HBase-2.2.2 编程实践
在开启练习之前,请确认你已经安装配置好了 Hadoop 3.1.3,并且这里是完全分布式部署,所以如果下列结果和各位做的不太一样,可以尝试适用于一下寻找解决办法。
零、环境
主机版本:Windows11
虚拟机版本:ubuntukylin-16.04-desktop-amd64
VMware 版本:VMware® Workstation 17 Pro
网卡:桥接模式
jdk 版本:jdk-8u162
Hadoop 版本:hadoop-3.1.3
HBase 版本:hbase-2.2.2
Eclipse 版本:eclipse-4.7.0
注:硬件版本是使用的兼容 VMware 12.X 的。
Master
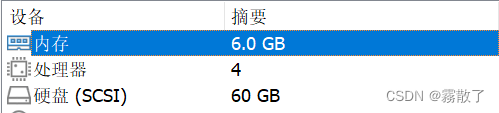

Slave
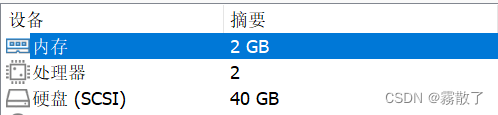
相对于具体的硬件配置,其实我认为并没有那么重要,大概一下就好了,其实差不了多少。
一、HBase Shell 介绍
优劣势
HBase shell 是 HBase 提供的一个基于命令行的交互式工具,用于管理和操作 HBase 中的数据。它的优势和劣势如下:
优势
- 方便快捷:使用 HBase shell 可以方便快捷地进行 HBase 数据库的操作和管理,而不需要编写程序或使用其他工具。
- 灵活性高:HBase shell 支持多种命令和参数组合,可以满足不同需求的操作,例如创建表、插入数据、查询数据、删除数据等。
- 易学易用:HBase shell 命令简单直观,不需要编程经验即可学习并使用。
- 跨平台支持:HBase shell 可以在任何支持 Java 的操作系统上运行,例如 Windows、Linux、MacOS 等。
- 可扩展性好:可以通过自定义脚本实现一些自动化操作,例如批量导入数据、备份数据等。
劣势
- 不利于大规模数据操作:在处理大规模数据时,由于 HBase shell 是基于命令行的工具,不适合手动输入大量命令进行操作,也不适合进行复杂的数据处理。
- 不支持事务:HBase shell 不支持事务,因此无法保证操作的原子性和一致性,而在编写程序时可以通过 Java API 实现事务。
- 不支持复杂数据类型:HBase shell 不支持复杂的数据类型,例如数组、结构体等,而 Java API 可以支持这些数据类型。
- 容易出错:由于 HBase shell 命令众多,并且命令格式有些繁琐,容易出现语法错误或执行错误。
用法
HBase shell 是 HBase 提供的一种命令行交互工具,可以使用它来管理和操作 HBase 数据库。HBase shell 支持大多数基本的数据库管理任务,例如创建和删除表、添加和删除列族、插入和检索数据等。HBase shell 使用类似于 SQL 的语法,并提供了一些额外的命令来方便用户进行一些高级操作。
HBase shell 的一些常用命令包括:
- create
table_name,column_family: 创建一个新的表- list: 列出所有可用的表
- describe
table_name: 显示表的结构信息- disable
table_name和 enabletable_name: 禁用和启用一个表- drop
table_name: 删除一个表- put
table_name,row_key,column_family:column_qualifier,value: 向表中插入一行数据- get
table_name,row_key: 按行获取表中的数据- scan
table_name: 扫描整个表并返回结果
除了这些基本命令之外,HBase shell 还支持许多其他的高级命令和选项,例如过滤器、版本控制和权限管理等。总之,HBase shell 是一个强大的工具,可以帮助用户管理和操作 HBase 数据库,它的命令集和语法都非常易于使用,可以进行快速操作和管理 HBase 数据库,但在处理大规模数据和复杂数据类型时,需要使用其他工具或编程语言进行处理。
二、Shell 命令
首先,请保证已经开启了 Hadoop 和 HBase,如果不确定,可以输入 jps,进行查看
jps
如果是下图这样子,就说明没有开启 Hadoop 和 HBase 服务
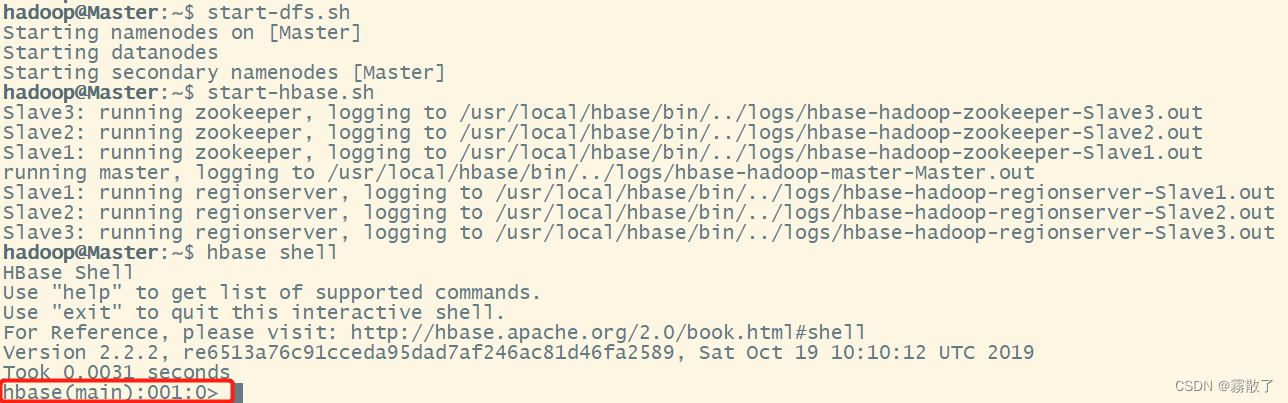
使用hbase shell命令连接到正在运行的 HBase 实例,该命令位于 HBase 安装的 bin/ 目录中。 在这个例子中,启动 HBase Shell 时打印的一些用法和版本信息被省略了。 HBase Shell 提示符以>字符结束。可以先输入以下命令,打开 Hadoop 和 HBase,并且打开使用 HBase 打开 shell 命令行
start-dfs.sh # 打开 Hadoop
start-hbase.sh # 打开 HBase
hbase shell # 用 HBase 打开 shell
看到红色框框,就说明成功使用 HBase 打开 shell 了。
创建表
在 shell 中输入 create table_name, column_family_name`` 命令,其中 table_name 为表名,column_family_name 为列族名。可以创建多个列族,用逗号分隔。我们尝试使用 shell 命令,在 HBase 中创建一张表,先输入如下命令:
create `student`,`Sname`,`Ssex`,`Sage`,`Sdept`,`course`
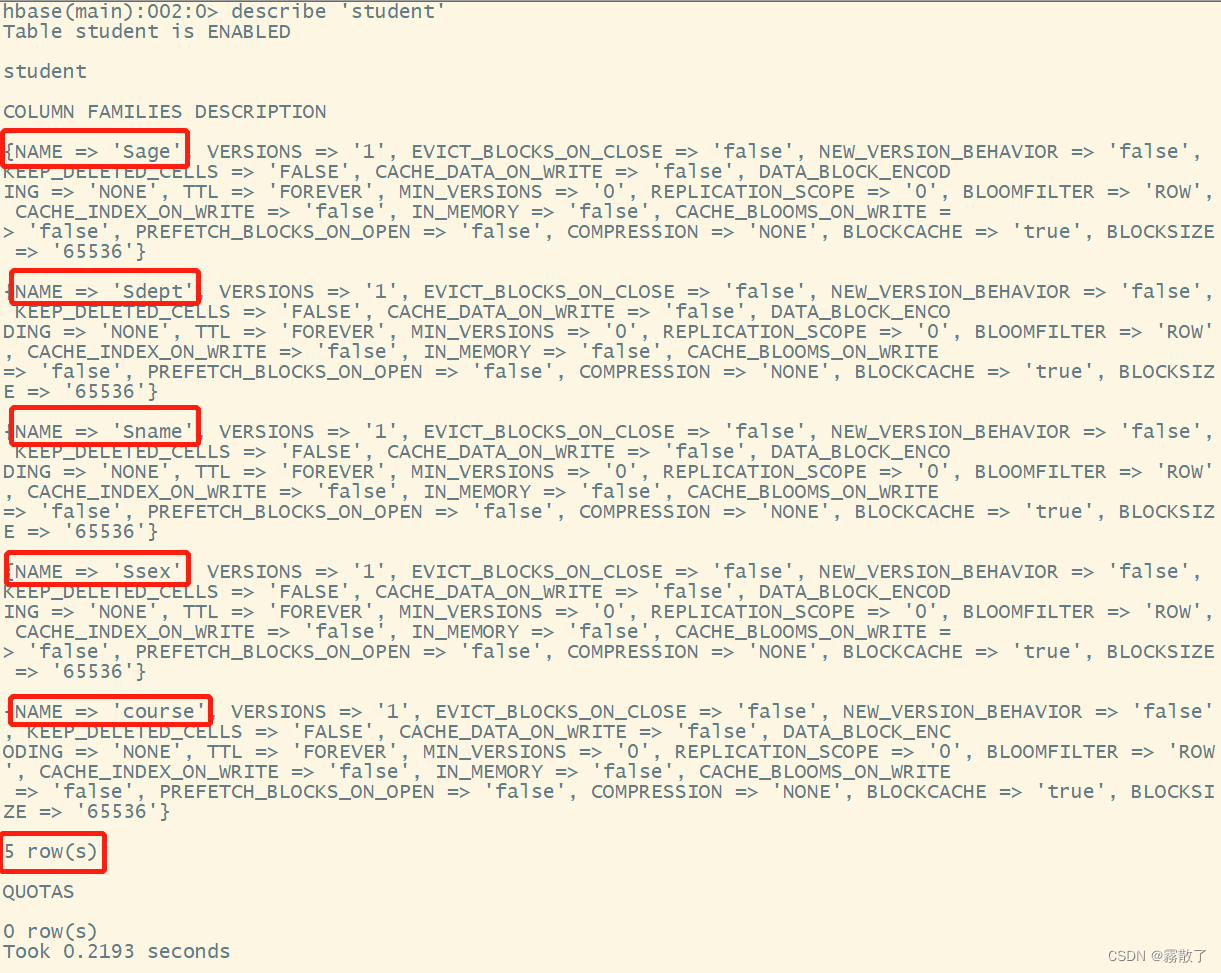
出现如图所示信息则说明运行成功。create student的意思就是创建一张新的 `table`(表),并且命名为 `studen`。而后面的Sname,Ssex,Sage,Sdept,course``,则是这张表的字段,分别为 Sname(学生姓名)、Ssex(学生性别)、Sage(学生年龄)、Sdept(学生公寓)、course(学生选课),因为HBase的表中会有一个系统默认的属性作为行键,无需自行创建,默认为 put 命令操作中表名后第一个数据。

