使用 IPvlan 网络
IPvlan 驱动为用户提供了全面控制 IPv4 和 IPv6 寻址的能力。 IPvlan 让操作者能完全操控二层(数据链路层)网络的 vlan 标签,甚至也提供了三层(网络传输层)路由控制给感兴趣的用户。对于抽象出物理限制的 overlay 部署,请看 多主机 overlay 驱动。
IPvlan 是久经考验的网络虚拟化技术的一个新变化。Linux 的实现是非常轻量级的,因为它们不是使用传统的 Linux 网桥进行隔离,而是与一个 Linux 接口或子接口相关联,以执行网络之间的分离和与物理网络的连接。
IPvlan 提供了许多独特的功能,并为各种模式的进一步创新提供了大量空间。这些方法的两个厉害之处在于,绕过 Linux 网桥后带来的对性能的正向影响、以及减少移动部件后带来的简易性。移除传统上位于 Docker 主机接口和容器接口之间的桥,留下一个由容器接口组成的简单设置,直接连接到 Docker 主机接口。这种结果很容易被外部服务所访问,因为在这些情况下不需要端口映射。
先决条件
- 本页中的例子都针对单台主机。
- 所有的例子都可以在运行 Docker 的单一主机上执行。任何使用子接口(如
eth0.10)的例子都可以用eth0或 Docker 主机上任何其他有效的父接口代替。带有 . (下点号)的子接口是即时创建的。-o parent指定父接口的选项也可以不在docker network create命令里出现,此时驱动会创建一个 假的(dummy)接口,使本地主机的连接能够执行文章的例子。 - 内核需求:
- 使用
uname -r来检查当前的内核版本。 - IPvlan Linux 内核 v4.2+ (早期的内核也能支持不过会有缺陷)
- 使用
IPvlan 二层模式(L2 mode)用例
下图展示了一个 IPvlan L2 模式的例子。驱动可以用 -d driver_name 来指定。在这个例子中,使用了 -d ipvlan。
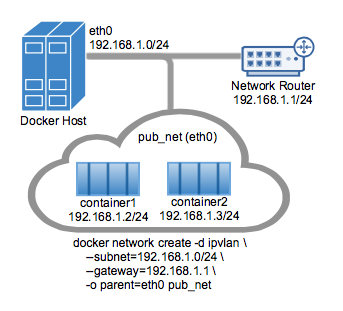
下面要说的例子中,使用 -o parent=eth0 来指定父接口后配置如下:
$ ip addr show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
inet 192.168.1.250/24 brd 192.168.1.255 scope global eth0
通过在 docker network create 命令的 --subnet 来使用宿主机接口的网络。容器会连接到用 -o parent= 选项指定的接口的同一网络上去。
创建一个 IPvlan 网络并启动一个容器连接它:
# IPvlan (-o ipvlan_mode= 如果没指定默认就是 L2 模式)
$ docker network create -d ipvlan \
--subnet=192.168.1.0/24 \
--gateway=192.168.1.1 \
-o ipvlan_mode=l2 \
-o parent=eth0 db_net
# 在 db_net 网络上启动一个容器
$ docker run --net=db_net -it --rm alpine /bin/sh
# 注意:容器里面 ping 不通底层宿主机的网卡
# 它们被 Linux 有意地隔离了以获得额外的隔离性
IPvlan 的默认模式是 二层(l2). 如果 -o ipvlan_mode= 留空,默认的模式就会被采用。类似的,如果 --gateway 留空,网络上第一个可用的地址将被设置为网关。举例,如果网络创建时提供的子网是 --subnet=192.168.1.0/24 那么容器收到的网关就会是 192.168.1.1。
为了帮助理解这种模式是如何跟其他主机交互的,请参考下图。图里展示了两台主机同样采用的2层片段(layer 2 segment)以及 IPvlan L2 模式。
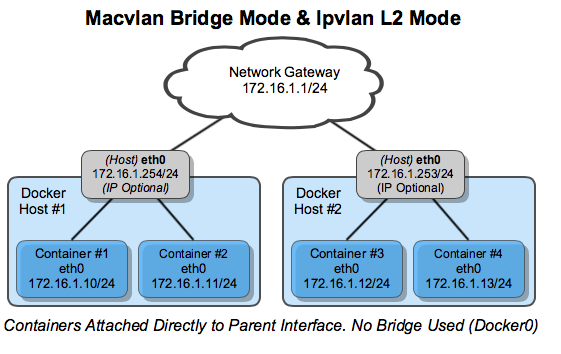
下面的指令会创建一个跟之前的 db_net 一样的网络,使用的是驱动的默认配置r --gateway=192.168.1.1 和 -o ipvlan_mode=l2。
# IPvlan (-o ipvlan_mode= 如果没指定默认就是 L2 模式)
$ docker network create -d ipvlan \
--subnet=192.168.1.0/24 \
-o parent=eth0 db_net_ipv
# 用后台模式启动一个指定名字的容器
$ docker run --net=db_net_ipv --name=ipv1 -itd alpine /bin/sh
