
以下内容整理自大数据能力提升项目必修课《大数据系统基础》同学们的期末答辩汇报。

各位老师大家上午好,我们组的题目是智能网联汽车大数据基础平台的构建。我们的指导企业是西部智联。我们的汇报将从这五个方面进行展开,第一个方面是项目背景与需求分析。
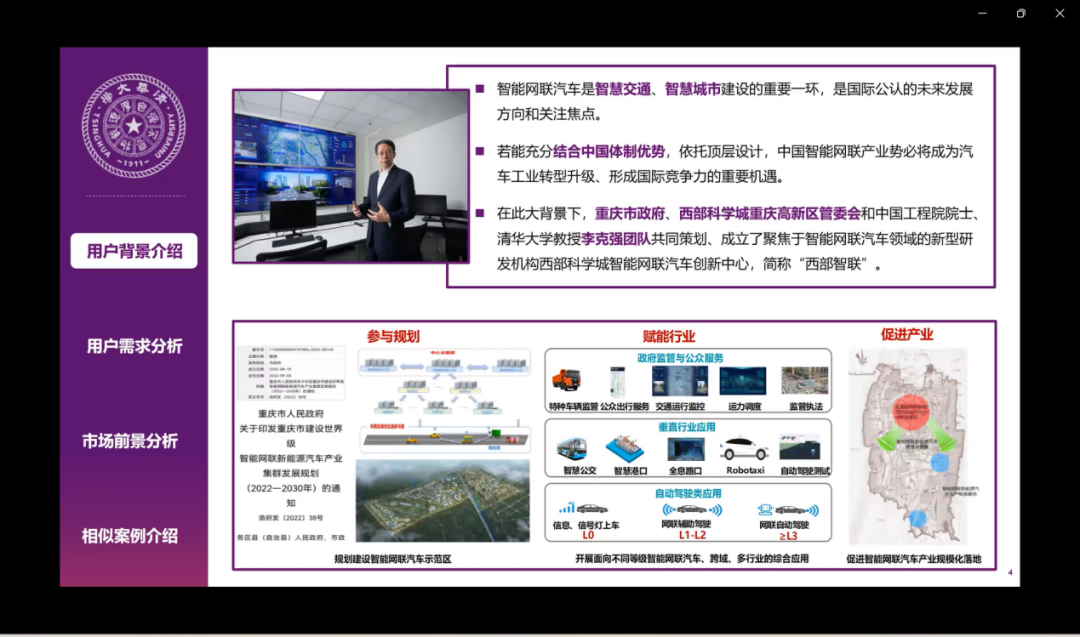
智能网联汽车是推进智慧交通发展,实现智慧城市建设的重要一环,也是国际公认的未来发展方向,也是我们中国能够实现汽车工业转型、形成国际竞争力的一个重要机遇。因此,重庆市政府西部科学城、重庆高新区管委会和我们学校的李克强教授团队共同策划成立了智能网联汽车领域的研发机构——西部科学城智能网联汽车创新中心。西部智联也是广泛开展业务,推进产业协同发展,促进智能网联汽车产业的规模化落地。
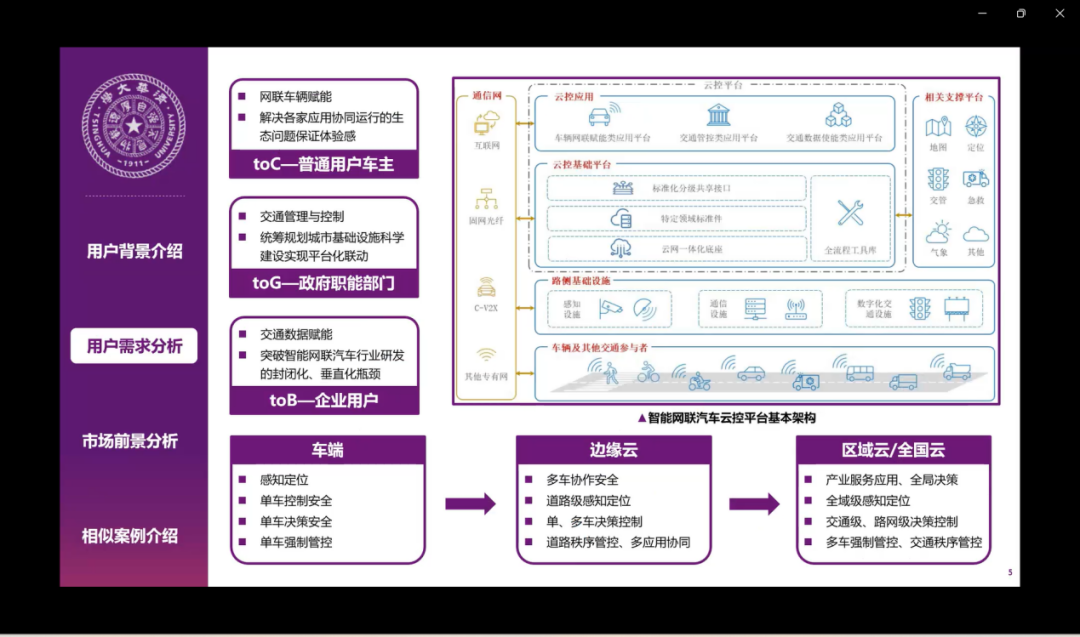
智能网联汽车云控平台的用户主要是普通车主、政府以及企业用户三个部分。普通车主的需求主要是解决应用协同的问题,保证体验感。对于政府的话,主要是要统筹整个交通的管理与控制,对于企业用户的话是利用数据赋能推进产业研发的瓶颈。因此我们就需要不断建立健全车端云、边缘云、区域云、全国云四级的支撑体系。