使用list命令确认 student 表存在
list `student`
创建完 student 表后,可通过 describe 命令查看 student表的详细信息,包括配置默认值
describe `student`
输入该指令后,可以看到有五个属性。
数据库基本操作
这一部分主要主要围绕 HBase 中的 增、删、改、查 作进行说明。
添加数据
put命令:用于向 HBase 中插入一条数据或更新一条数据。put 命令的语法如下:put `table_name`, `row_key`, `column_family:column_qualifier`, `value`其中,
table_name表示数据要插入的表名;row_key表示数据所在的行键;column_family:column_qualifier表示列族和列限定符,两者之间用冒号隔开;value表示要插入的数据值。例如,向名为
test_table的表中插入一条数据,行键为row_key_1,列族为cf1,列限定符为qualifier_1,值为value_1,则可以执行如下命令:put `test_table`, `row_key_1`, `cf1:qualifier_1`, `value_1`
运行下列命令为 student 表添加学号为 202108384110,名字为 HeZaoCha 的一行数据,其中,行键为 202108384110。
put `student`,`202108384110`,`Sname`,`HeZaoCha`

下面,为 202108384110 行下的 course 列族 bigdata列添加了一个数据,值为 97。HBase 中的列由列族前缀(在本例中为course)、冒号 : 和列限定符后缀(在本例中为bigdata)组成。
put `student`,`202108384110`,`course:bigdata`,`97`

删除数据
在 HBase 中用 delete 以及 deleteall 命令进行删除数据操作,它们的区别是:
delete用于删除一个数据,是put的反向操作
delete命令:用于从 HBase 中删除一条数据。delete 命令的语法如下:delete `table_name`, `row_key`, { COLUMN => `column_family:column_qualifier`, TIMESTAMP => timestamp}其中,
table_name表示要删除的表名;row_key表示要删除的数据所在的行键;column_family:column_qualifier表示要删除的列族和列限定符,两者之间用冒号隔开;timestamp表示要删除的数据的时间戳,如果不指定,则会删除最新版本的数据。例如,删除名为
test_table的表中行键为row_key_1,列族为cf1,列限定符为qualifier_1的数据,则可以执行如下命令:delete `test_table`, `row_key_1`, { COLUMN => `cf1:qualifier_1`}
输入下面 delete 命令,并且使用 get 命令查看删除后的结果
delete `student`,`202108384110`,`Ssex` # 删除键为 20210384110 的属性 Ssex
get `student`,`202108384110` # 获取键为 202108384110 的所有属性以及属性值

deleteall操作用于删除一条记录
HBase shell 中的 deleteall 命令用于删除指定行(row)中的所有单元格(cell)数据。使用该命令需要先进入 HBase shell,并且需要先选择要操作的表。以下是 deleteall 命令的使用方法:
选择要操作的表,例如:
scan `mytable`删除指定行中的所有单元格数据,例如:
deleteall `mytable`, `myrow`
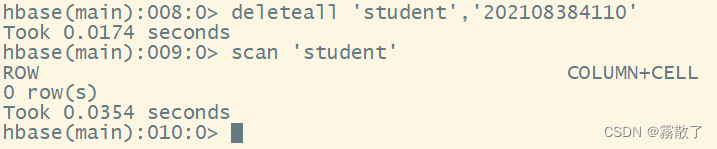
输入下面 deleteall 命令,并且使用 scan 命令查看删除后的结果
deleteall `student`,`202108384110` # 删除键为 202108384110 的记录
scan `student` # 扫描名为 student 的表
因为把整条记录删除了,所以扫描出来的表已经没有数据了。
查询数据
HBase中有两个用于查看数据的命令:
get命令,用于查看表的某一条记录
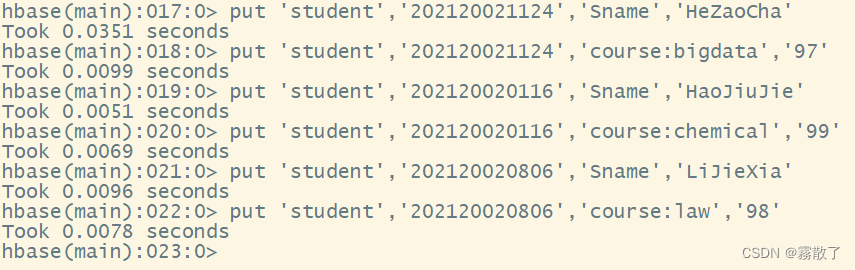
因为在上面我们已经把所有数据删除了,所以在实践之前,我们先使用 put 命令往表中添加三行数据
put `student`,`202120021124`,`Sname`,`HeZaoCha`
put `student`,`202120021124`,`course:bigdata`,`97`
put `student`,`202120020116`,`Sname`,`HaoJiuJie`
put `student`,`202120020116`,`course:chemical`,`99`
put `student`,`202120020806`,`Sname`,`LiJieXia`
put `student`,`202120020806`,`course:law`,`98`
get 命令的语法如下:
get `table_name`, `row_key`, { COLUMN => `column_family:column_qualifier`}其中,
table_name表示要查询的表名;row_key表示要查询的数据所在的行键;column_family:column_qualifier表示要查询的列族和列限定符,两者之间用冒号隔开。例如,查询名为
test_table的表中行键为row_key_1,列族为cf1,列限定符为qualifier_1的数据,则可以执行如下命令:get `test_table`, `row_key_1`, { COLUMN => `cf1:qualifier_1`}
在 shell 中输入 get table_name, row_key`` 命令,即可查询一行数据。使用 get 命令,查看学号为 202120021124 学生的记录
get `student`,`202120021124`

scan命令,用于查看某个表的全部数据
在 HBase 中,scan 命令是用于扫描表格中的数据的命令。scan 命令可以按行键范围、列限定符、时间戳等条件来过滤数据并返回结果。下面是 scan 命令的详细用法:
- 扫描整张表:在 HBase shell 中输入
scantable_name`` 命令,即可扫描整张表。- 按行键范围扫描:在 HBase shell 中输入
scantable_name, {STARTROW =>start_row_key, ENDROW =>end_row_key}命令,即可按行键范围扫描表格中的数据。- 指定列扫描:在 HBase shell 中输入
scantable_name, {COLUMNS => [column_family:column_name]}命令,即可指定列族和列名扫描表格中的数据。- 指定版本号扫描:在 HBase shell 中输入
scantable_name, {VERSIONS => number_of_versions}命令,即可指定版本号扫描表格中的数据。- 指定过滤器扫描:在 HBase shell 中输入
scantable_name, {FILTER => filter_expression}命令,即可指定过滤器扫描表格中的数据。其中,filter_expression是过滤器表达式,可以使用 HBase 内置的过滤器或自定义过滤器。- 指定最大返回行数:在 HBase shell 中输入
scantable_name, {LIMIT => max_number_of_rows}命令,即可指定最大返回行数扫描表格中的数据。- 按偏移量扫描:在 HBase shell 中输入
scantable_name, {OFFSET => offset_value}命令,即可按偏移量扫描表格中的数据。
使用 scan 命令可以扫描表中的数据。 扫描的时候可以添加一些选项来限制你的扫描,只输入表名,可以将所有数据数据都提取出来。
scan `student`
可以从图中看出,列以及列值都被扫描提取出来了。

