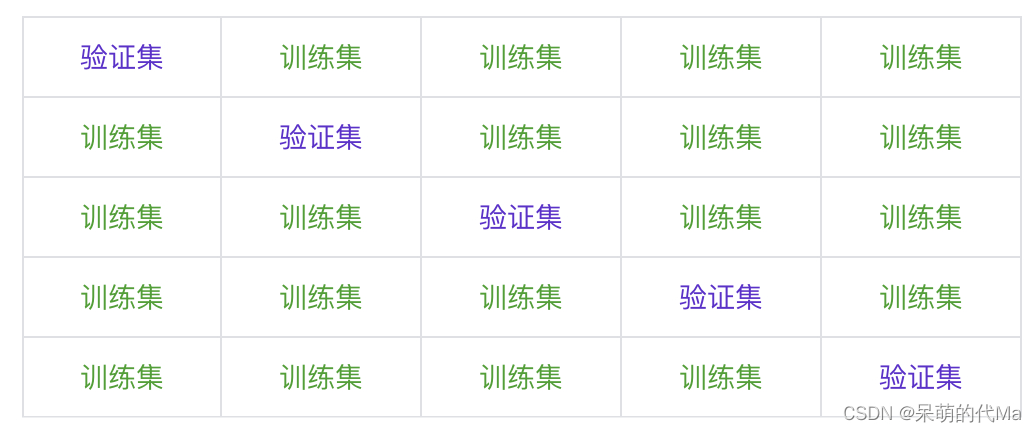
传统N折交叉验证方法
传统的N折交叉验证示意图如下图所示:
时序数据交叉验证方法
由于时间序列数据存在时序关系,因此数据之间的值存在一定的连续性,使用未来的数据验证过去的结果会使模型的验证方法不适合时序数据。
因此,在处理时序数据时,可以使用以下三种方法使用交叉验证方法来验证模型的稳定性:
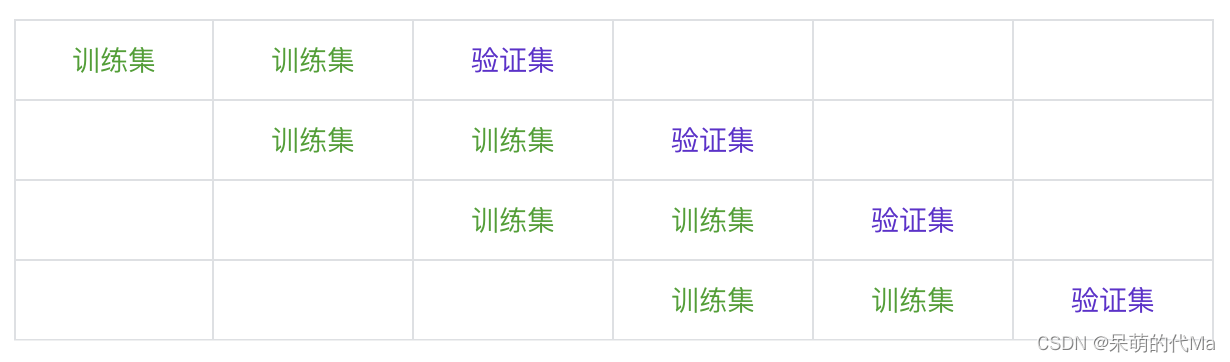
方法1:窗口拆分
示意图如下:
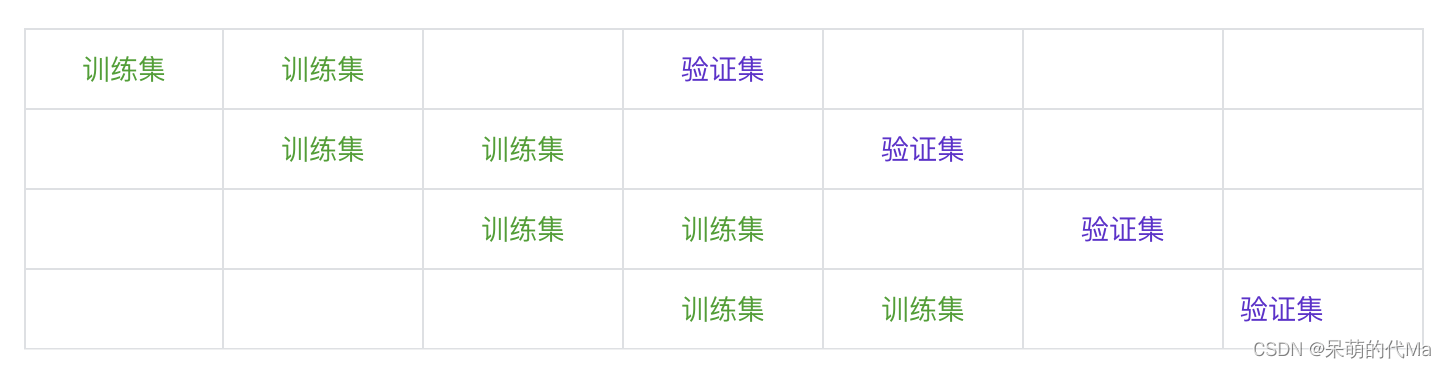
方法2:带间隔的窗口拆分
示意图如下:
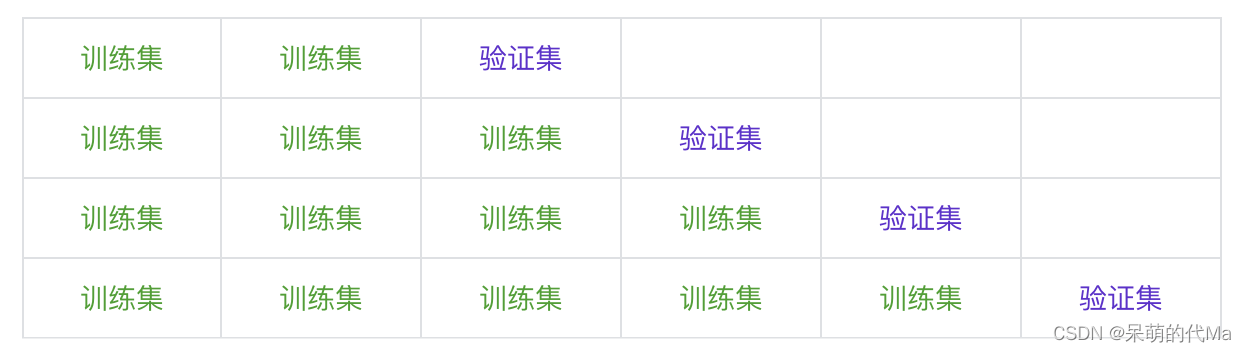
方法3:拓展窗口切分
示意图如下:
扫描二维码关注公众号,回复:
15663654 查看本文章

时序交叉验证python复现
import pandas as pd
def window_rolling_cross_val(time_index: list, train_span=3, val_span=1, split=10, gap=0):
"""窗口拆分
:param time_index:时序数据
:param train_span:训练数据
:param val_span:验证数据
:param split:将原始数据切分为多少个基本单位
:param gap:(带间隔的)间隔
"""
single_step = int(len(time_index) / split) # 单份长度
for _index in range(split - (train_span + val_span + gap) + 1):
train_start_index = _index * single_step # 训练集的起始位置
train_end_index = train_start_index + train_span * single_step # 训练集的终止位置
val_start_index = train_end_index + gap * single_step # 验证集的起始位置
val_end_index = val_start_index + val_span * single_step # 验证集的终止位置
train_data = time_index[train_start_index:train_end_index]
val_data = time_index[val_start_index:val_end_index]
print(f'train_data: {
train_data} val_data:{
val_data}')
def expand_cross_val(time_index: list, start_train_span=3, val_span=1, split=10):
"""拓展窗口切分
:param time_index:时序数据
:param start_train_span:训练数据
:param val_span:验证数据
:param split:将原始数据切分为多少个基本单位
"""
single_step = int(len(time_index) / split) # 单份长度
for _index in range(split - ((start_train_span + val_span) - 1)):
train_start_index = 0 # 训练集的起始位置
train_end_index = train_start_index + (_index + start_train_span) * single_step # 训练集的终止位置
val_start_index = train_end_index # 验证集的起始位置
val_end_index = val_start_index + val_span * single_step # 验证集的终止位置
train_data = time_index[train_start_index:train_end_index]
