引言:
北京时间:2023/7/3/14:09,刚睡醒,放假在家起床时间确实不怎么好调整,根本固定不了一点,当然通俗点说也就是根本起不来,哈哈哈,已经很少见到那种7点起来码字的情形了,再加上在家里,琐碎的事情很多,不像是在学校,除了睡觉吃饭就没什么其它事情需要我去花费精力,哎,感叹!加上在家吃饭时间比较慢,间接影响了我的睡觉时间,一般想在11点左右睡觉,当时又是码字状态最好的时候,睡不了一点,直接导致睡的比较迟,这点有待改善,从今天开始,刚好由于昨天更文了,今天不强制更文,所以今天11点前必须躺平睡觉,然后对于更文和学习进度上,目前顺其自然吧!毕竟我们时间充足,前期还是走稳一些较好,虽然还需要进行刷题,但是毕竟还有时间,莫慌,到时候船到桥头,自然也就直了,咱还是继续慢悠悠的向前走吧!该篇博客我们就来详谈一下进程地址空间和物理内存之间具体是如何通过页表进行映射,当然重点还是多线程相关知识。

深入线程概念
上篇博客的标题是多线程概念,有关线程的基本概念我们都讲解完了,但是由于时间原因,并没有进行深入的学习,所以在学习有关页表映射,线程创建和控制等知识前,我们先来补充一下线程概念相关知识。
1.如何理解之前学习的进程
在学习了线程之后,我们明白进程并不是CPU的执行单位,线程才是,那么此时应该如何理解以前学习的进程呢?首先明白,两者并没有任何的冲突,而是互相补充,也就是以前在学习进程时,由于进程知识复杂,所以并没有展开讲解内部与线程相关的知识,而只是从表面单一的执行流去学习它。其次明白,以前的进程是内部只有一个task_struct的进程,也就是可以理解为是内部只有一个执行流(线程)的进程,而今天我们学习的进程,内部不仅不止只有一个执行流,而是有多个执行流,并且这些执行流共享该进程中的所有资源(时间片,地址空间等)。明白了这点之后,接下来我们再谈谈操作系统对于线程的实现,我们就正式进入多线程深入学习。
2.不同操作系统对于线程的实现是否相同?
首先答案肯定是不同的,按照最普遍的两种操作系统(Windows和Linux)来说,它们之间对于线程的实现就大为不同,具体不同原因如下:
-
Windows
操作系统要不要管理线程,答案肯定是肯定的,同理,谈到计算机中的管理,不过就是先描述,后组织而已,如同操作系统管理进程一般,将所有的进程都描述成了对应的进程pcb(task_struct),然后对进程pcb进行管理,同理,操作系统对于线程的管理也是将线程先描述成一个TCB(task_struct),然后对TCB进行管理,当然由于线程是根据进程pcb创建,那么其TCB中的数据肯定没有pcb那么复杂,一般包含线程标识符,对应的上下文、栈空间、所述进程、线程状态、寄存器集合等数据!所以此时当线程和进程一样,拥有了自己的控制块,那么操作系统就可以像管理进程一样去管理线程,同理完成进程调度,也可以完成线程调度等工作,但是由于进程的数量已经非常多,那么线程的数量肯定更多,此时如果在管理进程的同时,又去管理线程,那么就会导致操作系统在运行时,非常的复杂,程序设计起来也没有那么简单,所以按照这种方法设计操作系统难度较大,当然我们现在使用的Windows操作系统(内部有真线程)就是按照这种方法来设计的。 -
Linux
Linux操作系统在设计进程和线程时,就发现,进程有PCB,线程有TCB,进程需要被调度,线程也需要被调度,并且线程的TCB是根据进程的PCB设计,那么此时Linux系统在设计时,那么世界顶级的程序员就让线程直接去复用PCB结构体,用PCB模拟线程的TCB,这样线程的数据结构和管理方式我就不需要重新设计,并且相应的线程调度算法也不需要重新设计,而是直接复用进程的设计方案就行,所以对于Linux来说,系统内部没有真正意义上的线程,而是使用进程来模拟线程(区分Windows系统有真正的线程)的方法设计。
总而言之,Windows系统对于线程的设计方法非常的朴实无华,而Linux则更加的巧妙,当然两者可以说是各有千秋,但是从代码维护和代码复用性、安全性上来看,Linux的设计方法肯定更优,所以这也就导致Linux系统可以不间断运行,而Windows系统不行。
3.那么Linux系统中的线程到底是什么呢?
