一、索引优化(有关索引详解可参看博客http://blog.csdn.net/zhangliangzi/article/details/51366345)
1、合理使用索引,在经常查询而不经常增删改操作的字段加索引,一个表上的索引不应该超过6个。
2、Order by与group by后应直接使用字段,而且字段应该是索引字段。
3、索引字段长度应较短而长度固定。
4、索引字段重复不能过多。
5、Hash索引与BTree索引区别(MyISAM与InnoDB不支持Hash索引)
(1)、BTree索引使用多路搜索树的数据结构,可以减少定位的中间过程;综合效率较高,默认使用的索引。
(2)、Hash索引使用Hash算法构建索引;精确的等值查询一次定位,效率极高,但特别不适合范围查询;使用Hash的复合索引是把复合索引键共同计算hash值,故不能单独使用。
6、会导致引擎放弃使用索引,改为进行全表的几种情况,都要在开发中尽量避免出现!
(1)、where子句中使用like关键字时,前置百分号会导致索引失效(起始字符不确定都会失效)。如:select id from test where name like "%吉坤"。
(2)、where子句中使用is null或is not null时,因为null值会被自动从索引中排除,索引一般不会建立在有空值的列上。
(3)、where子句中使用or关键字时,or左右字段如果存在一个没有索引,有索引字段也会失效;而且即使都有索引,因为二者的索引存储顺序并不一致,效率还不如顺序全表扫描,这时引擎有可能放弃使用索引,所以要慎用or。
(4)、where子句中使用in或not in关键字时,会导致全表扫描,能使用exists或between and替代就不使用in。
(5)、where子句中使用!=操作符时,将放弃使用索引,因为范围不确定,使用索引效率不高,会被引擎自动改为全表扫描;
(6)、where子句中应尽量避免对索引字段操作(表达式操作或函数操作),比如select id from test where num/2 = 100应改为num = 200。
(7)、在使用复合索引时,查询时必须使用到索引的第一个字段,否则索引失效;并且应尽量让字段顺序与索引顺序一致。
(8)、查询时必须使用正确的数据类型。数据库包含了自动了类型转换,比如纯数字赋值给字符串字段时可以被自动转换,但如果查询时不加引号查询,会导致引擎忽略索引。
二、表结构优化
1、设计符合第三范式的表结构。
2、尽量使用数字型字段,提高数据比对效率。
3、对定长、MD5哈希码、长度较短的字段使用char类型,提高效率;对边长而且可能较长字段使用varchar类型,节约内存。
4、适当的进行水平分割与垂直分割,比如当表列数过多时,就将一部分列移出到另一张表中。关于水平分割与垂直分割表详解:
水平分割表:一种是当多个过程频繁访问数据表的不同行时,水平分割表,并消除新表中的冗余数据列;若个别过程要访问整个数据,则要用连接*作,这也无妨分割表;典型案例是电信话单按月分割存放。另一种是当主要过程要重复访问部分行时,最好将被重复访问的这些行单独形成子集表(冗余储存),这在不考虑磁盘空间开销时显得十分重要;但在分割表以后,增加了维护难度,要用触发器立即更新、或存储过程或应用代码批量更新,这也会增加额外的磁盘I/O开销。
水平分割会给应用增加复杂度,它通常在查询时需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加两到三倍数据量,查询时也就增加读一个索引层的磁盘次数。垂直分割表(不破坏第三范式):一种是当多个过程频繁访问表的不同列时,可将表垂直分成几个表,减少磁盘I/O(每行的数据列少,每页存的数据行就多,相应占用的页就少),更新时不必考虑锁,没有冗余数据。缺点是要在插入或删除数据时要考虑数据的完整性,用存储过程维护。另一种是当主要过程反复访问部分列时,最好将这部分被频繁访问的列数据单独存为一个子集表(冗余储存),这在不考虑磁盘空间开销时显得十分重要;但这增加了重叠列的维护难度,要用触发器立即更新、或存储过程或应用代码批量更新,这也会增加额外的磁盘I/O开销。垂直分割表可以达到最大化利用Cache的目的。
垂直分割可以使得数据行变小(因为列少了,一行数据就变小),一个数据页就能存放更多的数据,在查询时就会减少I/O 次数。其缺点是需要管理冗余列,查询所有数据需要join操作 。三、临时表优化——临时表常常用于排序或分组,所以Order By与Group By后的字段尽量使用索引
临时表可以根据实际需求使用,但要尽力避免磁盘临时表的生成。
1、常见的会产生内存临时表的情况
1、UNION查询。2、子查询(所以我们一般用join代替子查询)。
3、join查询中,如果order by 与 group by如果使用的不都是第一张表上的字段,就会产生临时表。
4、order by中使用distinct函数。
2、常见的会产生磁盘临时表的情况
1、数据表中包含BLOB/TEXT列。2、Group by、distinct、union查询中包含超过512字节的列。
四、其他优化
1、不使用Select *,只查询需要的字段。
2、在只查询一条字段时,limit 1。3、避免大事务操作,提高并发能力。
4、在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。5、尽量少使用游标。
6、多去关注慢查询,总有我们提前考虑不到的问题,出现了就去解决它!
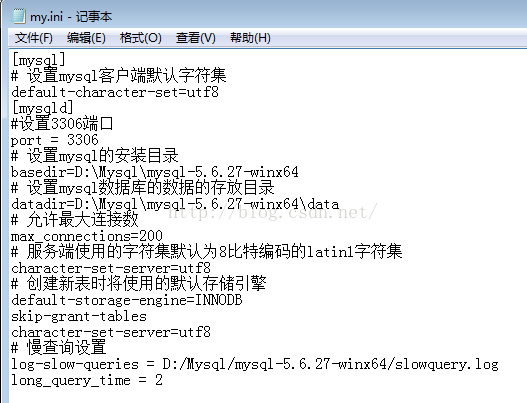
附慢查询开启方式:
在mysql安装目录下,找到my.ini配置文件,在mysqld下加上如下配置:
log-slow-queries = D:/Mysql/mysql-5.6.27-winx64/slowquery.log
long_query_time = 2