# 启动第二个容器,然后用容器名去ping第一个容器
# 来看一下docker自带的名字解析功能
$ docker run --net=db_net_ipv --name=ipv2 -it --rm alpine /bin/sh
$ ping -c 4 ipv1
# 注意:容器里面 ping 不通底层宿主机的网卡
# 它们被 Linux 有意地隔离了以获得额外的隔离性
驱动程序还支持 --internal 标志,它将完全隔离网络上的容器与该网络外部的任何通信。由于网络隔离与网络的父接口紧密相关,在 docker 网络创建中不使用 -o parent= 选项的结果与 --internal 选项完全相同。如果没有指定父接口或者使用了 --internal 标志,就会为用户创建一个netlink 类型的 假的(dummy) 父接口,并将其作为父接口使用,有效地隔离了网络。
下面两个 docker network create 例子会创建同样的网络,你可以附加容器上去:
# 留空 '-o parent=' 会创建一个隔离的网络
$ docker network create -d ipvlan \
--subnet=192.168.10.0/24 isolated1
# 指明 '--internal' 标志同样:
$ docker network create -d ipvlan \
--subnet=192.168.11.0/24 --internal isolated2
# 甚至 '--subnet=' 也可以留空
# 172.18.0.0/16的IPAM子网将被分配
$ docker network create -d ipvlan isolated3
$ docker run --net=isolated1 --name=cid1 -it --rm alpine /bin/sh
$ docker run --net=isolated2 --name=cid2 -it --rm alpine /bin/sh
$ docker run --net=isolated3 --name=cid3 -it --rm alpine /bin/sh
# 连接任意的容器,使用 `docker exec` 来开始一个 shell
$ docker exec -it cid1 /bin/sh
$ docker exec -it cid2 /bin/sh
$ docker exec -it cid3 /bin/sh
IPvlan 802.1q 中继(trunk)二层模式(L2 mode)用例
从结构上看,IPvlan 二层模式(L2 mode)中继与 Macvlan 在网关和 L2 路径隔离方面是一样的。有一些细微的差别,IPvlan 对 ToR 交换机的 CAM 表(MAC 交换表)压力、每个端口一个 MAC 和主机的父接口上的 MAC 耗尽都是有利的。在 802.1q 中继方案上,两者看起来是一样的。两种模式都执行了Tag标准,并与物理网络无缝集成,以实现底层集成和硬件供应商插件集成。
同一VLAN上的主机通常在同一个子网中,并且几乎总是根据其安全策略被分组在一起。在大多数情况下,一个多层应用程序被分层到不同的子网中,因为每个进程的安全配置文件需要某种形式的隔离。例如,如果你的信用卡处理与前端网络服务器被托管在同一个虚拟网络上,这将导致监管合规有关的问题,同时也绕过了长期以来分层防御深度架构的最佳实践。在使用 Overlay 驱动时,VLANs或等价的 VNI(虚拟网络标识符)是隔离租户流量(tenant traffic)的第一步。
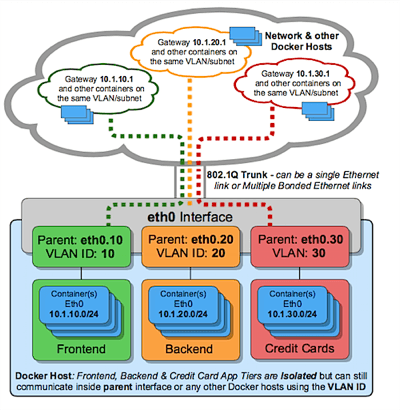
带有 VLAN 标签的 Linux 子接口可以是已经存在的,也可以是在你调用 docker network create时创建的。docker network rm将删除该子接口。像 eth0 这样的父接口不会被删除,只有 netlink 父索引大于0的子接口会被删除。
对于驱动程序来说,添加/删除 VLAN 子接口的格式需要是 interface_name.vlan_tag。其他不是 VLAN 的子接口的命名可以用作指定的父接口,但是当调用 docker network rm 时,该链接不会被自动删除。(对这段话的理解参考文末的【手动创建 802.1q 链接】)
选择使用现有的父 VLAN 子接口的或让 Docker 管理它们的选项,能使用户能够亲自完全管理 Linux 接口和网络,或让 Docker 创建和删除 VLAN 父子接口(netlink ip link)而不需要用户太费力。
