Redis数据5种基本的数据类型
文章目录
一、字符串常用操作
SET key value //存入字符串键值对
MSET key value [key value …] //批量存储字符串键值对
SETNX key value //存入一个不存在的字符串键值对
GET key //获取一个字符串键值
MGET key [key …] //批量获取字符串键值
DEL key [key …] //删除一个键
EXPIRE key seconds //设置一个键的过期时间(秒)
原子加减:
INCR key //将key中储存的数字值加1
DECR key //将key中储存的数字值减1
INCRBY key increment //将key所储存的值加上increment
DECRBY key decrement //将key所储存的值减去decrement
应用场景:
文章的访问量 + 对象存储 + 分布式锁
底层数据结构
127.0.0:6379> set str guojia
127.0.0:6379> set 100 100000
127.0.0:6379> set long aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
127.0.0:6379>type str #"string"
127.0.0:6379>type 100 #"string"
127.0.0:6379>type long #"string"
127.0.0:6379>object encoding str #"embstr"
127.0.0:6379>object encoding 100 #"int"
127.0.0:6379>object encoding long #"raw"
int 固定的长度 8个字节 64bit ,最多不超过20位
redisObjet 16字节,多出48 - 4 = 44字节
所以字符串大小在44以下的字节数 就可以存储下---->embstr一次性IO
否则就是raw需要多次读写操作IO
bitmap(32位String类型)最大512M
setbit key offet [0|1]
bitcount key 统计有多少个1
bitcount key start end 统计第start字节到end字节
应用场景:
签到(用户数据量大)
统计周统计是否登录
二、Hash常用操作 (注意大key)
HSET key field value //存储一个哈希表key的键值