删除表
如果要删除表或更改其设置,以及在某些其他情况下,需要首先使用 disable 命令禁用该表。如果想把被禁用的表重新启动,可以使用 enable 命令重新启用它。
删除表的命令如下
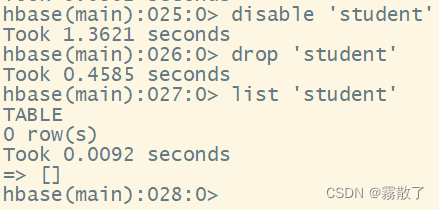
disable `student` # 禁用名为 student 的表
drop `student` # 移除名为 student 的表
list `student` # 查看 student 表是否存在
如图所示:student 表已经被删除。
以上是 HBase shell 的一些基本命令,可以用于表的数据管理、查询等操作。需要注意的是,HBase shell 对于大规模数据的操作效率较低,不适合处理海量数据,建议使用编程接口或其他大数据处理框架进行处理。
查询表历史数据
查询历史数据有很多种不同的用法,下面我们主要介绍两种:
- 查询指定时间范围数据
以下是在HBase shell中查询指定时间范围数据的详细步骤:
- 选择要查询的表
使用"list"命令查看所有的表,然后使用"scan"命令扫描表中的所有数据。例如,如果要查询名为"mytable"的表中的数据,可以使用以下命令:
scan 'mytable'
- 指定时间范围
HBase存储的是按时间顺序排列的数据,因此可以通过指定时间范围来查询数据。可以使用"TIMERANGE"关键字来指定时间范围。例如,如果要查询2019年1月1日到2019年1月31日之间的数据,可以使用以下命令:
scan 'mytable', { TIMERANGE => [1483200000, 1485801599] }其中,1483200000 和 1485801599 分别是两个不同时间的时间戳。这将返回符合指定时间范围的所有数据。
- 查询指定版本范围数据
以下是在 HBase shell 中查询指定版本范围数据的详细步骤:
- 选择要查询的表
使用 “list” 命令查看所有的表,然后使用 “scan” 命令扫描表中的所有数据。例如,如果要查询名为 “mytable” 的表中的数据,可以使用以下命令:
scan 'mytable'
- 指定版本范围
使用 “VERSIONS” 关键字可以指定要查询的版本数,例如想要查询某一列族(column family)下面某一列(column)的前 5 个版本,可以使用以下命令:
get 'mytable', 'rowkey', { COLUMN => 'cf:col', VERSIONS => 5}其中,‘rowkey’ 是待查询的行(row)的 rowkey,‘cf’ 是待查询的列族(column family),‘col’ 是待查询的列(column),5 表示要查询的版本数。该命令将返回符合条件的前 5 个版本的数据。
接下来我们演示第二种查询指定版本范围数据的用法。
首先,在 HBase shell 中创建一个名为 teacher 的表,并在该表中创建一个列族 Tname,并且指定该列族最多保存 5 个版本的数据。
create 'teacher',{
NAME=>'Tname',VERSIONS=>5}

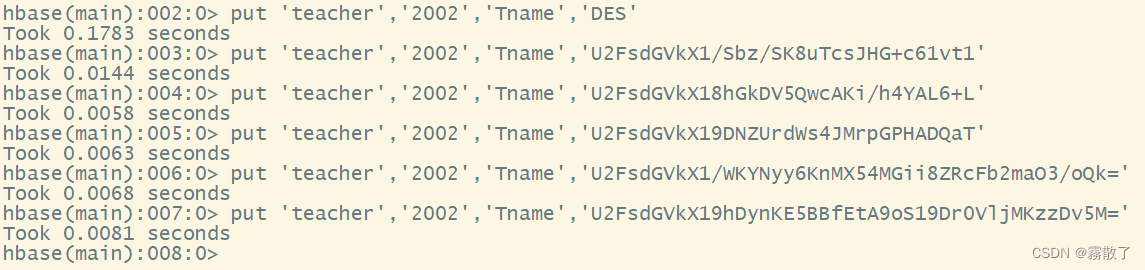
然后,使用 put 命令向 teacher 表中插入数据并更新数据,从而生成历史版本数据。下面我们生成六个版本的数据
put 'teacher','2002','Tname','DES'
put 'teacher','2002','Tname','U2FsdGVkX1/Sbz/SK8uTcsJHG+c61vt1'
put 'teacher','2002','Tname','U2FsdGVkX18hGkDV5QwcAKi/h4YAL6+L'
put 'teacher','2002','Tname','U2FsdGVkX19DNZUrdWs4JMrpGPHADQaT'
put 'teacher','2002','Tname','U2FsdGVkX1/WKYNyy6KnMX54MGii8ZRcFb2maO3/oQk='
put 'teacher','2002','Tname','U2FsdGVkX19hDynKE5BBfEtA9oS19Dr0VljMKzzDv5M='
最后,在查询时,我们可以选择指定要查询的历史版本数。如果未指定,则默认只查询最新的数据。可以选择的历史版本数为 1 到 5,如下命令所示
get 'teacher','2002',{
COLUMN=>'Tname',VERSIONS=>5}