举例:用 eth0.10 表示 eth0 的一个子接口,标记为VLAN id为10。相应的 ip link 命令是 ip link add link eth0 name eth0.10 type vlan id 10。
这个例子创建了 VLAN 标记的网络,然后启动两个容器来测试容器之间的连接。不同的 VLAN 如果没有路由器在两个网络之间进行路由,就不能互相 ping 通。按照 IPvlan 的设计,默认的命名空间是无法到达的,以便将容器命名空间与底层主机隔离。
VLAN ID 20
在第一个被 Docker 宿主机标记和隔离的网络中, eth0.20 是用 -o parent=eth0.20指定的 VLAN id 20 标记的父接口。可以使用其他命名格式,但需要使用 ip link 或Linux配置文件手动添加和删除链接。只要 -o parent 存在,任何东西都可以使用,只要它符合Linux netlink的要求。
# 现在,你可以正常将网络和主机添加到被标记的主(子)接口上。
$ docker network create -d ipvlan \
--subnet=192.168.20.0/24 \
--gateway=192.168.20.1 \
-o parent=eth0.20 ipvlan20
# 在两个不同的终端中,各自启动一个Docker容器,现在这两个容器可以互相ping了。
$ docker run --net=ipvlan20 -it --name ivlan_test1 --rm alpine /bin/sh
$ docker run --net=ipvlan20 -it --name ivlan_test2 --rm alpine /bin/sh
VLAN ID 30
在第二个网络中,它被 Docker 宿主机标记和隔离, eth0.30 是父接口,用 -o parent=eth0.30指定的VLAN id 30 标记。 ipvlan_mode= 默认为2层模式(L2 mode) ipvlan_mode=l2。也可以明确地设置它,结果与下面的例子所示相同。
# 现在,你可以正常将网络和主机添加到被标记的主(子)接口上。
$ docker network create -d ipvlan \
--subnet=192.168.30.0/24 \
--gateway=192.168.30.1 \
-o parent=eth0.30 \
-o ipvlan_mode=l2 ipvlan30
# 在两个不同的终端中,各自启动一个Docker容器,现在这两个容器可以互相ping了。
$ docker run --net=ipvlan30 -it --name ivlan_test3 --rm alpine /bin/sh
$ docker run --net=ipvlan30 -it --name ivlan_test4 --rm alpine /bin/sh
(主机的)网关在容器内被设置为默认网关。该网关通常是网络上的一个外部路由器。
$$ ip route
default via 192.168.30.1 dev eth0
192.168.30.0/24 dev eth0 src 192.168.30.2
例子: 多子网 IPvlan 二层模式在同一子网启动两个容器,并互相ping。为了让 192.168.114.0/24 到达 192.168.116.0/24,它需要一个二层模式的外部路由器。三层模式(L3 mode)则可以在用 -o parent=指定了同一个父接口的子网间进行路由。
网络路由器上的次选地址是很常见的,因为一个地址空间有可能有用完的情况,此时可以在三层的 VLAN接口上增加一个次选地址,或者通常称为 "交换机虚拟接口"(SVI)。
$ docker network create -d ipvlan \
--subnet=192.168.114.0/24 --subnet=192.168.116.0/24 \
--gateway=192.168.114.254 --gateway=192.168.116.254 \
-o parent=eth0.114 \
-o ipvlan_mode=l2 ipvlan114
$ docker run --net=ipvlan114 --ip=192.168.114.10 -it --rm alpine /bin/sh
$ docker run --net=ipvlan114 --ip=192.168.114.11 -it --rm alpine /bin/sh
