数据-weather数据集
| outlook |
temperature |
humidity |
wind |
play ball |
| sunny |
hot |
high |
weak |
no |
| sunny |
hot |
high |
strong |
no |
| overcast |
hot |
high |
weak |
yes |
| rain |
mild |
high |
weak |
yes |
| rain |
cool |
normal |
weak |
yes |
| rain |
cool |
normal |
strong |
no |
| overcast |
cool |
normal |
strong |
yes |
| sunny |
mild |
high |
weak |
no |
| sunny |
cool |
normal |
weak |
yes |
| rain |
mild |
normal |
weak |
yes |
| sunny |
mild |
normal |
strong |
yes |
| overcast |
mild |
high |
strong |
yes |
| overcast |
hot |
normal |
weak |
yes |
| rain |
mild |
high |
strong |
no |
具体实现过程
1 加载数据
数据保存在CSV文件中,需要先导入Python,此处使用Pandas包。
# 1.加载数据
names = ['A1', 'A2', 'A3', 'A4', 'A5']
datas = pd.read_csv('weather.csv', header=None, names=names)
# print(df) # 打印数据
# print("数据条数:", len(df)) # 打印数据条数pd.read_csv()
#pd.read_csv(filepath,header=none,encoding="utf-8",names=names)
header:设置导入 DataFrame 的列名称,默认为 "infer",即第1行数据用作列名。
names:命名列索引。
df.head()
默认前5行.
2 数据预处理
缺失值处理
检查数据中是否存在缺失值,并进行处理。此处数据量较小,肉眼观察没有缺失值。此处简单介绍一下对缺失值的处理:
dropna(how = 'any')
axis : {0 or ‘index’, 1 or ‘columns’}, default 0
0, or ‘index’ : 以行为单位进行计算,若该行中具有缺失值则舍去该行,
1, or ‘columns’ : 以列为单位进行计算,若该列中具有缺失值则舍去该列;
how :{‘any’, ‘all’}, default ‘any’
‘any’ : 只要含有NA,就舍去该行/列,
‘all’ : 只有该行/列均为NA时才舍去;
subset:array-like, optional,对特定的列进行缺失值删除处理;
data.dropna(how = 'all') #只丢弃全为缺失值的那些行/列
data.dropna(axis = 1) # 丢弃含有有缺失值的列
data.dropna(axis=1,how="all") # 丢弃全为缺失值的那些列
data.dropna(axis=0,subset = ["Age", "Sex"]) # 丢弃‘Age’和‘Sex’这两列中有缺失值的行 特征处理
观察数据各个字段的类型,对其进行处理,简单来说就是要让计算机理解数据。
查看各字符的相关信息:
print(df.info()) #打印数据相关信息使用独热编码对数据进行处理:
首先我们从独热编码和哑编码的区别入手了解一下独热编码。同样是一个变量A,它有三种不同的取值,分别是v,y,l,那么使用哑编码和独热编码进行编码结果如下:

在python中用来实现的库:
做哑变量编码的库:pandas
one-hot编码的库:sklearn、keras
3 划分X和Y
该数据集是根据outlook、temperature、humidity、wind判断play ball,因此选定outlook、temperature、humidity、wind为X,而play ball 为Y。
4 划分训练集和测试集
train_X,test_X,train_y,test_y = train_test_split(train_data,train_target,test_size=0.3,random_state=0)
参数解释:
train_data:待划分样本数据
train_target:待划分样本数据的结果(标签)
test_size:测试数据占样本数据的比例,若整数则样本数量
random_state:设置随机数种子,保证每次都是同一个随机数。若为0或不填,则每次得到数据都不一样
5 KNN模型构建
knn=KNeighborsClassifier(n_neighbors=3)

n_neighbors:寻找的邻居数,默认是5。
weights:预测中使用的函数。默认:统一权重
| ‘uniform’ | 统一权重,即每个邻域中的所有点均被加权。 |
| ‘distance’ | 权重点与其距离的倒数,在这种情况下,查询点的近邻比远处的近邻具有更大的影响力。 |
| ‘callable’ | 用户定义的函数,该函数接受距离数组,并返回包含权重的相同形状的数组。 |
