redo&undo日志:
redo日志大部分为物理日志,其记录时间点为缓冲中页面修改完成,但还没有刷新到硬盘的时间点(事务提交之前),即日至一定要比数据先到硬盘,聚集索引,次级索引,undo页面修改都需要记录redo日志,即可以把redo日志看成大管家,保证所有数据的完整性。
undo日志基本是逻辑日志,其记录时间点为修改缓冲中页面之前(先于redo日志,这样redo日志可以记录undo页面的变换,防止undo日志页因为宕机有部分没有刷新到ibd文件回滚段),需要注意的是次级索引记录的修改不记录undo日志(为什么?我感觉也可以记录。。)。需要注意的是binlog日志的记录点是在读取到commit之后写入的(即一定要知道事务提交了才能记录),这个时间redo已经写入,但一般修改的脏页还没刷新到硬盘。这三个日志写入时间点可以根据参数控制,一般都是联合使用。
那么redo&undo日志记录的到底是些什么呢?对于insert操作,undo记录的是插入行的主键,redo记录的是行插入位置的物理地址(space id ,page no,插入行,系统列。。),通过他们可以唯一确定插入位置。
delete操作,undo是将记录标记为delete mark,将系统列写入undo,将主键和所有索引列写入undo(索引列写入应该是为了次级索引恢复,insert不用大概是因为聚集索引的数据删了,次级索引就算不改也查不到数据了;还有个作用就是purge次级索引也可以通过它查询到对应页进行删除);redo同样是和insert差不多的操作。
update操作分为三种,一种是没有修改聚集索引键值,并且列长度未变的,这种的话聚集索引的数据位置没变,并且长度也没变,只需要在恢复的时候找到位置然后进行相应操作就行了。undo主要是将系统列写入,将主键列写入,将当前update列的前镜像写入,然后将修改后行记录的rollback ptr指向undo记录;redo主要是对聚集索引进行in place update,因为数据位置没变,如果update列包括次级索引,那么次级索引的位置肯定变了就不能就地解决了,需要对原记录进行delete mark,并且对新纪录insert redo日志。第二种是没有修改聚集索引键值但是列长度变化了,不过记录的位置没有变化,这对于undo是没有影响的,因为不管你怎么搞我只管把原来的位置变成原来的样子就可以了,对于redo主要影响的是聚集索引的记录不可进行in place update了,需要delete+insert redo,需要注意的是这里不是delete mark,而是直接将原纪录delete然后插入新纪录。第三种是修改了聚集索引键值,这种会导致新纪录跟原纪录不在同一位置,所以这里undo也不能in place update了,首先对原纪录进行delete mark操作然后写入undo,然后对新纪录进行insert操作然后写入undo;redo则是更第二种差不多。
这里顺便大概说一下innodb crash recovery的流程:
首先先把double write相关损坏的页面修复了,然后从redo log获取最后一次checkpoint的LSN,从这个点开始应用redo log,注意这里有个redo事件的重建流程,redo的流程是根据页为单位组建的,即recovery时缓冲池里维护一个hash表,根据space id 和page no做键值存储bucket list,每个页面维护一个list,其中list是根据事务id为顺序排列,因而重做的时候以页为单位,然后根据页里事务发生的顺序进行重做。
在redo完成后就需要进行undo未提交事务, undo信息的重构信息是由第五个页的trx list维护,大致流程是读取每个表的undo segement,然后根据事务id分别读取每个事务的undo slot,每个事务有两个slot(一个insert一个update),这些slot指向具体的undo page,读出这些slot后按照事务id 顺序组织在trx list里;然后每个undo page中的undo记录按照先后顺序同样进行顺序排列。大概的结构如下图:

undo信息组织完成后按照事务顺序进行回滚,然后根据最后一次commit操作的binlog信息决定是否回滚该事务的undo page。
MVCC原理
说到了undo就不得不提与之紧密相关的innodb mvcc,innodb事务的可重复读和读取已提交隔离等级就是通过mvcc+undo实现的。
我们都知道mvcc通过事务版本号进行mvcc,系统维护一个系统版本号,进行插入操作的时候就把插入记录的系统列事务id设置为当前系统版本号;对于删除操作,则是将记录标记为delete mark,并将事务id改为当前系统版本号;对于更新操作,则是同时保持旧记录和新纪录;对于查询操作则是根据当前系统版本号和查询行的事务id来判断记录是否可读。那么具体是怎么进行操作的呢。
主要是几个规则,一个是旧数据存储在undo中,再通过rollback ptr回溯查找历史版本。比如说update操作,对于不修改主键索引键值的update操作,更新后的行记录事务id存储修改时的系统版本号,然后将被更新的行记录写进undo中,并将更新后行记录rollback ptr指向这个undo记录,那么当一个正在进行的事务需要读取该进行了更新的记录,这个事务的版本号比更新后的行记录事务id要小,那么肯定是不能读取更新后的记录,就需要通过回滚指针前往undo读取更新前记录,直到满足条件为止。
那么这个决定记录是否可读的规则是由read view决定的,当隔离级别为可重复读时,每个事务开始时都会将当前系统所有的活跃事务拷贝到一个列表中(read view);当隔离级别为读取已提交时,在每个事务的每个语句开始时都会将所有活跃事务拷贝到read view中,即对于每个语句都需要更新它的可见性,如果不更新,那么在该读取事务进行时有其他事务对行记录进行了修改是不可知的。
然后按照以下逻辑判断事务可见性:
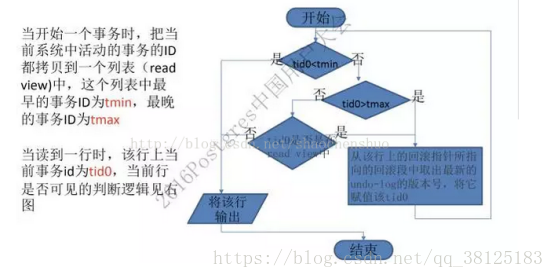
讲的都不是很详细和准确,如果想深入学习可以去何登成的技术博客学习大佬的见解~