退出 HBase 数据库表操作
最终退出数据库操作时,只需输入 exit 命令即可。需要注意的是,此处的退出指退出对数据库表的操作,而不是停止启动 HBase 数据库的后台运行。
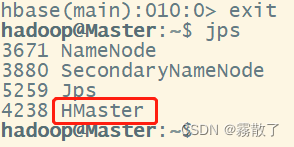
exit
退出后,我们输入 jps 可以看到 HMaster 仍然在运行,所以我们只是退出了 HBase shell,退出了对数据表的操作,而不是停止了 HBase 的运行。
三、Java API 编程实践
HBase 是一个基于 Hadoop 的分布式 NoSQL 数据库,它采用列式存储方式,适合处理大规模数据。下面是 HBase 中 Java API 编程的实践过程:
- 引入 HBase 相关依赖包:需要在项目中引入 HBase 相关依赖包,包括 hbase-client、hbase-common、hbase-protocol 等。
- 创建 HBase 配置对象:在代码中创建 HBase Configuration 对象,并设置 HBase 集群的相关信息,如 HBase 的 Zookeeper 地址、HBase Master 地址等。
- 创建 HBase 连接对象:使用 HBaseConfiguration 对象创建 HBase 连接对象 Connection。
- 获取 HBase 表对象:通过 Connection 获取 HBase 表对象 Table,可以对表进行操作,如插入、查询、删除等。
- 插入数据:使用 Put 对象插入数据到 HBase 表中。首先创建 Put 对象,然后设置行键和列族、列限定符和值,最后将 Put 对象插入到 HBase 表中。
- 查询数据:使用 Get 对象查询HBase表中的数据。首先创建 Get 对象,然后设置行键、列族和列限定符,最后通过 Table.get() 方法获取数据。
- 删除数据:使用 Delete 对象删除HBase表中的数据。首先创建 Delete 对象,然后设置行键、列族和列限定符,最后通过 Table.delete() 方法删除数据。
- 批量操作数据:HBase 支持批量操作数据,可以使用 Batch 操作类将多个 Put、Get、Delete 对象批量操作。Batch 操作类有 Batch.Callback 接口,可以在批量操作后调用回调函数进行操作结果的处理。
以上就是 HBase 中 Java API 编程实践的基本过程。在实际开发中,还需要根据具体的需求进行更加复杂的操作,如使用 HBase Filter 进行数据过滤和查询、使用HBase Coprocessor 进行数据处理和计算等。
下面就用一个例子来让大家具体感受一下操作过程,本次实例采用的开发工具是 Eclipse。具体如下:
- 下载并安装 HBase:首先,您需要下载并安装 HBase。您可以从 HBase 官方网站下载 HBase。
- 创建 Java 项目:在 Eclipse 中创建一个新的 Java 项目。
- 添加 HBase 依赖项:在 Java 项目中,右键单击“项目”并选择“属性”。然后,在“Java 构建路径”下选择“库”,单击“添加外部 JAR”并选择您在步骤1中下载的 HBase JAR 文件。
- 编写 HBase 代码:现在,您可以在 Java 项目中编写 HBase 代码。
- 运行和调试代码:您可以使用 Eclipse 的调试功能来运行和调试 HBase 代码。在 Eclipse 中,单击“调试”按钮来启动调试器。您可以设置断点、单步执行和检查变量值等。
具体流程就如上面所示了,如果还没有安装 Eclipse 的朋友,可以点这里找到 Eclipse 的安装方法。
