前言
第一周的学习记录。
之前有一点点基础所以是0.1。
缓慢的爬行ing。
主要参考了李沐的ai教学
一、CNN
卷积神经网络(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造性方法。
- 平移不变性:不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系
1、具体形式
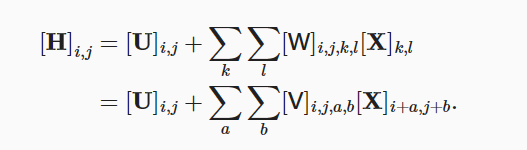
- 输入二维图像X
- 隐藏表示H
- 图像像素点(i,j)
- 偏置参数U
- 四阶权重张量W
对于平移不变性:
- 这意味着检测对象在输入X中的平移,应该仅导致隐藏表示H中的平移。
- 这就是说VU不依赖于i,j
即有:
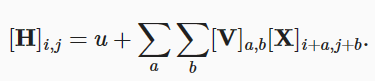
对于局部性:
- 为了收集用来训练参数H的相关信息,我们不应偏离到距(i,j)很远的地方。
即有:
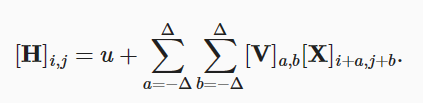
- V被称为卷积核、滤波器
2、图像卷积
*其实不是卷积是互相关(cross-correlation)
在卷积层中,输入张量和核张量通过互相关运算产生输出张量。
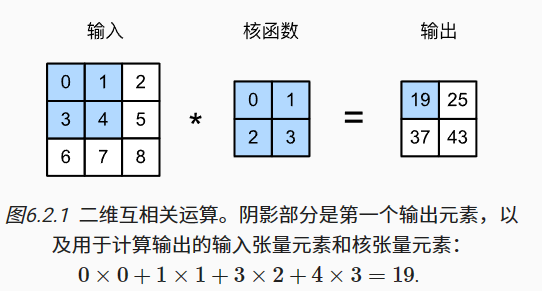
pytorch实现:
import torch
from torch import nn
from d2l import torch as d2l
# #@save是一个特殊的标记,会自动将代码保存在d21包内
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。卷积层中的两个被训练的参数是卷积核权重和标量偏置。
class Conv2D(nn.Module):
#二维卷积层
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
#添加偏置的前向传播
def forward(self, x):
return corr2d(x, self.weight) + self.bias
学习参数
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
#模型的grad置为0
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核,梯度下降法
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {
i+1}, loss {
l.sum():.3f}')
3、损失函数
分类错误率
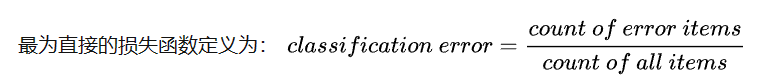
均方误差(MSE)

交叉熵损失函数(CELF)
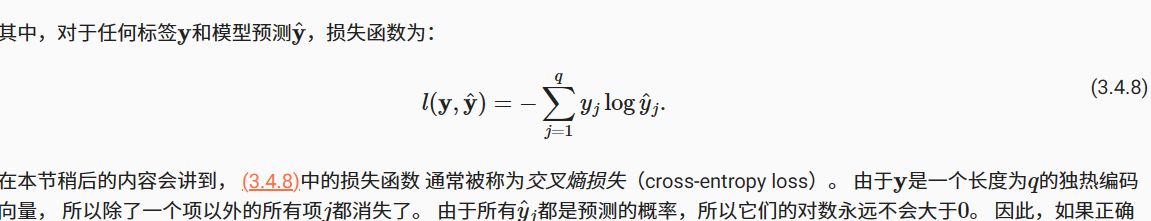
二、Pytorch
n维数组,又称为张量(tensor)
1、张量
创造张量
x = torch.arange(12)
x = tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
#张量也有shape属性,返回一个torch.Size值
x.shape
#张量的元素总数
x.numel() len(x)
#改变一个张量的形状而不改变元素数量和元素值
x.reshape(3, 4)
#全0、全1、其他常量
torch.zeros((2, 3, 4))
torch.ones((2, 3, 4))
# 随机(高斯分布)数
torch.randn(3, 4)
# 格式转化
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
# 重新分配内存的复制
B = A.clone()
运算
#按元素操作
x + y, x - y, x * y, x / y, x ** y
torch.exp(x)
#连接矩阵,0行1列
torch.cat((X, Y), dim=1)
#输出每个元素在对应位置是否相等的张量
X == Y
#求和产生单元素张量
X.sum()
#通过求和函数降维(指定所有行的元素)
A_sum_axis0 = A.sum(axis=0)
# 平均值
A.mean()
#点积
torch.dot(x, y)
#范数
torch.norm(u)
执行原地操作
#将表达式内容存储到原Y的地址,减少内存开销
Y[:] = <expression>
2、数据预处理
需要使用到pandas软件包,我们使用pandas预处理原始数据,并将原始数据转换为张量格式。
#导入csv文件
data = pd.read_csv(data_file)
#切片
outputs = data.iloc[:, 0:2]
#用每一列的均值替换NaN项
inputs = inputs.fillna(inputs.mean())
#将2值转化为两列,用0,1代表
#如Bottle列只有两个值(A,B),则自动转化为两列(BottleA,BottleB)
#用0,1赋值
inputs = pd.get_dummies(inputs, dummy_na=True)
3、自动微分
自动得到每个参数的偏导值
import torch
x = torch.arange(4.0)
# 梯度存储在x.grad里面
x.requires_grad_(True)
y = 2 * torch.dot(x, x)
#反向传播得到梯度
y.backward()
分离计算:y是关于x的函数,z是关于y和x的函数,我们希望只考虑x在y被计算之后的作用
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
4、神经网络相关
torch.nn.Sequential
- 是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。通俗的话说,就是根据自己的需求,把不同的函数组合成一个(小的)模块使用或者把组合的模块添加到自己的网络中。