(讨论下来)一个要点是,操作者有能力将他们的物理网络映射到他们的虚拟网络中,以便将容器整合到他们的环境中,而不需要进行操作上的大改动。网络运维(NetOps )将一个 802.1q 中继(trunk) 放入Docker主机。该虚拟链接将是网络创建中传递的 -o parent= 。对于无标记(非VLAN)的链接,就像 -o parent=eth0 一样简单,或者对于有VLAN ID的802.1q中继线,每个网络被映射到网络中相应的 VLAN/Subnet。
一个例子是,网络运维(NetOps)提供了用于 VLAN 在以太网链接上传递给Docker宿主机的 VLAN ID 和相关的子网。在配置 Docker 网络时,这些值被插入 docker network create 命令中。这些是持久的配置,每次 Docker 引擎启动时都会应用,这就减轻了管理复杂的配置文件的负担。网络接口也可以通过预先创建来手动管理,Docker 网络将永远不会修改它们,并将它们作为父接口。从网络运维(NetOps)设定到 Docker 网络命令的映射示例如下:
- VLAN: 10, 子网: 172.16.80.0/24, 网关: 172.16.80.1
--subnet=172.16.80.0/24 --gateway=172.16.80.1 -o parent=eth0.10
- VLAN: 20, 子网: 172.16.50.0/22, 网关: 172.16.50.1
--subnet=172.16.50.0/22 --gateway=172.16.50.1 -o parent=eth0.20
- VLAN: 30, 子网: 10.1.100.0/16, 网关: 10.1.100.1
--subnet=10.1.100.0/16 --gateway=10.1.100.1 -o parent=eth0.30
IPvlan 三层模式(L3 mode)例子
IPvlan 将需要将路由分配到每个端点(endpoint)。驱动程序只建立了IPvlan 三层模式(L3 mode)的端口,并将容器连接到接口上。而整个集群的路由的分配,超出了这个单一主机范围的驱动程序的初始实现。在三层模式下,Docker 宿主机非常类似于一个在容器中启动新的网络的路由器。它们所处的网络,如果没有路由分配,上游网络是不会知道的。对于那些好奇三层 IPvlan 将如何融入容器网络的人,请看下面的例子。
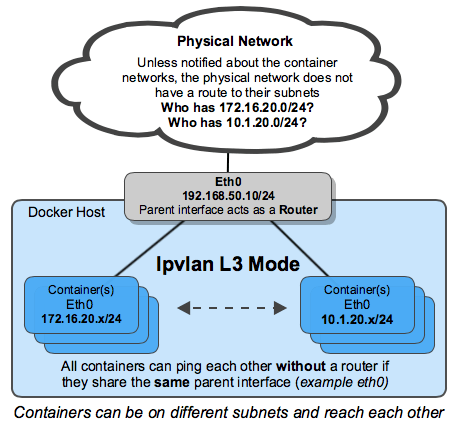
IPvlan L3模式会丢弃所有广播和多播流量。仅仅是这个原因就使IPvlan 三层模式成为那些寻求大规模和可预测的网络整合的首选。它是可预测的,并且由于没有桥接,因此能够更长时间的正常运行。桥接环路是高调故障的罪魁祸首,而根据故障域的大小,这些故障往往很难定位。这是由于BPDU(桥接端口数据单元,生成树协议)的级联性质,它在整个广播域(VLAN)中泛滥,以寻找和阻止拓扑环。消除桥接域,或者至少把它们隔离在一对 ToR(架顶交换机)上,将减少难以排除的桥接不稳定性。IPvlan 二层模式非常适合仅隔离在一对可提供无环非阻塞结构的ToRs中的VLAN。更进一步的选择,是通过IPvlan 三层模式在边缘进行路由,从而将故障域仅限于本地主机。
- 三层模式需要在一个单独的子网中作为默认命名空间,因为它需要在默认命名空间中有一个指向IPvlan父接口的 netlink 路由。
- 本例中使用的父接口是
eth0,它位于192.168.1.0/24子网。注意docker 网络与eth0不在同一个子网。 - 与IPvlan 二层模式不同,不同的子网/网络只要共享同一个父接口
-o parent=,就可以相互ping通。
$$ ip a show eth0
3: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:50:56:39:45:2e brd ff:ff:ff:ff:ff:ff
inet 192.168.1.250/24 brd 192.168.1.255 scope global eth0
- 传统的网关对三层模式的IPvlan接口没有什么意义,因为不允许有广播流量。正因为如此,容器的默认网关指向了容器的eth0设备。详情请看下面L3容器内部的
ip route或ip -6 route的CLI输出。
必须显示指定 -o ipvlan_mode=l3 ,因为 IPvlan 的默认模式是 l2。
下面的例子没有指定一个父接口。网络驱动程序将为用户创建一个虚假(dummy)类型的链接,而不是拒绝网络的创建,并将容器隔离开来,只能相互通信。
# 创建 IPvlan 三层网络
$ docker network create -d ipvlan \
--subnet=192.168.214.0/24 \
--subnet=10.1.214.0/24 \
-o ipvlan_mode=l3 ipnet210
