视频编解码的入门知识
视频编解码的发展历史
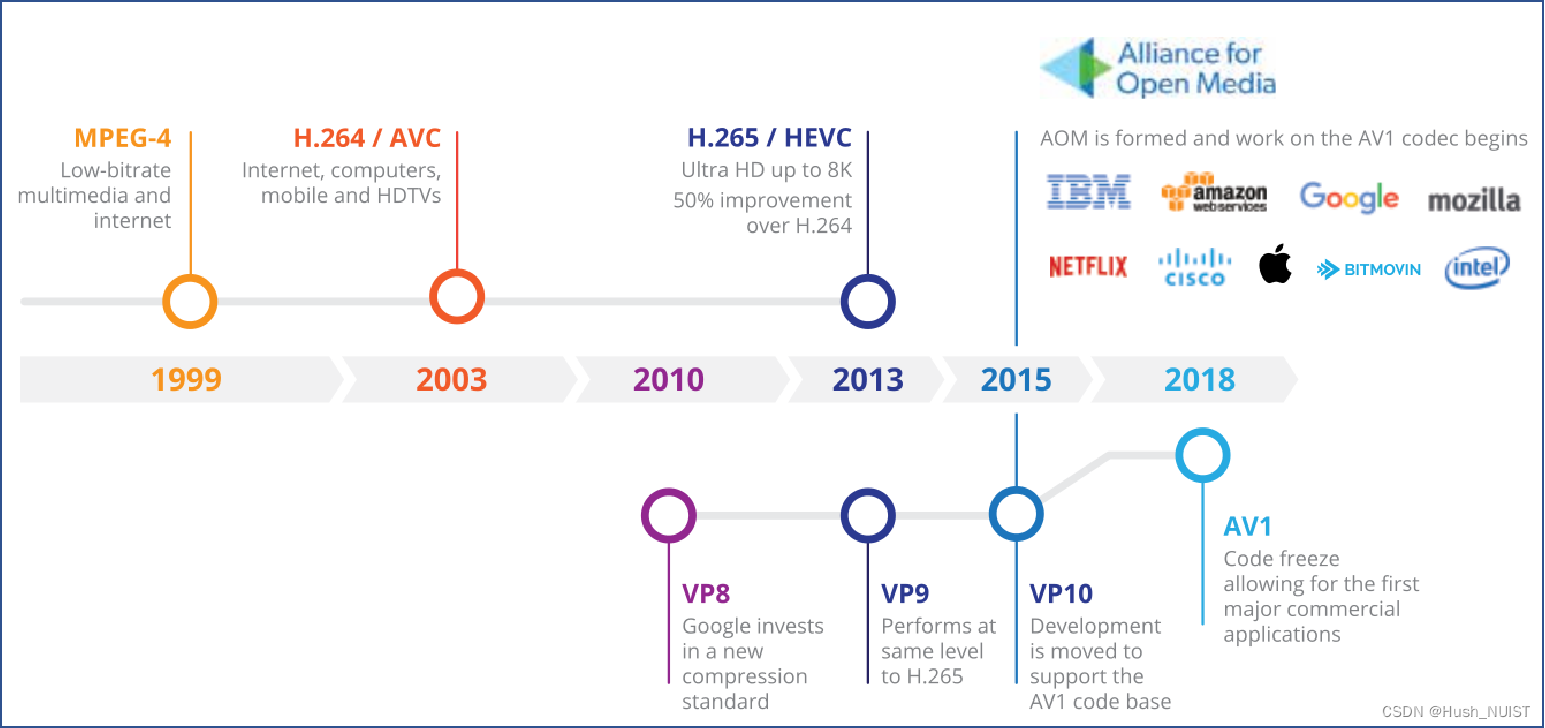
在过去的17年里,自2003年确定现在仍占主导地位的 H.264/运动图像专家组 (MPEG-4) 高级视频编码 (AVC) 标准的第一个版本以来,已经又开发了两个主要的新一代视频编码标准,即称为高效视频编码标准(HEVC) 和多功能视频编码 (VVC)标准。
与AVC一样保持了10年的开发周期,HEVC于2013年完成,并且与AVC相比,HEVC完成了约50%的比特率降低。
VVC 项目的周期缩短了三年,该项目于2020年7月完成,再次实现比其前身 (HEVC) 降低约50%的比特率。正如在之前的开发周期中一样,除了混合视频压缩方面的进一步提升之外,VVC标准还诠释了其命名中所突出的视频应用领域的广泛多功能性。VVC标准包含了对更加广泛的应用程序的支持,除了对典型的标准和高清摄像机捕获的内容编码支持外,还包括了对计算机生成/屏幕内容、高动态范围内容、多层和多视图编码的功能,以及沉浸式媒体(如 360° 视频)的支持。
HEVC和VVC(H265和H266)的编解码格式介绍
HEVC和VVC(H265和H266)的编解码流程介绍
AVC(H264)格式压缩编码原理
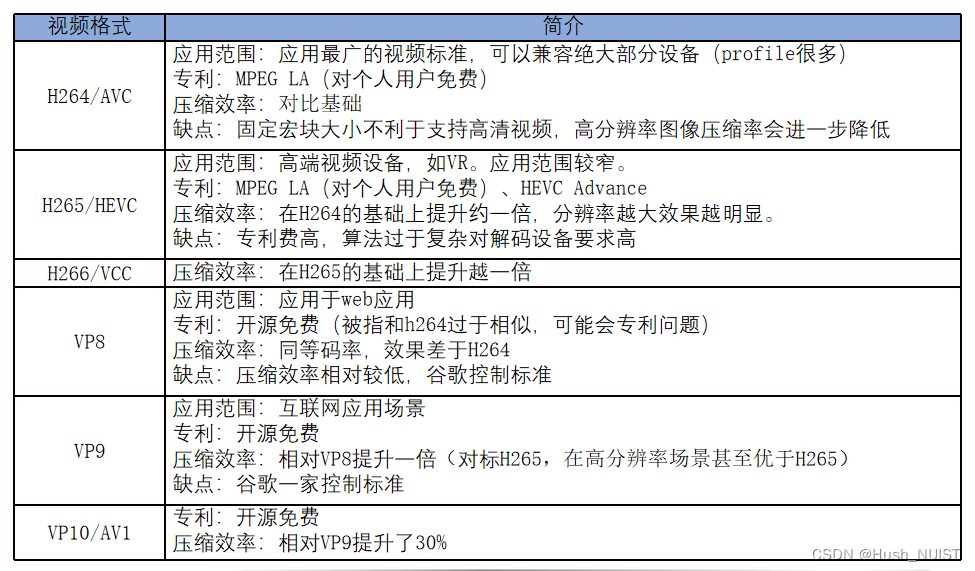
具体来说,这些主流的格式各有各自的优势:
视频编解码的作用和流程
视频编码的目的是为了压缩原始视频,压缩的主要思路是从空间、时间、编码、视觉等几个主要角度去除冗余信息。

一个视频被分解成帧或其他单元后,大致都要经过帧内预测、帧间预测、变换编码、量化编码、后处理和熵编码这些编码过程:
帧内预测:它利用视频帧内的局部冗余性来减小视频数据的大小,从而实现视频压缩。在视频编码过程中,每个视频帧都可以被分为许多块,然后使用已编码的块来预测目标块的像素值。帧内预测是指在同一帧内使用已编码的相邻像素块来预测目标像素块的像素值,而不使用来自其他帧的信息。它是一种无损压缩技术,因为它不会丢失视频的任何信息,只是通过预测来减少存储和传输的数据量。
在帧内预测中,通常使用以下几种方法来预测像素块的像素值:
均值预测:使用周围像素的平均值来预测目标像素的值。
区域预测:将目标像素块分为更小的块,并使用已编码的相邻块的像素值来预测目标像素块中每个像素的值。
模式预测:将已编码的相邻块中最相似的块称为模式块,然后使用模式块中的像素值来预测目标像素块中每个像素的值。
这些方法都旨在利用图像中的冗余性,从而减少需要存储和传输的数据量。
帧间预测:通过利用视频中前后两个或多个帧之间的相关性来减少视频的数据量。帧间预测利用了视频中帧与帧之间的相似性,以便在压缩时只需要传输一些变化的信息而不需要传输整个帧。在帧间预测中,视频编码器将当前帧与前面或后面的一个或多个参考帧进行比较。根据参考帧的信息,编码器可以推断出当前帧中哪些像素值发生了变化,并将这些变化信息进行编码和传输。这种方式可以在不丢失视频质量的情况下减少视频数据的大小,从而降低视频的传输带宽和存储空间要求。
可以用下图来加深预测编码这一步骤的理解:
变换编码:变换编码是指通过将信号进行变换,从而将其表示为一组变换系数。这些变换系数通常可以通过下一步的量化从而进一步减小精度并压缩数据。变换编码技术通常用于数字信号处理领域中的音频、图像、视频等数据的压缩,因为它可以提供更好的数据压缩效果并减少存储空间。常见的变换编码算法包括离散余弦变换(DCT)、离散小波变换(DWT)等。
量化编码:由于变换编码只是将图像数据从空间域矩阵转换为频域的变换系数矩阵,矩阵的系数个数和数据量都没有减少。要想压缩数据,还需要对频域中的统计特征进行量化和熵编码。量化就简单理解来说就是将人眼看不见的高频分量给去除从而起到压缩的作用。