nn.Conv2d

- 输入通道、输出通道、卷积核大小、步长、padding填充(当padding = 1时,是四周各加一行,即在行数和列数上加2)
nn.Sigmoid()
- 激活函数
nn.AvgPool2d
- 二维平均池化操作
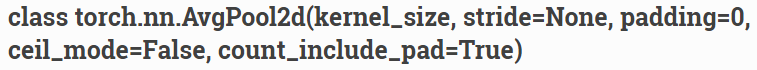
nn.flatten
- 将连续的维度范围展平为张量
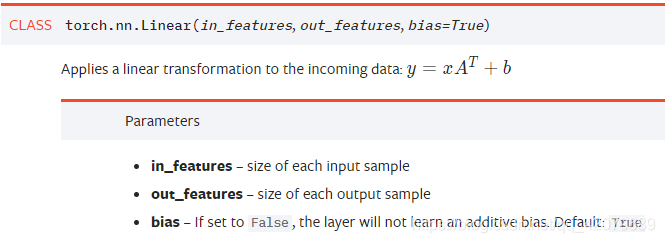
nn.Linear
三、Lenet
最简单的CNN(?)
transforms.ToTensor()
- 将原始的PILImage格式或者numpy.array格式的数据格式化为可被pytorch快速处理的张量类型
- np中图片的格式为(m * n *3 ),tensor为(3 * m * n)
- 还会将数值从 [0, 255] 归一化到[0,1]
transforms.Resize()
- 简单来说就是调整PILImage对象的尺寸
transforms.Compose(trans)
- 将一系列的transforms有序组合,实现时按照这些方法依次对图像操作。
torchvision.datasets.FashionMNIST
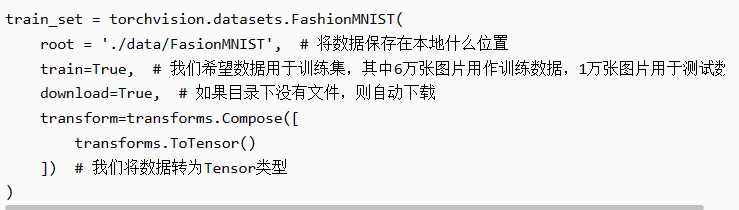
data.DataLoader
model.train()
也有model.eval()两个模式
训练时是针对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。
nn.init.xavier_uniform()
- xavier初始化方法中服从均匀分布U(−a,a) ,分布的参数a = gain * sqrt(6/fan_in+fan_out),
net.apply
- 该方法会将fn递归的应用于模块的每一个子模块
torch.optim.SGD
- 神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省社交网络训练的时间
optimizer.step()
- 所有的optimizer都实现了step()方法,这个方法会更新所有的参数
实现代码:(没有导入d2l包)
import torch
from torch import nn
import torchvision
from torch.utils import data
from torchvision import transforms
#构建网络架构
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="../data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=4),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=4))
def evaluate_accuracy_gpu(net, data_iter, device=None):
if isinstance(net, nn.Module):
net.eval()
#如果没有指定device的话,从把net的第一个参数的device拿出来
if not device:
device = next(iter(net.parameters())).device
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
def accuracy(y_hat, y):
# 使用argmax获得每行中最大元素的索引来获得预测类别
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
#结果是一个包含0(错)和1(对)的张量。 最后,我们求和会得到正确预测的数量。
return float(cmp.type(y.dtype).sum())
class Accumulator:
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def train(net,train_iter,test_iter,num_epochs,lr,device):
def init_weight(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weight)
print(device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(),lr = lr)
loss = nn.CrossEntropyLoss()
for epoch in range(num_epochs):
net.train()
for i,(X,y) in enumerate(train_iter):
optimizer.zero_grad()
X,y = X.to(device),y.to(device)
y_hat = net(X)
l = loss(y_hat,y)
l.backward()
optimizer.step()
test_acc = evaluate_accuracy_gpu(net,test_iter)
print(test_acc)
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size=batch_size)
lr, num_epochs = 0.9, 10
train(net, train_iter, test_iter, num_epochs, lr, torch.device("cuda:0"))