# 测试 192.168.214.0/24 连通
$ docker run --net=ipnet210 --ip=192.168.214.10 -itd alpine /bin/sh
$ docker run --net=ipnet210 --ip=10.1.214.10 -itd alpine /bin/sh
# 测试从 10.1.214.0/24 到 192.168.214.0/24 的三层连通
$ docker run --net=ipnet210 --ip=192.168.214.9 -it --rm alpine ping -c 2 10.1.214.10
# 测试从 192.168.214.0/24 到 10.1.214.0/24 的三层连通
$ docker run --net=ipnet210 --ip=10.1.214.9 -it --rm alpine ping -c 2 192.168.214.10
注意
网络创建中没有“
--gateway=”选项。如果指定了“l3”模式,则该字段将被忽略。从容器内部查看容器的路由表:# Inside an L3 mode container $$ ip route default dev eth0 192.168.214.0/24 dev eth0 src 192.168.214.10
为了从远程 Docker 主机ping容器或使容器能够ping远程主机,远程主机或介于两者之间的物理网络需要有一个指向容器Docker主机eth接口的主机IP地址的路由。
双栈IPv4 IPv6 IPvlan 二层模式
-
Libnetwork 不仅可以让你完全控制IPv4寻址,还可以让您完全控制IPv6寻址,并在这两个协议族之间提供对等的功能。
-
接下来的例子将只从IPv6开始。在同一个VLAN
139上启动两个容器,并互相ping。由于没有指定IPv4子网,默认的 IPAM 将提供一个默认的IPv4子网。该子网是隔离的,除非上游网络在VLAN139上明确地对其进行路由。
# 创建一个 v6 网络
$ docker network create -d ipvlan \
--ipv6 --subnet=2001:db8:abc2::/64 --gateway=2001:db8:abc2::22 \
-o parent=eth0.139 v6ipvlan139
# 在网络中启动一个容器
$ docker run --net=v6ipvlan139 -it --rm alpine /bin/sh
查看容器的 eth0 网卡跟 v6 路由表:
# IPv6 容器内部
$$ ip a show eth0
75: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc2::1/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc2::/64 dev eth0 proto kernel metric 256
default via 2001:db8:abc2::22 dev eth0 metric 1024
启动第二个容器,然后 ping 第一个容器的 v6 地址。
# 测试 IPv6 上的2层连通性
$ docker run --net=v6ipvlan139 -it --rm alpine /bin/sh
# 第二个 IPv6 容器的内部
$$ ip a show eth0
75: eth0@if55: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
inet6 2001:db8:abc2::2/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ping6 2001:db8:abc2::1
PING 2001:db8:abc2::1 (2001:db8:abc2::1): 56 data bytes
64 bytes from 2001:db8:abc2::1%eth0: icmp_seq=0 ttl=64 time=0.044 ms
64 bytes from 2001:db8:abc2::1%eth0: icmp_seq=1 ttl=64 time=0.058 ms
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max/stddev = 0.044/0.051/0.058/0.000 ms
下一个示例将设置具有示例VLAN ID 140的双栈IPv4/IPv6网络。
接着,创建一个同时有 IPv4 子网跟 IPv6 子网的网络,并都显式指定网关:
$ docker network create -d ipvlan \