HSETNX key field value //存储一个不存在的哈希表key的键值
HMSET key field value [field value …] //在一个哈希表key中存储多个键值对
HGET key field //获取哈希表key对应的field键值
HMGET key field [field …] //批量获取哈希表key中多个field键值
HDEL key field [field …] //删除哈希表key中的field键值
HLEN key //返回哈希表key中field的数量
HGETALL key //返回哈希表key中所有的键值
HINCRBY key field increment //为哈希表key中field键的值加上增量increment
应用场景:
对象存储 + 电商购物车
Hash数据结构实现
Hash 数据结构底层实现为一个字典( dict ),也是RedisBb用来存储K-V的数据结构,当数据量比较小,或者单个元素比较小时,底层用ziplist存储,数据大小和元素数量阈值可以通过如下参数设置。

hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码
hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
三、List常用操作
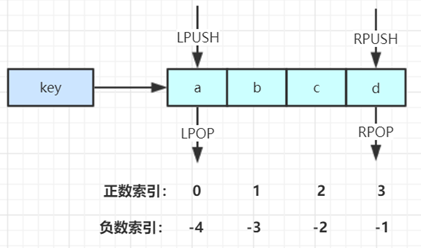
LPUSH key value [value …] //将一个或多个值value插入到key列表的表头(最左边)
RPUSH key value [value …] //将一个或多个值value插入到key列表的表尾(最右边)
LPOP key //移除并返回key列表的头元素
RPOP key //移除并返回key列表的尾元素
LRANGE key start stop //返回列表key中指定区间内的元素,区间以偏移量start和stop指定
BLPOP key [key …] timeout //从key列表表头弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
BRPOP key [key …] timeout //从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
应用场景:
微信公众号流 + 公众号消息

底层数据结构实现
为了防止胖指针现象情况,
所以引入了ziplist

quicklist就是双端队列形式
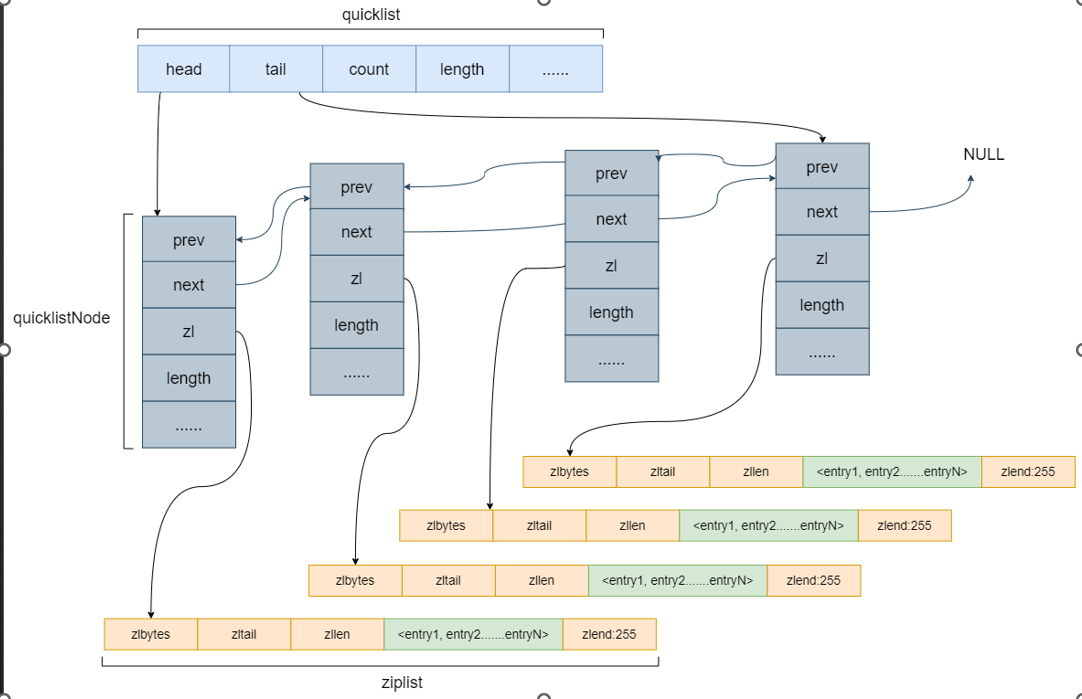
list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
list-compress-depth 1 // 0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 ... 以此类推
四、Set常用操作
SADD key member [member …] //往集合key中存入元素,元素存在则忽略,
若key不存在则新建
SREM key member [member …] //从集合key中删除元素
SMEMBERS key //获取集合key中所有元素
SCARD key //获取集合key的元素个数
SISMEMBER key member //判断member元素是否存在于集合key中
SRANDMEMBER key [count] //从集合key中选出count个元素,元素不从key中删除
SPOP key [count] //从集合key中选出count个元素,元素从key中删除
应用场景:
抽奖 + 微信点赞 + 收藏 + 标签


Set数据结构实现
Set 为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value 为 null 的 字典( dict ),当数据可以用整形表示时,Set集合将被编码为int set(有序)数据结构。两个条件任意满足时

Set将用hashtable存储数据。
1, 元素个数大于 set-max-intset-entries ,
2 , 元素无法用整形表示
set-max-intset-entries 512 // intset 能存储的最大元素个数,超过则用hashtable编码
Set运算操作
SINTER key [key …] //交集运算
SINTERSTORE destination key [key …] //将交集结果存入新集合destination中
SUNION key [key …] //并集运算
SUNIONSTORE destination key [key …] //将并集结果存入新集合destination中
SDIFF key [key …] //差集运算
