目录
张量Tensor
张量是一个多维数组。与numpy ndarray对象类似
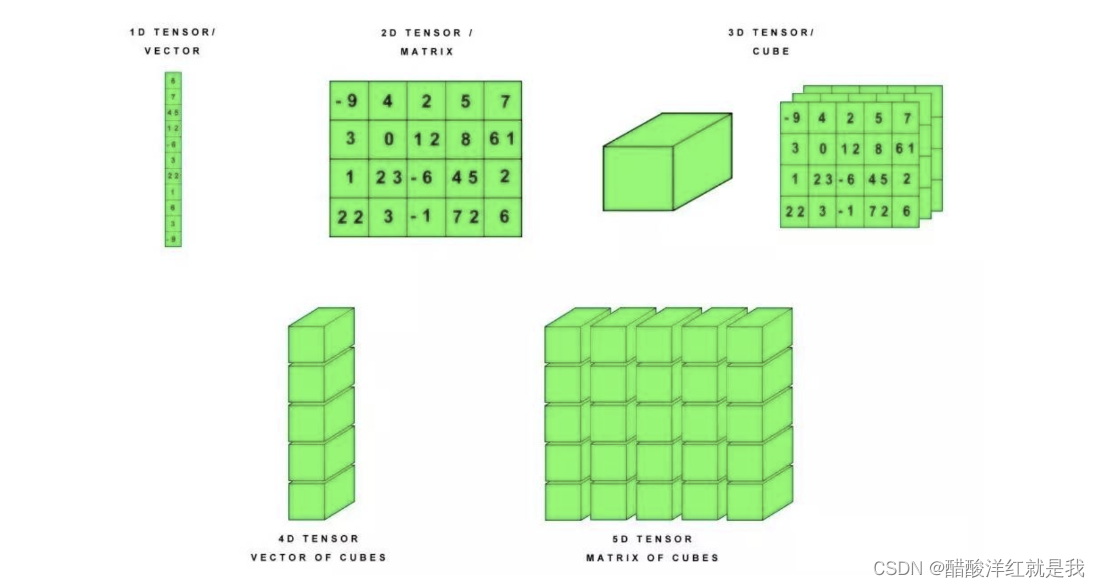
基本方法
import tensorflow as tf
#创建0维张量
tensor_1=tf.constant(4)
print(tensor_1)
#创建1维张量
tensor_2=tf.constant([2.0,3.0,4.0])
print(tensor_2)
#创建2维张量
tensor_3=tf.constant([[1,2],
[3,4],
[5,6]],dtype=tf.float16)
print(tensor_3)
Metal device set to: Apple M1
tf.Tensor(4, shape=(), dtype=int32)
tf.Tensor([2. 3. 4.], shape=(3,), dtype=float32)
tf.Tensor(
[[1. 2.]
[3. 4.]
[5. 6.]], shape=(3, 2), dtype=float16)
转换成numpy
np.array(tensor_1)
tensor_1.numpy()
常用函数
a=tf.constant([[1,2],
[3,4]])
b=tf.constant([[1,1],
[1,1]])
tf.add(a,b)
tf.multiply(a,b) #对应元素相乘
tf.matmul(a,b) #矩阵乘法
#最大值
tf.reduce_max(a)
#最大值索引
tf.argmax(a)
#平均值
tf.reduce_mean(a)
变量
是一种特殊的张量,形状是不可变的,但可以更改其中的参数
var=tf.Variable([[1,2],[3,4]])
var

#进行修改
var.assign([[2,3],[4,5]])

tf.keras介绍
常用模块
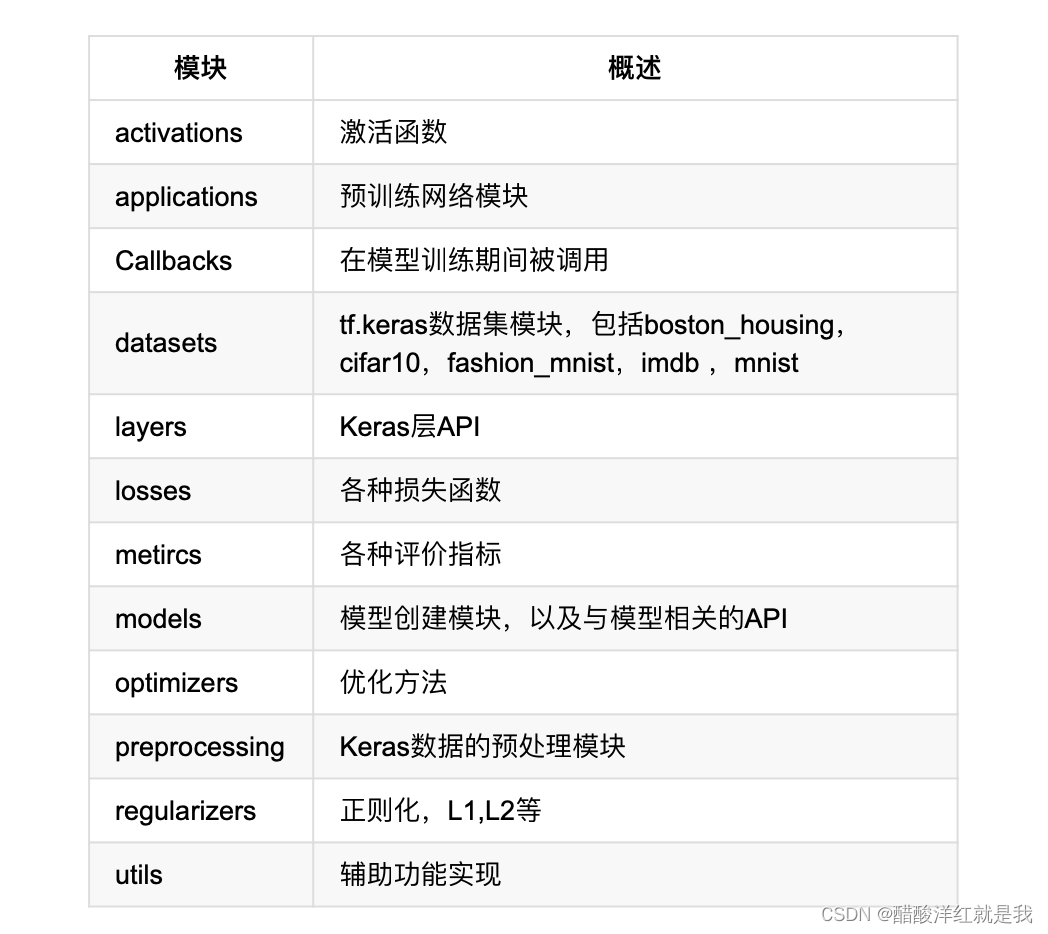
常用方法
导入
import tensorflow as tf
from tensorflow import keras
数据输入
对于小的数据集,可以直接使用numpy格式的数据进行训练、评估模型,对于大型数据集或者要进行跨设备训练时使用tf.data.datasets来进行数据输入
模型构建
- 简单模型使用Sequential进行构建
- 复杂模型使用函数式编程来构建
- 自定义layers
训练与评估
配置训练过程
模型训练
模型评估
模型预测
回调函数(callbacks)
用在模型训练过程中,来控制模型训练行为,可以自定义回调函数
模型的保存和恢复
只保存参数
#只保存模型的权重
model.save_weights('./my_model')