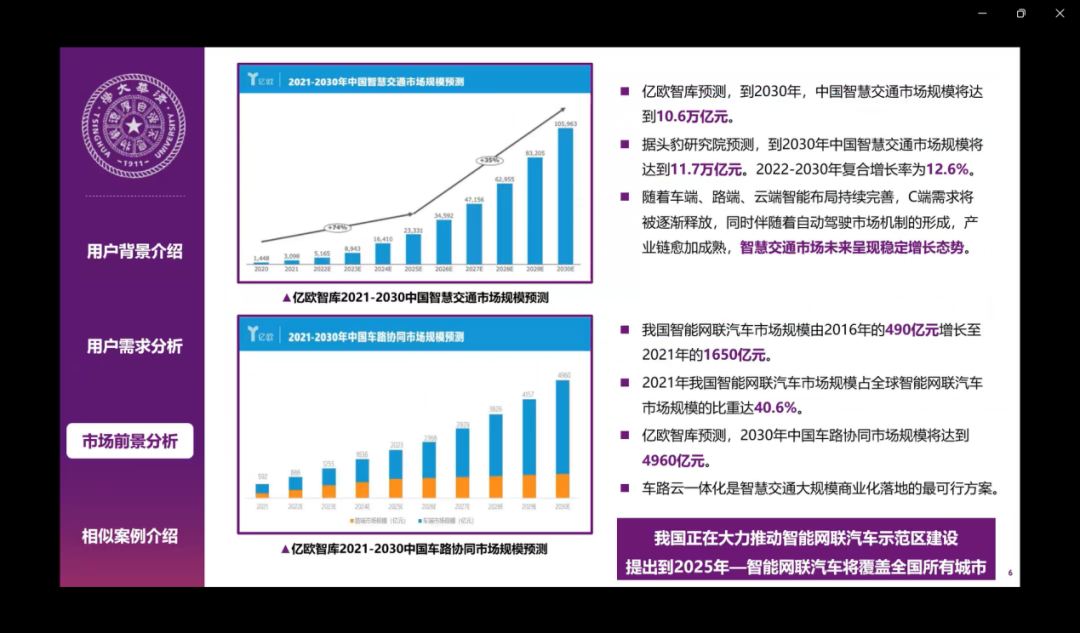
对于市场前景的话,智能交通市场未来的发展也在持续增长,整个市场规模也是非常巨大的,车路云一体化是实现整个智慧交通商业化落地的一个最可行的方案。因此我国也正在大力推动智能网联汽车示范区的建设。提出到2025年,智能网联汽车将会覆盖全国的所有城市。
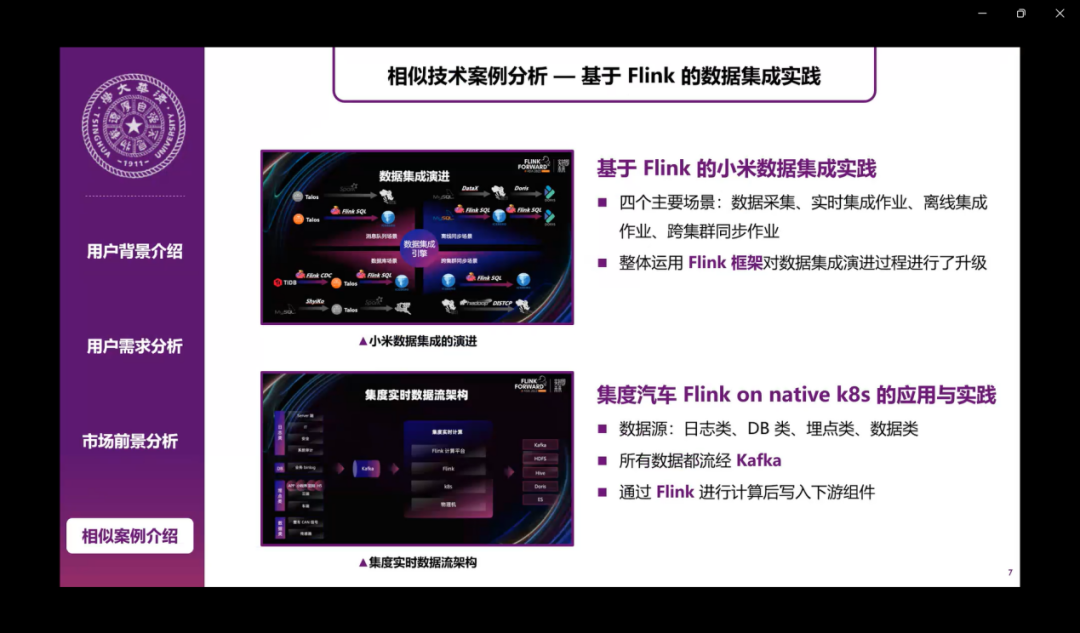
小米还有集度汽车也采用Flink和Kafka进行了一些数据集成的实践,我们也建立了北京亦庄自动驾驶示范区以及国家智能网联汽车长沙测试区,实现了智慧公交、自动驾驶出租车等应用。
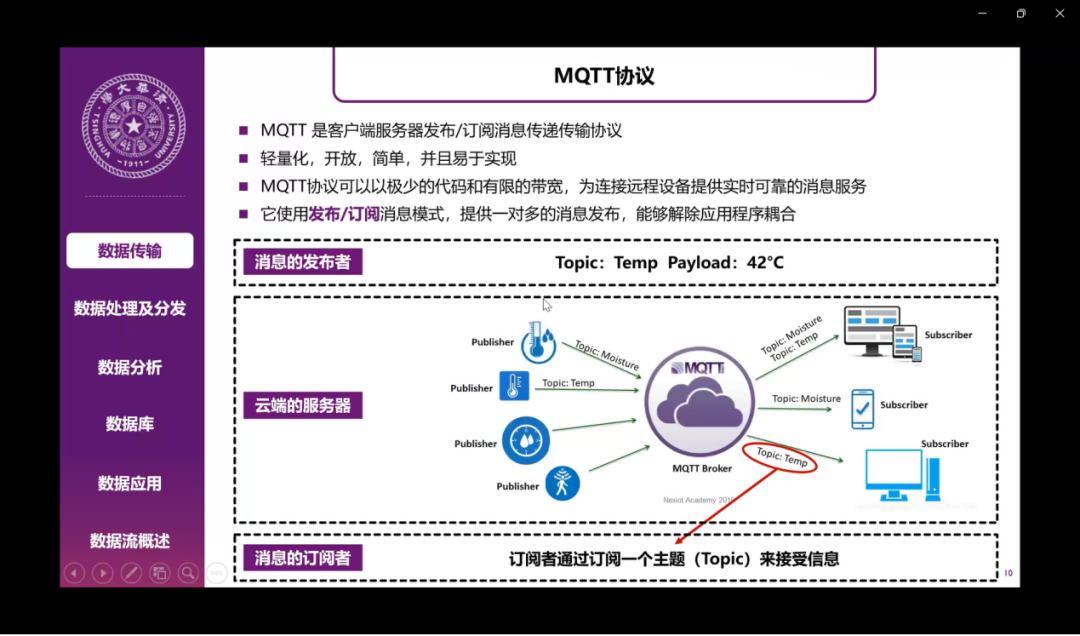
接下来我来介绍一下整个系统的设计架构。首先,在数据传输阶段,我们采用了MQTT协议进行消息的发布,还有订阅提供一对多的消息发布。在数据处理分发的方面,我们首先采用了Apache Nifi用于可视化的实时整理数据流动,整合数据的总线,接着运用了Kafka对数据进行分发,分发给不同的消费者。在数据分析方面,我们采用了Apache Flink进行有状态的计算,接着把数据分析后的数据传入一个TimescaleDB里面。