明白了上述知识,此时我们就知道Linux系统中只有进程并没有真线程,所以在CPU看来,虽然执行的都是task_struct,但是此时的task_struct和Windows系统中的task_struct肯定是有区别的,因为Windows中的进程不仅是一个执行流,其中还包括了很多的线程,而对于Linux来说,Linux中由于没有真正的线程,所以把进程和线程的概念统称为任务,CPU在执行时,执行的不是线程也不是进程,而是任务,并且该任务也被称为轻量级进程(Lightweight Process)。
使用代码看看Linux系统下的线程
明白了上篇博客有关线程的概念和上述有关知识,一切都还是基于概念上的纸上谈兵而已,具体到底是怎样的,还有待探究,如下图所示,就是使用对应线程相关接口,创建线程,然后查看Linux系统中对应线程之间的关系(ps -aL),如下:
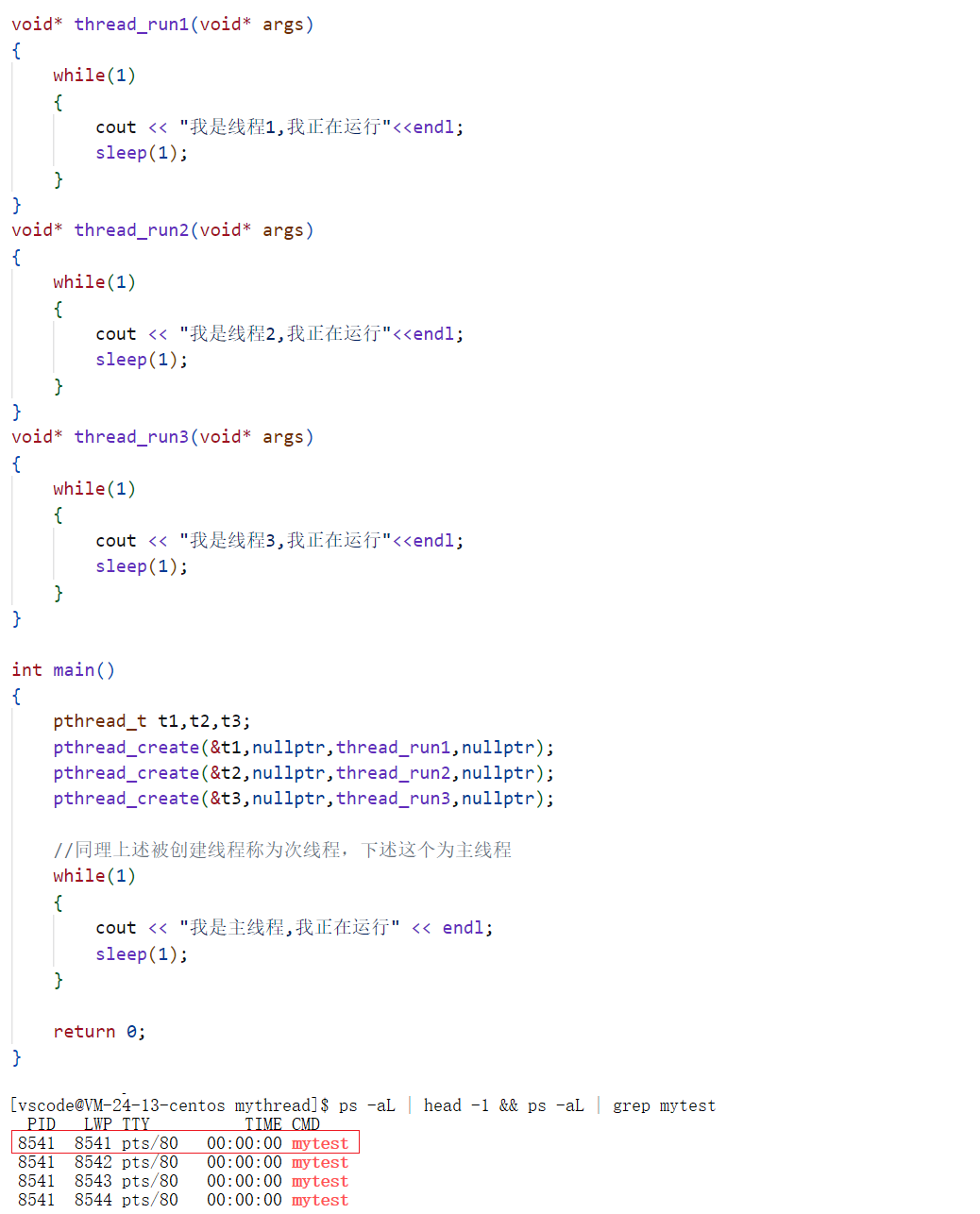
如上图所示,此时我们就可以很好的看出,这四个执行流(线程)属于同一个进程(8541),并且除了PID之外,还有一个LWP,此时这个LWP代表的就是轻量级进程的标识符,并且其中一个轻量级进程的LWP和PID相同,也就是表示该轻量级进程就是所谓的主线程。
上述代码中值得注意的地方有两点:其一是pthread_create接口的用法,功能创建一个线程,头文件:pthread.h,基本使用方式:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);简单使用就是如上述代码一样,这里不详解讲解该接口,其二是在Linux操作系统下执行相应线程代码时,由于pthread.h头文件并不是Linux系统的默认动态库,所以在执行相应pthread中的接口时,需要包含对应的静态库(libpthread.a),具体执行方式:g++ -o test -lpthread thread.cpp -std=c++11
详谈虚拟到物理之间的转换过程
搞定了上述有关线程概念相关知识的补充,此时我们就再来谈谈虚拟地址空间到物理内存之间的转换过程,当然,这块知识和我们学习线程息息相关,因为涉及到了线程的整体执行过程,虽然之前在学习虚拟地址空间和进程相关知识时,我们已经了解了大致过程,但是不够具体,并且有关页表映射相关的知识我们也没有详谈,所以接下来就让我们通过讲解页表映射,来回顾一下进程的整体执行过程吧!
页表映射问题
无论是在之前学习进程相关知识,还是学习虚拟地址空间,我们明白虚拟地址空间的设计本质是为了配合进程,当然也就是为了完善整个体系结构,在提高效率的同时,使系统更加安全稳定。并且我们明白,虚拟地址空间本质并不能存储任何数据,它起到的作用只是一个桥梁作用,让进程或者是线程可以通过虚拟地址空间中对应的地址访问到物理内存中对应的数据,从而执行相应的代码,当然上述理解在概念上并没有什么问题,但是当我们深入理解,认识了什么是页表之后,上述概念就有问题,因为进程虽然只有通过虚拟地址空间上的地址才能访问到物理内存中的数据,但虚拟地址空间本质是通过页表的映射才找到对应的物理地址,所以从这点看来,页表才是进程能够访问到物理内存中数据的桥梁。明白了这点之后,今天我们就来谈谈页表到底是如何实现虚拟地址空间到物理内存的映射吧!
1.那么页表应该有多大呢?
