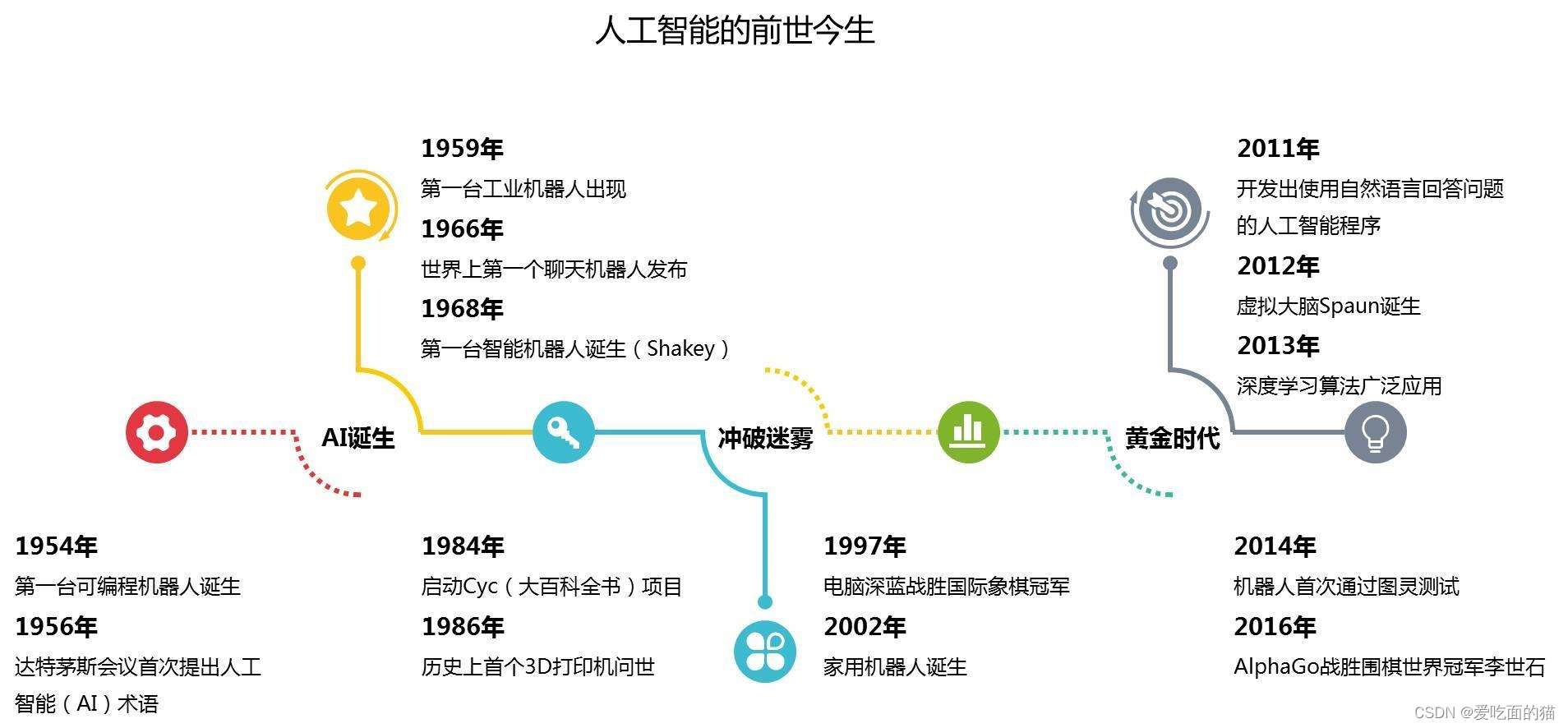
发展历史
在电影如 终结者、机械公敌 中,机器人为什么能够像人一样思考?其实这就是人工智能。人工智能多方面:例如人脸识别系统、肺部影响CT,手机中的美颜、垃圾邮件拦截、自动驾驶 。
上世纪30-50年代,随着计算机科学、生物神经科学、数学的发展,人工智能第1次进入到人们视野。
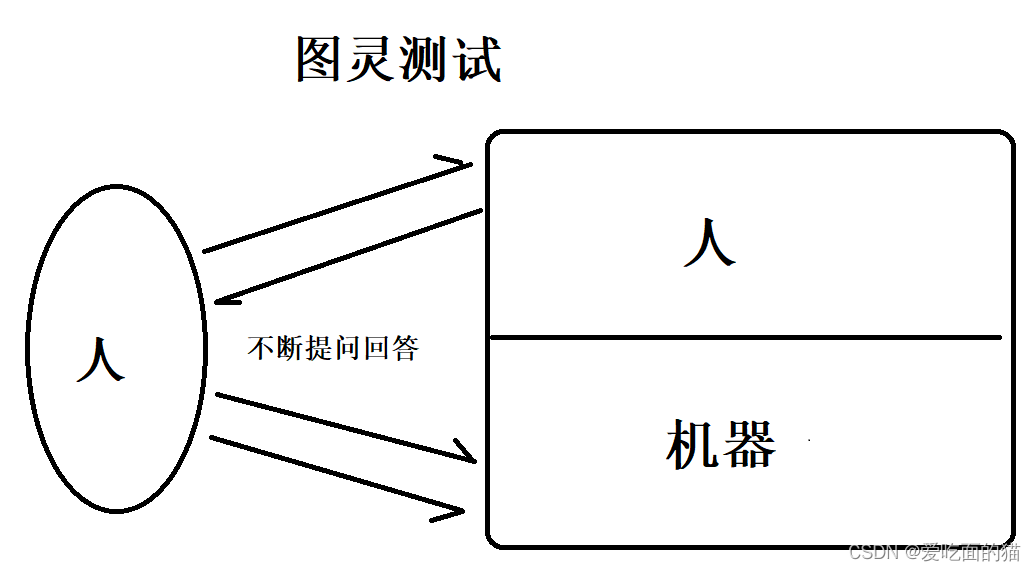
1950年,图灵发出提问:机器能够像人一样思考? 因此提出一种测试方法,即图灵测试。
图灵测试:让一个人和两个东西交流,通过一系列的提问和回答,让此人判断这两个东西中,哪个是真人,哪个是机器。通过判断,如果这个人无法判读是真人还是机器的时候,就说明这个机器通过了图灵测试。
1957年3位科学家,召开了达特矛斯会议,会议主题就是:机器能够像人类一样思考?并且在这次会议上确定一个词:"人工智能"。从这次会开始,人工智能进入第一次大发展时期。