常见的量化方法可以分为标量量化(SQ)和矢量量化(VQ两类:
1.标量量化:将图像中的数据划分成若干个区间,然后在每个区间用一个值代表这个区间内所有样点的取值。
2.矢量量化:将图像中的数据划分成若干个区间,然后在每个区间用一个代表矢量代表这个区间的所有矢量取值。
由于矢量量化引入了多个像素之间的关联,并且使用了概率的方法,一般压缩率比标量量化高。但是由于其计算复杂度高,所以目前广泛使用的量化方法是标量量。
编码端的量化过程可以简单理解为是每个 DCT 变换系数除以量化步长得到量化值。在解码端对应的反量化过程就是量化值乘以量化步长得到 DCT 变化系数值。
后处理:视频编码后处理是指在视频压缩之后,对压缩后的视频进行进一步的处理,以改善视频的视觉质量、降低码率、提高视频播放的效率等。以下是一些常见的视频编码后处理技术:
色彩空间转换:将原始视频从一种颜色空间转换为另一种颜色空间,例如从RGB到YUV。
去噪:通过降噪算法降低视频中的噪点和伪影,提高视频的清晰度和质量。
锐化:使用锐化算法增加视频的清晰度和边缘,使图像更加清晰。
调色:对视频的颜色进行调整,改善视觉效果。
降噪:使用降噪算法,减少视频中的噪点和伪影,提高视频质量。
色彩平衡:对视频中的颜色进行平衡,使颜色更加自然和平衡。
缩放:对视频进行缩放,改变视频的分辨率。
裁剪:裁剪视频的一部分,以改变视频的宽度、高度和纵横比。
滤镜:使用滤镜技术,为视频增加艺术效果。
帧率转换:将视频的帧率转换为其他帧率,以适应不同的播放需求。
熵编码:视频编码中的熵编码是一种数据压缩技术,用于将数字信号编码为比原始信号更短的二进制数据流。它的目的是通过利用输入信号的统计特性,将信号的冗余部分压缩掉,从而减少传输或存储所需的数据量。