通过上述知识,我们知道,页表是进程找到物理地址的桥梁,并且我们也知道虚拟地址空间的大小默认是4GB,当然这个大小取决于我们电脑的体系结构是32位寻址还是64位寻址,当然对于目前市面上来说,电脑都是64位的操作系统,但是对于我们学习知识来讲,我们以32位为例,假如此时我们的物理内存也是4GB,那么就会面临一个问题,当然也就是页表映射问题,页表应该如何设计才能让虚拟地址空间上2^32的地址映射到物理内存上呢?首先,页表不可能是直接映射,也就是不可能和虚拟地址空间、物理内存一样,拥有那么大的空间,因为想要实现直接映射的话,那么页表就需要有48GB的空间,如下图所示:

显然,我们的页表不可能拥有48GB的存储空间,所以页表不可能是采用直接映射的方法,实现虚拟地址空间到物理内存的映射,那么页表到底是使用什么方法,来实现映射的呢?想要明白这个点,此时我们就需要先复习一下有关IO的知识,如下所述:
2.复习相关IO知识
明白,当我们需要高频的从磁盘中加载数据到内存中时,由于磁盘的工作原理,它只有进行相应的机械运动,才可以将磁盘上的数据加载到物理内存中,那么就注定这个过程的效率非常低效,所以对于我们的计算机体系结构来说,肯定是不允许这种情况的发生,此时在设计对应磁盘加载数据到内存中时,就应该减少加载数据的频率,增大一次加载数据的大小,减少寻址,当然也就是减少机械运动,从而提高效率。具体如何减少磁盘数据加载到物理内存,如下所示:
所以体系结构就规定操作系统,当磁盘需要加载数据到内存中时,一次只加载4KB,无论你想要从磁盘中加载多大的数据到内存,磁盘每次都是按照4KB来加载,当然这个知识点和我们的局部性原理有一定的关系,这里我们先不做详解,那么此时就会面临一个问题,为什么是4KB不是8KB或者16KB呢?面对这个问题,在学习过文件系统,了解了磁盘的工作原理之后,对于我们来说并不是什么大问题,本质就是因为,在磁盘中,数据是以块为单位进行存储,当然磁盘中一个块也就是4KB大小,所以对于磁盘来说,在将数据加载到内存时,就是通过一个块一个块的加载,这也就是导致为什么每次都加载4KB的直接原因。当然这样的设计方法,好处肯定是巨大的,不仅可以减少机械运动,而且可以让每一块数据都和操作系统规定的大小相匹配,从而大大提高加载速度,不需要进行二次切割等操作。同理,对于物理内存来说,它在保存磁盘加载的数据时,也是按照4KB大小来保存,虽然内存中是以字节为单位,但是操作系统在管理物理内存时,也是通过一个一个4KB大小的内存单元进行管理,所以在这样的设计下,磁盘和内存之间的交互效率就得到很大的提高,并且对于物理内存中对应的4KB数据块,我们也称为页框,对于磁盘中对应的4KB数据块,我们也称为页帧 ,对于物理内存中页框的管理我们采用的是struct