1997年IBM发明机器人深蓝,和人类下象棋,结果战胜了12年的国际象棋冠军卡斯帕罗夫。人工智能再次复苏。
当然这一次的人工智能复苏和发展是得益于最近几十年计算机科学以及各种算法的改进,尤其是在人工智能算法领域,比如加拿大多伦多大学的辛顿,将反向传播算法BP引用于人工智能,纽约大学的杨立坤,将卷积神经网路引用于人工智能,加拿大蒙特利尔大学的本吉奥。

经过发展在特定领域如图像识别领域,语音识别领域等,都有长足发展。那么计算机是如何做到这一点的呢?这本质上其实是一个数学问题。
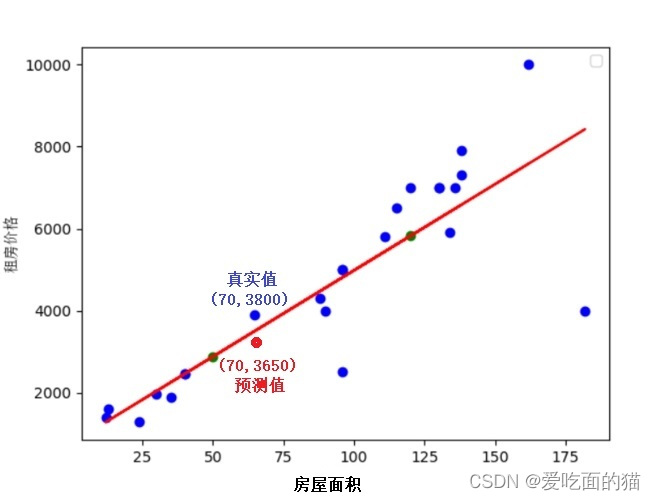
此处以处理回归问题为例,如预测房价即给你一套房屋信息,预测房子价格。
首先要知道房价取决于哪些关键因素,如城市、乡村、面积大小、楼层、小区环境等。
假如房价就取决于面积,那么给了很多这样的关于面积和房屋价格的数据,根据这些数据能不能找到一个函数,让这个函数能够满足所有的点或大部分点?