val_data = time_index[val_start_index:val_end_index]
print(f'train_data: {
train_data} val_data:{
val_data}')
def main():
time_list = pd.date_range("2023-01-01", "2023-02-01").strftime("%Y-%m-%d").tolist()
window_rolling_cross_val(time_list[:20], train_span=3, val_span=1, gap=2)
print('====================')
expand_cross_val(time_list[:20], start_train_span=4, val_span=4)
if __name__ == '__main__':
main()
得到最终的结果:
train_data: ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05', '2023-01-06'] val_data:['2023-01-11', '2023-01-12']
train_data: ['2023-01-03', '2023-01-04', '2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08'] val_data:['2023-01-13', '2023-01-14']
train_data: ['2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08', '2023-01-09', '2023-01-10'] val_data:['2023-01-15', '2023-01-16']
train_data: ['2023-01-07', '2023-01-08', '2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12'] val_data:['2023-01-17', '2023-01-18']
train_data: ['2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12', '2023-01-13', '2023-01-14'] val_data:['2023-01-19', '2023-01-20']
====================
train_data: ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08'] val_data:['2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12', '2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16']
train_data: ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08', '2023-01-09', '2023-01-10'] val_data:['2023-01-11', '2023-01-12', '2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16', '2023-01-17', '2023-01-18']
train_data: ['2023-01-01', '2023-01-02', '2023-01-03', '2023-01-04', '2023-01-05', '2023-01-06', '2023-01-07', '2023-01-08', '2023-01-09', '2023-01-10', '2023-01-11', '2023-01-12'] val_data:['2023-01-13', '2023-01-14', '2023-01-15', '2023-01-16', '2023-01-17', '2023-01-18', '2023-01-19', '2023-01-20']