创建 Java 项目
首先,启动 Eclipse,启动命令如下
cd /usr/local/eclipse # 进入 Eclipse 安装目录
./eclipse # 启动 Eclipse
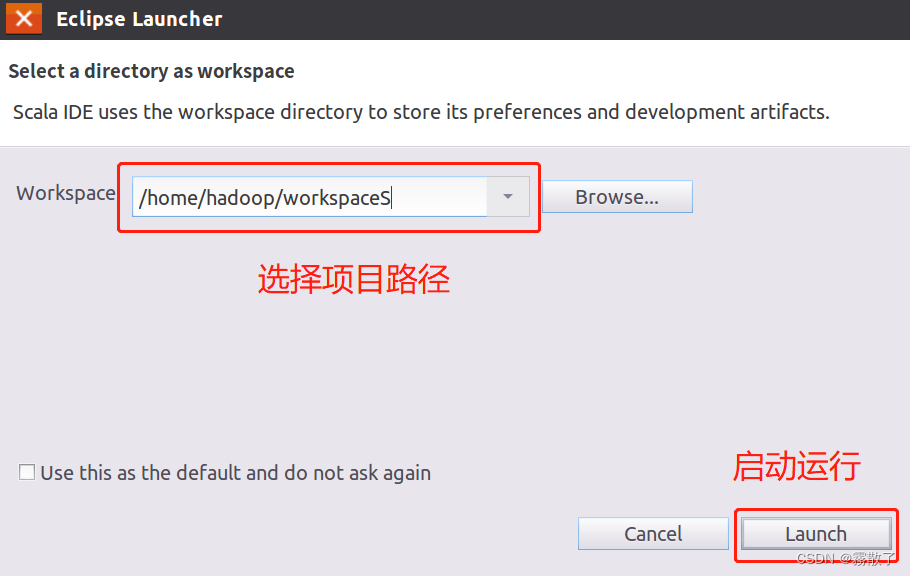
启动以后,出现如下图所示界面,点击界面右下角的 Launch 按钮运行 Eclipse
请点击软件界面位于顶部的 File 菜单,接着在弹出的下拉子菜单中选择 New,再在子菜单中找到 Project 并进行选择。
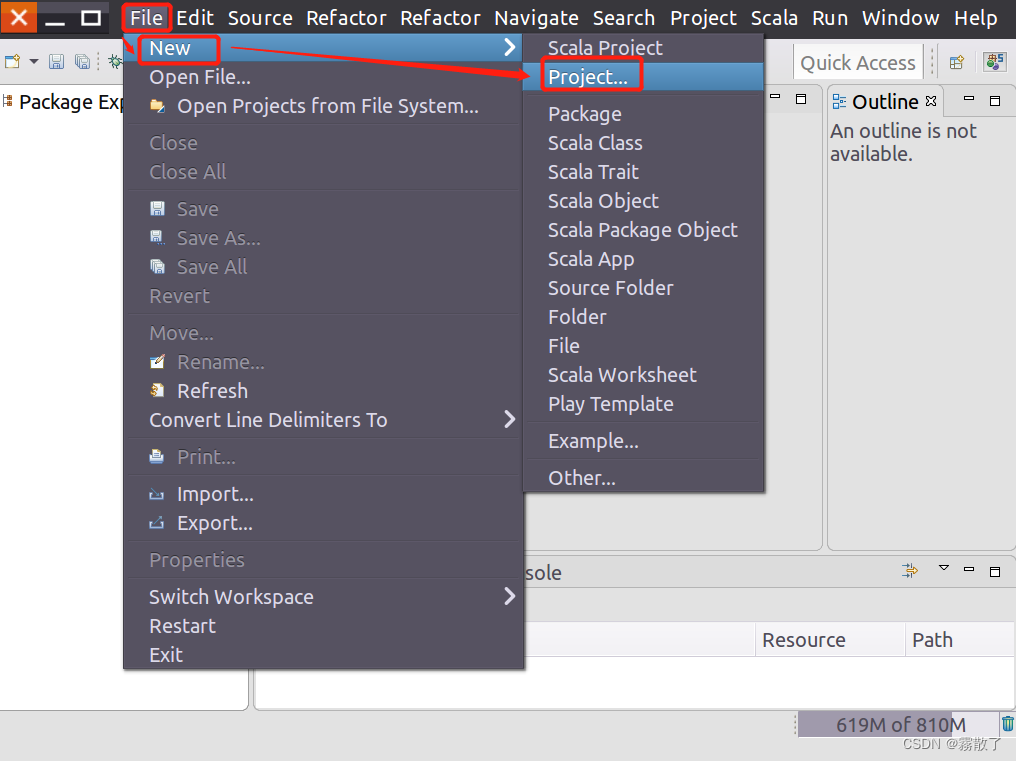
选择 Java Project ,声明这个项目是一个 Java 项目,然后选择 Next 进入下一步。
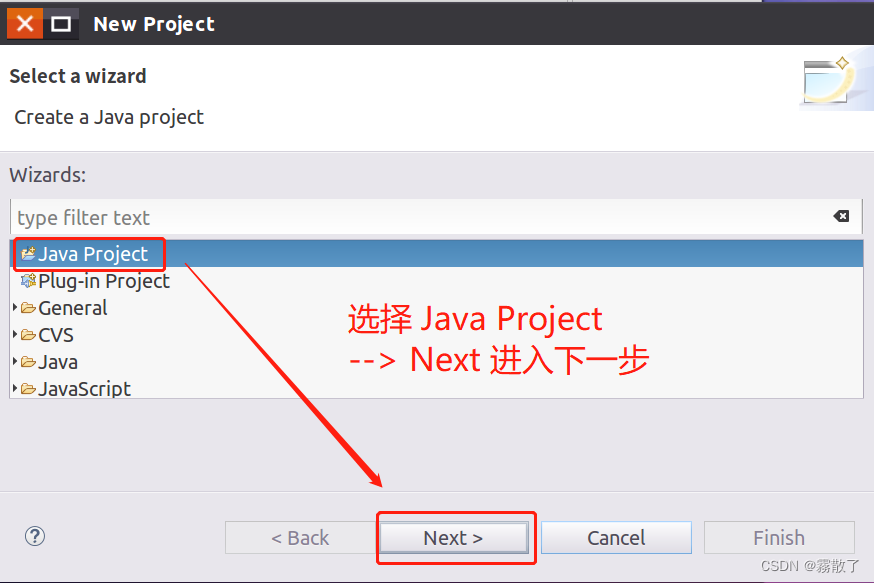
在下面的 Java 工程创建对话框中,你可以输入 HBaseExample 作为项目名称,并在 JRE 选项卡中选择第二项 Use a project specific JRE,使用项目特定的 JRE。最后,点击屏幕底部的 Next 按钮进入下一步。
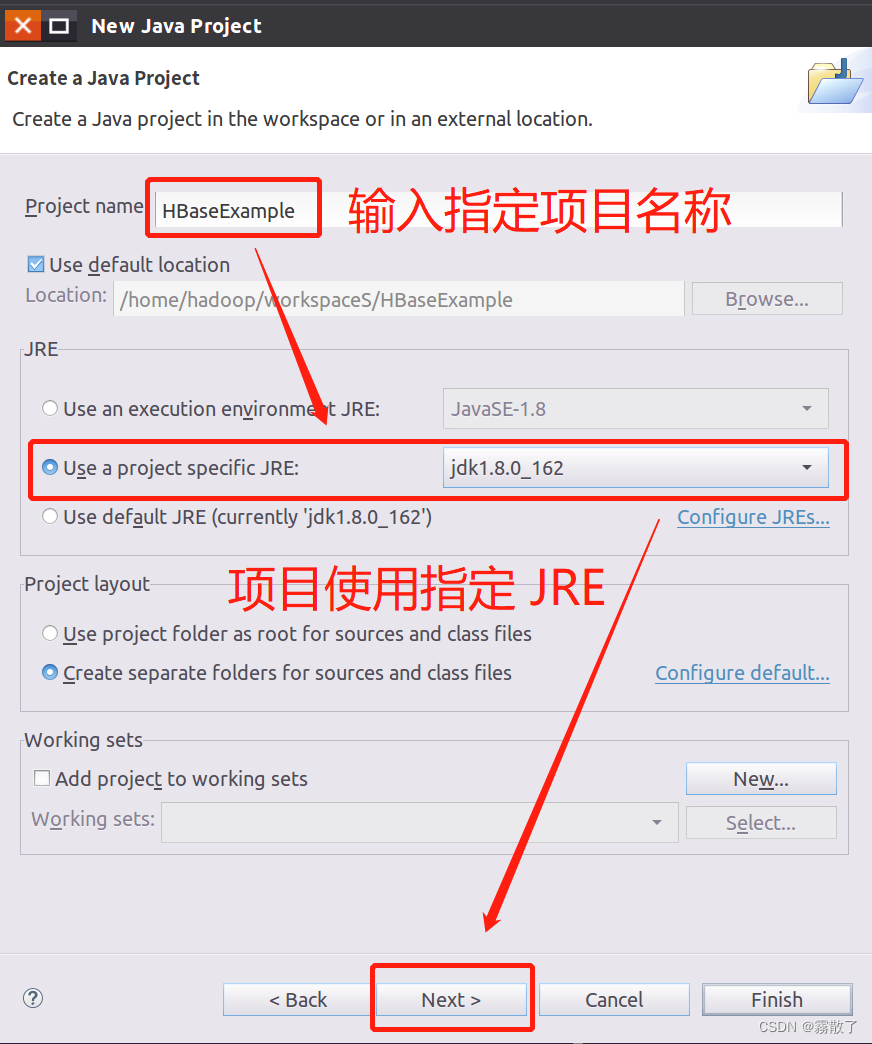
添加 HBase 依赖项
在出现的窗口中(如下图所示),请单击 Libraries 选项卡,并单击屏幕右侧的 Add External JARs... 按钮,添加外部JAR包。
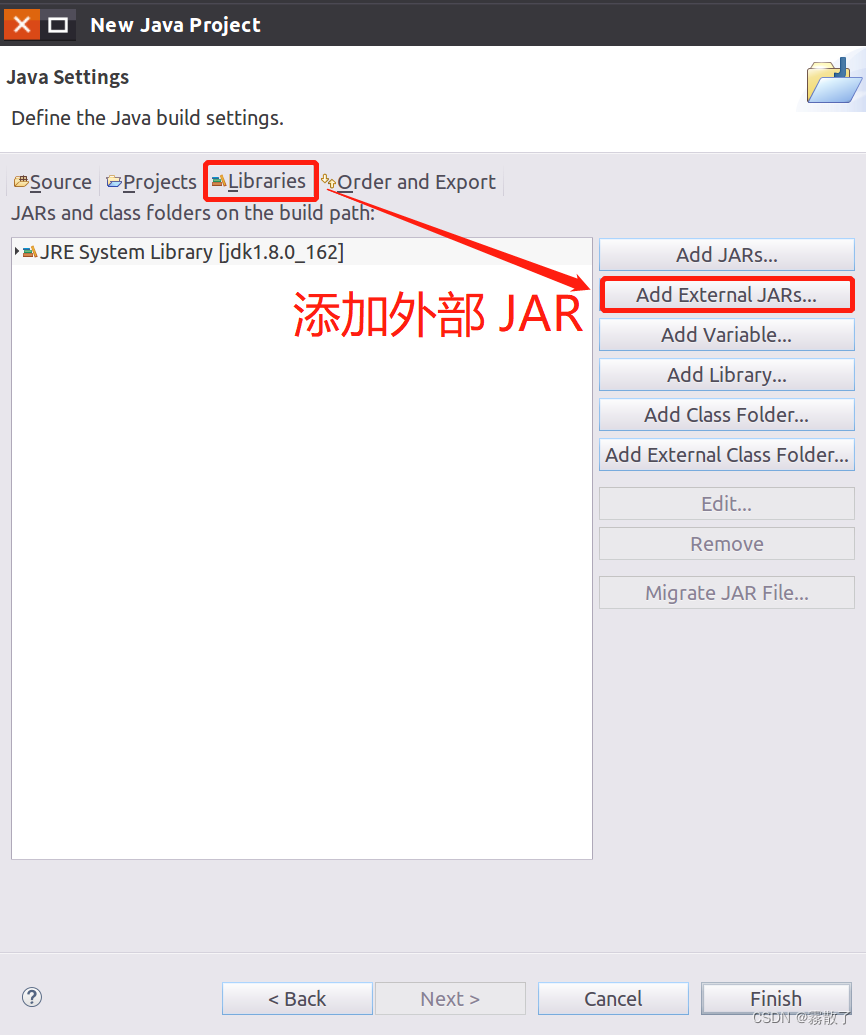
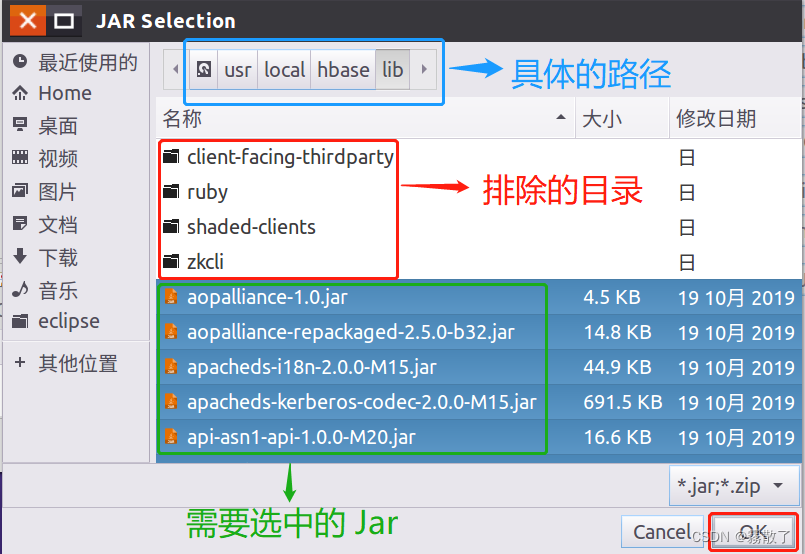
在弹出的 JAR Selection 界面中(如下图所示),前往 /usr/local/hbase/lib ,HBase 的安装目录,选定此目录下除了 client-facing-thirdparty、ruby、shaded-clients 和 zkcli 这四个目录以外的所有 jar 文件(可以使用 Ctrl + A 进行全选,再按住 Ctrl 键点击余下四个目录进行取消选中),随后,点击屏幕底部的 OK 按钮。
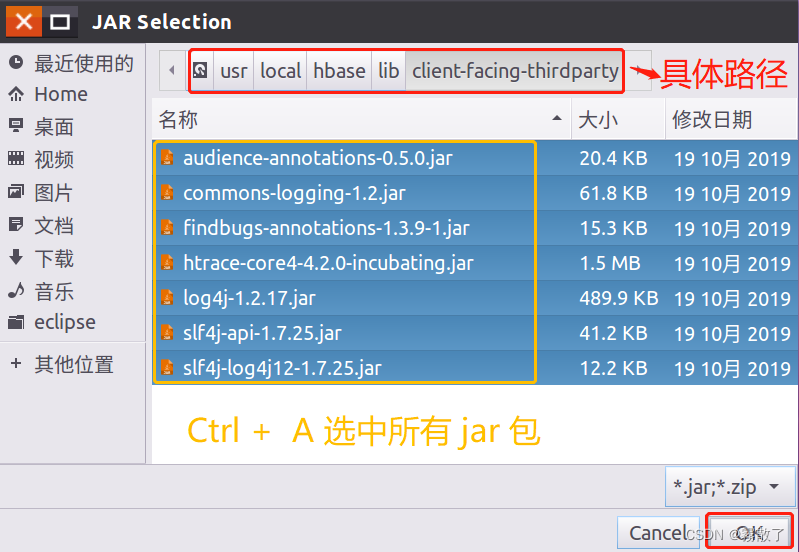
接着,再次点击 Add External JARs... 按钮,在 JAR Selection 界面中,选择进入 client-facing-thirdparty 文件夹,在 client-facing-thirdparty 文件夹中(参考下图),使用 Ctrl + A 勾选所有的 jar 文件,然后点击页面底部的 OK 按钮。
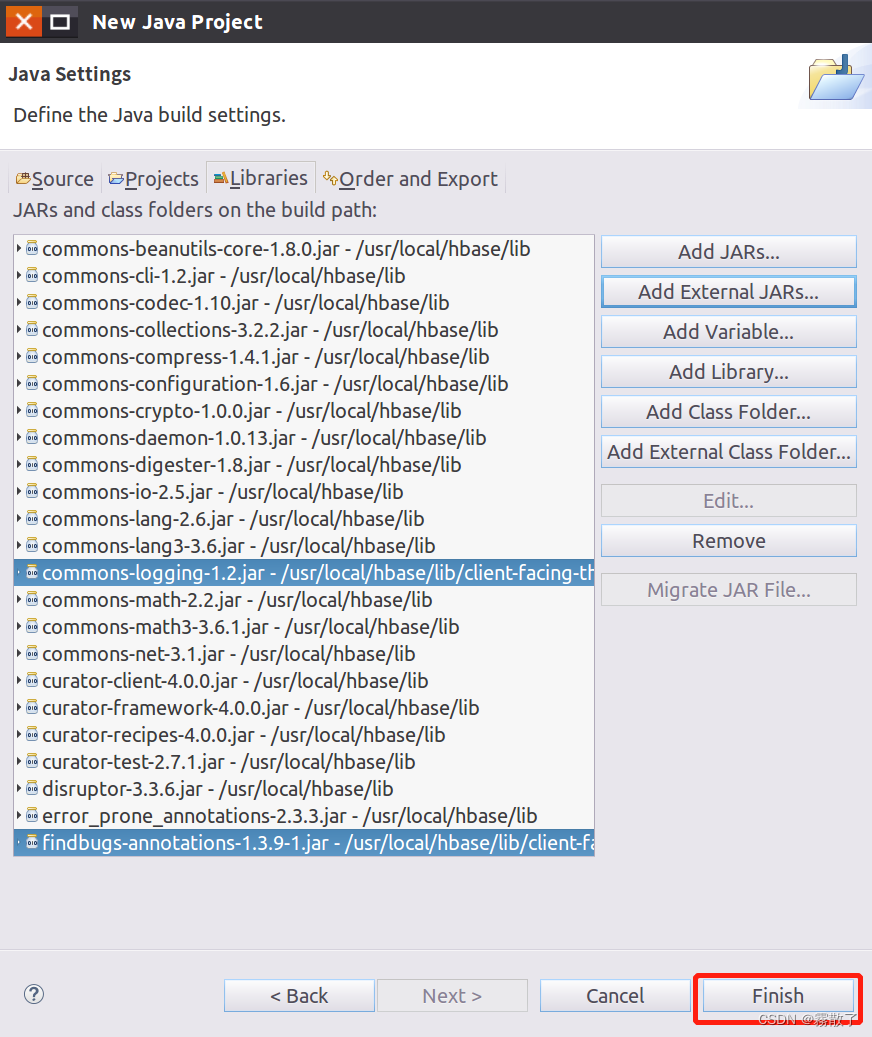
完成上述操作添加完 jar 包后,回到下图的界面,点击窗口底部的 Finish 按钮,完成项目的创建。
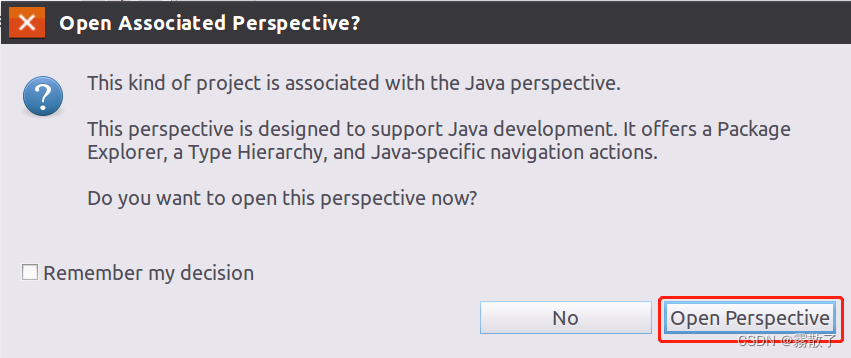
然后会弹出一个提示窗口(如下图所示)
这种项目与Java 透视图相关联。
此透视图旨在支持Java 开发。它提供了一个 PackageExplorer、一个 Type Hierarchy 和特定于 Java 的导航操作。
现在要打开这个透视图吗?
我们点击 Open Perspective 按钮,打开视图。
编写 HBase 代码
找到刚才创建好的工程名称 HBaseExample 项目文件夹,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择 New 按钮,然后选择 Class
