布的随机数;L 为一个 1×d 的矩阵,其中每个元素均为1。
当R2<ST 时,这意味着周围没有天敌,探索者可以进行全局搜索。若R2≥ST 这意味着一些麻雀已经发现了捕食者,所有麻雀都要采取相关行动。前文提到在觅食过程中,一些追随者会时刻监视着探索者。一旦探索者找到更好的食物,它们会立即离开现在的位置去争夺食物。如果它们赢得了竞争则可以立即获得该食物,追随者的位置更新方式如下:
其中,Xp为最优探索者的位置,Xworst 为当前全局最差位置;n为种群规模。A为一 个1×d 的矩阵,每个元素随机幅值为1或-1,并且A+=AT(AAT)-1,当i >n/2时,这表明,适应度值较低的第i个加入者没有获得食物,处于十分饥饿的状态,此时需要飞往其它地方觅食,以获得更多的能量。
当意识到危险时,麻雀种群会做出反捕食行为:
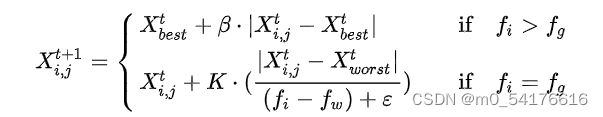
2.bilstm神经网络
存在由于时间序列趋势性、周期性、随机性或则综合性,传统的时间序列算法不一定可以很好地发挥性能。而LSTM神经网络拥有记忆功能,基本上是一个循环神经网络,能够处理长期依赖关系。我们可以采用bilstm进行时间序列预测,这样处理的好处在于,bilstm可以处理过去对未来的影响以及未来对未来的影响,同时,神经网络拟合过程中不用考虑差分、是否平稳等等过分复杂的因素,因为网络可以自适应调整权重。
LSTM的全称是Long Short-Term Memory,它是RNN(Recurrent Neural Network)的一种。在计算每个h时,LSTM内部加了三个控制开关:forget gate、input gate、output gate。通过这三个门的开关来选择性地保留之前文本的信息,这样可以解决梯度爆炸和消失的问题,可以处理更长的文本数据。

bilstm可以看做两层神经网络,一层对由于数据进行正向训练,另一层对数据进行反向训练,并将结果作向量求和。
由于bilstm的学习资料在网上已经很全面了,这里就只对代码展开:
在MATLAB中,bilstm神经网络可以被定义为以下结构:
numFeatures = size(XTrain,1);%输入节点数
numResponses = size(YTrain,1);%输出节点数
miniBatchSize %batchsize
numHiddenUnits1
numHiddenUnits2
maxEpochs
learning_rate
layers = [ ...
sequenceInputLayer(numFeatures)
Bilstm的layer层
fullyConnectedLayer(numResponses)
regressionLayer];
options = trainingOptions('adam', ...
'MaxEpochs',maxEpochs, ...
'MiniBatchSize',miniBatchSize, ...
'InitialLearnRate',learning_rate, ...
'GradientThreshold',1, ...
'Shuffle','every-epoch', ...
'Verbose',true,...
'Plots','training-progress');3.时间序列
时间序列分析法是根据过去的变化趋势预测未来的发展,它的前提是假定事物的过去延续到未来。
在实际应用中,我们会经常遇到单变量时间序列:用电量、蒸汽排放量、股票等等。对于单变量的时间序列,我们可以通过过去的几个节点数据(滞后阶数)来预测。
4.麻雀搜索算法优化bilstm
通过将bilstm的loss函数将损失将到最低来实现网络的最大拟合程度。一般以rmse作为损失值来判断网络的情况。
本文以风力发电量进行预测,预测的结果如下:麻雀搜索算法优化的结果:
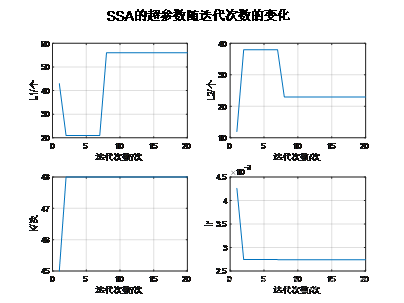
本文以两个bilstm的隐含层个数、学习速率,maxepoch四个参数进行优化,时间序列的滞后阶数为10阶。
预测结果以训练集均方误差(MSE),训练集平均绝对误差(MAE),训练集平均相对百分误差(MAPE),训练集拟合优度(R2)作为评价。
4.1 不采用麻雀搜索算法优化的结果


4.2 采用麻雀搜索算法优化的结果:



Ssa-bilstm
寻优过程:
预测结果:
创作不易,请各位给个打赏吧