p:Minkowski距离的指标的功率参数。当p = 1时,等效于使用manhattan_distance(l1)和p=2时使用euclidean_distance(l2)。对于任意p,使用minkowski_distance(l_p)。默认是2。
常用方法:
| fit(X, y) | 使用X作为训练数据和y作为目标值拟合模型。 |
| predict(X) | 预测提供的数据的类标签。 |
| score(X,y) | 返回给定.测试数据和标签上的平均准确度。 |
6 模型评估
classification_report(y_true, y_pred)
sklearn中的classification_report函数用于显示主要分类指标的文本报告。在报告中显示每个类的精确度,召回率,F1值等信息。
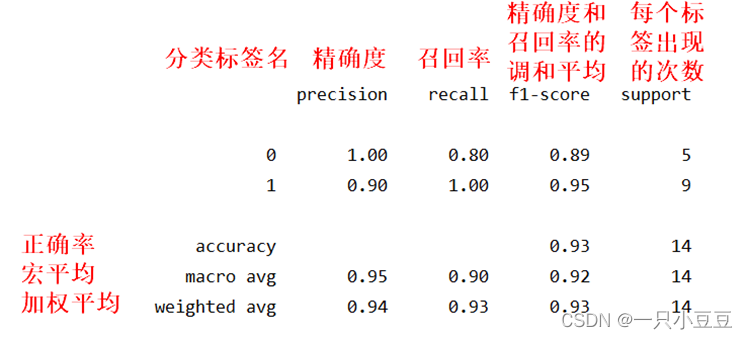
metrics.confusion_matrix(y_true, y_pred)
混淆矩阵
7 预测
给定x的值,预测y,此处对['rain','hot','normal','weak']进行预测
完整代码
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split # 数据划分
from sklearn.neighbors import KNeighborsClassifier # KNN模型
# 1.加载数据
names = ['A1', 'A2', 'A3', 'A4', 'A5']
datas = pd.read_csv('weather.csv', header=None, names=names)
# print(df) # 打印数据
# print("数据条数:", len(df)) # 打印数据条数
# 2.数据预处理
# a.异常数据过滤
# b.查看各字符的相关信息
# print(df.info()) #打印数据相关信息
# c.自定义的一个独热编码实现方式:将v变量转换成为一个向量/list集合的形式
def parse(v, l):
# v是一个字符串,需要进行转换的数据
# l是一个类别信息,其中v是其中的一个值
return [1 if i == v else 0 for i in l]
# print(parse('v', ['v', 'y', 'l'])) # [1, 0, 0]
# print(parse('y', ['v', 'y', 'l'])) # [0, 1, 0]
# print(parse('l', ['v', 'y', 'l'])) # [0, 0, 1]
# d.定义一个处理每条数据的函数
def parseRecord(record):
result = []
a1 = record['A1']
for i in parse(a1, ('sunny', 'overcast', 'rain')):
result.append(i)
a2 = record['A2']
for i in parse(a2, ('hot', 'cool', 'mild')):
result.append(i)
a3 = record['A3']
for i in parse(a3, ('high', 'normal')):
result.append(i)
a4 = record['A4']
for i in parse(a4, ('weak', 'strong')):
result.append(i)
a5 = record['A5']
if a5 == 'yes':
result.append(1)
else:
result.append(0)
return result
# e.将数据转换为数值类型
# 重新定义names
new_names = ['A1_0', 'A1_1', 'A1_2',
'A2_0', 'A2_1', 'A2_2',
'A3_0', 'A3_1',
'A4_0', 'A4_1',
'A5']
datas = datas.apply(lambda x: pd.Series(parseRecord(x), index=new_names), axis=1) # 将函数应用到由各列或行形成的一维数组上。
# print(datas)
# 3.划分X和Y
X = datas[new_names[0:-1]]
Y = datas[new_names[-1]]
# 4.划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
# 5.KNN模型构建
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train) # 训练模型
# 6.模型评估
from sklearn import metrics
from sklearn.metrics import classification_report
y_true, y_pred = Y, knn.predict(X)
print(classification_report(y_true, y_pred))
print(metrics.confusion_matrix(y_true, y_pred))
# 7.预测
# predata=['rain','hot','normal','weak']
print(knn.predict([[0, 0, 1, 1, 0, 0, 0, 1, 1, 0]]))