熵编码的基本思想是将出现频率高的符号(如某些像素值或者运动矢量)用短的编码表示,而将出现频率低的符号用长的编码表示。这种编码方式可以用于各种视频编码标准,如MPEG和H.264。
熵编码通常在视频编码的最后一步完成,因为它需要对编码后的数据进行二次扫描才能确定最终编码的二进制位数。常见的熵编码有香农(Shannon)编码、哈夫曼(Huffman)编码、算术(Arithmetic)编码、游程编码等。
视频编解码常用工具


视频封装格式与属性
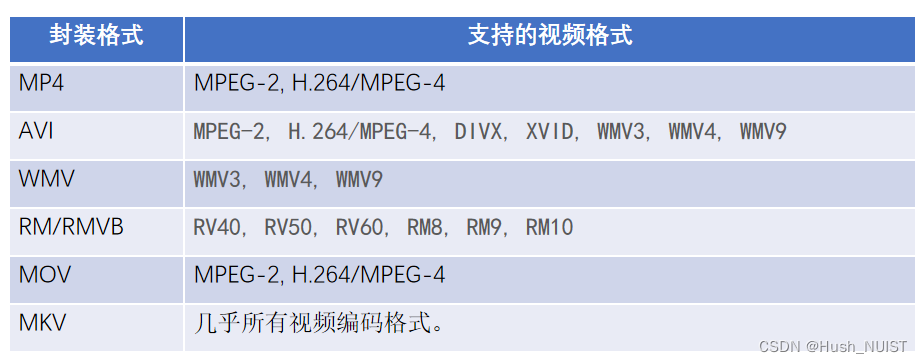
区别于视频编码格式,封装格式与文件名后缀对应,是对视频、音频、字幕信息进行打包的的一种容器格式。
视频的属性:
编码格式:前面已经提到,如H264/5/6,VP8/9,AV1,AVS1/2/3
帧率:每秒包含的图像帧数,如25fps,30fps,60fps。
码率:每秒钟包含的视频数据大小,单位bps。
分辨率:每帧图像的宽高比。720P,1080P,2K,4K,8K

视频编码常用名词与术语
GOP、I帧、P帧、B帧
GOP(group of pictures), 指的就是两个I帧之间的间隔. 比较说GOP为120,如果是720 p60 的话,那就是2s一次I帧。
在视频编码序列中,主要有三种编码帧:I帧、P帧、B帧。
I帧即Intra-coded picture(帧内编码图像帧),不参考其他图像帧,只利用本帧的信息进行编码。
P帧即Predictive-codedPicture(预测编码图像帧),利用之前的I帧或P帧,采用运动预测的方式进行帧间预测编码。
B帧即Bidirectionallypredicted picture(双向预测编码图像帧),提供最高的压缩比,它既需要之前的图像帧(I帧或P帧),也需要后来的图像帧(P帧),采用运动预测的方式进行帧间双向预测编码。
YUV颜色空间