--subnet=192.168.140.0/24 --subnet=192.168.142.0/24 \
--gateway=192.168.140.1 --gateway=192.168.142.1 \
--subnet=2001:db8:abc9::/64 --gateway=2001:db8:abc9::22 \
-o parent=eth0.140 \
-o ipvlan_mode=l2 ipvlan140
启动一个容器,查看 eth0 以及 v4 & v6 路由表:
$ docker run --net=ipvlan140 --ip6=2001:db8:abc2::51 -it --rm alpine /bin/sh
$ ip a show eth0
78: eth0@if77: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.140.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc9::1/64 scope link nodad
valid_lft forever preferred_lft forever
$$ ip route
default via 192.168.140.1 dev eth0
192.168.140.0/24 dev eth0 proto kernel scope link src 192.168.140.2
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc9::/64 dev eth0 proto kernel metric 256
default via 2001:db8:abc9::22 dev eth0 metric 1024
启动第二个容器,指定好 --ip4 地址,跟着用 IPv4 包 ping 第一个容器:
$ docker run --net=ipvlan140 --ip=192.168.140.10 -it --rm alpine /bin/sh
注意
在IPvlan 二层模式下,位于同一父接口上的不同子网无法相互ping通。这需要路由器使用辅助子网代理 arp 请求。然而,IPvlan 三层模式将正常路由相同的
-o parent父链接下的不同子网之间的单播流量。
双栈IPv4 IPv6 IPvlan 三层模式
示例:IPvlan 三层模式双栈IPv4/IPv6,多子网带 802.1q VLAN标记:118
与所有示例一样,使用标记的 VLAN 接口不是必须的。可以将子接口与 eth0, eth1, bond0 或主机上任何其他有效的接口交换,而不是 lo 回环。
你将看到的主要区别是,三层模式不会创建具有下一跳的默认路由,而是仅设置指向 dev eth 的默认路由,因为根据设计,Linux会过滤 ARP/广播/组播。由于父接口本质上充当路由器,因此父接口的IP和子网需要与容器网络不同。这与桥接和L2模式相反,后者需要在同一个子网(广播域)上才能转发广播和组播数据包。
# 创建一个 IPv6+IPv4 双栈 IPvlan 三层 network
# v4 跟 v6 的网关都被指定为到类似 'default dev eth0' 的设备
$ docker network create -d ipvlan \
--subnet=192.168.110.0/24 \
--subnet=192.168.112.0/24 \
--subnet=2001:db8:abc6::/64 \
-o parent=eth0 \
-o ipvlan_mode=l3 ipnet110
# 用不同的终端在网络(ipnet110)启动一些容器,并测试连通性
$ docker run --net=ipnet110 -it --rm alpine /bin/sh
# 启动第二个指定了 v6 地址的容器
$ docker run --net=ipnet110 --ip6=2001:db8:abc6::10 -it --rm alpine /bin/sh
# 启动第三个制定了 v4 地址的容器
$ docker run --net=ipnet110 --ip=192.168.112.30 -it --rm alpine /bin/sh
# 启动第四个同事指定了 v4 跟 v6 地址的容器
$ docker run --net=ipnet110 --ip6=2001:db8:abc6::50 --ip=192.168.112.50 -it --rm alpine /bin/sh
接口跟路由表的输出如下:
$$ ip a show eth0