TimescaleDB是基于postgreSQL数据库打造的一个时序数据库。数据可以自动按照时间和空间进行一个分区。在数据应用方面,我们运用了Apache的Superset进行可视化,因为它可以支持多种的数据库,包括连接我们之前用到的TimescaleDB数据库。
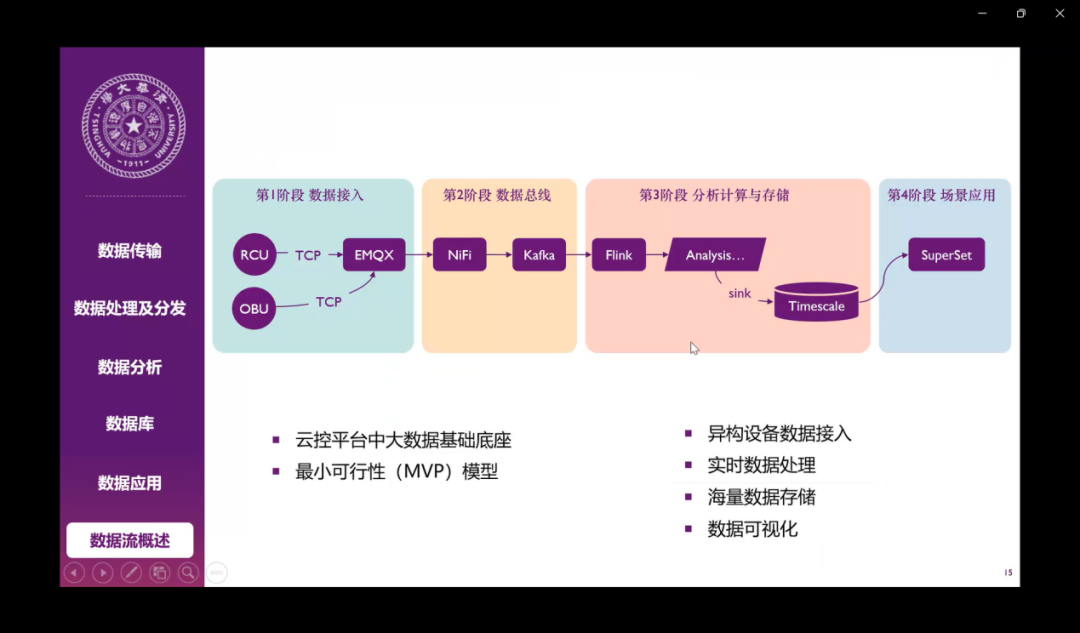
我们整体的系统的架构如上图所示。除了上述讲到的一些技术以外,在第一部分的数据接入,我们采用的数据是企业提供的一个RCU路端数据,还有一个OBU的云车端的数据,然后采用了TCP协议进行通信,然后运用EMQX的引擎进行数据的接入。基于这个系统框架,我们进行后续的开发实践。

下面我来介绍一下技术实现的部分。首先是我们开发工作的基础,我们开发工作是基于三台华为云的Linux机器,这里非常感谢企业导师的支持。然后初始机的环境的配置、开发用的数据主要是导师提供的静态数据,一共是40万条,还有数据源的模拟程序,所以最终的动态数据的量级可以达到千万的量级。导师也提供了一个数据交互规范,供我们进行参考。