新建一个 Java 类。
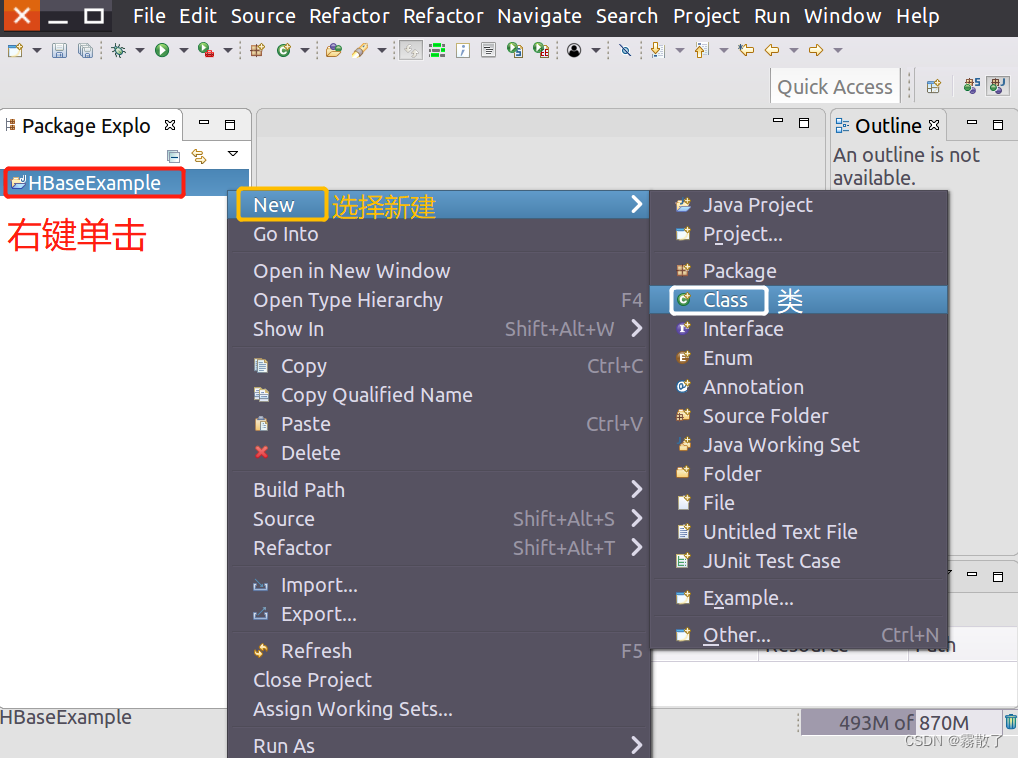
在下图显示的 New Java Class 对话框中,输入 ExampleForHBase 到 Name 文本框,最后点击底部的 Finish 按钮。
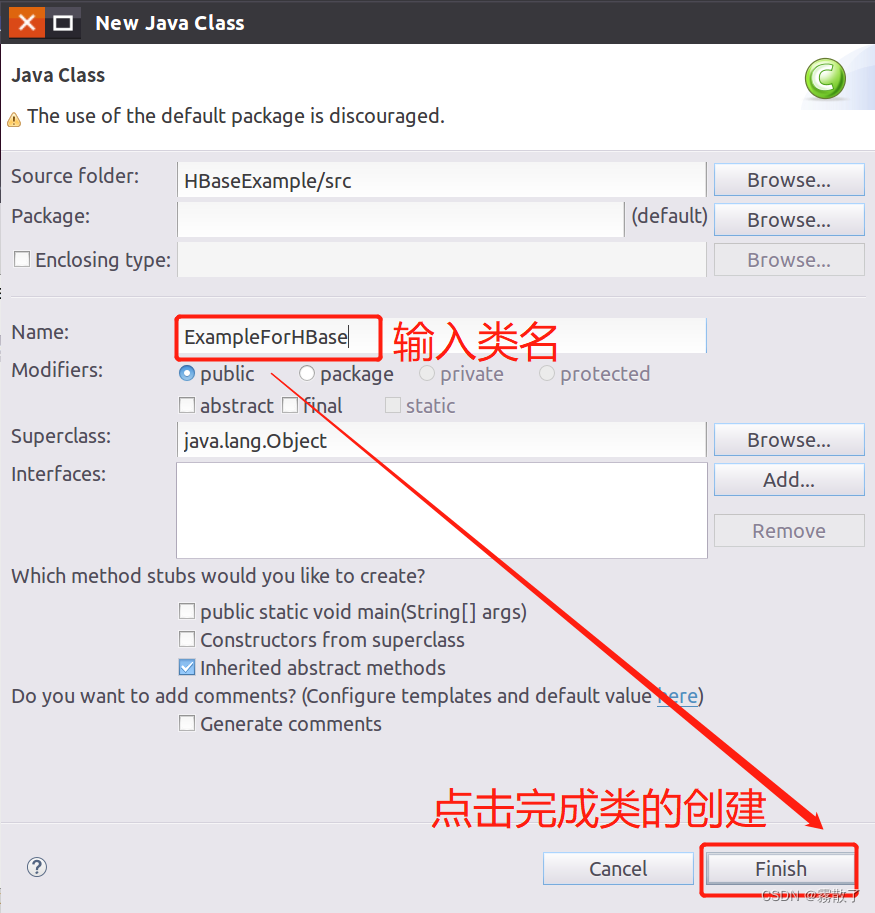
选中上面创建的新的 Java 类,然后在代码窗口中输入下列 Java 代码,然后保存,如下图所示
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class ExampleForHBase {
public static Configuration configuration;
public static Connection connection;
public static Admin admin;
public static void main(String[] args)throws IOException{
init();
// 创建 student 表
createTable("student",new String[]{
"score"});
// 向 student 表中添加数据
insertData("student","HeZaoCha","score","English","88");
insertData("student","HeZaoCha","score","Math","86");
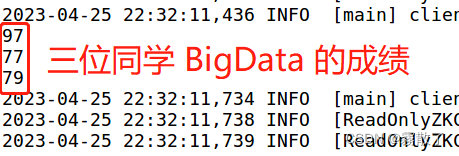
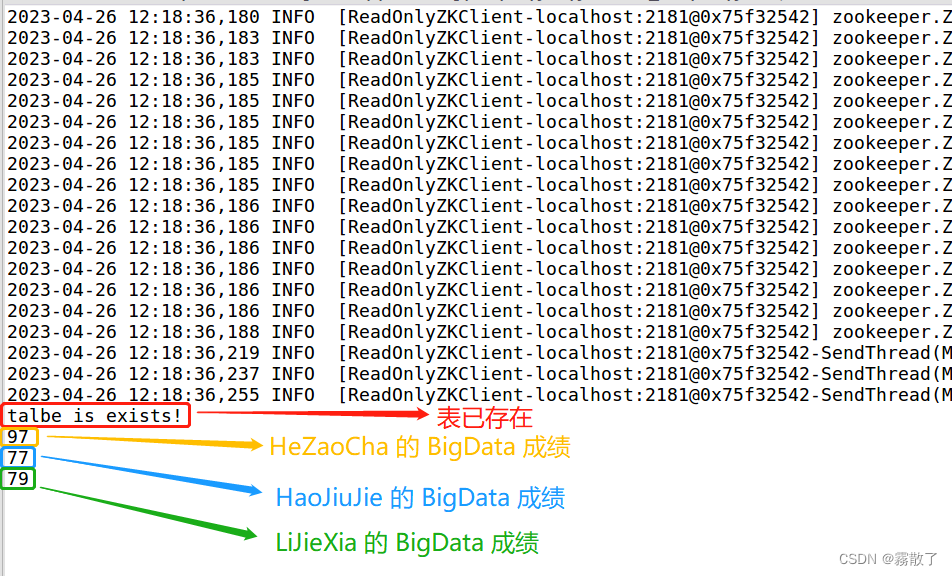
insertData("student","HeZaoCha","score","BigData","97");
insertData("student","HaoJiuJie","score","English","99");
insertData("student","HaoJiuJie","score","Math","80");
insertData("student","HaoJiuJie","score","BigData","77");
insertData("student","LiJieXia","score","English","66");
insertData("student","LiJieXia","score","Math","87");
insertData("student","LiJieXia","score","BigData","79");
// 获取 student 表中的数据
getData("student", "HeZaoCha", "score","BigData");
getData("student", "HaoJiuJie", "score","BigData");
getData("student", "LiJieXia", "score","BigData");
close();
}
public static void init(){
configuration = HBaseConfiguration.create();
configuration.set("hbase.rootdir","hdfs://localhost:9000/hbase");
try{
connection = ConnectionFactory.createConnection(configuration);
admin = connection.getAdmin();