SDIFFSTORE destination key [key …] //将差集结果存入新集合destination中
应用场景:
电商筛选 + 微博关注人脉

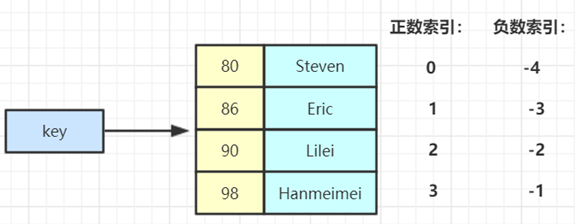
五、ZSet常用操作
ZADD key score member [[score member]…] //往有序集合key中加入带分值元素
ZREM key member [member …] //从有序集合key中删除元素
ZSCORE key member //返回有序集合key中元素member的分值
ZINCRBY key increment member //为有序集合key中元素member的分值加上increment
ZCARD key //返回有序集合key中元素个数
ZRANGE key start stop [WITHSCORES] //正序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES] //倒序获取有序集合key从start下标到stop下标的元素
应用场景:
微博热搜
Zset集合操作
ZUNIONSTORE destkey numkeys key [key …] //并集计算
ZINTERSTORE destkey numkeys key [key …] //交集计算
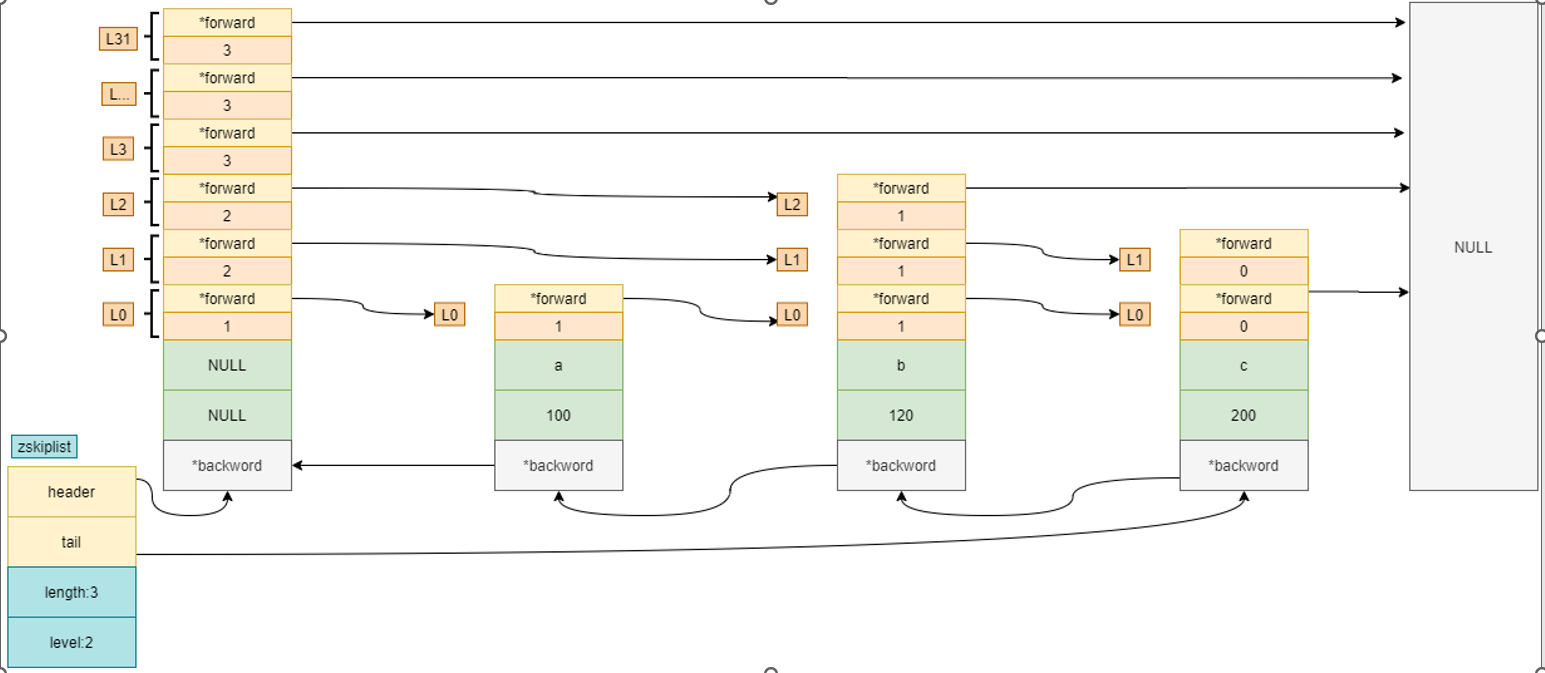
Zset数据结构实现
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储。

zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码
zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
跳表:
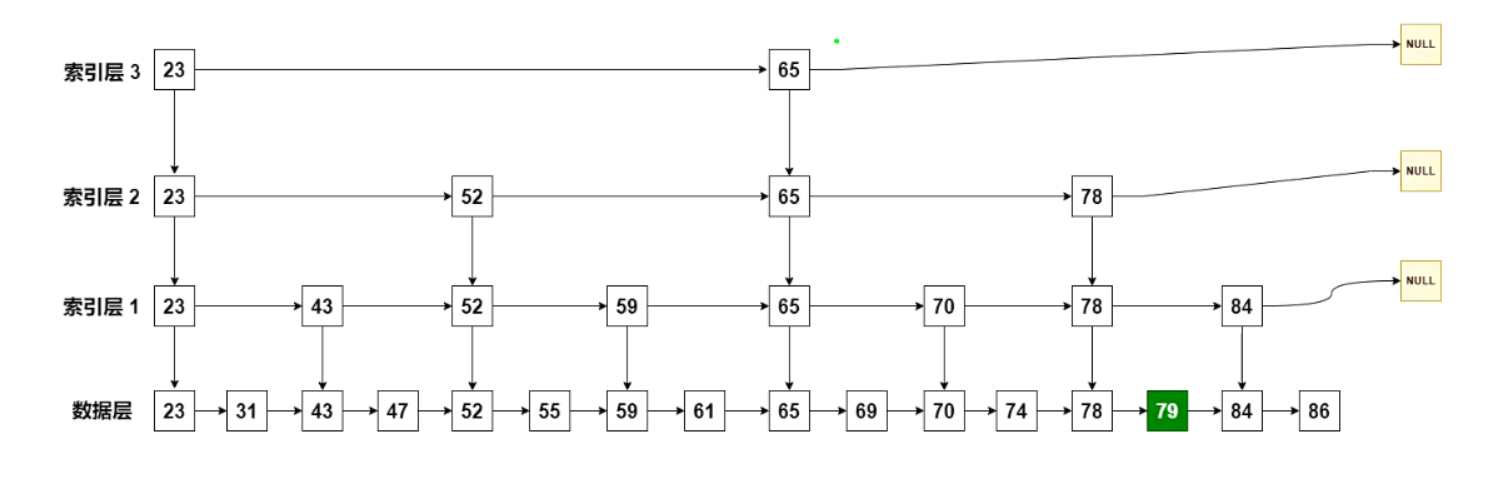
字典用来查询数据到分数的对应关系
skiplist用来根据分数查询数据
六、bitmap(32位String类型)最大512M
setbit key offet [0|1]
bitcount key 统计有多少个1
bitcount key start end 统计第start字节到end字节
应用场景:
签到(用户数据量大)
统计周统计是否登录
七、Redis所有的键都是用String类型表示的?