数据源程序是使用GO语言进行开发的,我们是使用的MQTT的TCP协议进行传输,模拟实际的数据。单个程序的数据源是10赫兹,我们发送的是一个序列化的Json数据,但这个程序可以启动多个进程,可以模拟多车多路侧单元。我们设计的QoS是0,最多分发一次,这样网络负载比较低,虽然数据有可能会丢失,但是对我们整个实验没有什么太大的影响,下面是一个这个数据的示例。
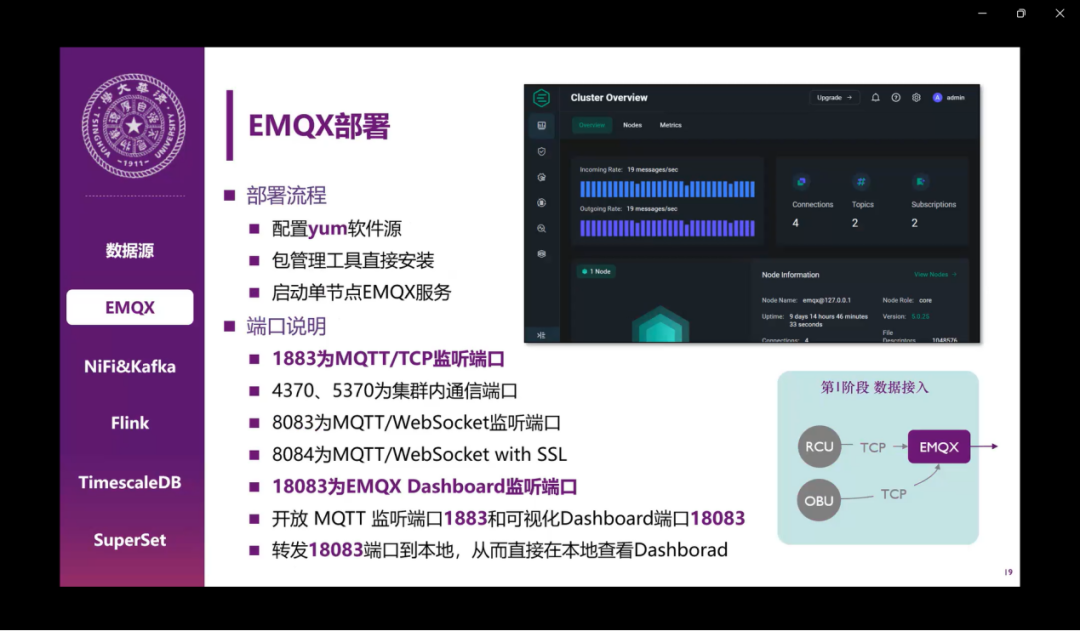
然后是EMQX的部署,这个部署就比较简单。需要说明的是EMQX安装在服务器上,所以需要考虑到网络安全的问题,所以我们最终还是没有对公网进行开放,我们把端口转发到本地进行调试。右上角就是我们安装完之后的dashboard,我们可以在里面很轻松地看到每秒传入和传出的信息量。
接下来是NiFi和Kafka两个部分,Kafka需要特别注意一下,因为我们后续是在不同的机器上进行流式计算,所以我们需要在局域网内其他机器去访问Kafka,所以我们还需要修改一下相关的监听地址。然后就是NiFi的配置,这个配置主要是两个方面,一个是连接EMQX,是一个MQTT的消费者,然后是连接Kafka,它是一个Kafka brokers,是一个生产者。我们通过同样的方式订阅了OBU所有的信息,把数据直接传输到Kafka中。