这个函数就是直线y=wx+b,此时引入两个参数斜率w和截距b。
当然这个直线不可能过所有的点,甚至1个点都不过,它和实际情况是有差别的。
例如真实情况是70平房屋价格是3800即(70,3800),而估计的价格是70平房屋价格是3650元即(70,3650),这个两个价格之间就有差异,这个差异就是△y1,还有很多其他点,都有差异,分别是△y2、△y3....,△yi
当然直线也不是固定的,可能过所有点,或者是够能过大部分的点,或者过一部分点,其他点在这个直线的两侧,或者一个点也不过,但所有点在直线的两侧。那么哪条直线最合适呢?
此时就要看这些直线中能让 预测值和真实值 之间的综合误差是最小的。这条直线就是我们需要的,而综合误差就是损失函数。
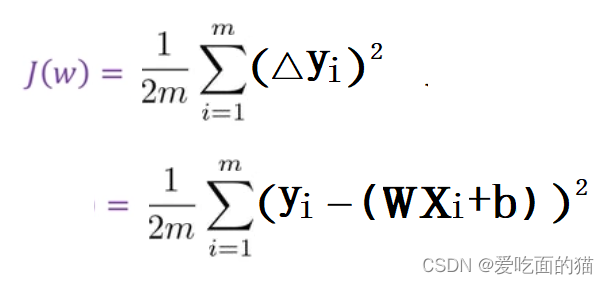
此时损失函数中xi,yi都是已知的数据(房屋面积和价格),同时我们引入了参数w和b,不同的w和b就是不同的直线,此时我们希望找到一个w和b,使得所有的误差综合损失最小,损失最小,这条直线就是最符合房屋面积和价格的关系。
问题:
如何找到这个最合适的w和b,使得损失函数最小呢?
其实就是最小二乘法。
只是目前我们只有两个参数,比较好算,如果参数非常多,我们又如何优化这些参数呢?
解决方案是:使用梯度下降法
梯度下降法
此时我们以 w 作为x轴,损失函数 作为y轴,此时它是一个二次函数,如图。

梯度下降法过程:
- 首先我们给定1个w0,
- 然后在w0出进行求偏导
- 我们进行求偏导得到1个结果dJ/dw0。偏导结果表示函数变换的速度,速度越快,倾斜率越大,偏导的结果页越大,说明这个点距离最低点越远
- 此时我们需要一个新的点,这个新的点是在原来的点基础上减小一点,即 w1 = w0 -ηdJ/dw0
- 如果w1不是最低点,则需要一个新的点,这个新的点是在w1基础上减小一点,即 w2 = w1 -ηdJ/dw0
- 依次类推,直到函数变换率变为最小,也就是wi点的斜率即 dJ/dw 约等于 0 或等于0 或 wi约等于 wi-1
- 最终求得的wi使得变化率最小,这个wi就是我们要找的最低点 即最优解。
- 实际上在进行优化过程中, w和b是同时进行优化的,是在一个三维的空间进行优化的。
在实际中,房价不单单是和面积有关,还和楼层、小区环境、地理位置等多个因素。因此我们的方程就变成了 y = w1x1 +w2x2+...+wnxn+b,此时参数页有w和b变为 (w1,w2,...,wn)和 b。
y = w1x1 +w2x2+...+wnxn+b 的损失函数和梯度下降法调优的方式都是雷同的。我们通过给定的所有数据((x1,x2,...,xn),y)训练,找到使得 y = w1x1 +w2x2+...+wnxn+b 的损失函数最小的参数(w1,w2,...,wn)和 b。此时我们得到的最优参数(w1,w2,...,wn)和 b,及使用梯度下降法得到最优解的过程一同保存,这个就是我们得到的最优模型。
生活中还有分类问题,分类问题其实也是画一条线,在线一边的是某个类,在另一边的是某个类。例如肿瘤分类是良性肿瘤还是恶性肿瘤。给出很多良性肿瘤和恶性肿瘤的照片,这些是照片的图像数据矩阵就是我们的X,照片的种类如良性就是Y,因此我们需要通过损失函数和梯度下降法找到使得损失函数最小的参数W和B。
所以人工智能问题可以把它化为一个数学问题,而这个数学问题就是寻找参数的最优值,所用的方法就是梯度下降法。
