词频统计
代码文件
继承Mapper,类实现自己的Mapper类,并重写map()方法。
package wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text,Text,IntWritable>{
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException{
String line = v1.toString();
String[] words = line.split(" ");
for(String word:words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
继承Reducer类,实现自己的Reducer类,并重写Reducer()方法。
package wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable>{
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable v:v3) {
sum += v.get();
}
context.write(k3, new IntWritable(sum));
}
}
程序入口类
package wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception{
//job
Job job = Job.getInstance(new Configuration());
job.setJarByClass(WordCountMain.class);
//mapper
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reducer
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//execute job
job.waitForCompletion(true);
}
}
计算各部门最高工资
| EMPNO |
ENAME |
JOB |
MGR |
HIREDATE |
SAL |
COMM |
DEPTION |
| 7369 |
SMITH |
CLERK |
7902 |
###### |
800 |
|
20 |
| 7499 |
ALLEN |
SALESMAN |
7698 |
###### |
1600 |
300 |
30 |
| 7521 |
WARD |
SALESMAN |
7698 |
###### |
1250 |
500 |
30 |
| 7566 |
JONES |
MANAGER |
7839 |
1981/4/2 |
2975 |
|
20 |
| 7654 |
MARTIN |
SALESMAN |
7698 |
###### |
1250 |
1400 |
30 |
| 7698 |
BLAKE |
MANAGER |
7839 |
1981/5/1 |
2850 |
|
30 |
| 7782 |
CLARK |
MANAGER |
7839 |
1981/6/9 |
2450 |
|
10 |
| 7788 |
SCOTT |
ANALYST |
7566 |
###### |
3000 |
|
20 |
| 7839 |
KING |
PRESIDENT |
###### |
5000 |
|
10 |
| 7844 |
TURNER |
SALESMAN |
7698 |
1981/9/8 |
1500 |
0 |
30 |
| 7876 |
ADAMS |
CLERK |
7788 |
###### |
1100 |
|
20 |
| 7900 |
JAMES |
CLERK |
7698 |
###### |
950 |
|
30 |
| 7902 |
FORD |
ANALYST |
7566 |
###### |
3000 |
|
20 |
| 7934 |
MILLER |
CLERK |
7782 |
###### |
1300 |
|
10 |
代码文件
Mapper类:
package saltotal;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class STM extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key1,Text value1,Context context)
throws IOException, InterruptedException {
String data = value1.toString();
String[] words = data.split(",");
context.write(new Text(words[2]), new IntWritable(Integer.parseInt(words[5])));
}
}
Reducer类:
package saltotal;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class STR extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3,Context context)
throws IOException, InterruptedException {
int max = 0;
for(IntWritable v:v3) {
if(v.get() > max) {
max = v.get();
}
}
context.write(k3, new IntWritable(max));
}
}
程序入口类:
package saltotal;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SalaryTotalMain {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(STM.class);
job.setMapperClass(STM.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(STR.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.waitForCompletion(true);
}
}
右键点击“src”

弹窗后选择”Export“

选择"JAR file"后,点击"Next"
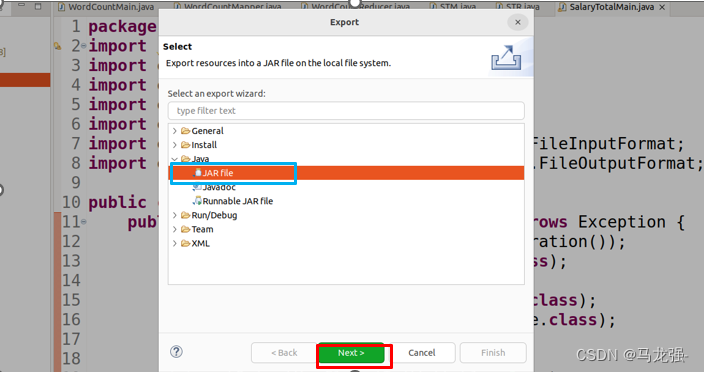
选择Java文件,选择Jar包保存路径,点击"Finish"导出jar包
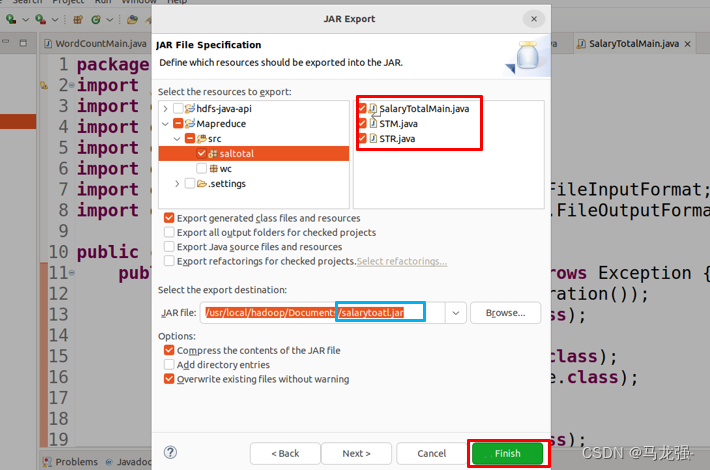
Documents下出现jar包
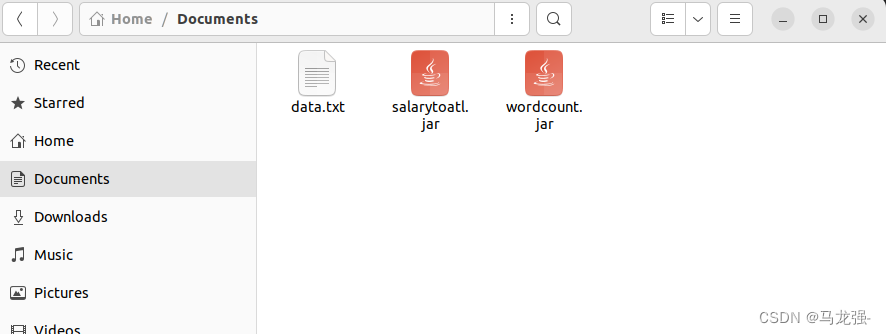
连接Xshell,使用Xftp传输文件到"Documents"路径下
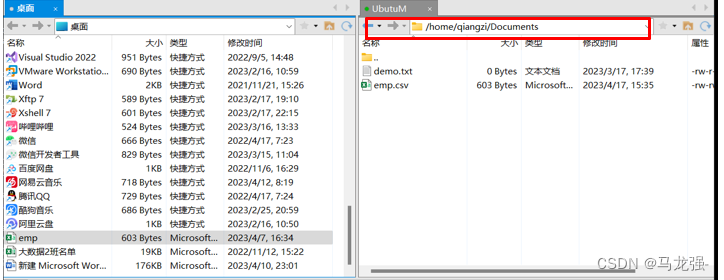
路径下出现emp.csv文件(在虚拟机可以拖拽到路径下)
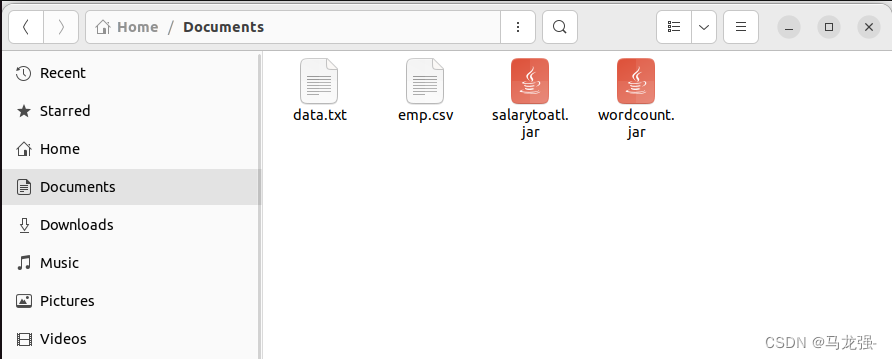
输入指令 cd /Documents,进入Documents路径下,ls,发现文件在路径下