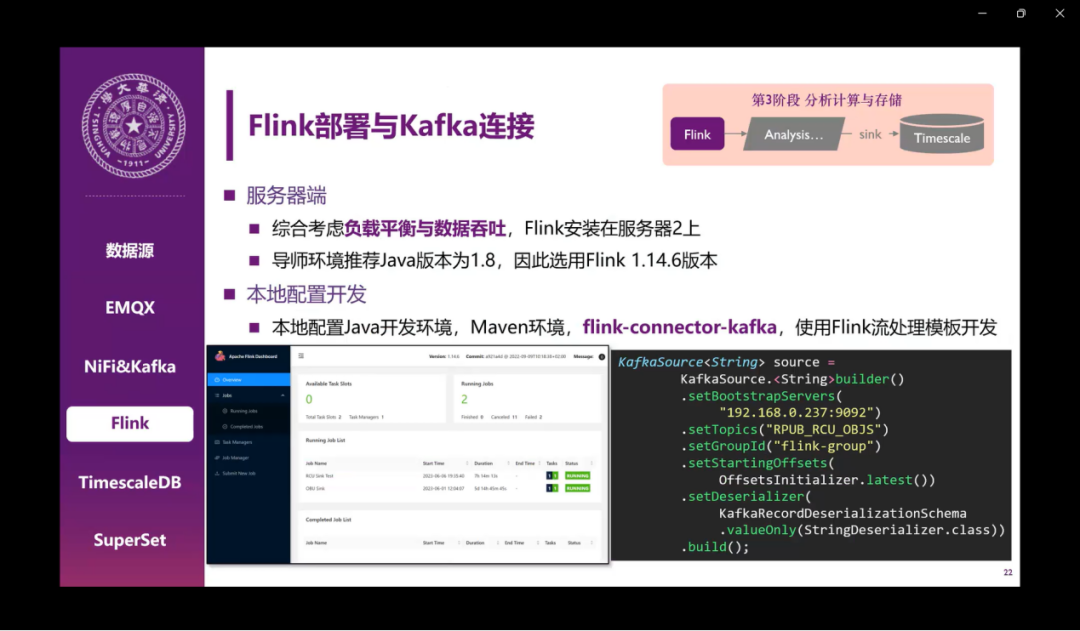
关于Flink的部署,我们在服务器端主要也是考虑到负载平衡和数据吞吐的一些原因,把之前网络密集型的放在了服务器一上,现在这个计算密集型的我们就安装在了服务器二。导师推荐的java环境是JDK1.8,所以我们就用了之前的Flink 1.14.6版本。在本地也需要同样配置一个java开发环境,maven的一个仓库,添加一个相关的价包,然后就可以用这个Flink的流处理模板去进行开发了。右下角是我们做的Kafka source示例,主要是添加一下相关的地址信息和订阅的主题,就可以获得相关的一些offset,配置一下反序列化的方法就可以了。
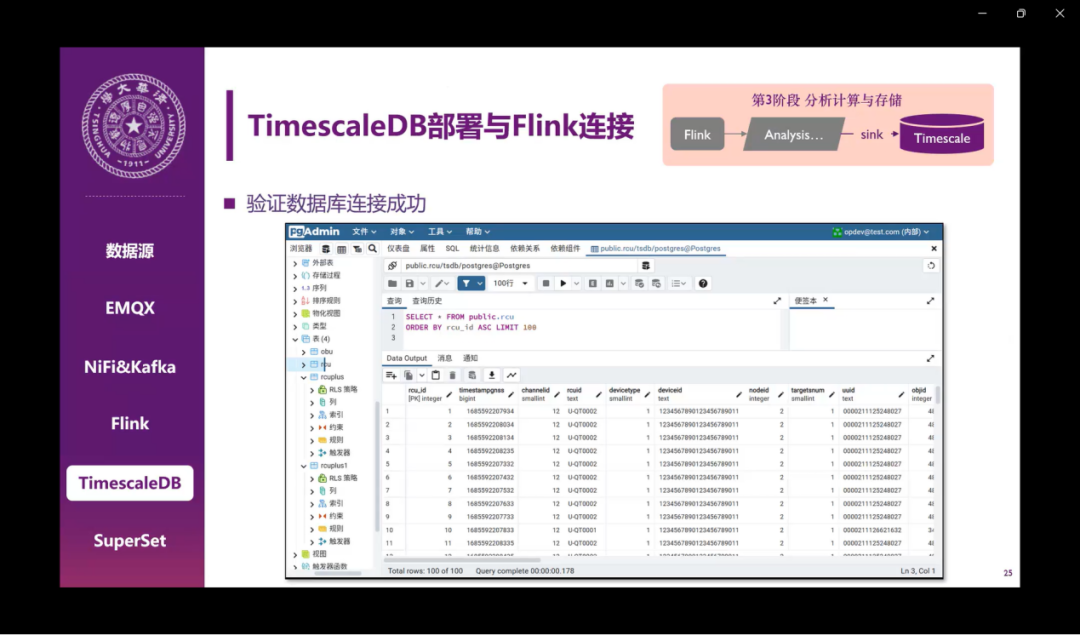
之后是TimescaleDB的连接,主要是我们需要设计一个存储表,我们是用的JDBC Sink,然后把Flink的计算结果直接存到TimescaleDB中。后面我们验证了一下这个数据库连接是否成功,我们在postgres admin中直接查看数据的结果,可以看到它已经成功存入到数据中了。
