申明:文章内容是作者自己的学习笔记,教学来源是开课吧讲师梁勇老师。
不要杠,开心学习!
讲师介绍:梁老师 《细说Java》与《Java深入解析》图书作者。一线互联网资深数据分析专家,超过十年软件开发与培训经验。精通Python与Java开发,擅长网络爬虫,数据分析与可视化,机器学习,自然语言处理等技术。曾参与阿里云大学数据分析,机器学习,自然语言处理等课程开发与认证设计,担任阿里云学院导师。
进入正文:
损失函数定义
机器学习模型关于单个样本的预测值与真实值的差称为损失。损失越小,模型越好,如果预测值与真实值相等,就是没有损失。用于计算损失的函数称为损失函数。模型每一次预测的好坏用损失函数来度量。
机器通过损失函数进行学习。这是一种评估特定算法对给定数据建模程度的方法。如果预测值与实际结果偏离较远,损失函数会得到一个非常大的值。在一些优化函数的辅助下,损失函数逐渐学会减少预测值的误差。
通俗的讲损失函数
衡量模型预测的好坏。
损失函数就是用来表现预测与实际数据的差距程度。
比如你做一个线性回归,实际值和你的 预测值肯定会有误差,那么我们找到一个函数表达这个误差就是损失函数。
假设我们令真实值为Y 预测值为f(x) 损失函数为L(Y,f(x))他们的关系就是下图:

损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
举例
接下来,我们举个例子来讲解下损失函数:
首先我们假设要预测一个公司某商品的销售量:

X:门店数 Y:销量
我们会发现销量随着门店数上升而上升。于是我们就想要知道大概门店和销量的关系是怎么样的呢?
我们根据图上的点描述出一条直线:

似乎这个直线差不多能说明门店数X和Y得关系了:我们假设直线的方程为Y=a0+a1X(a为常数系数)。假设a0=10 a1=3 那么Y=10+3X(公式1)

我们希望我们预测的公式与实际值差值越小越好,所以就定义了一种衡量模型好坏的方式,即损失函数(用来表现预测与实际数据的差距程度)。于是乎我们就会想到这个方程的损失函数可以用绝对损失函数表示:
公式Y-实际Y的绝对值,数学表达式:[1]
上面的案例它的绝对损失函数求和计算求得为:6
为后续数学计算方便,我们通常使用平方损失函数代替绝对损失函数:
公式Y-实际Y的平方,数学表达式:L(Y,f(X))= [1]
上面的案例它的平方损失函数求和计算求得为:10
以上为公式1模型的损失值。
假设我们再模拟一条新的直线:a0=8,a1=4

公式2 Y=8+4X
绝对损失函数求和:11 平方损失函数求和:27
公式1 Y=10+3X
绝对损失函数求和:6 平方损失函数求和:10
从损失函数求和中,就能评估出公式1能够更好得预测门店销售。
统计学习中常用的损失函数有以下几种
(1)0-1损失函数(gold standard 标准式)
0-1损失是指,预测值和目标值不相等为1,否则为0:
该损失函数不考虑预测值和真实值的误差程度,也就是说只要预测错误,预测错误差一点和差很多是一样的。感知机就是用的这种损失函数,但是由于相等这个条件太过严格,我们可以放宽条件,即满足|Y−f(X)|<T时认为相等。
这种损失函数用在实际场景中比较少,更多的是用俩衡量其他损失函数的效果。
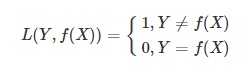
(2)绝对损失函数(absoluteloss function)
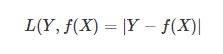
(3)平方损失函数(squared loss)
实际结果和观测结果之间差距的平方和,一般用在线性回归中,可以理解为最小二乘法:
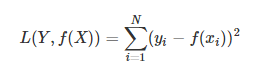
(4)对数损失函数(logarithmic loss)
主要在逻辑回归中使用,样本预测值和实际值的误差符合高斯分布,使用极大似然估计的方法,取对数得到损失函数:
损失函数L(Y,P(Y|X))L(Y,P(Y|X))是指样本X在分类Y的情况下,使概率P(Y|X)达到最大值。
经典的对数损失函数包括entropy和softmax,一般在做分类问题的时候使用(而回归时多用绝对值损失(拉普拉斯分布时,μ值为中位数)和平方损失(高斯分布时,μ值为均值))。
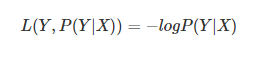
(5)指数损失函数(Exp-Loss)
在boosting算法中比较常见,比如Adaboosting中,标准形式是:
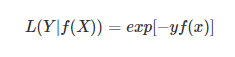
(6)铰链损失函数(Hinge Loss)
铰链损失函数主要用在SVM中,Hinge Loss的标准形式为:
y是预测值,在-1到+1之间,t为目标值(-1或+1)。其含义为,y的值在-1和+1之间就可以了,并不鼓励|y|>1|y|>1,即并不鼓励分类器过度自信,让某个正确分类的样本的距离分割线超过1并不会有任何奖励,从而使分类器可以更专注于整体的分类误差。
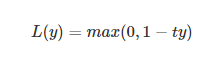
逻辑回归的损失函数
线性回归的损失函数是平方损失。逻辑回归的损失函数是对数损失函数,定义如下:
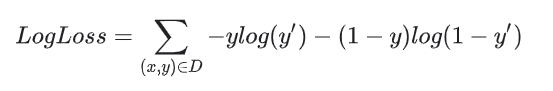
其中:
- (xy)ϵD 是包含很多有标签样本 (x,y) 的数据集。
- “y”是有标签样本中的标签。由于这是逻辑回归,因此“y”的每个值必须是 0 或 1。
- “y’”是对于特征集“x”的预测值(介于 0 和 1 之间)。
总结
损失函数越小,模型就越好。
损失函数可以很好得反映模型与实际数据差距的工具,理解损失函数能够更好得对后续优化工具(梯度下降等)进行分析与理解。

借鉴了以下大佬的文章:
https://blog.csdn.net/l18930738887/article/details/50615029
https://blog.csdn.net/google19890102/article/details/50522945?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-4
https://blog.csdn.net/qq_24753293/article/details/78788844
https://blog.csdn.net/chkay399/article/details/81878157
https://developers.google.cn/machine-learning/crash-course/logistic-regression/model-training