}catch (IOException e){
e.printStackTrace();
}
}
public static void close(){
try{
if(admin != null){
admin.close();
}
if(null != connection){
connection.close();
}
}catch (IOException e){
e.printStackTrace();
}
}
public static void createTable(String myTableName,String[] colFamily) throws IOException {
TableName tableName = TableName.valueOf(myTableName);
if(admin.tableExists(tableName)){
System.out.println("talbe is exists!");
}else {
TableDescriptorBuilder tableDescriptor = TableDescriptorBuilder.newBuilder(tableName);
for(String str:colFamily){
ColumnFamilyDescriptor family =
ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes(str)).build();
tableDescriptor.setColumnFamily(family);
}
admin.createTable(tableDescriptor.build());
}
}
public static void insertData(String tableName,String rowKey,String colFamily,String col,String val) throws IOException {
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowKey.getBytes());
put.addColumn(colFamily.getBytes(),col.getBytes(), val.getBytes());
table.put(put);
table.close();
}
public static void getData(String tableName,String rowKey,String colFamily, String col)throws IOException{
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(rowKey.getBytes());
get.addColumn(colFamily.getBytes(),col.getBytes());
Result result = table.get(get);
System.out.println(new String(result.getValue(colFamily.getBytes(),col==null?null:col.getBytes())));
table.close();
}
}
运行和调试代码
在开始运行程序之前,需要启动 HDFS 和 HBase,打开终端,输入下列命令。
start-dfs.sh # 启动 HDFS
start-hbase.sh # 启动 HBase
开启服务后,输入 jps 可以查看进程服务是否开启