sds :
int free: 0 (剩余空间)
int len: 6 (字符串长度)
char buf[] = “guojia”
扩容机制:(len + addlen ) * 2 :
char buf[] = “guojia123”
len = (6+3)*2 =18
如果 地址达到1M(1024 * 1024)大小的时候就不再是上面的那种 1倍的扩容了,而是每次扩大1M
上面的len 是4字节32位 ,所以表示最大的长度是 8,589,934,592
而redis做了优化 ,有些字符串用不到这么大的空间,所以就浪费掉内存
redis存储String类型的几种形式
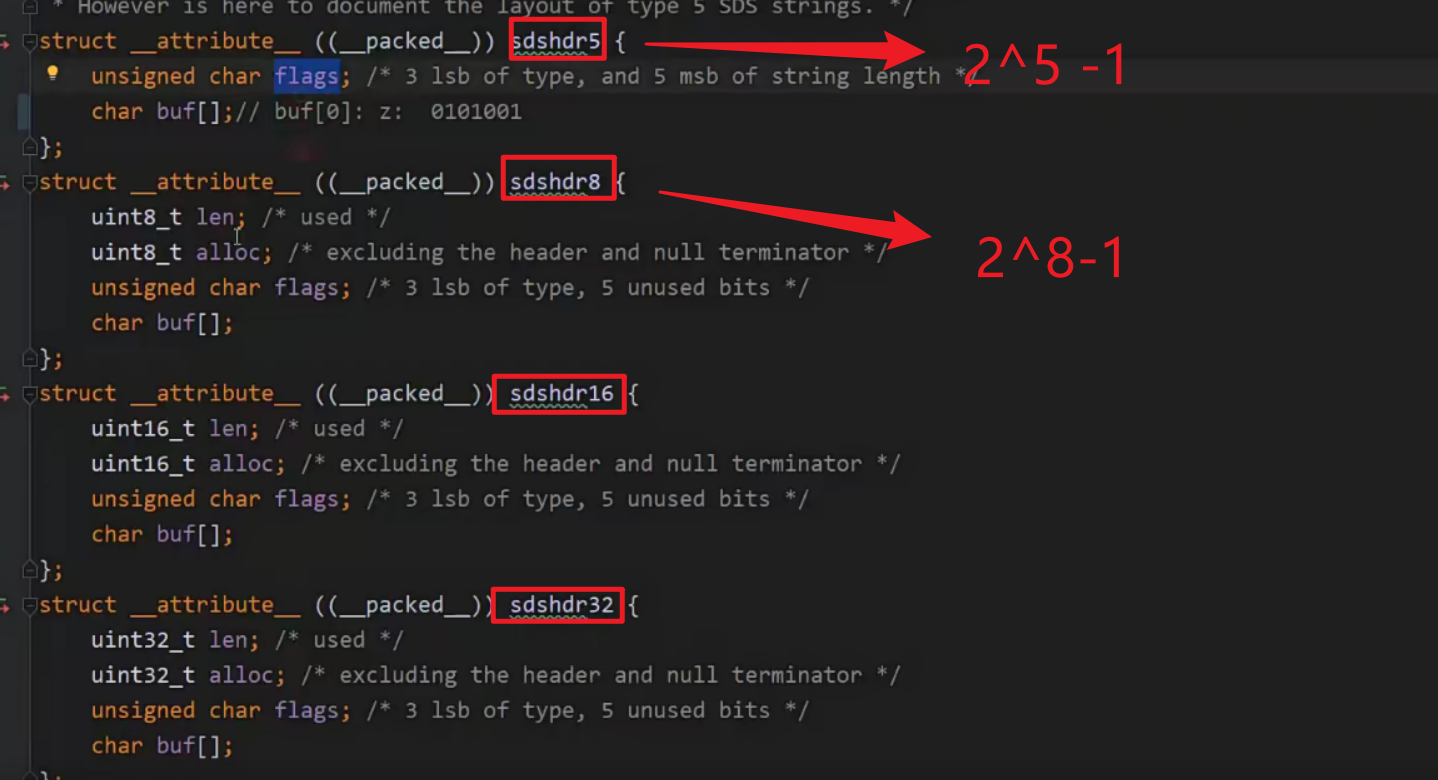
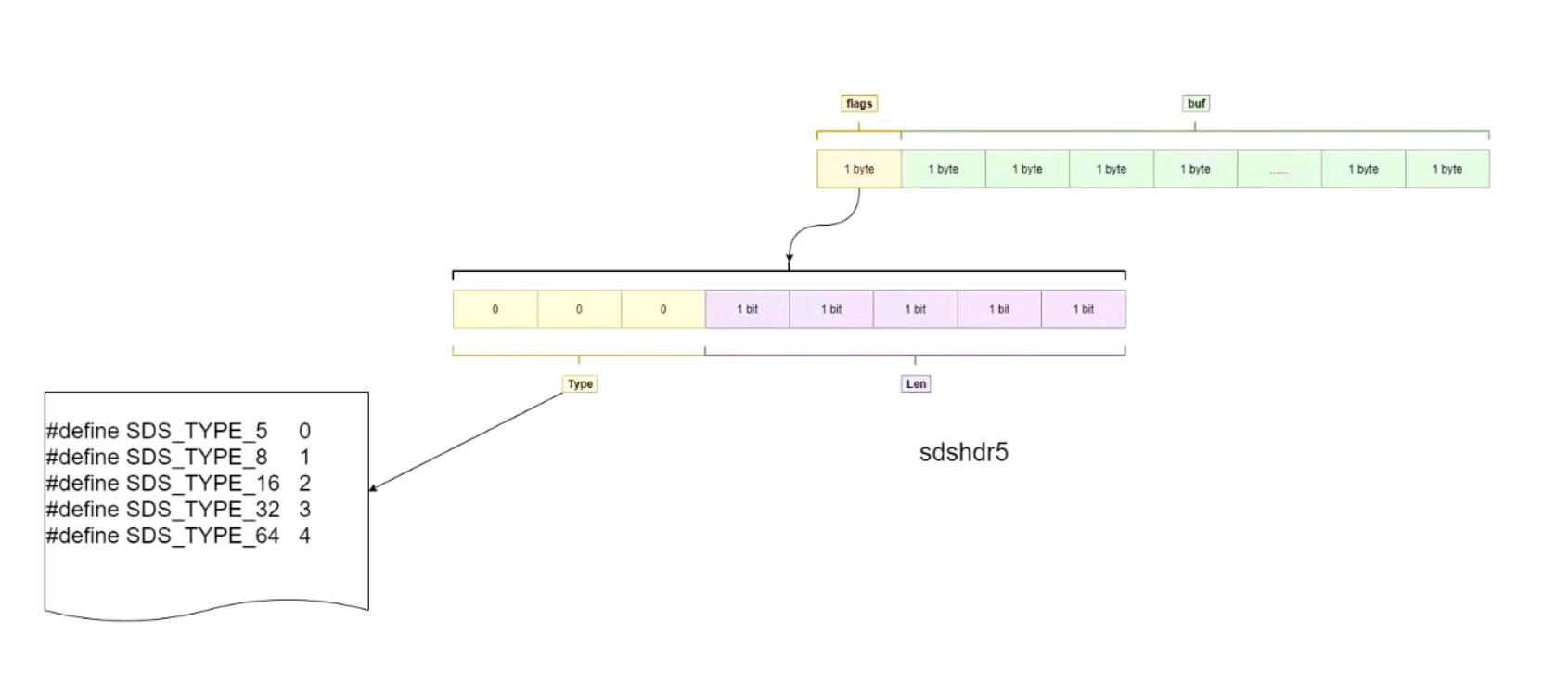
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length 1 字节 8bit位 */
char buf[];
};