page结构体,对于所有页框的管理,我们使用的是struct page mem[]数组,且struct page结构体中一般包含的属性非常的少,因为该结构体本质只是用于判断该页框是否被占用(status),而struct page mem[]数组的使用就更加的简单,本质就是通过该数组对应的下标找到没有被占用的那一个页框(遍历),然后将磁盘中对应加载的4KB数据保存起来而已。具体如下图所示:
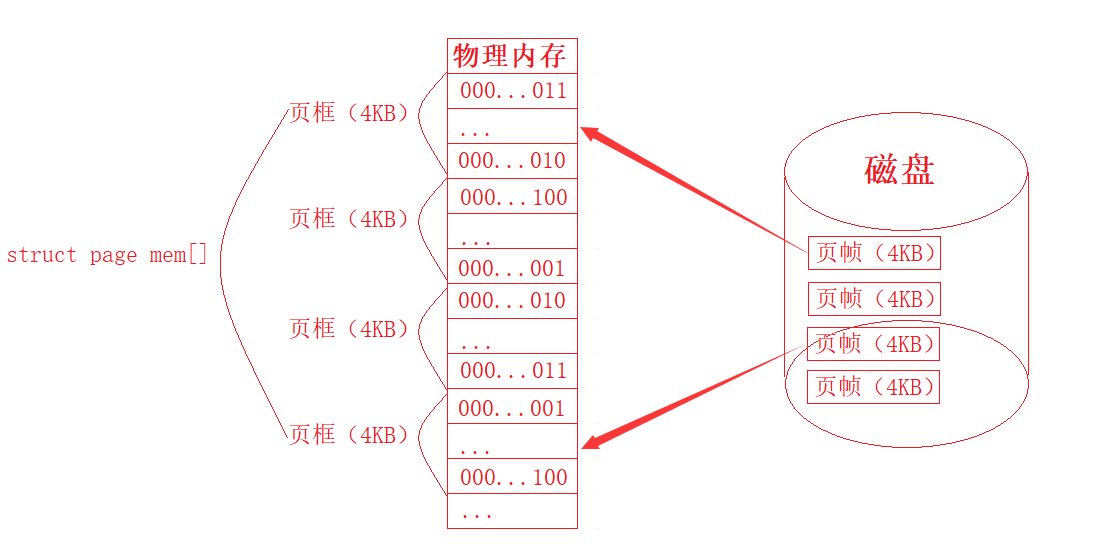
总:内存管理的本质就是将磁盘中特定的4KB数据块内容加载到某一个物理内存的4KB空间中。
3.再谈局部性原理
明白了上述知识,此时我们就知道,由于磁盘加载数据到内存的过程一定是按照4KB的大小,也就是以块为单位来加载,以块为单位进行保存,那么此时我们就会遇到一个问题,当然这个问题和我们的局部性原理息息相关,也就是当我们只需要使用几个字节的数据时,如果再从磁盘中一次性加载4KB数据到内存,那么就非常的浪费效率,那么为什么还要这样设计呢?当然这样设计肯定是有好处的,无论是除了上述减少机械运动之外,这样设计还有另一个好处,也就是为什么不担心我只使用10字节的数据,而照样加载4KB,因为在我们的电脑中存在局部性原理,也就是允许我们提前加载正在访问数据相邻或者附近的数据到内存中! 所以因为有局部性原理的存在,操作系统本身就算你只使用10字节的数据,它也会将对应数据附近的数据也加载到内存中,因此就算是只用10字节数据,我们一次性将该数据对应的块数据(4KB)加载到内存也是非常合理的,既满足效率问题,也符合局部性原理的概念,一石二鸟。局部性原理的本质: 进行数据的预加载,当将来想要执行该代码附近的代码时,CPU很大概率会直接命中内存中预加载的数据,就不需要再通过磁盘加载数据,大大提高效率。
明白了上述局部性原理相关知识,我们就可以明白,为什么一个占用内存非常大的大型游戏,可以被运行起来了,也就是一个可执行程序,它需要占用非常大的内存才能被执行,普通电脑的内存根本装不下,所以我们明白,想要让该可执行程序执行起来,就需要让它在执行的时候,一部分一部分的执行,也就是在加载的过程中,只加载一部分,游戏运行到哪里,它就加载哪部分的可执行程序,本质就是在不断切换内存中相应区段的可执行程序,从而让该游戏一直可以运行下去,而这个一部分一部分执行代码的过程,肯定就离不开我们上述所说的局部性原理。
4.页表映射问题详解
搞定了上述1、2、3知识点,此时我们正式来看看页表映射问题,也就是页表到底是如何实现地址空间到物理内存的映射,如下图所示:
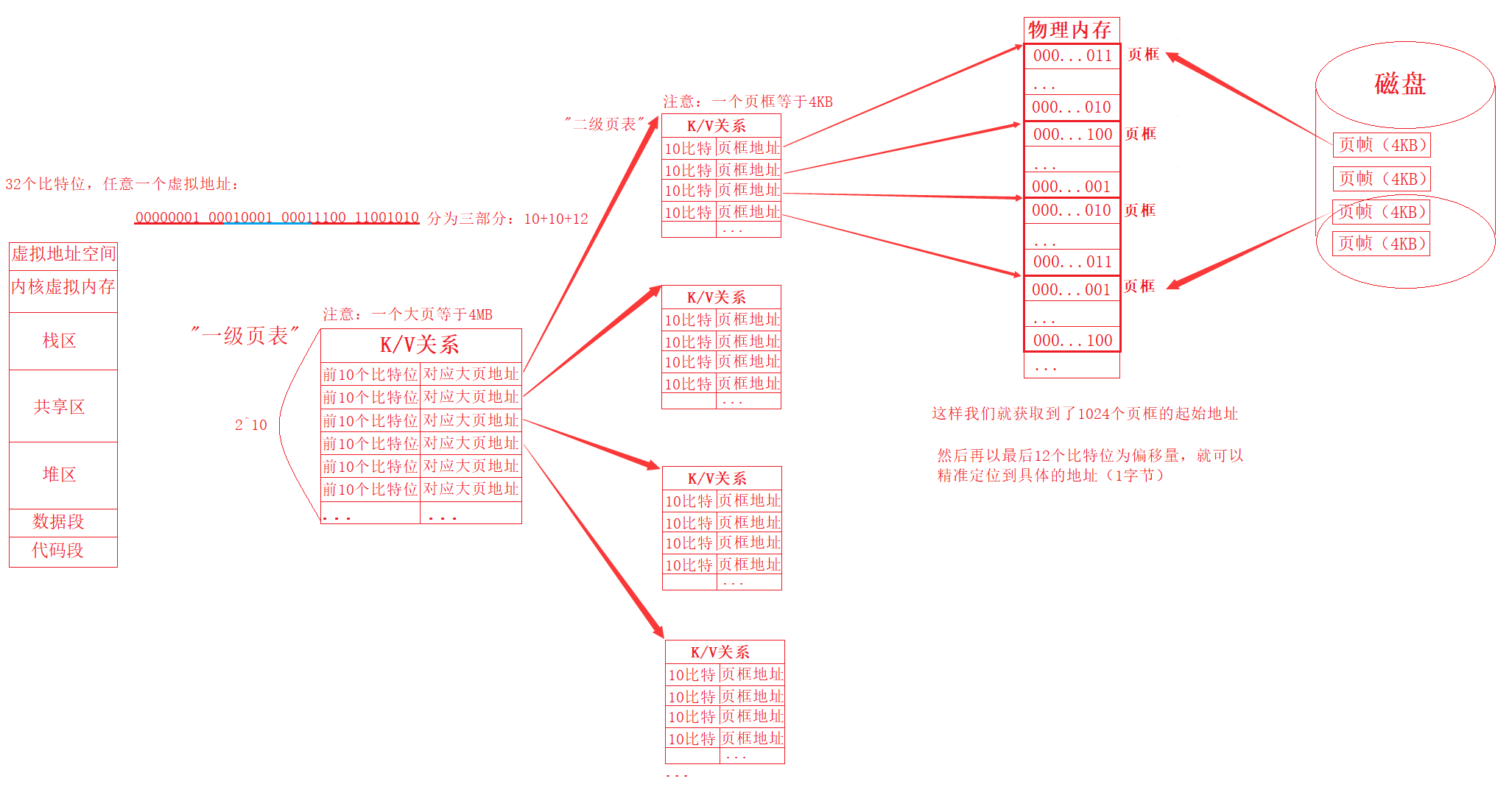