然后,如下图所示,右键单击代码窗口,在弹出的菜单中选择 Run As,再在弹出的菜单中点击 1 Java Application 按钮,开始运行程序。

有一个错误,这个错误就是无法找到 localhost 的位置,所以找不到主机的路由。
java.net.NoRouteToHostException: 没有到主机的路由
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1141)
2023-04-25 15:14:16,749 WARN [ReadOnlyZKClient-localhost:2181@0x184cf7cf] zookeeper.ReadOnlyZKClient (ReadOnlyZKClient.java:exec(192)) - 0x184cf7cf to localhost:2181 failed for get of /hbase/hbaseid, code = CONNECTIONLOSS, retries = 3
2023-04-25 15:14:17,748 INFO [ReadOnlyZKClient-localhost:2181@0x184cf7cf-SendThread(localhost:2181)] zookeeper.ClientCnxn (ClientCnxn.java:logStartConnect(1032)) - Opening socket connection to server localhost/10.13.235.141:2181. Will not attempt to authenticate using SASL (unknown error)
2023-04-25 15:14:19,647 WARN [ReadOnlyZKClient-localhost:2181@0x184cf7cf-SendThread(localhost:2181)] zookeeper.ClientCnxn (ClientCnxn.java:run(1162)) - Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
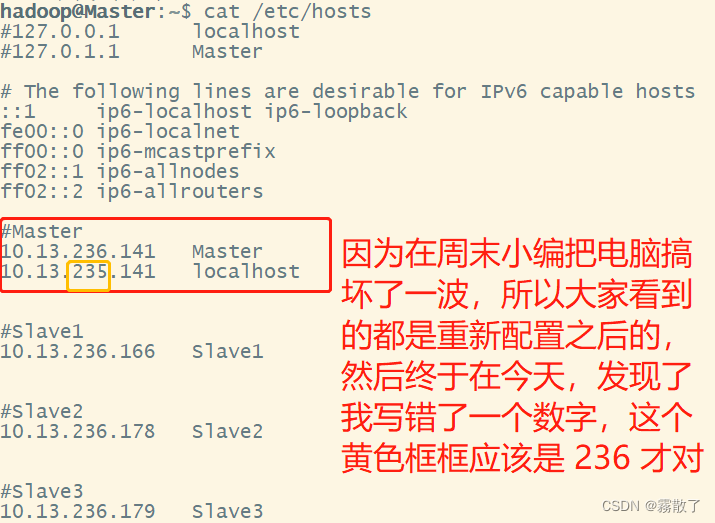
小小检查一波,发现是我 hosts 文件配置写错了,因为小编电脑在周末出了点问题,其实就是单纯地操作不当导致的后果,然后我又重新配置了一遍,再写的这篇博客,挺抱歉我写错了一个数字导致浪费了一些时间,这里大家引以为鉴就好,应该不会有人错这个了。如果不是这样报错的话,可能是防火墙未关闭,也请大家注意防火墙的问题。
解决完问题后,再次运行
java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1141)
2023-04-25 15:49:48,359 WARN [ReadOnlyZKClient-localhost:2181@0x184cf7cf] zookeeper.ReadOnlyZKClient (ReadOnlyZKClient.java:exec(192)) - 0x184cf7cf to localhost:2181 failed for get of /hbase/hbaseid, code = CONNECTIONLOSS, retries = 1
2023-04-25 15:49:49,356 INFO [ReadOnlyZKClient-localhost:2181@0x184cf7cf-SendThread(Master:2181)] zookeeper.ClientCnxn (ClientCnxn.java:logStartConnect(1032)) - Opening socket connection to server Master/10.13.236.141:2181. Will not attempt to authenticate using SASL (unknown error)
2023-04-25 15:49:49,357 WARN [ReadOnlyZKClient-localhost:2181@0x184cf7cf-SendThread(Master:2181)] zookeeper.ClientCnxn (ClientCnxn.java:run(1162)) - Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
到这里我逐渐发现不对劲了,所以我重新做了一遍尝试,就是重新进行配置,这次我把 hbase-site.xml 改成了下面这个样子,唯一的改动就是我把 hbase.zookeeper.quorum 参数多加了一个 Master,理由就是,他也是 ZooKeeper 的一份子。
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Master,Slave1,Slave2,Slave3</value>
<description>The directory shared by RegionServers. </description>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hadoop/tmp/base/zookeeper</value>
<description>
Property from ZooKeeper's config zoo.cfg. The directory where the
snapshot is stored.
</description>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Master:9000/hbase</value>
<description>The directory shared by RegionServers. </description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>
The mode the cluster will be in. Possible values are false:
standalone and pseudo-distributed setups with managed Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see
hbase-env.sh)
</description>
</property>
</configuration>
效果如图所示:

然后再次启动 HBase,再次运行实例,就可以看见如下输出了。
运行之后,我们遇到了一个小小的 warming,这个就是:无法为您的平台加载本机Hadoop库...在适用的情况下使用内置Java类

WARN [main] util.NativeCodeLoader (NativeCodeLoader.java:<clinit>(62)) - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决办法是,在 Hadoop 的环境配置文件下修改 HADOOP_OPTS=$HADOOP_OPTS -Djava.library.path 指向 Hadoop 的本地库
cd /usr/local/hadoop/ # 进入 Hadoop 的安装目录
vim etc/hadoop/hadoop-env.sh # 修改 Hadoop 的环境配置文件
下面的双引号不能去掉,一定注意,双引号不能去掉,否则会报错 -Djava.library.path=/usr/local/hadoop/lib/native': 不是有效的标识符
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/usr/local/hadoop/lib/native"

修改完后,将修改与三个节点同步,然后再次启动 HDFS 和 HBase,运行实例,发现还是没有解决问题。关闭 HBase 和 Hadoop,然后删除 Hadoop 安装目录下的 tmp 目录,重新进行 Namenode 的格式化。
cd /usr/local/hadoop # 进入 Hadoop 的安装目录
hdfs namenode -format # 格式化 HDFS
再次运行实例,发现还是未能解决问题。
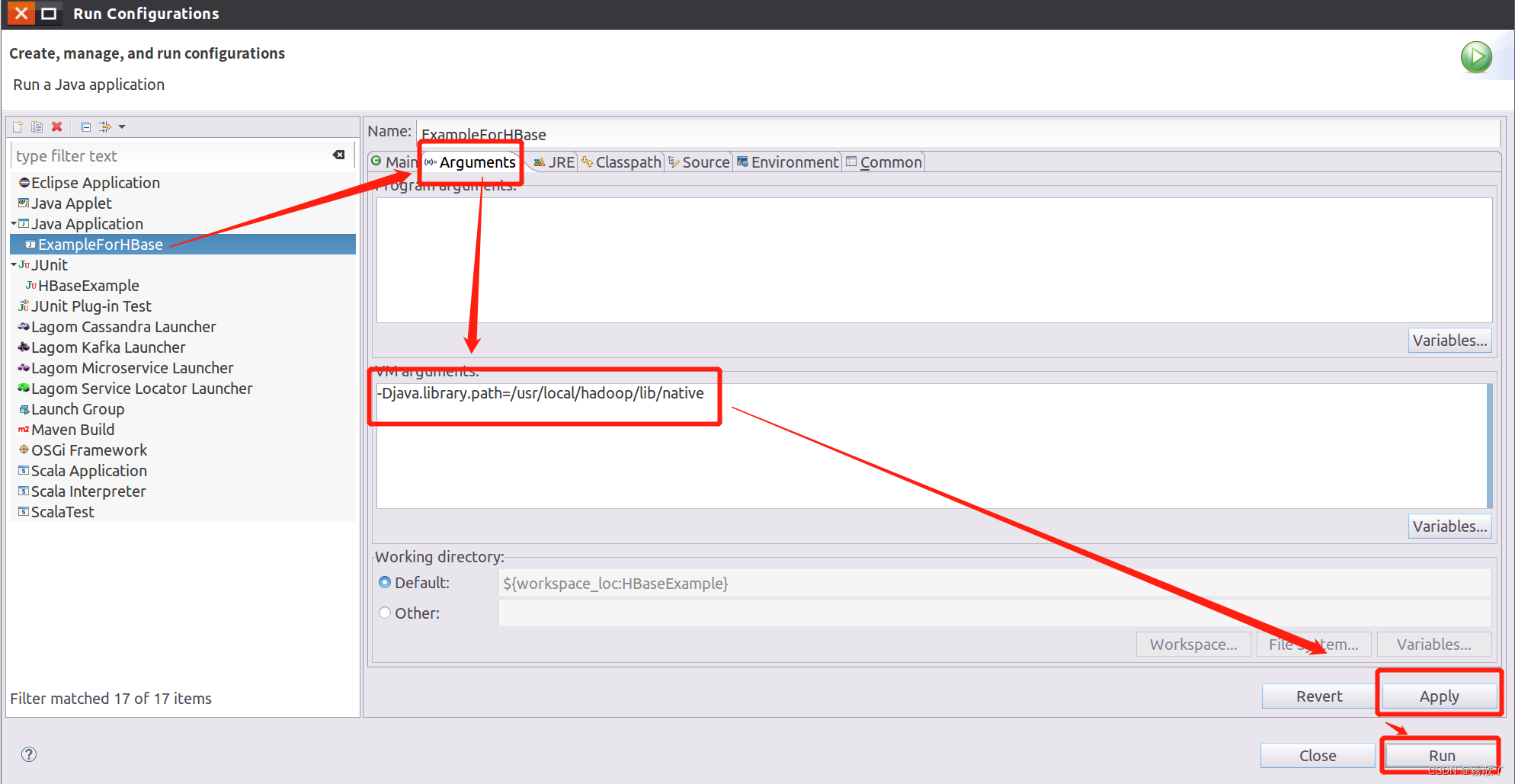
尝试下一种办法,右键单击代码框,在菜单中选择 Run As,然后在下一级菜单中选择 Run Configurations...

找到我们的实例,然后选择 Arguments,在 VM arguments 框内输入 -Djava.library.path=/usr/local/hadoop/lib/native,然后点击右下角的 Apply --> Run。
-Djava.library.path=/usr/local/hadoop/lib/native
再次运行实例,发现警告已经解决。
四、写在最后
能看到这里,说明大家学习真的很认真;小编在这里说声抱歉,因为我重新安装了电脑的缘故,整个虚拟机都是重新开始的,所以很多细节上的问题我也没特别的去注意,也是到后面才发现前一篇博客也有不少错的地方,在这里给大家说一声抱歉。这篇博客,大家就当着一个小朋友纠错的过程吧。再次感谢大家能看到这里,该说不说的,这篇博客有一些彩蛋,都是致敬我的一些兄弟和…某人的,我很希望大家能找到这个彩蛋,这说明你们也算是我比较亲近的朋友了;但是又不是特别希望你们能找到这个彩蛋,因为这毕竟有点秘密不方便给别人看。