#加载模型的权重
model.load_weights('./mu_model')
保存整个模型
#保存模型架构与权重在h5文件中
model.save('my_model.h5')
#加载模型:包括架构和对应的权重
model=keras.models.load_model('my_model.h5')
实例
鸢尾花数据集
#导入相关的库
import numpy as np
from sklearn.model_selection import train_test_split
#深度学习:tf.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras import utils
#数据处理
x=iris.values[:,:4]
y=iris.values[:,4]
train_x,test_x,train_y,test_y=train_test_split(x,y,test_size=0.5,random_state=0)
#目标值的热编码
def one_hot_encode(arr):
#获取目标值中的所有类别,并进行独热编码
uniques,ids=np.unique(arr,return_inverse=True)
return utils.to_categorical(ids,len(uniques))
#对目标值进行编码
train_y_one=one_hot_encode(train_y)
test_y_one=one_hot_encode(test_y)
#模型构建
#通过sequential进行构建
model=Sequential([
#隐藏层
Dense(10,activation='relu',input_shape=(4,))
Dense(10,activation'relu')
#输出层
Dense(3,activation='softmax')
])
model.summary()
utils.plot_model(model,show_shapes=True) #查看网络结构
#模型预测与评估
#模型编译
model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
#类型转换
train_x=np.array(train_x,dtype=np.float32)
test_x=np.array(test_x,dtype=np.float32)
#模型训练
model.fit(train_x,train_y_one,epochs=10,batch_size=1,verbose=1)
#模型评估
loss,accuracy=model.evaluate(test_x,test_y_one,verbose=1)