通过上图,此时我们可以看出,当我们想要将地址空间中的某一个地址映射到物理内存中时,此时需要通过页表上对应的索引关系,才能让虚拟地址转换为物理地址,如上图所示,我们将任意一个虚拟地址(32位)分为了三部分(10+10+12),其中前10个比特位表示的是一级页表中对应的1024个地址,并且由于页表本质是一种K/V关系的数据结构(索引),所以这1024个地址表示的就是如上图中所示的1024个大页地址,目的也就是通过某个虚拟地址的前10个比特位,找到1024大页地址中唯一的大页地址,并且此时这个大页地址,我们也称为二级页表,同理,这个二级页表由10个比特位构成,通过这10个比特位,我们同理就能找到1024个页框地址中唯一的那个页框地址,最终根据虚拟地址的第三部分,也就是最后12个比特位,找打该页框中对应的唯一物理地址(1个字节),成功将虚拟地址通过页表映射为物理地址。并且明白:上述通过二级页表寻找物理地址的过程是一个起始地址+偏移量的过程,类似我们之前学习过的寻找某一种类型占用的物理地址(编译器只提供我们起始地址,也就是一个字节,然后根据类型,也就是偏移量,找到对应数据对应所占的空间)。
搞定了上述页表映射问题,我们也就解决了页表应该有多大的问题,因为页表是被存储在物理内存中,所以按照上述的原理也就是占用了1024个2^10空间,当然因为一个地址占用4个字节,此时页表的大小就是4MB,相比于之前的48GB,可以说是非常小了,当然对于内存来说,也是非常小的。但是由于页表结构是建立了映射关系之后,才去开辟空间,也就是虚拟地址空间上有多少地址,我才映射多少地址,并不会把所有地址都给先创建好,所以一般页表结构只需要几个字节或者几十个字节就能搞定,具体页表的大小,是由我们的程序,也就是的代码,当然也就是虚拟地址空间上的地址数量等因素决定的。
此时值得注意的是:因为一个页框为4KB,也就是4096个字节,所以在通过虚拟地址最后12个比特位作为偏移量去寻址的时候,每一个字节的地址都是刚好相匹配的,千万不能将这里的地址数,也就是字节数给理解成了1024,否则就出问题了。
总而言之:当进程访问到一个虚拟地址时,也就是CPU在访问某一句代码时,CPU会将对应的虚拟地址发送给集成在CPU内部的内存管理单元(MMU)处理,由于内存管理单元中存储着一级页表(页表目录)的物理地址,所以在内存管理单元接收到对应的虚拟地址之后,内存管理单元(MMU)首先是将对应物理地址的页表(页表目录)加载进来,其次才是根据内存管理单元接收到的虚拟地址的高位(前10个比特位)和页表目录找到对应二级页表(页表项)的物理地址,然后再根据页表项中对应的索引(K/V)和虚拟地址的最后12个比特位找到特定的物理地址,最终进程就可以使用该物理地址读取或者写入数据啦!
什么是缺页中断