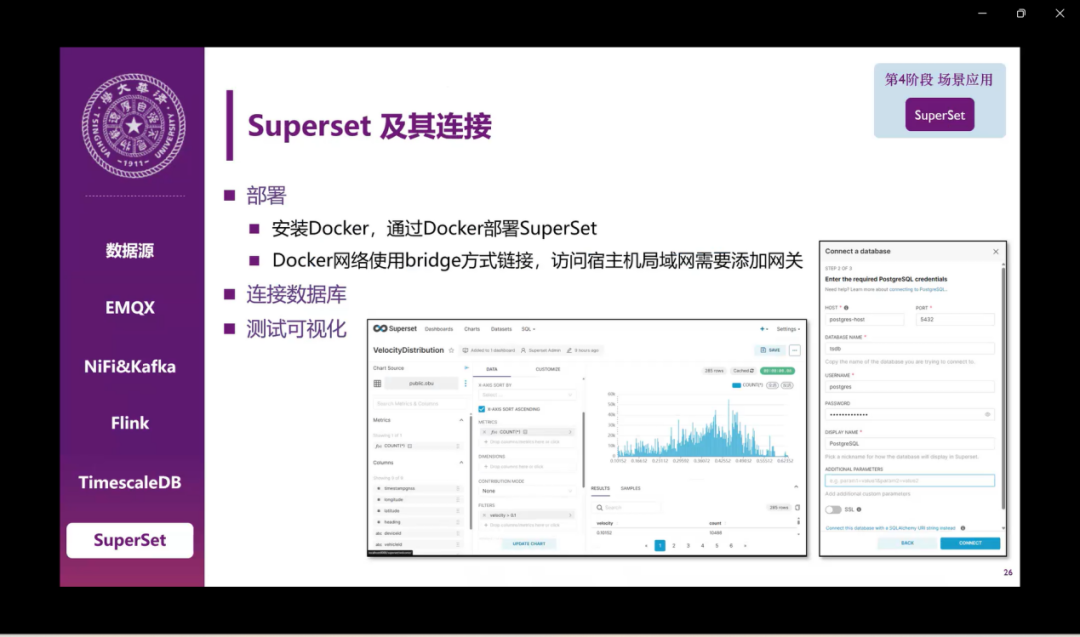
然后是Superset和它的连接,我们是用的这种容器化的部署方式,就是用docker去部署,但是这个其实有一些问题,因为容易出现网络访问的问题,它需要访问速手机局域网内的一个其他的服务器,所以还是要去加一些网关方面的操作。在这个配置完成之后,可以看到这个最大的这张图,实现了数据的可视化。
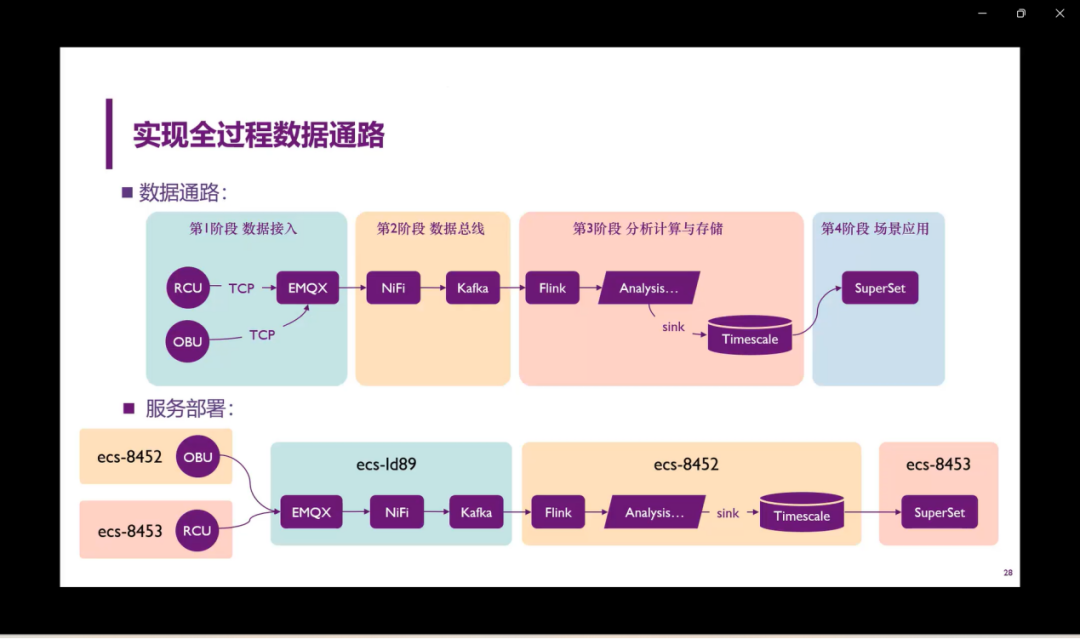
接下来我们简单看一些成果展示。首先,最大的成果就是我们实现了从原始数据,也就是从最开始的RCU、OBU的数据到最后呈现到用户手里的Superset,我们可以用可视化的方法实际看到或者探索数据。下面是服务器的部署,为了平和三台服务器上的工作,让负载相对均衡一点,我们把三台服务器上安装的分别的东西都列举在这儿了。第二个部分就是我们的创新点,能够处理实时流数据。从一开始RCU、OBU到EMQX,我们对于流数据的支持进行了一定的考虑,一直到最后,整个过程都是支持完全支持流数据处理的。第三就是整个数据和架构都具备横向拓展的空间,我们现在测试用的原始数据是40万条,但是一方面这个数据库我们可以拓展,比如说sink到timescaleDB甚至更多的数据库。