YUV,是一种颜色编码方法。常使用在各个视频处理组件中。YUV在对照片或视频编码时,考虑到人类的感知能力,允许降低色度的带宽。
YUV是编译true-color颜色空间(color space)的种类,Y’UV, YUV, YCbCr,YPbPr等专有名词都可以称为YUV,彼此有重叠。“Y”表示明亮度(Luminance、Luma),“U”和“V”则是色度、浓度(Chrominance、Chroma)。
YUV是视频序列常用传输格式,很多情况其他颜色空间的视频需要转化成YUV进行传输,因为YUV的编码格式没有UV也可以完整的展现出图像,从而解决了黑白图像和彩色图像的兼容问题,还可以降低色度的采样率的同时对图像质量不会产生太大影响。
在使用HM的时候遇到的专业术语
HEVC编码时候可以在命令行看到:
POC:对应图像时域播放顺序的序号,POC 0 就是指时域播放第一帧
TId(temporal id 时域层序号,一个帧只能参考时域层低于他的帧,不能参考更高层的帧)
以及I、P、B帧的帧数、总bit数、YUV各自及总的PSNR值。
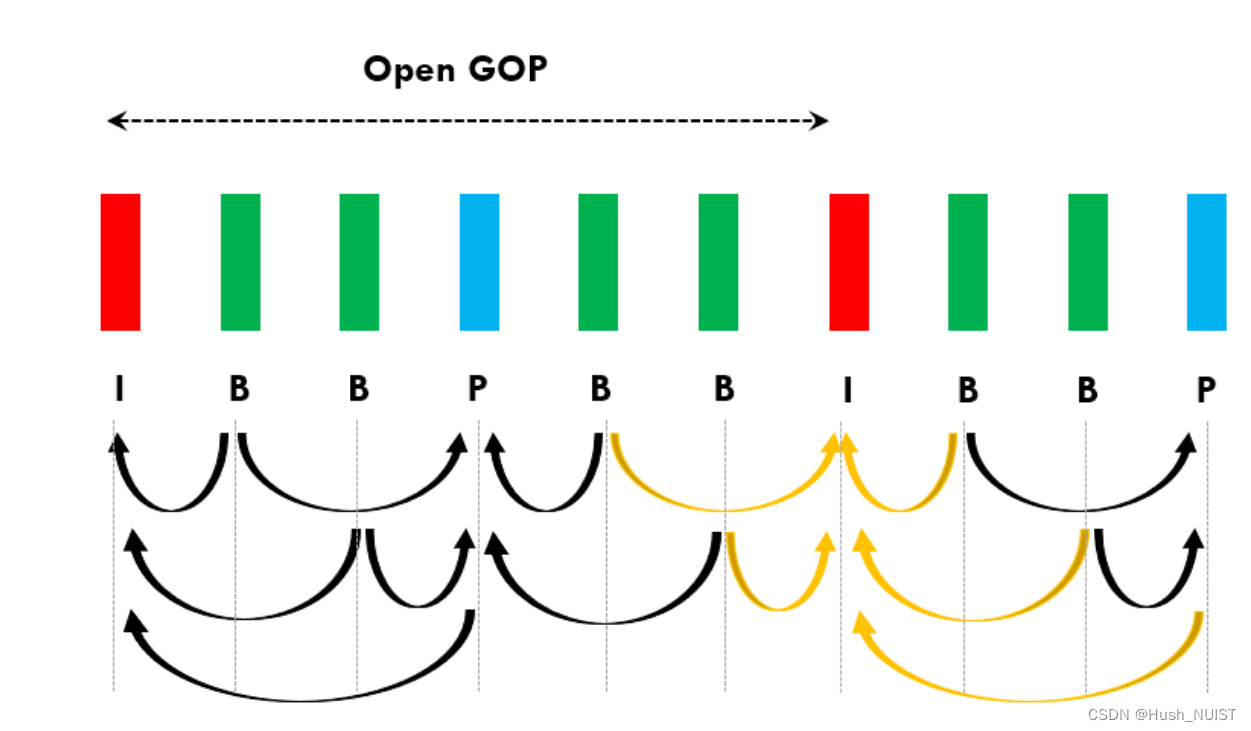
closed gop和open gop
闭合式GOP是指,一个GOP内的最后一个帧是一张I帧,同时下一个GOP的第一个帧也是一张I帧,这样两个GOP之间就没有任何数据相关性。这种方式通常用于需要精确编辑和剪切的场景。
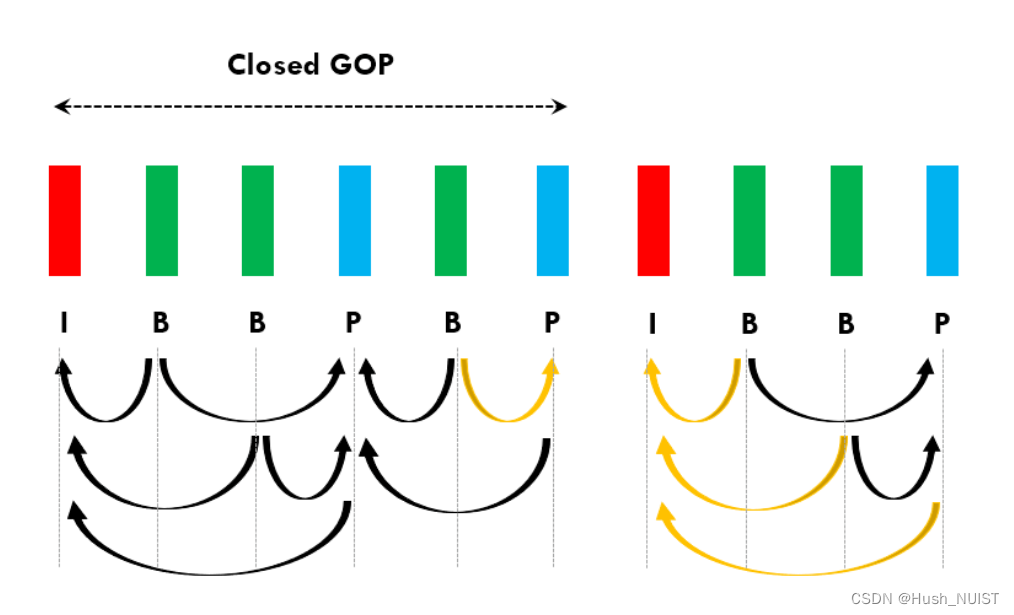
而开放式GOP则是指,一个GOP内的最后一个帧不一定是一张I帧,而是可以是一个B帧。这种情况下上一个GOP的最后一帧可能以下一个GOP的帧为参考进行预测。这种方式通常用于实时传输或流式传输的场景中,因为它可以提高编码效率,减少带宽和存储需求。
这篇文章写的很清楚:
https://zhuanlan.zhihu.com/p/445113040