63: eth0@if59: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 00:50:56:2b:29:40 brd ff:ff:ff:ff:ff:ff
inet 192.168.112.2/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 2001:db8:abc4::250:56ff:fe2b:2940/64 scope link
valid_lft forever preferred_lft forever
inet6 2001:db8:abc6::10/64 scope link nodad
valid_lft forever preferred_lft forever
# 注意默认的路由指向了 eth 设备,因为 arp 包被(eth)过滤了
$$ ip route
default dev eth0 scope link
192.168.112.0/24 dev eth0 proto kernel scope link src 192.168.112.2
$$ ip -6 route
2001:db8:abc4::/64 dev eth0 proto kernel metric 256
2001:db8:abc6::/64 dev eth0 proto kernel metric 256
default dev eth0 metric 1024
注意
当指定
--ip6=地址时,可能存在一个bug,当你删除具有指定v6地址的容器,然后启动具有相同v6地址的新容器时,它会抛出以下错误,就好像地址没有正确释放到v6池中。它将无法卸载容器并被保留下来。
docker: Error response from daemon: Address already in use.
手动创建 802.1q 链接
VLAN ID 40
如果用户不希望驱动程序创建VLAN子接口,则需要在运行 docker network create之前子接口就要存在。如果您的子接口命名不是 interface.vlan_id ,则只要接口存在并且已启动,它就会在 -o parent= 选项中得到认可。
手动创建的链接可以命名为任何名称,只要在创建网络时它们存在即可。无论网络以什么名称被 docker network rm 删除,手动创建的链接都不会被删除。
# 创建一个绑定到 dot1q VLAN 40的新子接口:
$ ip link add link eth0 name eth0.40 type vlan id 40
# 启用新的子接口
$ ip link set eth0.40 up
# 现在,可以像平常一样通过连接到标记的主(子)接口添加网络和主机。
$ docker network create -d ipvlan \
--subnet=192.168.40.0/24 \
--gateway=192.168.40.1 \
-o parent=eth0.40 ipvlan40
# 在两个终端里,分别启动能互相ping通的容器
$ docker run --net=ipvlan40 -it --name ivlan_test5 --rm alpine /bin/sh
$ docker run --net=ipvlan40 -it --name ivlan_test6 --rm alpine /bin/sh
例子: 手动创建的任意名字的 VLAN 子接口:
# 创建一个绑定到 dot1q VLAN 40的新子接口:
$ ip link add link eth0 name foo type vlan id 40
# 启动新的子接口
$ ip link set foo up
# 现在,可以像平常一样通过连接到标记的主(子)接口添加网络和主机。
$ docker network create -d ipvlan \
--subnet=192.168.40.0/24 --gateway=192.168.40.1 \
-o parent=foo ipvlan40
# 在两个终端里,分别启动能互相ping通的容器
$ docker run --net=ipvlan40 -it --name ivlan_test5 --rm alpine /bin/sh
$ docker run --net=ipvlan40 -it --name ivlan_test6 --rm alpine /bin/sh
手动创建的链接,可以用下面的命令清理:
$ ip link del foo
与所有 Libnetwork 驱动程序一样,它们可以被自由混合和匹配,甚至可以并行运行第三方生态系统驱动程序,以最大程度地提高Docker用户的灵活性。