最后的可视化也不是只有在Superset,可以在从数据库中取数据到任何其他你想要的地方,包括从前面我们NiFi、Kafka对于这个topic的管理都是非常完善的,我们有更多的topic,可以有更多的生产者,消费者。最后就是我们在做的这个过程中间也把这些软件程序的应用给服务化了,服务化的好处就是能够保证这些服务都能在后台去运行。我们借助在这个特点,再借助我们用的图形界面,我们不需要在登录服务器做什么操作了,只需要在本地端在命令行里边输入一段命令,就可以直接在本地的localhost中看到每一个部分的可视化界面,方便我们后续的操作和测试。

之后就是Flink的计算。Flink除了对消息的转发之外,也包括计算能力。我们这里通过一个简单的例子去测试一下Flink的计算。这里我们对于输入进来的数据分类统计每一个时间段的数量,我们在Flink里添加了一些相应的计算代码之后,把数据也sink到了Times DB的数据库当中。在这个TimesscaleDB数据当中,我们就可以看到由Flink计算得到的数据。它在TimesscaleDB中呈现出一个数据积累的效果,那么就验证了在Flink有状态计算的功能。
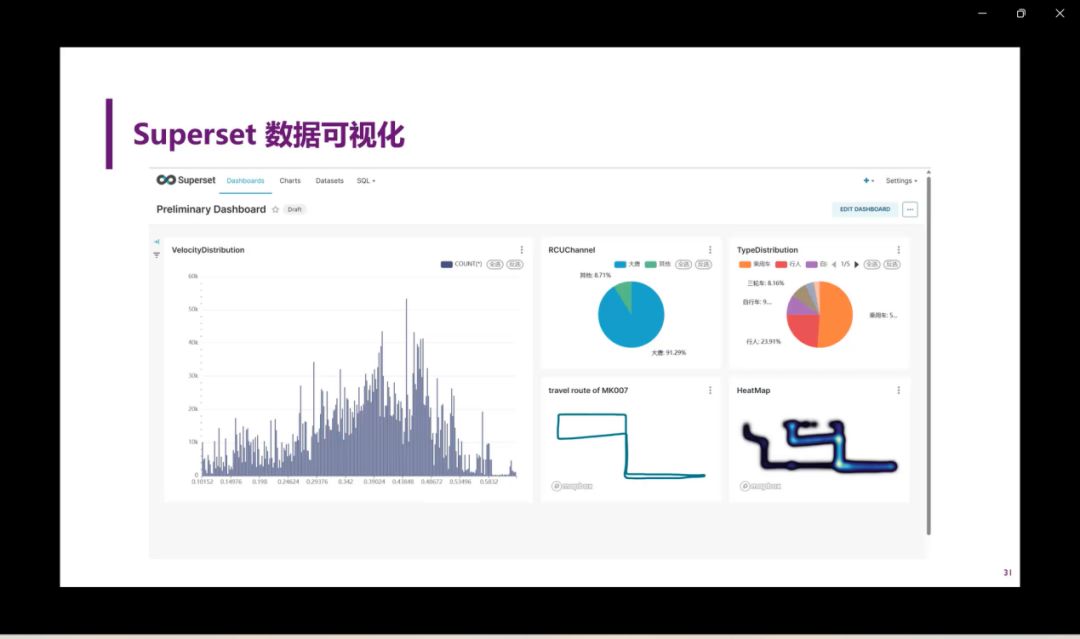
另外就是Superset的数据可视化,我们做了一个初步的示例dashboard。可以看出来,右上角的两个图对于来源数据进行分类统计,然后左边这个图是对于所有车的数据——速度进行了实时的分布统计图。右下角是其中一辆车,比如说是它的代号是mk007,这辆车它的轨迹样式,以及所有车的所有数据点的heat map。这里heat map我们可以看出就是在哪些地方,它明显是一个路口。这里数据点是比较多的,有可能是因为车在这速度比较慢,或者说车在这甚至停掉了。那么在这个heat map可以看到所有数据点的分布情况。
最后简单总结和反思一下,我们在整个项目过程中间定期的组成例会,每次例会都留有议题文件以及文件内的详情,每次会议我们都有企业导师去参与进行指导。最后我们整个团队的合作就依照着技术路线来展开,一步一步来做,步步为营,统筹技术,文字等等去发挥每一位同学的长处优势。
关于收获,整个过程大家都收获了很多,更多的是从技术层面对于大数据相关的技术以及一些更具体的技术都有了更深的了解,当然这个过程中间还有一些存在的问题。最后感谢所有人的努力。
编辑:文婧
校对:林亦霖