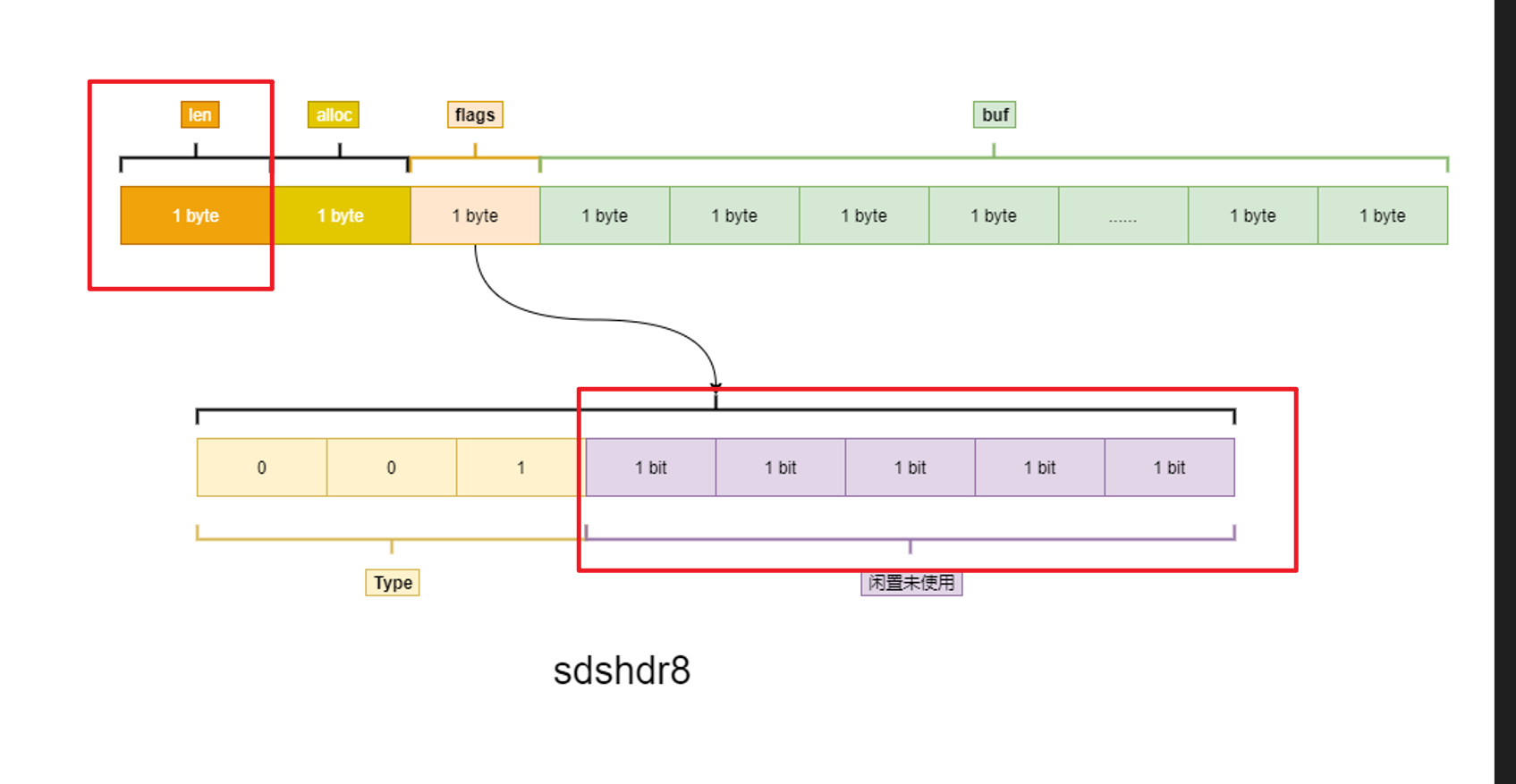
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //1字节 /* used */
uint8_t alloc; // 1字节 /* excluding the header and null terminator */
unsigned char flags; //1字节 /* 3 lsb of type, 5 unused bits */
char buf[]; //1字节
};
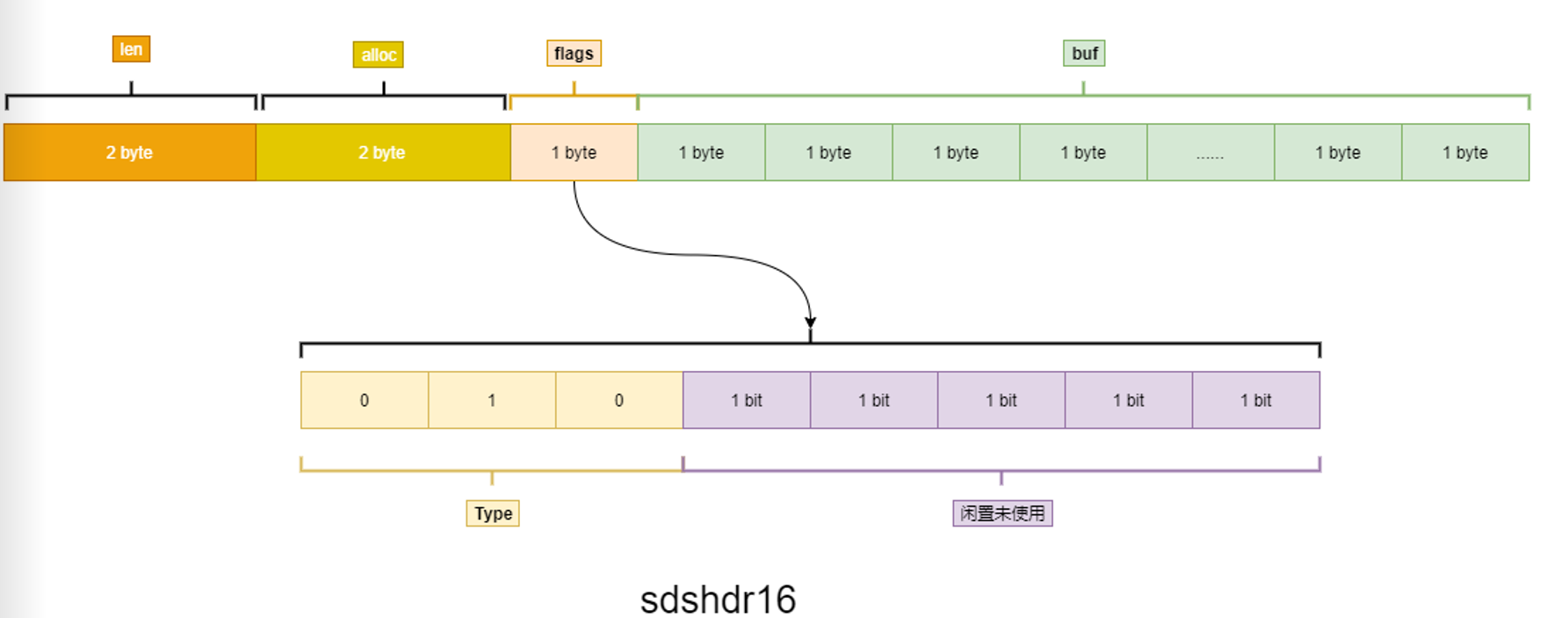
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
八、Redis底层数据结构实现
扩容:是渐进式的扩容机制,因为redis在数据键的存储和查看的时候都是单线程的,如果直接扩容那么数据的迁移会影响性能,甚至会阻塞住。
渐进式:当访问这个数据,再去做迁移(一个桶一个桶的去搬)。如果一直没有去访问键值对,有个时间轮询挨个去搬。
//redis 中默认的16个库
typedef struct redisDb {
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
long long avg_ttl;
unsigned long expires_cursor;
list *defrag_later;
} redisDb;
//map -> dict
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2]; //两个主要是用于扩容新老数据搬迁使用的
long rehashidx;
unsigned long iterators;
} dict;
//table -> dictht
typedef struct dictht {
dictEntry **table; //就是table表
unsigned long size; //数组的长度
unsigned long sizemask; //size-1
unsigned long used; //Entry个数 user == size 扩容一倍
} dictht;
// Entry -> dictEntry
typedef struct dictEntry {
void *key; //指向的String对象
union { //value
void *val; //value 的类型
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //用于链表使用的,即hash冲突
} dictEntry;
//封装的是redis中的所有的类型
typedef struct redisObject {
unsigned type:4; //4bit,,string,hash,list 约束客户端的命令使用的
unsigned encoding:4; //4bit object encoding
unsigned lru:LRU_BITS; //3字节
int refcount;// 4字节
void *ptr; //8字节 真正存储的数据
} robj;