搞定了上述过程,也就是进程如何通过页表找到对应物理内存中数据的过程,理解缺页中断,对于我们来说,不过只是多理解一个概念,或者是理解一个现象而已,顺水推舟,结合之前的编码经验,我们知道,我们编码过程中在什么栈区、堆区、静态区开辟空间,本质都只是在虚拟地址空间上申请了一个地址而已,同理,从操作系统资源管理方面来看,操作系统不可能因为我们编码过程中申请了一个虚拟地址,它就把这个地址或者说这个地址对应的数据映射到内存中去,这样会导致内存资源的浪费,所以只有当我们完成了编码,生成了可执行程序,运行可执行程序之后,操作系统才会自动帮我们向内存申请空间,那么此时问题也就来了,当然也就是缺页中断概念来了,操作系统怎样自动帮我们向内存申请空间呢?从概念上来讲,这个申请空间的过程我们就叫做缺页中断,详情如下:
有了上述缺页中断的概念,那么我们就意识到,在通过页表建立映射关系时,不是先有映射关系,而是因为有缺页中断,才有映射关系,也就是说,当MMU接收到虚拟地址加载完页表之后,准备映射时,发现对应页表中并没有相应的索引关系,也就是物理内存中没有匹配的空间,那么此时MMU就会触发缺页中断,当触发了中断之后,操作系统就会去执行对应的处理方法,当然此时也就是去执行申请内存的操作。同理,缺页中断除了可以触发操作系统自动申请内存外,它还是让磁盘中的数据自动加载到内存中,也就是当访问内存中的数据时,检测到内存中并没有对应的匹配数据,同理发生缺页中断,操作系统执行相应处理方法,最终将磁盘中的数据加载到内存中。
深入分析线程
搞定了上述知识,无论是进程还是线程,它们的执行过程我们就都搞定了,接下来让我们分析一下线程的优点和缺点,通过分析线程的优缺点,将线程概念相关知识彻底搞懂!如下:
线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
- 性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型
线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的
同步和调度开销,而可用的资源不变。 - 健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了
不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。 - 缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。 - 编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
有关线程优缺点知识的分析,我们留到下篇博客,由于时间问题,该篇博客就这样吧!