启动hdfs 
jps,查看节点

查看salarytotal.jar中内容

将emp.csv上传到HDFS下input文件夹中

查看input文件夹下内容

查看user下文件(不能有重复文件)

输入指令,命名文件名为"sc"(最后的文件名可以随意命名,这里的为sc)

qiangzi@qiangzi-virtual-machine:~/Documents$ hadoop jar salarytoatl.jar saltotal.SalaryTotalMain /input/emp.csv /user/sc5
23/04/17 20:14:29 INFO client.RMProxy: Connecting to ResourceManager at qiangzi-virtual-machine/127.0.1.1:8032
23/04/17 20:14:32 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
23/04/17 20:14:35 INFO input.FileInputFormat: Total input files to process : 1
23/04/17 20:14:36 INFO mapreduce.JobSubmitter: number of splits:1
23/04/17 20:14:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1681718824501_0006
23/04/17 20:14:38 INFO conf.Configuration: resource-types.xml not found
23/04/17 20:14:38 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/04/17 20:14:38 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
23/04/17 20:14:38 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
23/04/17 20:14:40 INFO impl.YarnClientImpl: Submitted application application_1681718824501_0006
23/04/17 20:14:40 INFO mapreduce.Job: The url to track the job: http://qiangzi-virtual-machine:8088/proxy/application_1681718824501_0006/
23/04/17 20:14:40 INFO mapreduce.Job: Running job: job_1681718824501_0006
23/04/17 20:15:10 INFO mapreduce.Job: Job job_1681718824501_0006 running in uber mode : false
23/04/17 20:15:10 INFO mapreduce.Job: map 0% reduce 0%
23/04/17 20:18:25 INFO mapreduce.Job: map 100% reduce 0%
23/04/17 20:18:45 INFO mapreduce.Job: map 100% reduce 100%
23/04/17 20:18:49 INFO mapreduce.Job: Job job_1681718824501_0006 completed successfully
23/04/17 20:18:51 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=200
FILE: Number of bytes written=417325
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=708
HDFS: Number of bytes written=66
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=188987
Total time spent by all reduces in occupied slots (ms)=16669
Total time spent by all map tasks (ms)=188987
Total time spent by all reduce tasks (ms)=16669
Total vcore-milliseconds taken by all map tasks=188987
Total vcore-milliseconds taken by all reduce tasks=16669
Total megabyte-milliseconds taken by all map tasks=193522688
Total megabyte-milliseconds taken by all reduce tasks=17069056
Map-Reduce Framework
Map input records=14
Map output records=14
Map output bytes=166
Map output materialized bytes=200
Input split bytes=105
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=200
Reduce input records=14
Reduce output records=5
Spilled Records=28
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=2528
CPU time spent (ms)=4880
Physical memory (bytes) snapshot=457605120
Virtual memory (bytes) snapshot=3926859776
Total committed heap usage (bytes)=277348352
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=603
File Output Format Counters
Bytes Written=66
查看sc中的内容
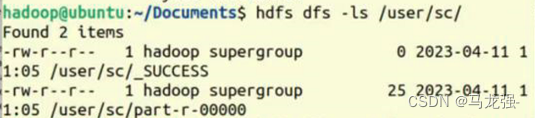
查看统计内容

实验结果
